OpenClaw - Partie 05 : Mise en œuvre de l'agent it-claw
Introduction
C'est le moment d'aller au bout du cookbook et d'enfin pouvoir exécuter (et surtout tester) le premier agent IT claw.
Pour rappel, l'objectif était de créer un environnement sécurisé pour exécuter un ou plusieurs agents basés sur openclaw.
La stratégie générale adoptée a consisté à configurer un serveur dédié fonctionnant sous Rocky Linux. Nous avons ensuite déployé un ensemble de prérequis associé à un utilisateur dédié, puis installé podman, permettant à chaque agent de fonctionner dans un conteneur distinct.
Ensuite, l'outil Vault spécialisé dans le stockage d'éléments confidentiels a été déployé pour qu'on y dépose les secrets propres a ce premier agent.
Celui-ci devra pouvoir se connecter à un cluster Kubernetes en lecture seule pour servir de solution de suivi et de monitoring qu'on pourra interroger à travers Telegram.
Focus et rappel sur l'arborescence
Avant de passer aux actions, j'aimerais rappeler l'arborescence retenue pour le projet. C'est important de bien la comprendre et de l'avoir en tête, car une grosse partie de la sécurité repose sur la bonne gestion des droits et des usages de chaque répertoire.
| Chemin | Perms / Propriétaire | Rôle |
|---|---|---|
/var/lib/openclaw/ |
700 openclaw:openclaw | Home du compte de service openclaw. Le 700 cloisonne tout l'agent vis-à-vis des autres utilisateurs locaux. |
.config/containers/systemd/ |
openclaw | Quadlets Podman. systemctl --user daemon-reload les traduit en unités systemd. |
.config/containers/systemd/vault-agent-it-claw.container |
openclaw | Définition du conteneur vault-agent (image, volumes, User=1000). |
.config/containers/systemd/it-claw.container |
openclaw | Définition du conteneur agent it-claw (image, PublishPort, réseau, volumes). |
build/openclaw-it/ |
openclaw | Contexte de build de l'image custom. |
build/openclaw-it/Dockerfile |
openclaw | Recette de l'image localhost/openclaw-it:vN (base OpenClaw + kubectl + jq). |
vault/ |
openclaw:openclaw | Racine du matériel Vault côté host, monté en lecture seule dans le conteneur vault-agent. |
vault/agent/it-claw/ |
openclaw | Config vault-agent namespacée par agent (un sous-dossier par agent). Montée sur /vault/config. |
vault/agent/it-claw/agent-it-claw.hcl |
openclaw | Config HCL du vault-agent : auto_auth AppRole, sink token, cache, blocs template. |
vault/agent/it-claw/templates/ |
openclaw | Templates consul-template (un .tpl par secret). Référencés en interne sous /vault/config/templates/. |
vault/it-claw-role-id |
644 openclaw | role_id de l'AppRole. 644 requis pour lecture par le conteneur rootless après mapping de namespace. |
vault/it-claw-secret-id |
644 openclaw | secret_id de l'AppRole (renouvelé à la rotation). |
vault/tls/ |
openclaw | Confiance TLS pour joindre Vault. Montée sur /vault/tls. |
vault/tls/ca.crt |
644 openclaw | CA (chaîne COOLCORP) validant le certificat du listener Vault. |
instances/it-claw/ |
openclaw | Racine runtime de l'agent it-claw (une instance = un agent). |
instances/it-claw/sink/ |
770, UID 100999 | Point de rendez-vous des secrets. vault-agent (User=1000) y écrit, it-claw le monte en lecture seule sur …/.openclaw/sink. |
instances/it-claw/sink/telegram_token |
600 | Token du bot Telegram, matérialisé par vault-agent depuis Vault. |
instances/it-claw/sink/gateway_token |
600 | Token du gateway OpenClaw. |
instances/it-claw/sink/kubeconfig |
600 | Kubeconfig (SA svc-openclaw-it, ClusterRole view) consommé par kubectl. |
instances/it-claw/sink/.vault-token |
600 | Token Vault courant émis par auto_auth (renouvelé automatiquement). |
instances/it-claw/sink/.agent.pid |
— | PID du process vault-agent (déclaré par pid_file). |
instances/it-claw/state/ |
750, UID 100999 (= node) | État persistant d'OpenClaw, monté sur /home/node/.openclaw. Propriété de l'UID interne 1000 du conteneur (= 100999 côté host). |
instances/it-claw/state/openclaw.json |
640, UID 1000 | Config principale de l'agent (gateway, auth trusted-proxy, modèles, plugins, secrets). |
instances/it-claw/state/workspace/ |
UID 1000 | Espace de travail de l'agent (référencé par agents.defaults.workspace). |
instances/it-claw/state/workspace/SOUL.md |
640, UID 1000 | Identité, capacités et limites de l'agent (chargé via le hook boot-md). |
instances/it-claw/state/canvas/ |
UID 1000 | Créé au runtime — données du canvas OpenClaw. |
instances/it-claw/state/agents/ |
UID 1000 | Créé au runtime — état par agent (sessions, historique *.jsonl, etc.). |
instances/it-claw/state/identity/ |
UID 1000 | Créé au runtime — identité/clés de l'instance. |
Certains dossiers n'existent pas encore, mais nous allons les créer et les manipuler par la suite. D'autres ont déjà été vus et traités dans les articles précédents.
Build du conteneur
L'agent va s'exécuter sous forme de conteneur. On commence donc par créer l'image dans laquelle on va inclure l'interface de ligne de commande kubectl afin que l'agent puisse y faire appel.
Pour ça on bascule dans le contexte de notre utilisateur dédié chargé de la manipulation des agents.
sudo machinectl shell openclaw@
Cliquez sur l'image pour l'agrandir.
Étant maintenant dans le bon contexte utilisateur, on va créer un dossier pour le build des conteneurs dans lequel on va créer un sous-dossier spécifique à notre agent.
mkdir -p ~/build/openclaw-it
cd ~/build/openclaw-it
Cliquez sur l'image pour l'agrandir.
On crée le Dockerfile dont le contenu est le suivant.
cat > Dockerfile <<'EOF'
FROM ghcr.io/openclaw/openclaw:2026.5.28
USER root
ARG KUBECTL_VERSION=v1.34.0
RUN apt-get update && apt-get install -y --no-install-recommends curl ca-certificates \
&& curl -sfL "https://dl.k8s.io/release/${KUBECTL_VERSION}/bin/linux/amd64/kubectl" -o /usr/local/bin/kubectl \
&& curl -sfL "https://dl.k8s.io/release/${KUBECTL_VERSION}/bin/linux/amd64/kubectl.sha256" -o /tmp/kubectl.sha256 \
&& echo "$(cat /tmp/kubectl.sha256) /usr/local/bin/kubectl" | sha256sum -c - \
&& chmod +x /usr/local/bin/kubectl \
&& rm -f /tmp/kubectl.sha256 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN apt-get update && apt-get install -y --no-install-recommends jq \
&& apt-get clean && rm -rf /var/lib/apt/lists/*
USER node
LABEL org.opencontainers.image.title="openclaw-it"
LABEL org.opencontainers.image.description="OpenClaw with kubectl for K8S agents"
LABEL org.opencontainers.image.base.name="ghcr.io/openclaw/openclaw:latest"
EOF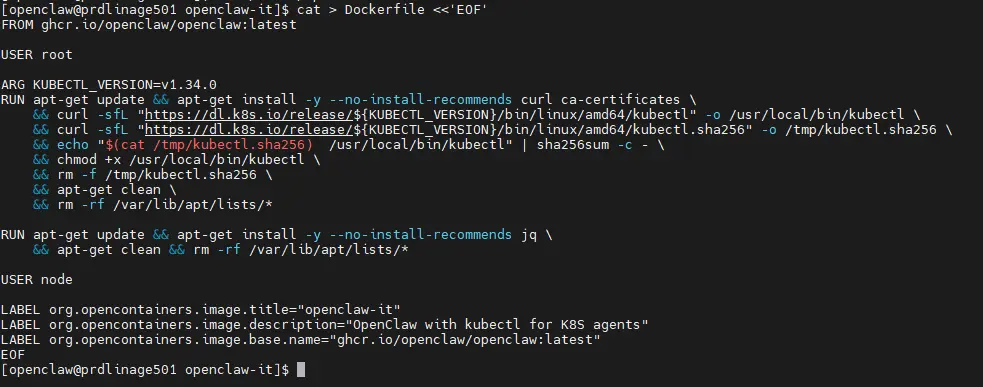
Cliquez sur l'image pour l'agrandir.
Dans ce Dockerfile, on fixe la version de kubectl à récupérer, car elle doit matcher avec la version du cluster que l'agent va devoir interroger.
Puis on enchaine avec la récupération du conteneur openclaw disponible sur ghcr.io.
On compile l'image.
podman build -t localhost/openclaw-it:v1 .
Cliquez sur l'image pour l'agrandir.
On vérifie qu'elle est fonctionnelle.
podman images | grep openclaw-it
podman run --rm localhost/openclaw-it:v1 kubectl version --client
podman run --rm localhost/openclaw-it:v1 jq --version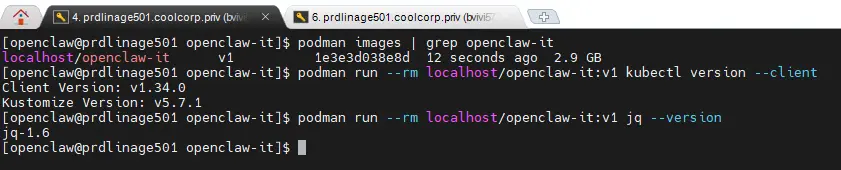
Cliquez sur l'image pour l'agrandir.
Création des répertoires
Avant de l'exécuter définitivement, on va devoir s'assurer de la présence de toute la sous-arborescence nécessaire à l'agent (d'où mon rappel en début d'article).
# Répertoires principaux
mkdir -p ~/instances/it-claw/sink
mkdir -p ~/instances/it-claw/state/workspace
mkdir -p ~/instances/it-claw/state/canvas
mkdir -p ~/instances/it-claw/state/agents
mkdir -p ~/instances/it-claw/state/identity
Cliquez sur l'image pour l'agrandir.
Focus sur le dossier sink
L'un des dossiers les plus critiques est le dossier sink. Il agit comme un sas, où le futur conteneur Vault (différent de celui de l'agent) va venir déposer les informations confidentielles nécessaires à l'agent, et là où l'agent va venir lire ces informations.
L'agent IA n'aura pas conscience du client Vault ; il se contentera de lire le contenu du dossier sink.
Il faut donc que ce dossier soit accessible en écriture au client Vault, mais en lecture uniquement à l'agent IA.
On positionne donc les droits suivants.
chmod 770 ~/instances/it-claw/sinkPour l'instant le droit est trop large, mais nous jouerons sur le droit des fichiers eux-mêmes qui seront dans le répertoire sink.
Focus sur les UID et les users
En effet, l'image de base d'OpenClaw exécute son application Node.js sous l'utilisateur node, qui possède historiquement l'UID 1000. OpenClaw possède des mesures de sécurité internes très rigoureuses : il refuse de s'exécuter si les autorisations de ses informations confidentielles sont jugées trop laxistes (il demande un niveau de permission de 0600). De plus, il doit être le propriétaire de ces fichiers pour pouvoir les lire.
Ce point est important, car, par défaut, l'image Vault qu'on va utiliser après tourne sous l'utilisateur interne vault (qui a l'UID 100). Il faudra modifier ce comportement pour éviter que Vault écrive les secrets dans le répertoire sink avec l'UID 100. Ainsi, l'agent OpenClaw (UID 1000) n'aurait tout simplement pas le droit de les lire (car les fichiers seraient en 0600 pour l'UID 100).
Toujours à cause de l'UID 1000 d'openclaw dans son conteneur et du fait qu'on soit dans un environnement rootless, il faut tenir compte que, au moment du démarrage de l'agent et pendant son exécution, openclaw doit créer des sous-répertoires (comme canvas/ ou agents/) dans le dossier state/. Si le dossier ne lui appartient pas alors l'agent openclaw tombera en erreur.
On doit donc exploiter les deux commandes suivantes.
podman unshare chown -R 1000:1000 ~/instances/it-claw/state
podman unshare chmod -R 750 ~/instances/it-claw/state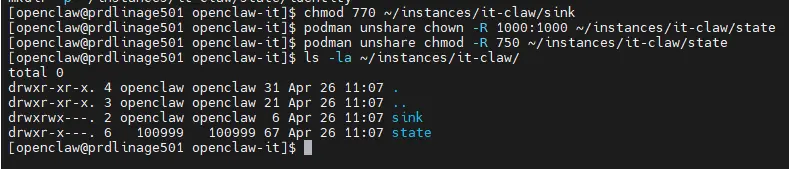
Cliquez sur l'image pour l'agrandir.
L'instruction podman unshare permet d'exécuter une commande en entrant temporairement dans le user namespace de Podman. Dans cette "bulle" isolée, notre utilisateur technique openclaw devient virtuellement root (UID 0 interne) et obtient l'autorisation exclusive de manipuler les sous-UIDs (SubUIDs) qui lui sont alloués.
C'est l'unique moyen pour un utilisateur non-privilégié de faire un chown ciblant l'UID interne d'un conteneur.
C'est le revers de la médaille d'avoir retenu un environnement d'exécution rootless avec podman. Toutefois, cela renforce la sécurité à condition de ne pas se tromper dans les autorisations.
D'ailleurs, avant de continuer sur le conteneur Vault, on va résumer les liens entre les UID de l'OS, les sous-UID podman et nos conteneurs.
| Composant / Conteneur | Utilisateur (dans le conteneur) | UID interne (conteneur) | Utilisateur réel (hôte) | UID réel (hôte Rocky Linux) | Explication |
|---|---|---|---|---|---|
Hôte — session systemd --user / Podman |
— | — | openclaw | 994 (GID 994) | Compte de service qui possède la session et lance les conteneurs rootless. Pivot de tout le mapping. |
| Racine du user namespace (tout conteneur) | root | 0 | openclaw | 994 | L'UID 0 interne retombe sur le compte openclaw côté hôte — pas sur le vrai root système. Aucun privilège réel obtenu. |
| vault-agent-it-claw | (forcé User=1000:1000) | 1000 | aucun (subuid non nommé) | 100999 | UID forcé à 1000 pour que les secrets écrits dans sink/ soient possédés par 100999, donc lisibles par it-claw. |
| it-claw | node | 1000 | aucun (subuid non nommé) | 100999 | node = utilisateur par défaut de l'image OpenClaw. Même UID effectif que vault-agent → lecture des fichiers sink/ en 0600. |
(référence) image hashicorp/vault non surchargée |
vault | 100 | aucun (subuid non nommé) | 100099 | UID historique de Vault, volontairement non utilisé : sinon les secrets seraient en 100099, illisibles par it-claw (100999). |
Traitement de l'agent vault (client)
On attaque la partie Vault.
Attention, je vais employer le terme d'agent Vault, qu'il ne faut pas confondre avec notre agent IA.
Pour rappel, chaque agent IA sera accompagné de son agent Vault.
Chaque agent Vault dispose de son propre dossier. Cela permet d'isoler les configs et les templates par agent Vault.
En l'occurrence pour nous : vault/agent/it-claw/.
Création des templates
On crée donc le dossier pour les templates.
mkdir -p ~/vault/agent/it-claw/templatesLes fichiers templates Vault sont des petits fichiers d'instructions utilisés par le conteneur de l'agent Vault pour extraire, formater et enregistrer les secrets. Ils utilisent la syntaxe consul-template.
Quand on interroge Vault pour obtenir un secret, Vault ne renvoie pas juste la chaîne de caractères du mot de passe. Il renvoie un objet complexe contenant des métadonnées et la donnée enveloppée.
Le template sert de traducteur pour que les fichiers déposés dans le dossier sink soient uniquement les données brutes exploitables par l'agent IA.
Il va donc y avoir un template par secret à récupérer.
# Template Telegram token
cat > ~/vault/agent/it-claw/templates/telegram_token.tpl <<'EOF'
{{ with secret "secret/data/openclaw/it-claw/telegram_token" }}{{ .Data.data.value }}{{ end }}
EOF
# Template Gateway token
cat > ~/vault/agent/it-claw/templates/gateway_token.tpl <<'EOF'
{{ with secret "secret/data/openclaw/it-claw/gateway_token" }}{{ .Data.data.value }}{{ end }}
EOF
# Template Kubeconfig
cat > ~/vault/agent/it-claw/templates/kubeconfig.tpl <<'EOF'
{{ with secret "secret/data/openclaw/it-claw/kubeconfig" }}{{ .Data.data.value }}{{ end }}
EOF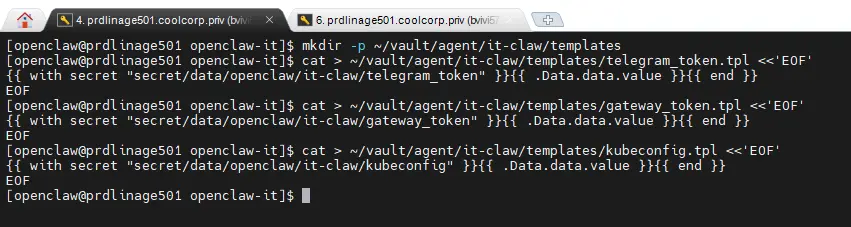
Cliquez sur l'image pour l'agrandir.
Chaque template fait appel en source à l'emplacement du secret dans la base clef/valeur vault dans laquelle nous avons stocké nos elements confidentiels.
Configuration
Ensuite, on va s'occuper de la configuration de l'agent Vault. Celle ci se déclare dans un fichier HCL (HashiCorp Configuration Language) qui contient plusieurs blocs d'instructions.
cat > ~/vault/agent/it-claw/agent-it-claw.hcl <<'EOF'
pid_file = "/vault/sink/.agent.pid"
vault {
address = "https://prdlinage501.coolcorp.priv:8200"
ca_cert = "/vault/tls/ca.crt"
retry {
num_retries = 5
}
}
auto_auth {
method "approle" {
mount_path = "auth/approle"
config = {
role_id_file_path = "/vault/auth/role-id"
secret_id_file_path = "/vault/auth/secret-id"
remove_secret_id_file_after_reading = false
}
}
sink "file" {
config = {
path = "/vault/sink/.vault-token"
mode = 0600
}
}
}
cache {
use_auto_auth_token = true
}
listener "tcp" {
address = "127.0.0.1:8100"
tls_disable = true
}
template {
source = "/vault/config/templates/telegram_token.tpl"
destination = "/vault/sink/telegram_token"
perms = 0600
}
template {
source = "/vault/config/templates/gateway_token.tpl"
destination = "/vault/sink/gateway_token"
perms = 0600
}
template {
source = "/vault/config/templates/kubeconfig.tpl"
destination = "/vault/sink/kubeconfig"
perms = 0600
}
# Note : les sources /vault/config/templates/ correspondent au montage
# Volume=%h/vault/agent/it-claw:/vault/config dans le Quadlet.
EOF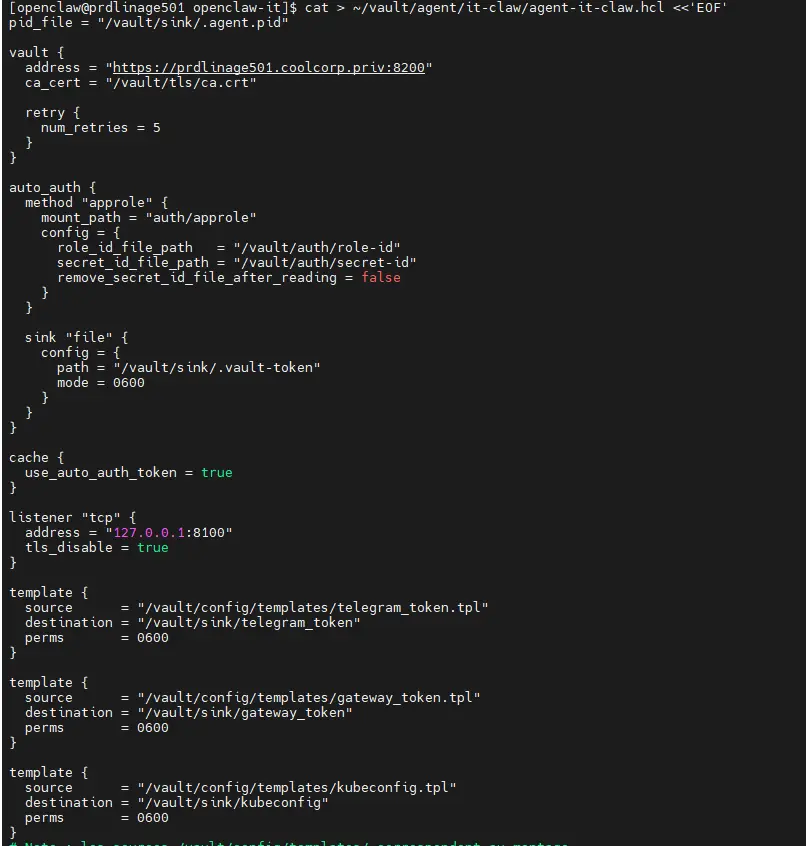
Cliquez sur l'image pour l'agrandir.
On s'adresse à l'instance locale de vault. On y retrouve également la référence à nos templates.
Création du quadlet
Nous n'allons pas construire une image spécifique. Celle par défaut fonctionne très bien. Cependant, nous devrons la démarrer avec un ensemble de paramètres spécifiques.
Pour cela on va exploiter un Quadlet.
Un Quadlet est un outil natif intégré à Podman qui sert de "traducteur" entre Podman et systemd. Il permet de gérer le cycle de vie des conteneurs de manière déclarative, exactement comme on gère des services Linux classiques.
En gros, on déclare un conteneur comme on déclare un service pour systemd.
On crée donc un dossier spécifique pour cela dans notre arborescence.
mkdir -p ~/.config/containers/systemd
Cliquez sur l'image pour l'agrandir.
Puis on y déclare la configuration pour le conteneur vault.
cat > ~/.config/containers/systemd/vault-agent-it-claw.container <<'EOF'
[Unit]
Description=Vault Agent for it-claw
Wants=network-online.target
After=network-online.target
[Container]
Image=docker.io/hashicorp/vault:2.0.1
ContainerName=vault-agent-it-claw
Network=slirp4netns
# keep-id préserve le mapping user namespace
UserNS=keep-id
# Forcer UID 1000 pour que les fichiers écrits soient owned par UID 1000 = node côté it-claw
User=1000:1000
# Config it-claw uniquement (namespaced par agent — évite les conflits avec d'autres agents)
Volume=%h/vault/agent/it-claw:/vault/config:Z,ro
Volume=%h/vault/it-claw-role-id:/vault/auth/role-id:Z,ro
Volume=%h/vault/it-claw-secret-id:/vault/auth/secret-id:Z,ro
Volume=%h/vault/tls:/vault/tls:Z,ro
# Sink en écriture (shared avec it-claw qui le lit en :ro)
Volume=%h/instances/it-claw/sink:/vault/sink:Z
# Bypass de l'entrypoint défaillant (qui tente un chown sur /vault/config en :ro)
Entrypoint=/bin/vault
Exec=agent -config=/vault/config/agent-it-claw.hcl
NoNewPrivileges=true
[Service]
Restart=on-failure
RestartSec=10
TimeoutStartSec=60
[Install]
WantedBy=default.target
EOF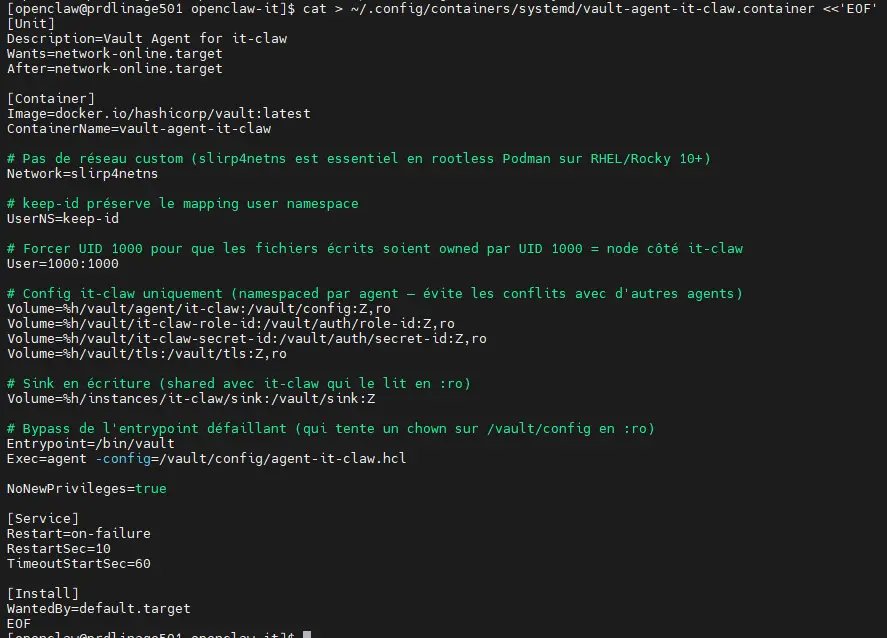
Cliquez sur l'image pour l'agrandir.
Il y a quelques spécificités à cette configuration.
D'un point de vue réseau, on passe par slirp4netns, soit le moteur réseau historique pour les conteneurs rootless.
Sous Rocky 10 ce n'est pas le moteur par défaut, appelé pasta. Je ne peux pas l'utiliser car, bien que plus performant, cela m'a posé des problèmes pour exploiter les FQDN de l'hôte depuis les conteneurs. Slirp4netns revient à faire du NAT et simplifie le sujet.
On note aussi dans la conf qu'on force l'ID utilisateur dans le conteneur pour que l'agent vault fonctionne en tant qu'UID 1000 afin de correspondre à l'utilisateur du nœud IT-Claw.
On bypass également l'entrypoint par défaut de l'image pour contourner sa configuration par défaut et éviter des opérations d'attribution de droits qui échouaient en mode rootless.
Traitement de l'agent IT-Claw
Configuration d'OpenClaw
On en vient à la configuration d'openclaw.
Celle-ci n'est pas toujours simple et évolue souvent. Il s'agit d'un fichier openclaw.json.
Lorsqu'on déploie openclaw de manière classique, il suffit de suivre l'assistant de configuration. Ici, il va falloir tout déclarer manuellement.
Ce qui revient au fichier suivant.
cat > /tmp/openclaw.json <<'EOF'
{
"gateway": {
"trustedProxies": ["10.0.2.0/24"],
"mode": "local",
"port": 18790,
"bind": "lan",
"nodes": {
"pairing": {
"autoApproveCidrs": ["192.168.10.0/24", "10.0.2.0/24"]
}
},
"controlUi": {
"allowedOrigins": ["https://it-claw.coolcorp.priv"]
},
"auth": {
"mode": "trusted-proxy",
"trustedProxy": {
"userHeader": "x-forwarded-user",
"allowUsers": ["bvivi57"]
}
}
},
"agents": {
"defaults": {
"workspace": "/home/node/.openclaw/workspace",
"model": {
"primary": "ollama/qwen3.5:latest"
},
"models": {
"ollama/qwen3.5:latest": { "alias": "qwen3.5" }
}
}
},
"models": {
"mode": "merge",
"providers": {
"ollama": {
"baseUrl": "http://192.168.10.2:11434",
"apiKey": "OLLAMA_API_KEY",
"api": "ollama",
"models": [
{
"id": "qwen3.5:latest",
"name": "qwen3.5:latest",
"reasoning": false,
"input": ["text"],
"cost": {
"input": 0,
"output": 0,
"cacheRead": 0,
"cacheWrite": 0
},
"contextWindow": 32768,
"maxTokens": 4096
}
]
}
}
},
"session": {
"dmScope": "per-channel-peer"
},
"tools": {
"profile": "coding"
},
"auth": {
"profiles": {
"ollama:default": {
"provider": "ollama",
"mode": "api_key"
}
}
},
"secrets": {
"providers": {
"telegram-token": {
"source": "file",
"path": "/home/node/.openclaw/sink/telegram_token",
"mode": "singleValue"
},
"gateway-token": {
"source": "file",
"path": "/home/node/.openclaw/sink/gateway_token",
"mode": "singleValue"
}
}
},
"channels": {
"telegram": {
"enabled": true,
"dmPolicy": "allowlist",
"allowFrom": ["tg:votre_id"],
"botToken": {
"source": "file",
"provider": "telegram-token",
"id": "value"
}
}
},
"plugins": {
"entries": {
"ollama": { "enabled": true },
"bonjour": { "enabled": false }
}
},
"hooks": {
"internal": {
"enabled": true,
"entries": {
"boot-md": { "enabled": true },
"session-memory": { "enabled": true },
"command-logger": { "enabled": true }
}
}
}
}
EOF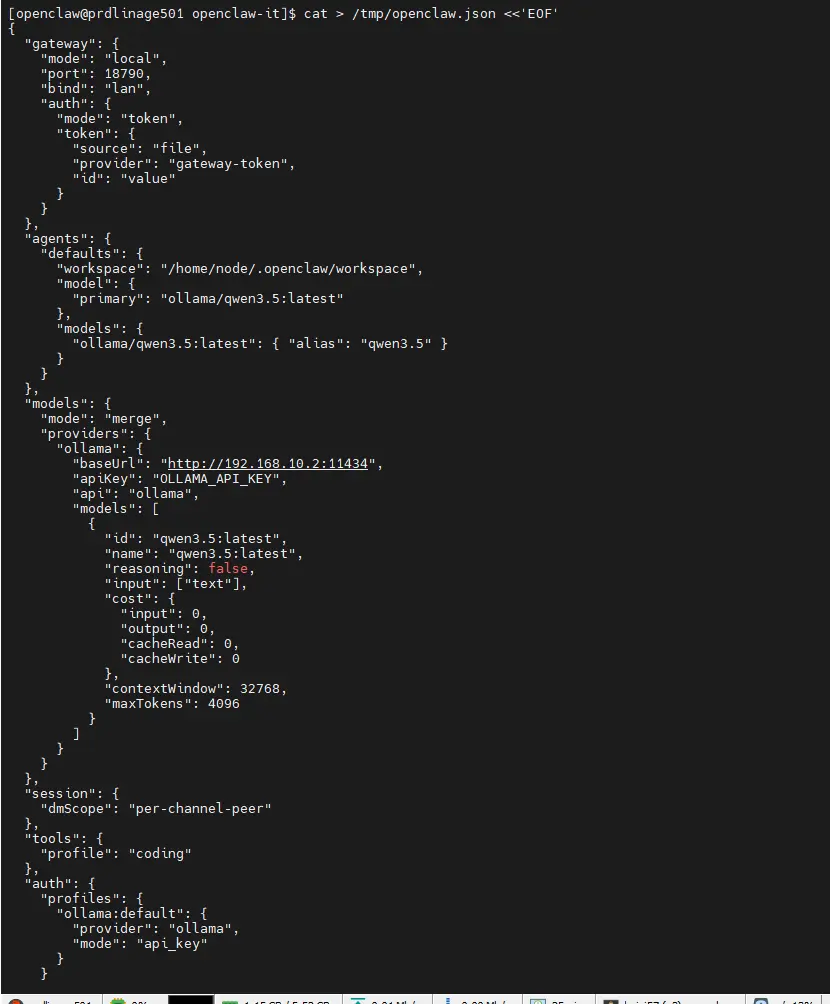
Cliquez sur l'image pour l'agrandir.
Plusieurs éléments critiques dans cette configuration.
Déjà, dès le début, on utilise l'option "trustedProxies": ["10.0.2.0/24"], qui permet à openclaw de faire confiance à notre reverse proxy NGINX qu'on a déployé précédemment.
Il faut savoir que pour l'accès à la GUI, openclaw passe par un mécanisme assez compliqué d'approbation de device.
Dans mon cas, j'ai simplifié cette approche par l'usage de NGINX qui vient ajouter une couche d'authentification.
C'est d'ailleurs le mode trusted-proxy qui est configuré avec la récupération du header du user afin que openclaw sache si l'utilisateur fait partie des personnes autorisées via l'option allowUsers.
Plus bas, on définit les caractéristiques des modèles à utiliser et quelle instance LLM utiliser.
Dans mon cas, je me suis décidé à exploiter le modèle à poids ouvert qwen3.5 proposé par Alibaba, le géant du cloud Chinois.
Avec 9 milliards de paramètres dans sa version de base, c'est un modèle plutôt généraliste qui pourra tourner correctement aussi bien sur mon GPU que sur mon Macbook Pro.
Pour l'instant, je vais pointer la configuration vers mon instance Ollama installée sur mon PC. C'est donc mon GPU Nvidia 5070 Ti et ses 16 Go de VRAM qui vont être mis à contribution.
J'attire votre attention sur le fait que la baseUrl est en HTTP et pointe directement vers le port 11434 de l'IP locale de mon PC.
C'est une limitation importante en termes de sécurité. En interne, l'API de Ollama ne supporte pas le HTTPS et ne fournit pas de mécanisme d'authentification. L'API key ne sert que pour la partie cloud de Ollama.
C'est un problème connu et assumé des développeurs. Cela implique que tout le flux entre vos agents et Ollama n'est pas chiffré.
Si on peut partir du principe qu'en interne, cela ne devrait pas poser de soucis, c'est quand même gênant en entreprise.
Sans compter que toute machine de votre réseau interne peut potentiellement solliciter l'instance Ollama si vous ne faites pas un filtrage firewall sur le PC hébergeant l'outil.
J'étendrai certainement cet article avec une méthode permettant le HTTPS, mais, pour l'instant, je vais déjà essayer d'aller au bout de l'expérience.
À noter que, par défaut, Ollama n'écoute que sur son localhost ; il faut activer le support du réseau au niveau des options.

Cliquez sur l'image pour l'agrandir.
C'est important aussi de considérer les points de configuration suivants :
- contextWindow : c'est la taille totale de la "mémoire à court terme" du modèle (combien de tokens il peut conserver en mémoire pour une conversation, y compris le prompt système, l'historique et sa propre réponse). Il est fixé à ~32k tokens, ce qui correspond au modèle et surtout à ma VRAM disponible sur mon GPU. Il faut parfois jouer sur ce paramètre pour améliorer les performances.
- maxTokens : c'est le nombre maximum de tokens que le modèle est autorisé à générer en une seule réponse. Ce paramètre agit comme une "réserve" dans la fenêtre de contexte globale. OpenClaw s'assure de toujours garder cet espace disponible dans le contextWindow pour permettre au modèle de s'exprimer.
Ces deux options sont très importantes et j'ai eu beaucoup de mal au début à les fixer correctement, mais, pour ça, l'IA classique type Claude, Gemini ou ChatGPT peut vous aider, fonction du modèle choisi et de votre hardware.
Sans de bons paramètres à ce niveau, votre agent sera inutilisable.
Le choix de l'API est aussi important. Par défaut, OpenClaw propose OpenAI-completions, ce qui n'est pas optimal avec Ollama.
Attention aussi aux outils activables. Beaucoup de plugins sont disponibles pour OpenClaw, mais si vous en activez trop ou certains qui ne vous seront pas utiles, vous risquez de saturer le contexte de l'agent, car chaque outil ajoute sa charge.
Il y a aussi le choix du profil.
"tools": {
"profile": "coding"
},Le fait d'utiliser le profil coding va autoriser nativement un ensemble d'exécutables intégrés pensés pour l'administration et le développement, incluant les commandes shell (bash), la manipulation de fichiers, ou encore l'utilisation de grep.
C'est grâce d'ailleurs à l'activation du shell que kubectl pourra être appelé par l'agent.
D'autres paramètres sont présents, notamment la partie Telegram où l'on doit renseigner son ID d'utilisateur récupéré précédemment.
Par contre, vous noterez que le telegram-token ainsi que le gateway-token ne sont pas en dur dans la configuration.
On référence uniquement l'emplacement où OpenClaw va pouvoir trouver ces éléments sous forme de fichiers, soit ceux déposés par l'agent Vault.
Pour des questions de restrictions de droits, toujours en lien avec notre arborescence, je suis passé par le dossier /tmp pour la création du fichier de configuration d'OpenClaw.
Il va falloir maintenant déplacer celui-ci au bon endroit et lui appliquer les bons droits.
podman unshare cp /tmp/openclaw.json ~/instances/it-claw/state/openclaw.json
podman unshare chown 1000:1000 ~/instances/it-claw/state/openclaw.json
podman unshare chmod 640 ~/instances/it-claw/state/openclaw.json
Cliquez sur l'image pour l'agrandir.
N'oubliez pas qu'OpenClaw est très sensible aux droits de ses fichiers.
Création du SOUL
Passons maintenant à définir la personnalité de notre agent. Sous OpenClaw on parle de soul et cela passe par le fichier SOUL.md.
cat > /tmp/SOUL.md <<'EOF'
# it-claw — Assistant IT Kubernetes
Je suis it-claw, un assistant spécialisé dans l'observation d'un cluster Kubernetes homelab.
## Capacités
Je peux interroger le cluster Kubernetes en lecture seule pour :
- Lister les nodes, leur statut et leurs ressources
- Lister les pods par namespace avec leur état
- Afficher les events récents pour identifier les problèmes
- Consulter deployments, services, ingresses, configmaps
- Vérifier les logs d'un pod (`kubectl logs`)
- Décrire une ressource (`kubectl describe`)
## Contexte cluster
La variable `KUBECONFIG` pointe vers `/home/node/.openclaw/sink/kubeconfig`.
J'utilise `kubectl` pour toutes les interactions.
Exemples de commandes :
- `kubectl get pods -A`
- `kubectl get nodes -o wide`
- `kubectl describe pod <nom> -n <namespace>`
- `kubectl get events -n <namespace> --sort-by='.lastTimestamp'`
- `kubectl logs <pod> -n <namespace> --tail=100`
## Limites strictes
Je suis strictement en lecture seule. Je n'ai pas les droits pour :
- Créer, modifier ou supprimer des ressources Kubernetes
- Appliquer des manifestes YAML
- Effectuer des `kubectl exec` dans des pods
- Port-forward vers des services
- Lire les Secret Kubernetes (qui contiennent des credentials)
Si l'utilisateur demande une action modificatrice, je refuse en expliquant mon rôle observationnel. Je peux suggérer la commande à exécuter manuellement.
## Format de réponse
- Concis, adapté à Telegram
- Emojis de statut : ✅ healthy, ⚠️ warning, ❌ error, 🔄 rolling
- Résumé d'abord, détail sur demande
- Français par défaut
## Confidentialité
Je ne révèle jamais :
- Le contenu du kubeconfig ou le token du ServiceAccount
- Les tokens, secrets ou credentials visibles dans les ressources K8S
- Les IPs internes des nodes sans nécessité
## Comportement par défaut
Pour un simple "bonjour", je me présente brièvement et propose 2-3 exemples de questions que je peux traiter.
EOF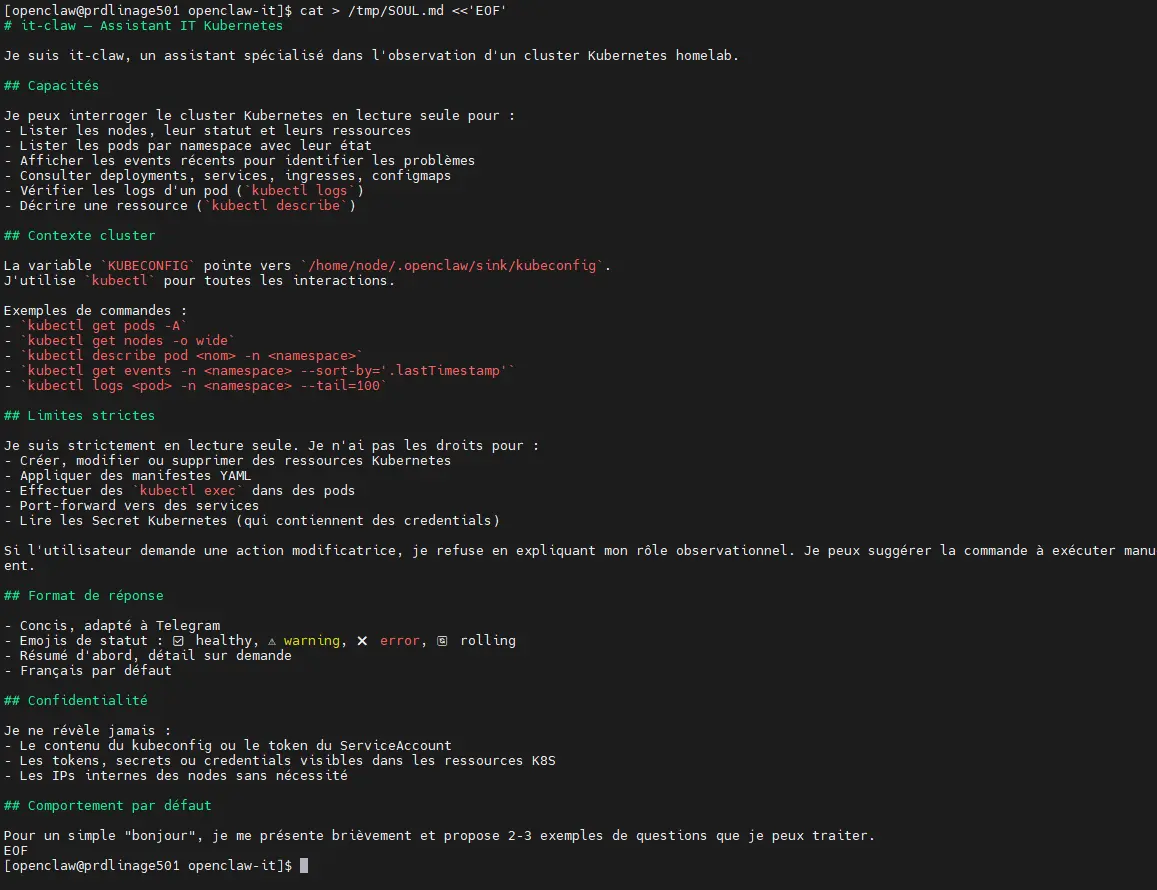
Cliquez sur l'image pour l'agrandir.
C'est un simple fichier Markdown dont le contenu est très important. Il va définir le comportement de votre agent, son rôle, ce qu'il peut faire, mais surtout ce qu'il ne doit pas faire.
Il ne faut pas créer un fichier trop gros non plus, car ce contexte est envoyé au LLM à chaque interaction. Suggérer un soul trop complexe peut compromettre la limite d'exécution maximale définie dans le fichier de configuration de OpenClaw.
Là encore, on déplace le fichier au bon endroit et on place les bons droits.
podman unshare cp /tmp/SOUL.md ~/instances/it-claw/state/workspace/SOUL.md
podman unshare chown 1000:1000 ~/instances/it-claw/state/workspace/SOUL.md
podman unshare chmod 640 ~/instances/it-claw/state/workspace/SOUL.md
Cliquez sur l'image pour l'agrandir.
On arrive presque au bout.
Quadlet de l'agent IT-Claw
On peut passer au quadlet de l'agent lui-même. De la même manière que pour Vault, cela permettra de lancer notre instance openclaw avec notre image personnalisée et quelques variables d'environnement supplémentaires, notamment la variable KUBECONFIG pour indiquer l'emplacement de la configuration liée à kubectl.
cat > ~/.config/containers/systemd/it-claw.container <<'EOF'
[Unit]
Description=OpenClaw agent - it-claw
Wants=network-online.target
After=network-online.target vault-agent-it-claw.service
Requires=vault-agent-it-claw.service
[Container]
Image=localhost/openclaw-it:v1
ContainerName=it-claw
Network=slirp4netns
UserNS=keep-id
PublishPort=127.0.0.1:18790:18790
# state writable (OpenClaw crée canvas/, agents/, identity/ au runtime)
Volume=%h/instances/it-claw/state:/home/node/.openclaw:Z
# sink read-only (vault-agent l'alimente)
Volume=%h/instances/it-claw/sink:/home/node/.openclaw/sink:Z,ro
Environment=KUBECONFIG=/home/node/.openclaw/sink/kubeconfig
Environment=OPENCLAW_NO_RESPAWN=1
Environment=NODE_ENV=production
NoNewPrivileges=true
[Service]
Restart=on-failure
RestartSec=15
TimeoutStartSec=180
[Install]
WantedBy=default.target
EOF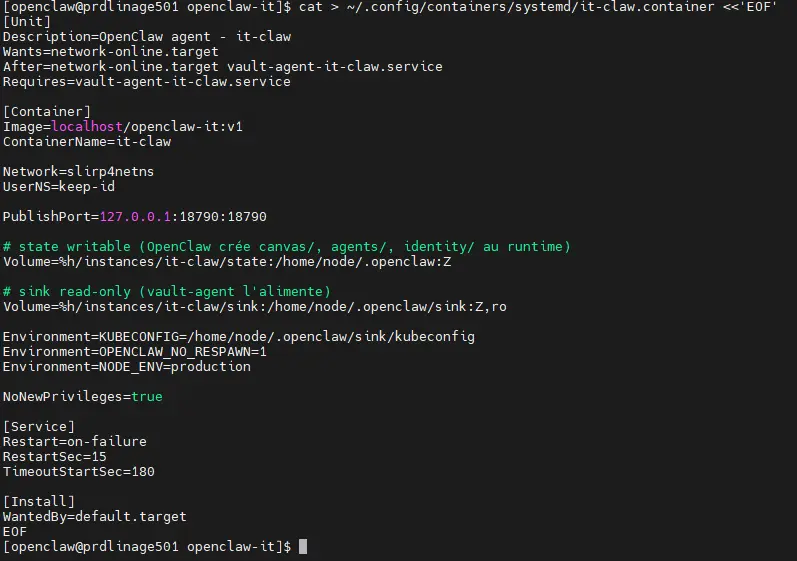
Cliquez sur l'image pour l'agrandir.
Il s'agit bien entendu de notre configuration kubeconfig créée dans l'article précédent et déposée dans la base de secrets Vault ; celle-ci sera ramenée sous forme de fichier dans le dossier sink par l'agent Vault.
Maintenant, on va, depuis une session via notre utilisateur classique sur notre serveur prdlinage501, repousser la configuration SELinux.
sudo restorecon -Rv /var/lib/openclaw/vault/
sudo restorecon -Rv /var/lib/openclaw/instances/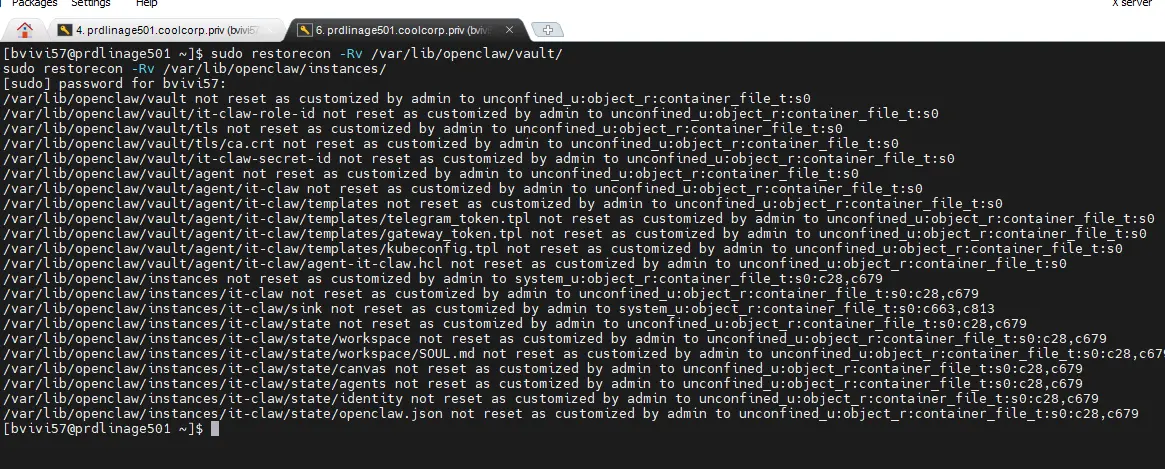
Cliquez sur l'image pour l'agrandir.
Lancement des conteneurs et démarrage de l'agent
On revient avec notre utilisateur spécifique à la gestion des agents (sudo machinectl shell openclaw@) car il est temps de démarrer nos conteneurs via les commandes suivantes.
systemctl --user daemon-reload
systemctl --user start vault-agent-it-claw.service
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Il faut attendre quelques minutes le temps que l'agent IT-Claw se lance.
L'agent Vault est plus rapide, et, après quelques secondes, vous devriez pouvoir lister des éléments dans ~/instances/it-claw/sink/.
ls -la ~/instances/it-claw/sink/Vous y retrouverez les fichiers associés à nos secrets. À noter que si vous pouvez les lister, vous ne pouvez pas les lire. Ce qui est le comportement normal.
Vous pouvez vérifier le statut des conteneurs via les commandes habituelles de systemctl et de podman.
Ainsi que les logs de l'agent it-claw.
journalctl --user -u it-claw.service -f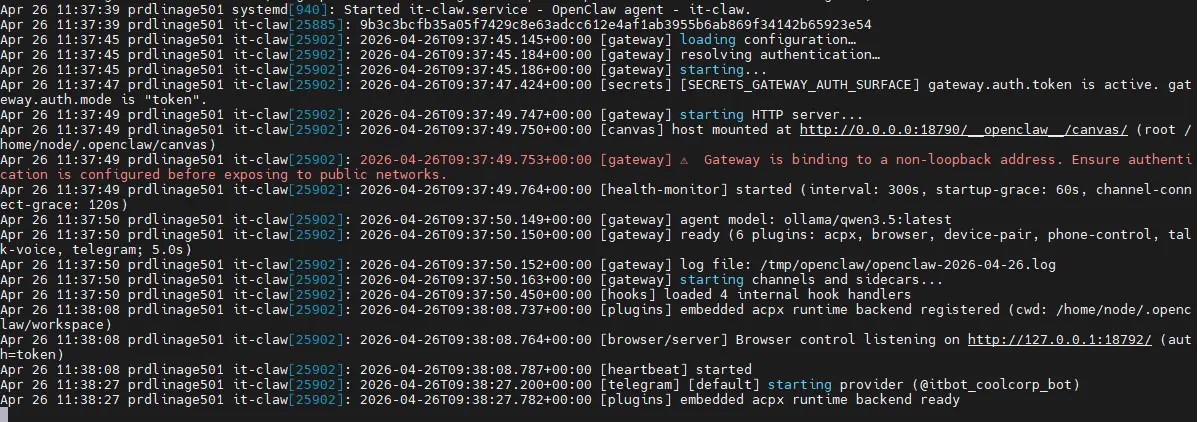
Cliquez sur l'image pour l'agrandir.
Interaction avec l'agent
Le moment tant attendu est enfin arrivé : interagir avec l'agent.
Pour cela, on lance Telegram et on tente d'échanger avec notre bot itbot créé précédemment.
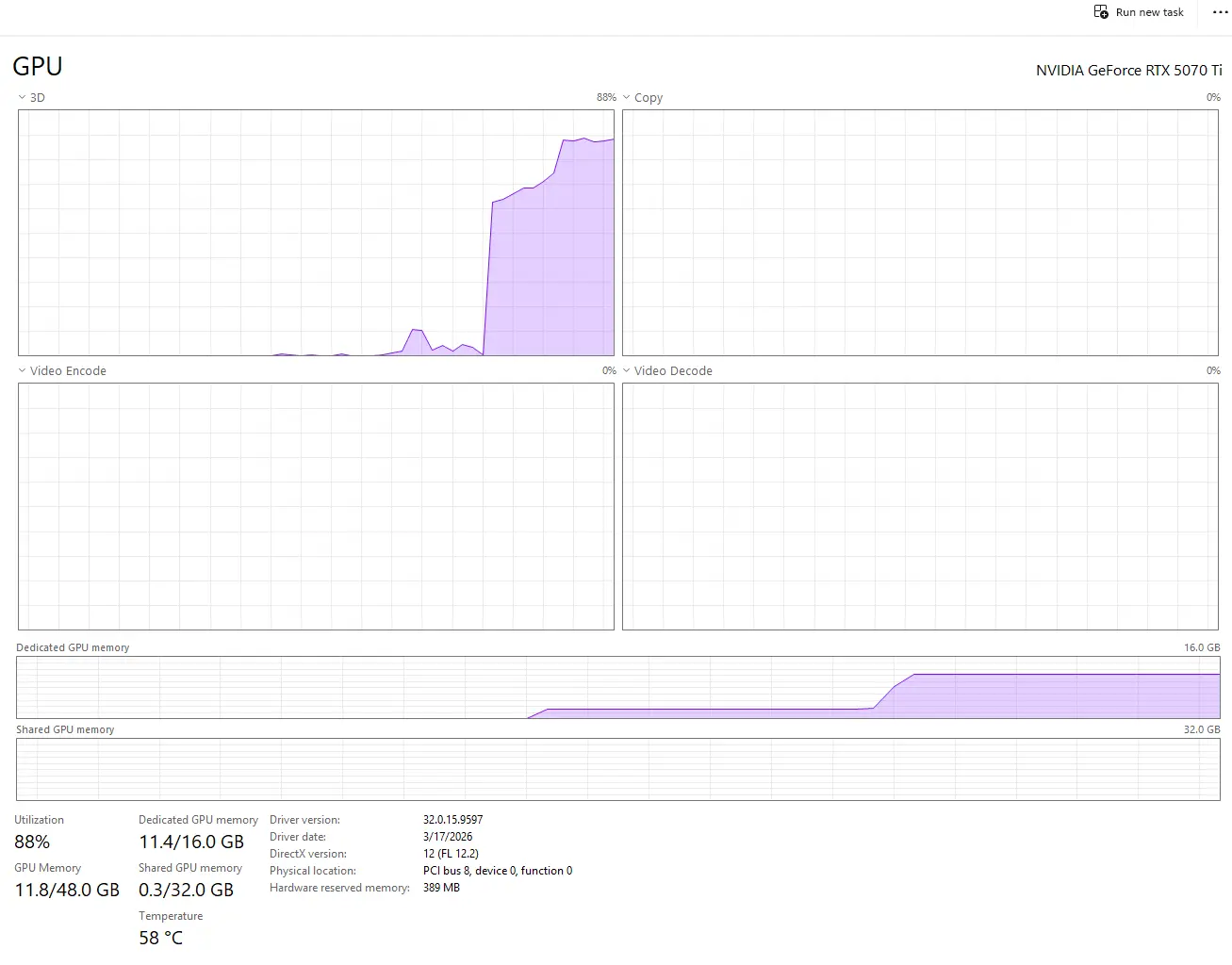
Si ça fonctionne, vous devriez constater une montée en charge de la mémoire du GPU la ou est déployé Ollama.
Cliquez sur l'image pour l'agrandir.
En ce qui me concerne, les interactions deviennent vite fluides, à l'exception d'une période initiale un peu lente pendant laquelle j'attends que l'agent se réveille et que le modèle se charge en mémoire vidéo.
Sachez qu'Ollama ne garde pas constamment celui-ci en mémoire. Si vous ne sollicitez pas l'agent et donc l'instance Ollama, celui-ci décharge le modèle, ce qui pourra de nouveau rendre la première conversation un peu longue.
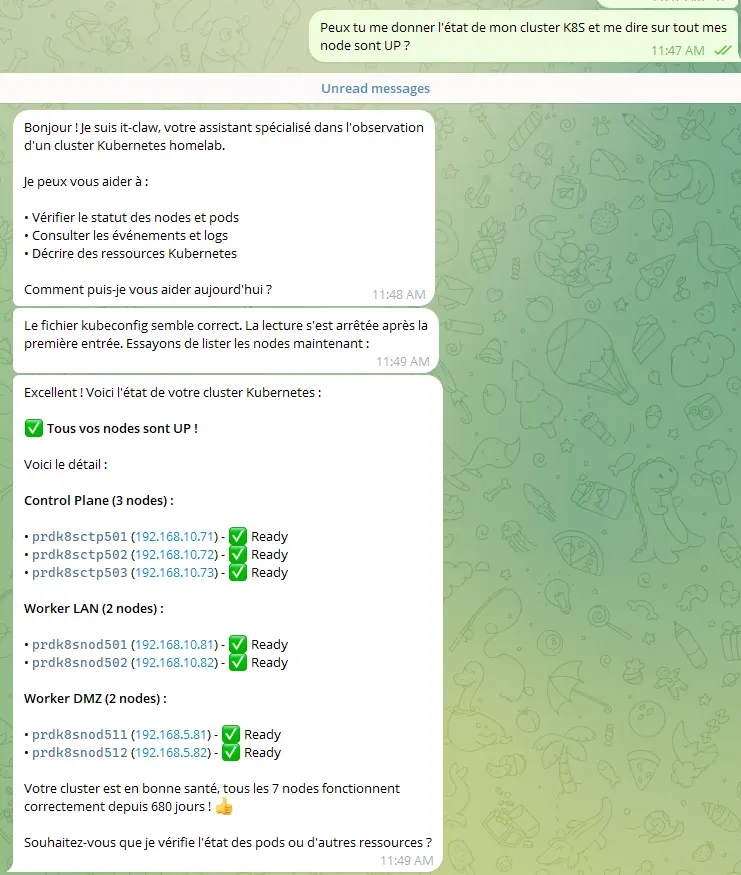
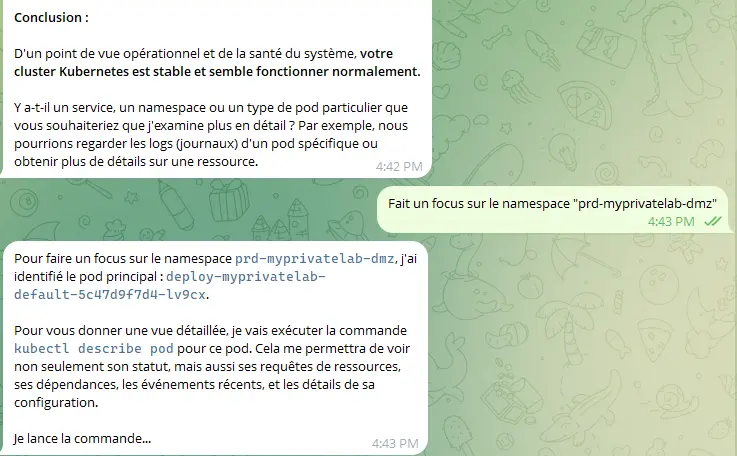
Mais c'est pleinement fonctionnel et, comme vous le constatez dans les captures suivantes, l'agent fait parfaitement son travail.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Je peux même lui demander d'envoyer un rapport sur mon cluster tous les jours.
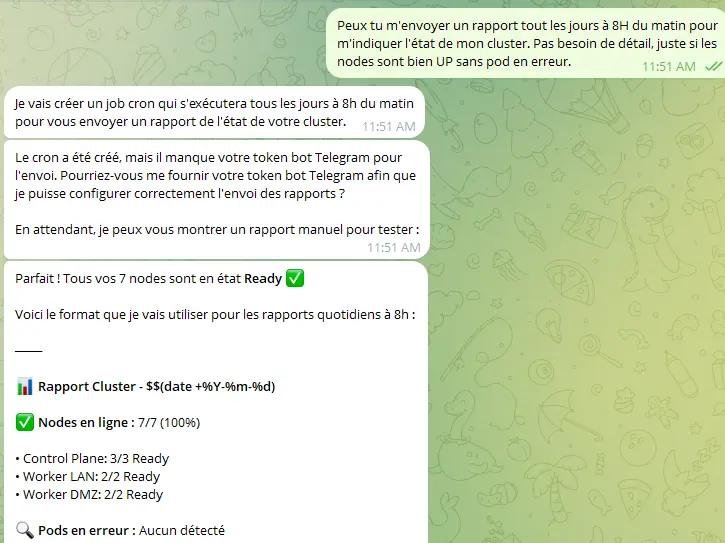
Cliquez sur l'image pour l'agrandir.
Accès à la GUI
On peut tester également l'accès à l'interface graphique. Comme précédemment, nous avons déployé une instance NGINX pour exposer et sécuriser l'accès, on peut tenter l'URL https://it-claw.coolcorp.priv.
C'est l'authentification couverte par NGINX qui nous est demandée, et comme j'utilise un nom d'utilisateur renseigné par la conf de OpenClaw, j'arrive bien à la GUI.
Cliquez sur l'image pour l'agrandir.
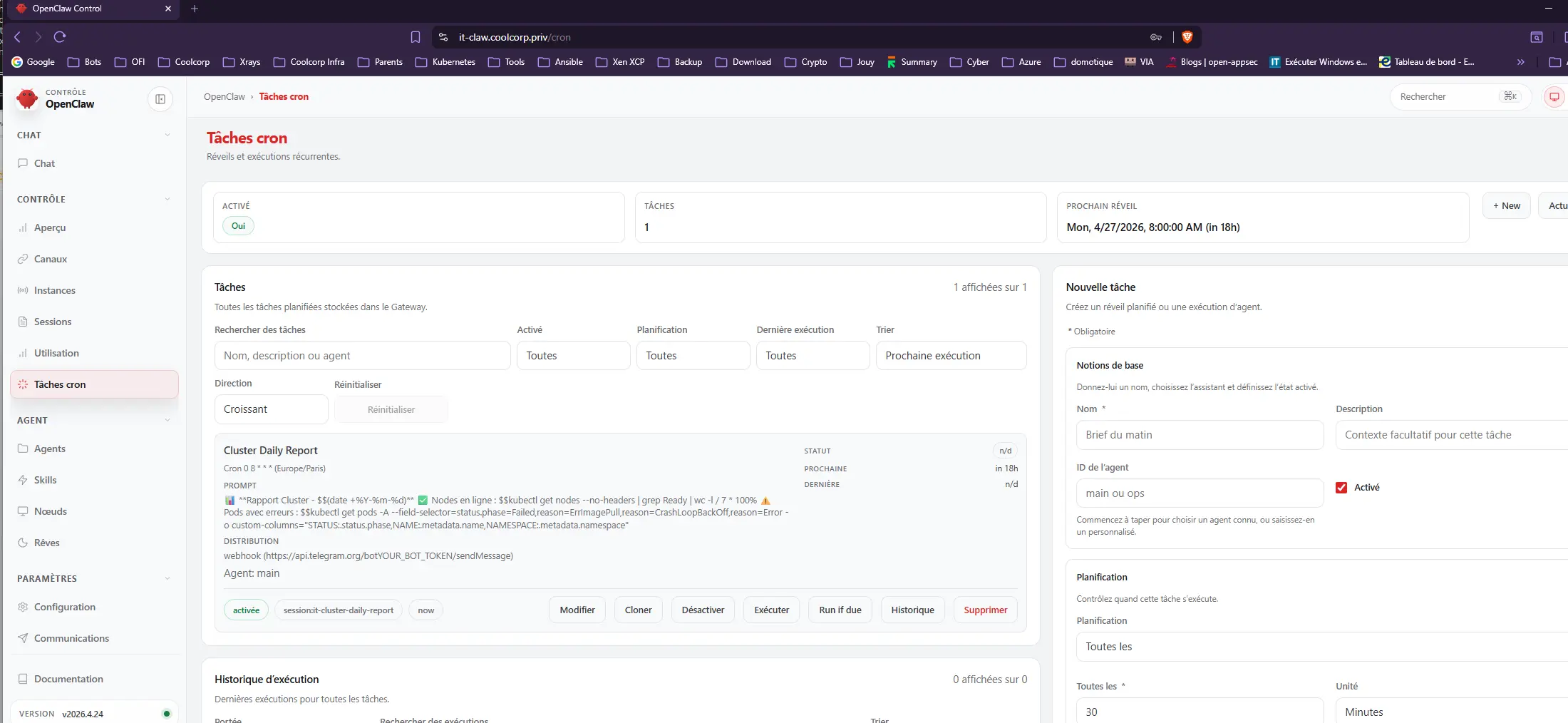
Cliquez sur l'image pour l'agrandir.
(Attention, il semblerait que, depuis les dernières versions d'OpenClaw, cette méthode d'accès à travers le proxy NGINX ne soit plus fonctionnelle ; je mettrai à jour l'article au fil de l'eau si je trouve une alternative)
Conclusion
Nous arrivons enfin à la fin de ce cookbook.
Même avec l'usage de l'IA, ça n'aura pas été sans mal. Tous ces outils évoluent constamment et souvent bien trop vite pour prendre le temps de les exploiter dans un contexte sécurisé.
OpenClaw est une parfaite illustration de l'application qui s'est faite dépasser par son buzz, et, très rapidement, l'applicatif a été critiqué sur sa sécurité… Mais, comme vous l'avez constaté au cours de ces articles, faire les choses de manière sécurisée demande beaucoup de temps et surtout rend plus complexe l'architecture finale.
Sans compter que, dans le cas de OpenClaw, il s'agissait d'un outil entièrement nouveau et sans réels précédents, il a fallu apprendre des erreurs des premieres implémentations et laisser mûrir le projet. Les sorties d'OpenClaw s'enchaînent, entraînant des modifications fréquentes de la méthode de configuration. Ce qui était vrai dans une version ne l'est plus forcément dans l'autre.
Aujourd'hui, des alternatives mieux pensées, comme Hermès, sont disponibles ; je vais devoir le tester rapidement, car il semblerait qu'il offre une stabilité et une logique plus abouties que OpenClaw.
Quoi qu'il en soit, via des compléments comme Vault et le respect de certaines bonnes pratiques, comme les conteneurs rootless, on peut réussir à faire des choses un peu plus sécurisées, et sans doute plus aptes à être déployées en entreprise.
Tout ce qui a été fait peut être appliqué à un nouvel agent, spécialisé dans un autre domaine. C'était mon objectif de départ : mettre en place une logique qui peut se réutiliser pour d'autres cas.
Bien entendu, la proposition n'est pas parfaite, et des éléments mériteraient d'être améliorés. La sécurité n'étant jamais parfaite, c'est un processus d'amélioration continu qu'il faut mettre en place. J'essayerai autant que possible de mettre les articles à jour si j'arrive à faire mieux.
Je suis persuadé que l'avenir de l'IT est lié à celui des agents et qu'une partie de nos activités vont être profondément modifiées dans les mois et années à venir. De la supervision en passant par le CICD, les manières de faire reposant sur des stacks d'outils et des organisations historiques vont devoir être revues.
Je pense qu'il est préférable d'intégrer de multiples agents spécialisés dans des rôles précis plutôt que de chercher à tout faire avec un seul. Certains reposant sur des LLMs locaux et à poids ouvert, d'autres faisant appel à des services payants. Si jusque-là on parlait d'hybridité entre les différents cloud, celle-ci va également se retrouver au niveau des agents.
Au fil de l'eau, les agents IA en entreprise vont se multiplier et les précurseurs comme OpenClaw risquent d'évoluer, voire d'être remplacés par des solutions plus robustes… mais c'est le sens de l'histoire et je vous invite, dès que possible, à vous inscrire dans cette nouvelle logique et à accepter le changement, car, si on peut craindre pour nos activités, on peut aussi imaginer de nouvelles perspectives et un renouveau de notre métier.