Étape 6 : Initialisation du cluster
Introduction
Il est temps maintenant de lancer l’initialisation du cluster. Avant de démarrer, il est important de refaire le point sur la démarche et les actions déjà entreprises. La lecture des articles précédents de la section Kubernetes Cook Book (Onprem) est fortement conseillée pour être à l’aise sur la suite des opérations.
Il a d’abord fallu construire un environnement de travail, afin d’opérer une infrastructure virtuelle.
L’idée était de limiter les besoins tiers et d’exploiter principalement son poste de travail pour interagir avec la plateforme cible.
Une démarche d’automatisation et d’industrialisation minimale a été retenue via les outils du marché, avec:
- une première phase orientée Infrastructure As Code via OpenTofu (Terraform)
- une seconde phase orientée configuration avec Ansible
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
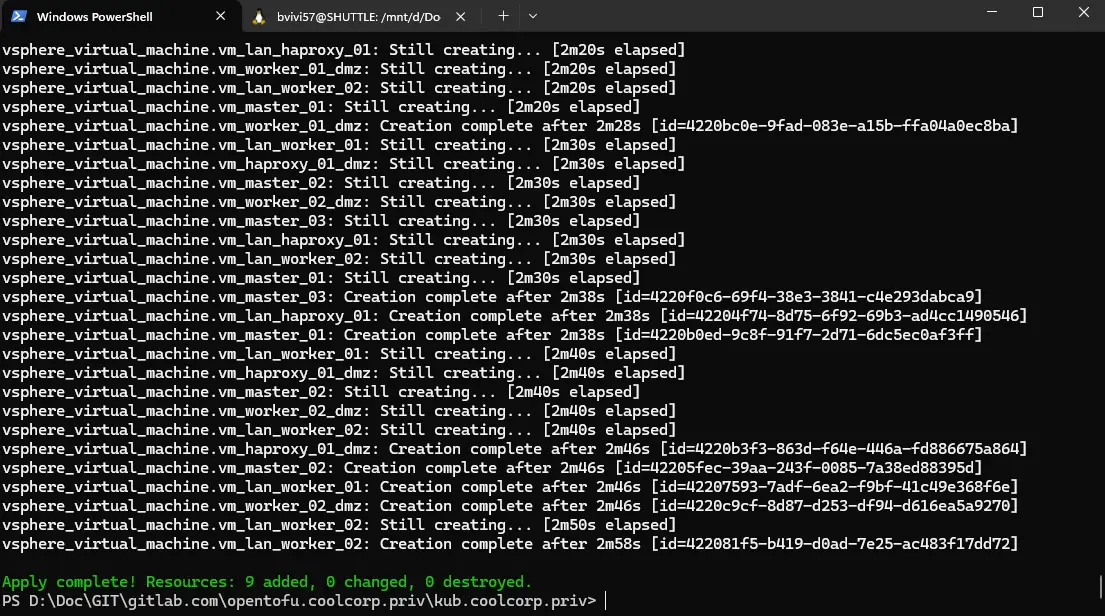
Une fois l’outillage en place, on n’a fixé une cible d’architecture K8S, en définissant le nombre de nodes nécessaires ainsi que leur rôle respectif.
En se basant sur un template de VM, il a été possible de déployer, via OpenTofu, l’ensemble des serveurs associés à cette architecture cible.
C’est poursuivi l’exécution d’un playbook Ansible, décrit dans différentes étapes. Il a ainsi été possible d’installer tous les prérequis nécessaires sur chaque node et de préparer l’ensemble des fichiers de configurations nécessaire au fonctionnement de Kubernetes.
Lancement de kubeadm
Comme déjà évoqué, c’est kubeadm qui a été retenu pour initialiser le cluster. C’est la méthode par défaut et la plus évidente pour un déploiement Vanilla de kubernetes.
Kubeadm nécessite d’être exécuté en tant que root. On va donc se positionner dans ce contexte, sur le premier control plane, à savoir dans l’architecture cible prdk8sctp501.
On va se positionner dans /etc/kubernetes.
Cliquez sur l'image pour l'agrandir.
Puisque c’est ici que le playbook Ansible a copié le fichier kubeadm.conf dont voici le contenu final:
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: 1.29.4
networking:
podSubnet: "10.11.0.0/16"
serviceSubnet: "10.12.0.0/16"
controlPlaneEndpoint: "kub.coolcorp.priv:6443"
clusterName: "kub"
controllerManager:
extraArgs:
cloud-provider: external
apiServer:
certSANs:
- 192.168.10.91
- kub.coolcorp.priv
Ce qu’il est important de retenir c’est:
- La version de l’API que va utiliser kubeadm : kubeadm.k8s.io/v1beta3
- la version de Kubernetes qui va être déployée : 1.29.4
- le réseau qui va être dédié aux pods: 10.11.0.0/16
- le réseau qui va être dédié aux services : 10.12.0.0/16
- l’URL qui va être associée à l’API (et pour laquelle un certificat interne va être généré) : kub.coolcorp.priv
N’hésitez pas à lire cet article pour une meilleure compréhension de cette configuration.
Importance du loadblancer en LAN
Avant d’aller plus loin, il est capital que le serveur HAproxy jouant le rôle de load balancer dans le LAN soit opérationnel: prdk8snlb501 dans l’architecture cible.
Situé en amont du cluster et chargé de répartir la charge de l’accès à l’API sur les trois control plane, il doit être en ligne, répondre aux requêtes et rediriger les flux.
Lorsqu’on va solliciter kubeadm, celui-ci va s’appuyer sur le nom DNS du cluster et son IP (192.168.10.91) qui sont associés au serveur HAproxy et non directement au control plane.
Il faut donc que la résolution soit correcte et pointe bien vers le load balancer. Le service HAproxy doit tourner et sa configuration opérationnelle pour renvoyer les requêtes sur le port 6443 vers l’un ou l’autre des control plane.
Le détail de ce paramétrage est disponible ici.
Exécution sur le premier control plane
Si tous les voyants sont au vert à ce niveau, on va donc pouvoir lancer le déploiement du premier control plane du cluster (dans l'architecture cible le premier control plane est prdk8sctp501) avec la commande:
kubeadm init --config kubeadm.conf --upload-certs --v=5 --skip-phases=addon/kube-proxy.
--config kubeadm.conf: Cette instruction permet à kubeadm de lancer la phase d’init en utilisant les paramètres fournis dans le fichier kubeadm.conf.
–v=5: autorise une sortie plus verbeuse pour aider au diagnostic si nécessaire.
--skip-phases=addon/kube-proxy: permet de ne pas ajouter l’addon kube-proxy habituellement installé par défaut. Ce point est propre à l’usage qu’on n’aura par la suite du driver réseau Cilium. Dans notre cas, Cilium va s’occuper des fonctions habituellement prises par kube-proxy.Même si Cilium peut s’utiliser avec kube-proxy, cette méthode permet de tirer pleinement parti des fonctionnalités de Cilium.
Kubernetes repose sur des composants, qui eux même s’exécutent pour la plupart sous forme de conteneurs.
L’installation peut prendre un peu de temps, généralement une dizaine de minutes. Durant ce laps de temps, Kubeadm va récupérer les images de chaque conteneur et générer leurs configurations associées.
Ces configurations vont toute se retrouver dans /etc/kubernetes/manifests. Ils pourront ainsi être utilisés par l’agent kubelet, qui rappelez-vous, a été installé en amont via Ansible.
L’agent Kubelet, parmi toutes ces fonctions, à la charge de démarrer tous les conteneurs décrit dans ce dossier et dont l’image a été récupérée par kubeadm. Ce répertoire est sans cesse surveillé par l’agent kubelet, et tout changement à ce niveau sera répercuté sur le cluster.
C’est comme ça que les composants de bases du cluster peuvent démarrer sans interaction externe.
Kubeadm va d’ailleurs s’assurer que ces composants soient correctement lancés et accessibles, notamment l’API server (d’où l’importance du bon fonctionnement de HAproxy en amont).
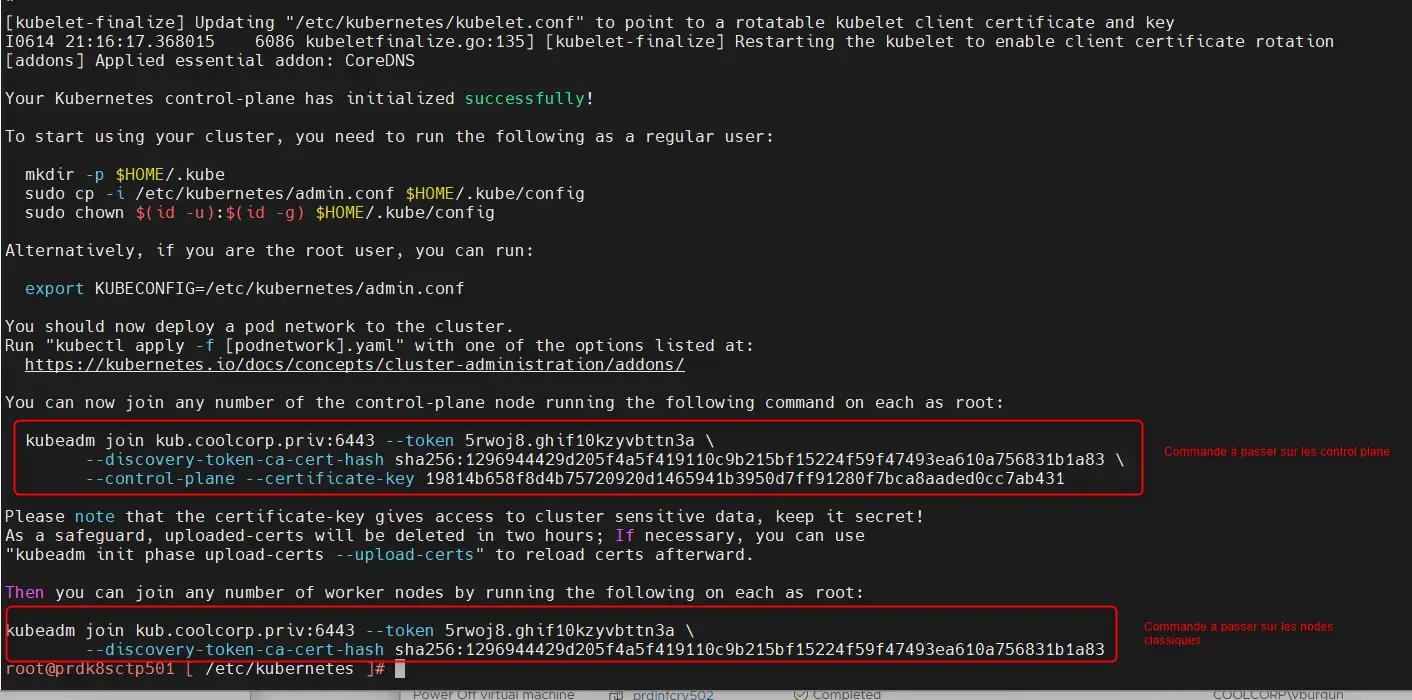
Si tout se passe correctement, on obtient en fin d’exécution les commandes nécessaires à jouer sur les autres nodes afin qu’ils puissent rejoindre le cluster.
Cliquez sur l'image pour l'agrandir.
Exécution sur les autres control plane
Attention, la commande n’est pas la même, fonction que l’on souhaite ajouter un control plane ou un simple nœud d’exécution.
De même ces commandes ont une durée de vie d’une heure. Passer ce délai, les token générés expirent et il faudra relancer des demandes d’association sur le control plane primaire pour obtenir de nouvelles instructions.
On poursuit sur les deux autres control plane d’abord (prdk8sctp502 / prdk8sctp503). Pour cela rien de compliqué, on se connecte en root sur chacun d’eux et on copie la commande relevée sur le premier control plane. Plus besoin de fichier de configuration, kubeadm va directement chercher à contacter le premier nœud et générer la configuration nécessaire.
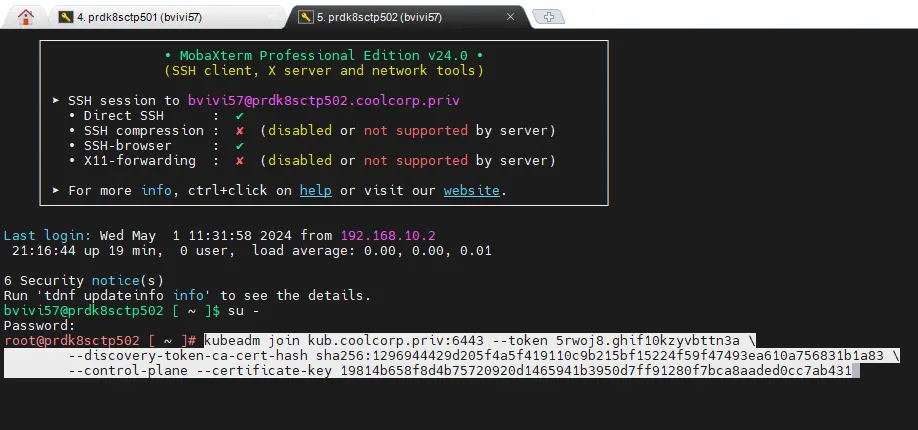
Cliquez sur l'image pour l'agrandir.
Il est fortement conseillé de procéder node par node, et d’attendre le succès de l’opération avant de passer au serveur suivant.
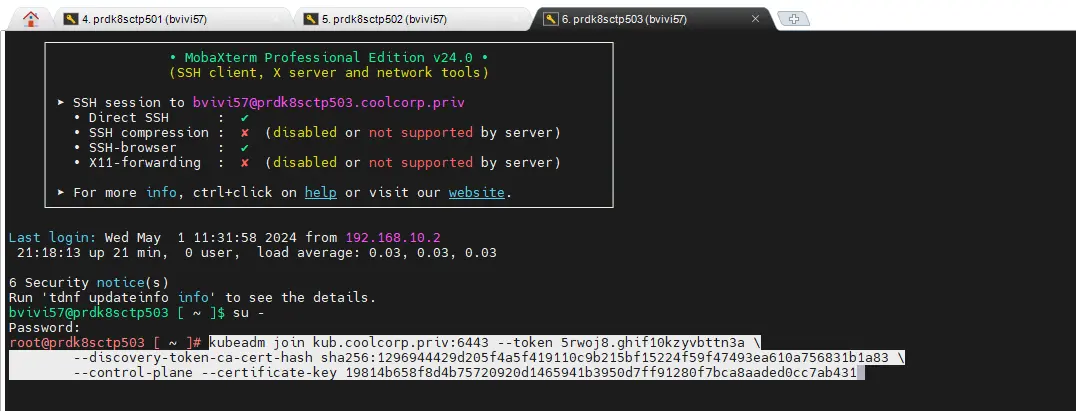
Cliquez sur l'image pour l'agrandir.
Durant ces étapes, les nouveaux control plane vont s’ajouter au cluster et s’inscrire comme participant au consensus notamment pour la partie base de données clef/valeur etcd.
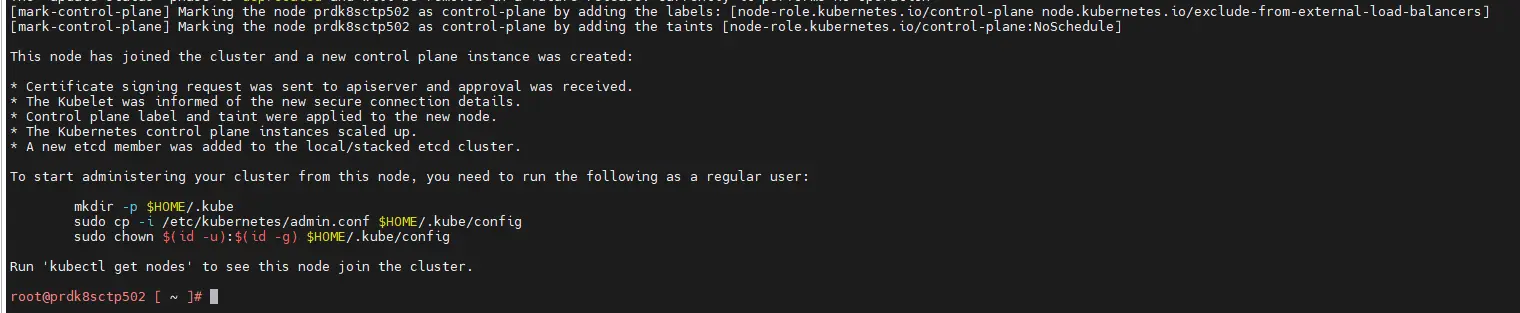
Cliquez sur l'image pour l'agrandir.
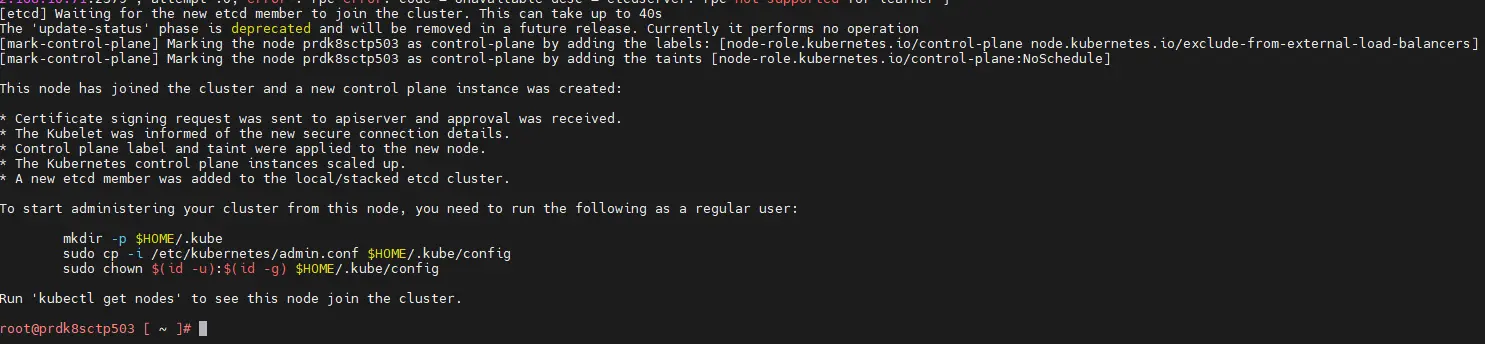
Cliquez sur l'image pour l'agrandir.
Toute la configuration d’un cluster K8S est maintenue dans cette base. Elle devient donc critique, car chaque action que vous opérez par la suite donnera lieu à une mise à jour de cette base qui contiendra la cible souhaitée concernant l’exécution des pods.
K8S n’aura de cesse de comparer le contenu de cette base avec le statut actuel du cluster afin de s’assurer en permanence que son contenu correspond à ce qui est exécuté sur le cluster.
C’est d’ailleurs à cause de etcd qu’il faut un minimum de 3 control plane pour assurer un service HA, car c’est etcd, qui via le protocole de consensus RAFT, impose ce nombre minimal.
À noter qu’il est possible d’externaliser la base etcd à l’extérieur du cluster afin de monter une architecture indépendante. On peut aussi utiliser une autre base que etcd. L’important est que l’API serveur puisse communiquer avec cette base (et être compatible).
Nous concernant on va rester classique et laissé etcd comme un composant interne au cluster. On s’assurera de sa sauvegarde dans un article dédié.
Une fois les trois control plane associés, on poursuit avec les nodes classiques.
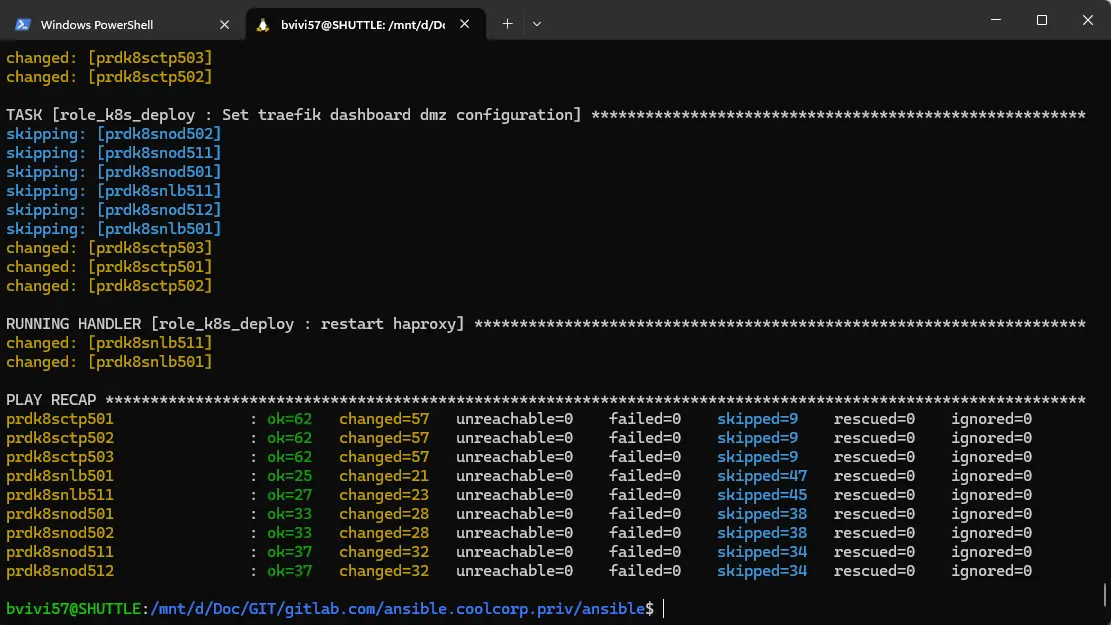
Exécution sur les nodes classiques
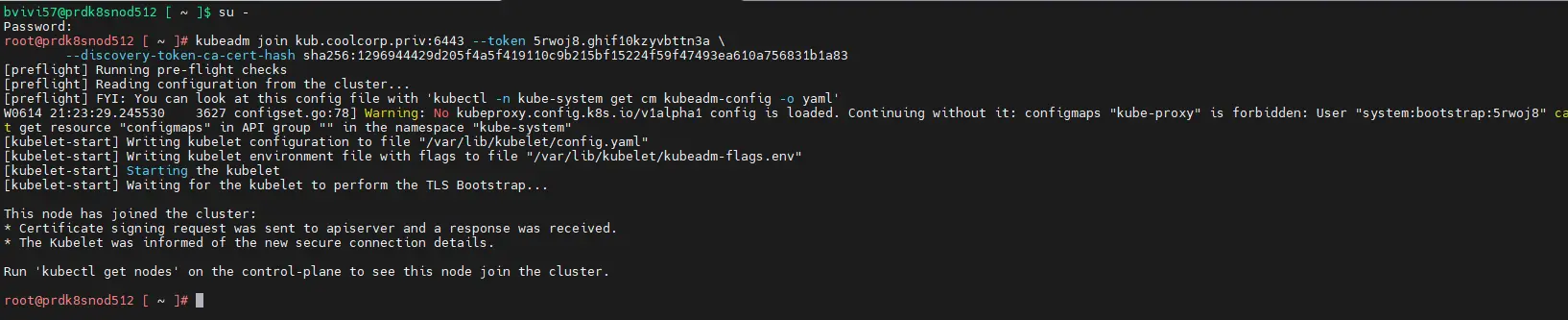
La commande est un peu différente et beaucoup plus rapide. Il suffit de se connecter en root sur chaque node (prdk8snod501(worker LAN) / prdk8snod502(worker LAN) / prdk8snod511(worker DMZ) / prdk8snod511(worker DMZ)) et de copier la sortie dédiée au worker issu de l’initialisation du cluster sur le premier control plane.
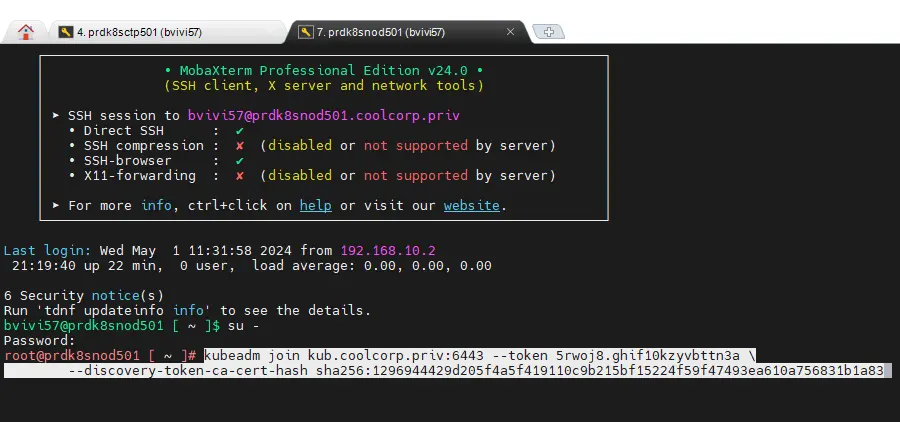
Cliquez sur l'image pour l'agrandir.
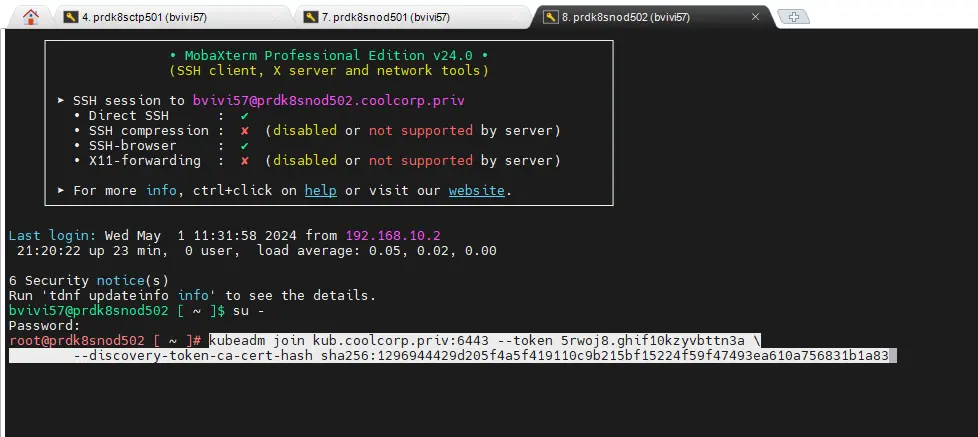
Cliquez sur l'image pour l'agrandir.
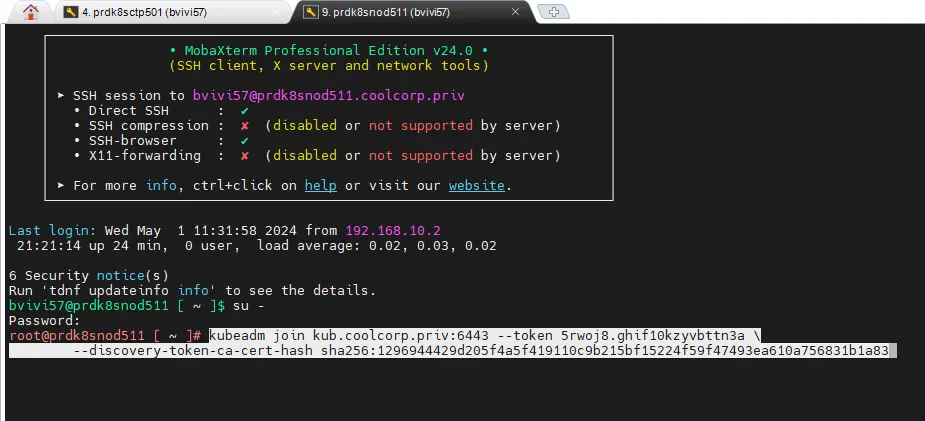
Cliquez sur l'image pour l'agrandir.
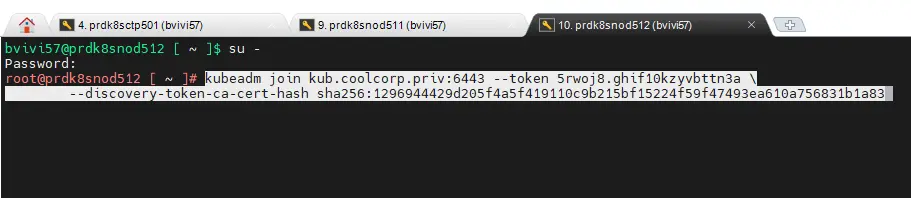
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
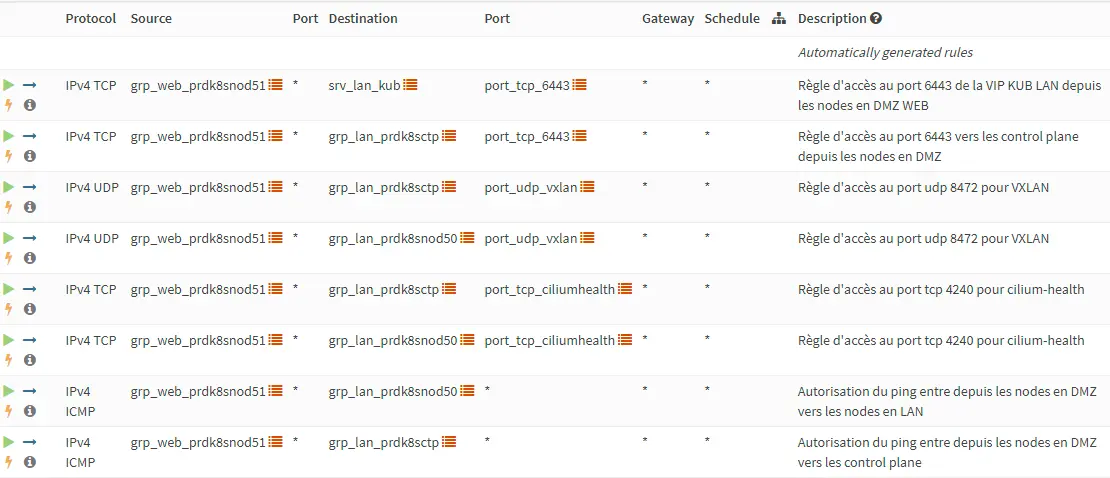
La seule subtilité et de s’assurer de la bonne communication entre les nodes. C’est notamment important pour les nœuds en DMZ. Dans mon cas je transite par un firewall intermédiaire (OPNsense) et il est capital qu'un certain nombre de flux soit ouvert.
Voici une extraction de la configuration de mon firewall entre la DMZ et le LAN de mon côté.
Cliquez sur l'image pour l'agrandir.
A noter qu'une matrice des flux vous est présenté au sein de cet article (presentation des règles iptables positionnées par Ansible).
Récupération du fichier de config pour kubectl
Arrivé à ce stade, tous les serveurs ont rejoint le cluster, mais il reste à récupérer le fichier de configuration kubectl généré durant l’installation sur le premier control plane.
Pour rappel, kubectl est la CLI de base permettant de communiquer avec le cluster et de le piloter.
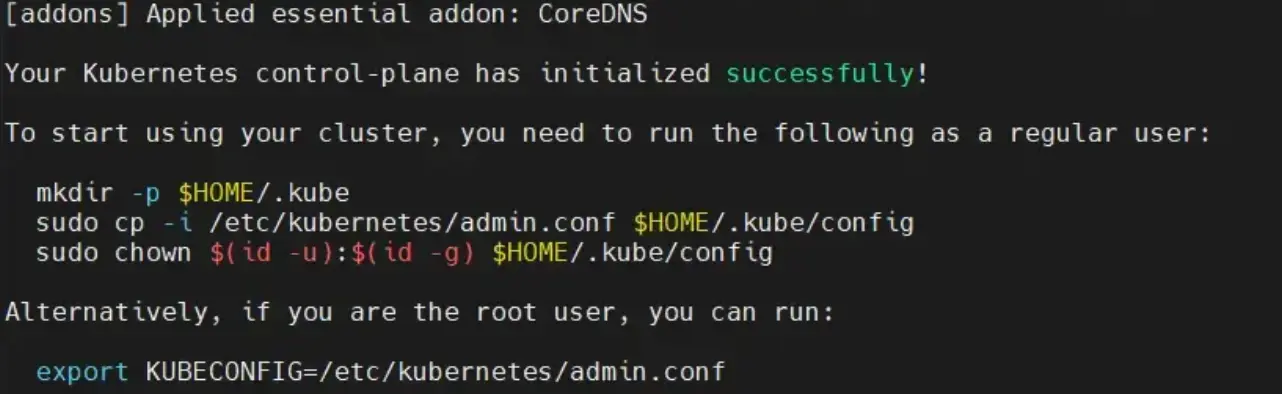
Lorsque kubeadm initie le cluster, il créer également le fichier admin.conf qui n’est autre que le fichier permettant la connexion au cluster en tant qu’administrateur. On y’ retrouvera l’URL de l’API et surtout les identifiants de connexion sous forme de clef privée/clef publique permettant d’interagir avec le cluster en tant qu’admin.
C’est un fichier extrêmement critique, qu’il ne faudrait jamais sortir du serveur. Il faudra privilégier la génération de nouveaux fichiers propres à une identité donnée, avec des droits spécifiques pour être utilisé sur d’autres sources de connexion, comme un poste de travail.
Mais en l’état et pour poursuivre l’installation du cluster, il va nous falloir récupérer ce fichier et l’appliquer à notre utilisateur courant, pour démarrer la suite.
La sortie de kubeadm en fin d'installation sur chaque control plane vous donne d’ailleurs les commandes associées. On peut se concentrer uniquement sur le premier control plane (à faire en root)
Cliquez sur l'image pour l'agrandir.
Étant donné que mon user local est « bvivi57 », dans mon exemple, je dois appliquer les lignes suivantes.
cp -i /etc/kubernetes/admin.conf /home/bvivi57/.kube/config
chown -R bvivi57 /home/bvivi57/.kube/

Cliquez sur l'image pour l'agrandir.
À partir de là, vous devriez:
- ne plus avoir à vous connecter sur les autres nodes en dehors du premier control plane.
- ne plus avoir à vous connecter en root en dehors des opérations d’update.
On revient donc à l’utilisateur courant.
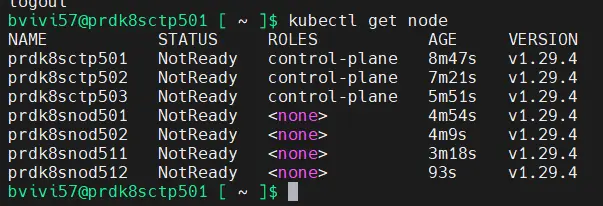
On va pouvoir enfin taper notre première commande kubectl, pour vérifier le statut des nodes
kubectl get node
Cliquez sur l'image pour l'agrandir.
On a bien tous les nœuds, mais ils sont tous en NotReady. C’est normal. Pour rappel, K8S est une plateforme modulaire qui vous laisse un grand choix dans l’architecture à déployer. Avec kubeadm, nous avons déployé uniquement les composants de bases, mais ils nous manquent la couche réseau.
Installation de Cilium
Cette dernière doit être compatible CNI (ne pas hésiter à faire un tour ici pour bien comprendre), a savoir le standard qu’un driver réseau doit respecter pour s’intégrer à un cluster Kubernetes.
Il en existe plusieurs, mais c’est Cilium qui a été retenu. C’est la solution la plus en vogue au moment de l’écriture de cet article. (mais les modes changent souvent, l’important est de retenir un CNI qui correspond à vos usages).
Basé sur la technologie du Kernel Linux eBPF, il offre tout un panel de fonctionnalités avancées, notamment pour le filtrage et le suivi des flux.
Étant donné qu’on lui a dédié des taches Ansible, toute sa configuration a déjà été préparée et disponible dans le dossier de l’utilisateur courant ~/kub.coolcorp.priv/network/ (kub.coolcorp.priv avait été fixé en variable de Ansible comme répertoire de stockage des configurations : ça reste un exemple).

Cliquez sur l'image pour l'agrandir.
Le contenu du fichier cilium-values.yaml final est le suivant:
kubeProxyReplacement: strict
k8sServiceHost: 192.168.10.91
k8sServicePort: 6443
ipam:
mode: "cluster-pool"
operator:
clusterPoolIPv4PodCIDRList:
- "10.13.0.0/16"
hubble:
relay:
enabled: true
ui:
enabled: true
frontend:
server:
ipv6:
enabled: false
tls:
auto:
enabled: true
method: helm
certValidityDuration: 1095
On y retrouve le réseau 10.13.0.0/16 que l’on va dédié à Cilium ainsi que d’autres paramètres, comme l’IP de l’API du cluster (donc l’IP du serveur HAproxy). On va indiquer aussi que l’on souhaite activer certaines fonctionnalités, notamment la GUI de hubble qu’on exploitera plus tard.
L’installation de Cillium est possible de différentes manières, mais comme on peut le lire dans le fichier de configuration, c’est helm que l’on va retenir.
Pour rappel, helm est un gestionnaire de paquet pour Kubernetes. Il permet de simplifier le déploiement des applications, en récupérant directement dans des repos, les fichiers de configuration nécessaires à l’installation d’un logiciel sur un cluster kubernetes, sans que vous ayez à vous soucier des différents objets employés.
Personnellement, j’utilise helm avec parcimonie. Il est très pratique, mais en masquant ses actions, on n’est pas toujours certains que l’outil déployé le soit fonction de notre besoin.
helm utilise une configuration par défaut, qu’il est possible d’obtenir avec la commande helm show values nom_apps.
Je vous invite toujours à vérifier en amont de vos opérations avec helm le contenu du paramétrage par défault.
Si celui-ci ne vous convient pas, il est toujours possible de le surcharger avec sa propre configuration. C’est d’ailleurs ce que nous allons faire ici avec l’usage du fichier cilium-values.yaml
Avant de pouvoir déployer Cilium, il faut déjà ajouter son repo helm (pour rappel , la commande helm a été ajoutée durant les actions Ansible).
helm repo add cilium https://helm.cilium.io/
On s’assure que le repo est à jour.
helm repo update
Cliquez sur l'image pour l'agrandir.
On peut checker par curiosité la configuration par défaut utilisé par Helm pour déployer Cilium.
helm show values cilium/cilium
Cliquez sur l'image pour l'agrandir.
Le fichier est très grand, car Cillium peut prendre énormément de paramètres.
On va se contenter de notre configuration et on passe à l’installation directement avec la commande
helm install --version 1.15.4 --namespace=kube-system cilium cilium/cilium --values=./cilium-values.yaml --set hubble.relay.enabled=true --set hubble.ui.enabled=true

Cliquez sur l'image pour l'agrandir.
Cette instruction va dire à helm de déployer Cilium en version 1.15.4 dans le namespace kube-system en s’appuyant sur notre fichier de configuration.
Le namespace kube-system est le namespace le plus critique du cluster, puisqu’il contient la base du system. On évite de le manipuler (d’ailleurs dans des solutions « kubernetes as a service » des provider cloud, on ne peut pas y accéder la plupart du temps). Dans le cas de Cillium ce n’est pas une aberration qu’il soit déployé dans ce dernier.
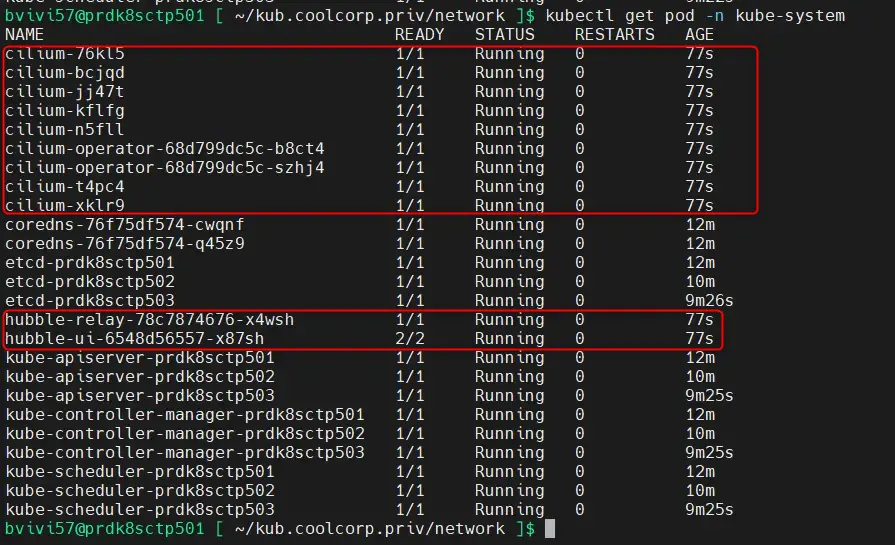
On peut d’ailleurs voir l’ajout des pods associé à Cilium via la commande:
kubectl get pod -n kube-system
En plus des composants de base de Kubernetes, on observe bien les composants propres à Cilium. Pour une installation réussie, ils doivent tous être en exécution (Cela peut prendre plusieurs minutes après le retour de la commande de helm).
Cliquez sur l'image pour l'agrandir.
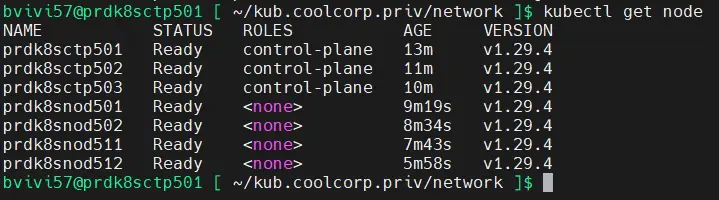
Si tous les composants sont opérationnels, on peut revérifier le statut des nodes.
kubectl get node
Cliquez sur l'image pour l'agrandir.
Tous sont désormais dans une statue ready, cela est dû en grande partie à ce que grâce au déploiement de la couche réseau, les DNS internes au cluster sont désormais UP (vous pouvez les voir dans la namespace kube-system).
Afin de s’assurer que cilium est pleinement opérationnel. On peut s’appuyer sur la cli de Cilium qu’on n’a déployé durant le playbook Ansible.
cilium status –wait
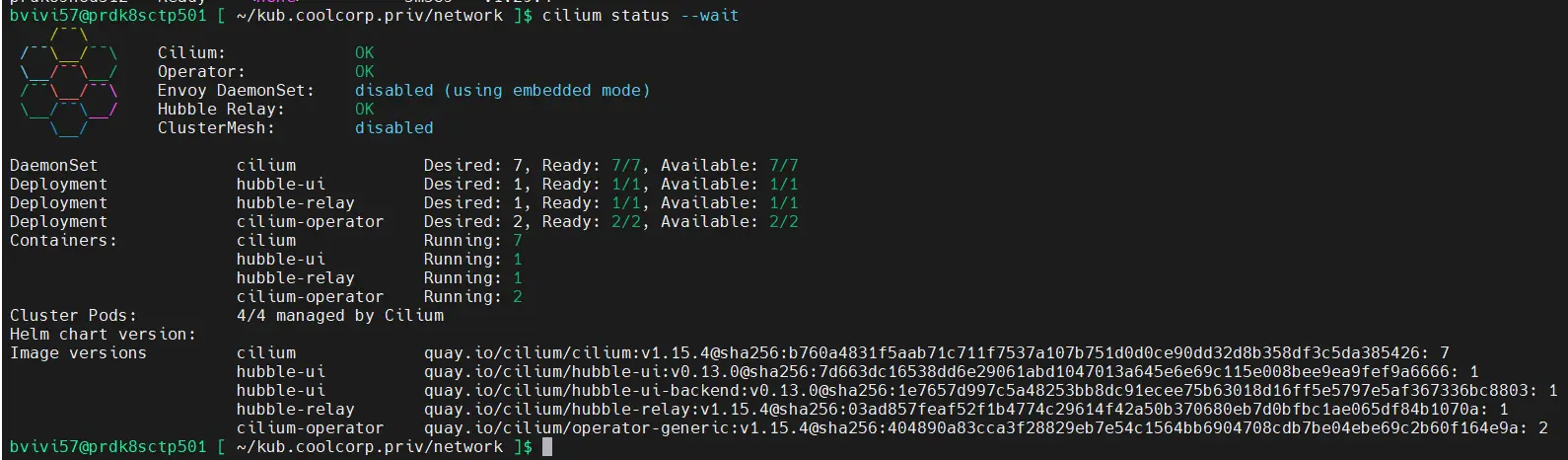
Cliquez sur l'image pour l'agrandir.
Tous devraient être au vert.
Il est même possible de faire des tests plus poussés avec la commande cilium connectivity test, mais dans ce cas, cela peut durer très longtemps, car beaucoup de choses sont évaluées.
À noter qu’attention, Cilium peut aussi s’installer avec la CLI, mais dans ce cas il ne faut pas utiliser helm. Il ne faut jamais mélanger les méthodes d’installation. Dans notre cas, la CLI est uniquement la à des fins de diagnostic, si demain Cilium doit être mis à jour c’est Helm qu’il faudra utiliser.
Le test ultime consiste à lancer la GUI de Cilium. En l’état elle n’est pas encore exposée avec un ingress par exemple, mais il est déjà possible d’y avoir accès.
Pour cela il va falloir faire sur son poste de travail, ce que j’ai dit un peu plus haut de ne pas faire….
Mais on va dire que c’est uniquement à des fins de tests.
On récupère le contenu du fichier de config de kubectl pour le copier sur son poste. Dans le cas d’un OS Windows, kubectl peut s’installer de différentes manières, toutes décrites ici.
L’important est de retenir une version compatible avec son cluster. Il est possible de choisir une version supérieure jusqu’à une limite de 2. En l’occurrence, dans mon exemple, le cluster à été déployé en 1.29, on peut utiliser kubectl en 1.30.
Une fois le binaire sur le poste, la configuration qu’il va utiliser se trouve dans le profil utilisateur, en l’occurrence sous Windows dans C:\Users\mon_user\.kube
Cliquez sur l'image pour l'agrandir.
Il suffit de créer un fichier config (sans extension) qui va contenir exactement ce qu’il y’a dans le fichier ~/.kube/config du premier control plane que nous avons récupérée précédemment.
Pour rappel, ce contenu est très sensible puisqu’il permet un accès admin au cluster. Normalement on n’utilise jamais en dehors de taches d’administration très spécifiques.
Quoiqu’il en soit, cela devrait permettre maintenant d’interagir sur le cluster en tant qu’admin directement depuis son poste de travail (vous pouvez tester la commande kubectl get node pour valider que la connexion est opérationnelle).
On peut désormais tenter de lancer l’UI de cilium avec la commande
kubectl port-forward -n kube-system svc/hubble-ui 12000:80

Cliquez sur l'image pour l'agrandir.
On ne va pas rentrer dans le détail à ce niveau, mais cette commande va permettre de mapper le port de son poste 12000 (veillez à ce qu’il ne soit pas déjà pris, sinon retenez un autre numéro) au port 80 du service hubble-ui présent au sein du cluster qui expose l’UI sur le port 80.
De cette manière en tapant dans son navigateur http://127.0.0.1:12000/ on accède à l’UI de Cilium
Cliquez sur l'image pour l'agrandir.
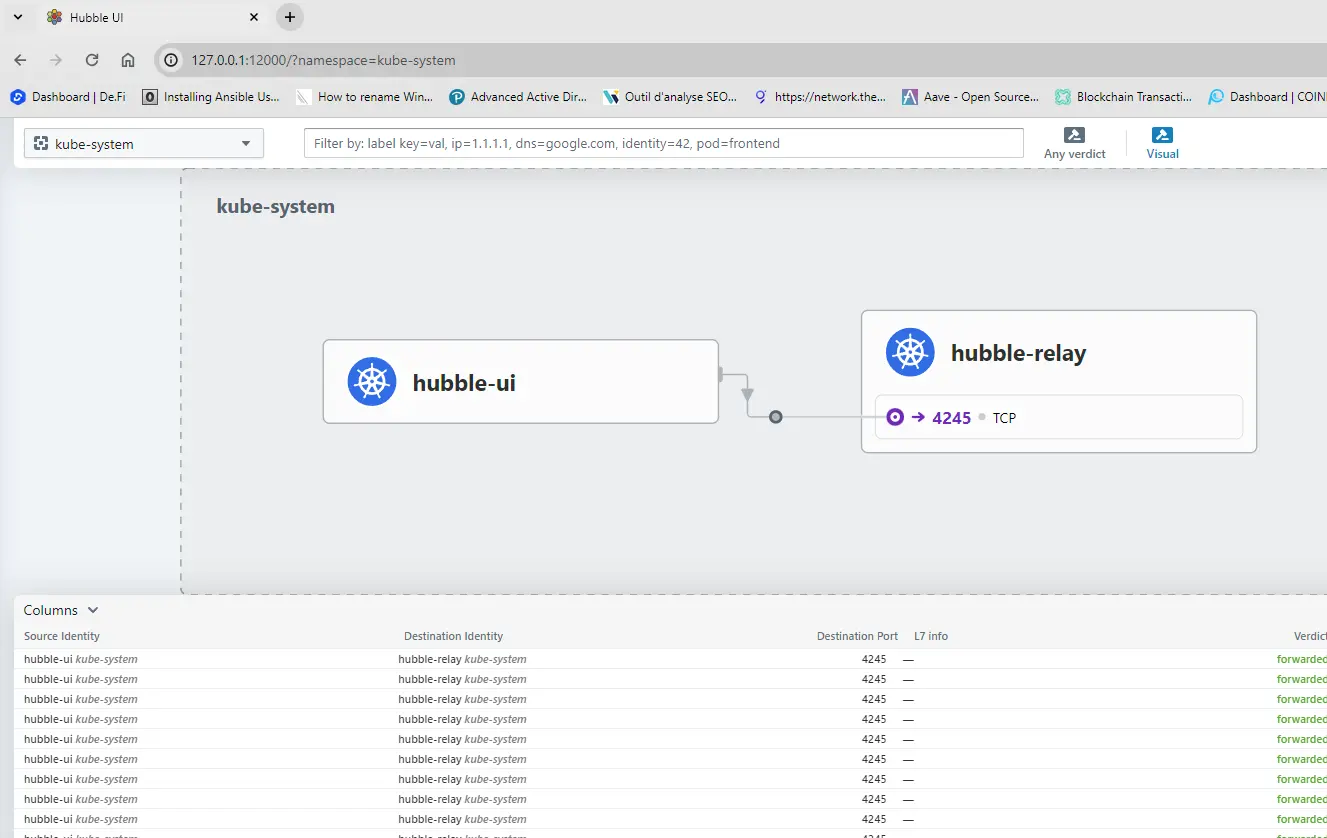
Cliquez sur l'image pour l'agrandir.
Une fois qu’on s’est assuré de l’accès, on peut mettre fin à la commande.
Mise en place des alias et des taint
Avant de conclure, on va juste terminer par deux petites opérations.
Rappelez-vous que dans l’architecture cible, on dispose de nœuds sur le LAN et en DMZ.
Il va être important de les différentier pour une meilleure lisibilité.
On va donc commencer par mettre des labels.
Les commandes suivantes peuvent être passées sur le poste de travail si le fichier de config de kubectl est toujours présent (ce qui n'est pas bien) ou sur le premier control plane dans le contexte utilisateur standart:
kubectl label node prdk8snod511 node-role.kubernetes.io/worker-dmz=
kubectl label node prdk8snod511 network=dmz
kubectl label node prdk8snod512 node-role.kubernetes.io/worker-dmz=
kubectl label node prdk8snod512 network=dmz
kubectl label node prdk8snod501 network=lan
kubectl label node prdk8snod501 node-role.kubernetes.io/worker-lan=
kubectl label node prdk8snod502 network=lan
kubectl label node prdk8snod502 node-role.kubernetes.io/worker-lan=

Cliquez sur l'image pour l'agrandir.
Si on refait un kubectl get node, on n’a désormais plus de détails dans le rôle.
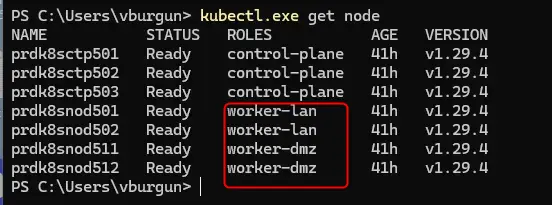
Cliquez sur l'image pour l'agrandir.
Mais ce n’est pas suffisant. Car en dehors de simplement labéliser les nodes, on souhaite également mettre des contraintes d’exécution pour éviter par la suite qu’une application destinée au LAN ne se retrouve en DMZ et inversement.
Je ne vais pas rentrer dans le détail pour l’instant, mais pour cela on va « tainter » ou marquer en français nos nodes.
De cette manière, on pourra par la suite configurer nos déploiements applicatifs pour qu’ils « tolèrent » ou non les marques posées sur les nodes.
kubectl taint nodes prdk8snod511 node-role.kubernetes.io/worker-dmz=:NoSchedule
kubectl taint nodes prdk8snod512 node-role.kubernetes.io/worker-dmz=:NoSchedule

Cliquez sur l'image pour l'agrandir.
On va appliquer cette restriction uniquement sur les nodes en dmz. En gros, les commandes ci-dessus, vont permettre d’interdire le « schedule » autrement dit l’exécution d’un pod si celui-ci n’est pas explicitement configuré pour supporter le taint « worker-dmz ».
De cette manière, si on ne précise rien, jamais un pod ne pourra être lancé sur un node en DMZ. Il faudra explicitement le configurer pour que cela se fasse, on évite donc la situation la plus critique d’un point de vue sécurité, a savoir exposer une application interne à l’extérieur par mégarde.
Conclusion
On n’a enfin un cluster opérationnel.
Toute les briques de bases sont déployées et on peut désormais y exécuter des assets. Mais dans notre cas, et conformément à notre cible de départ, on va également installer des composants additionnels, comme un driver de storage pour exploiter des datastores vmware et un ingress controleur, Traefik, pour simplifier l’exposition de nos ressources…mais ça c’est par la.