Ajout d'un worker à un cluster K8S
Introduction
L’avantage d’une solution comme Kubernetes est d’être scalable facilement selon deux modèles:
- Vertical : on conserve le nombre de nœuds d’exécution, mais on augmente leur capacité : ajout de RAM, de CPU…cette scalabilité est d’autant plus simple dans un environnement virtuel, ou les nodes sous forme de VMs peuvent voir leurs caractéristiques mise à jour rapidement fonction des ressources disponibles sur l’hyperviseur sous-jacent.
- Horizontal : on augmente le nombre de nœuds d’exécution pour ajouter de la capacité au cluster en déployant de nouveaux serveurs.
Le premier cas est souvent plus simple à réaliser, mais plus l’on augmente les capacités d’un worker, plus on augmente la dépendance du cluster à ce dernier. Si un node doté d’une grande quantité de ressources venait à tomber, on impacte forcement plus d’applications puisque celui-ci est en capacité d’en exécuter davantage.
En cas de scalabilité horizontale, on augmente la complexité du cluster, mais on étale davantage les ressources.
L’ajout d’un node de type worker sous K8S est très simple, dès lors qu’un serveur, physique ou virtuel dispose des prérequis suffisants, l’ajout de ce dernier à un cluster existant se fait en quelques minutes.
Cet article a pour vocation de donner un exemple d’ajout d’un worker…mais en mettant également en avant la capacité de Kubernetes à mélanger des serveurs de types et de configurations différents.
En dehors des besoins de scalabilité, on peut très bien être amené à dédier des nodes à des profils d’applications spécifiques. Grâce au marquage des nodes et aux instructions possibles autour des objets K8S, on peut découper son cluster par type d’usage.
On peut faire en sorte que certains nœuds exécutent des assets spécifiques, exigeant des caractéristiques qu’on ne pourrait pas retrouver sur d’autres serveurs du cluster.
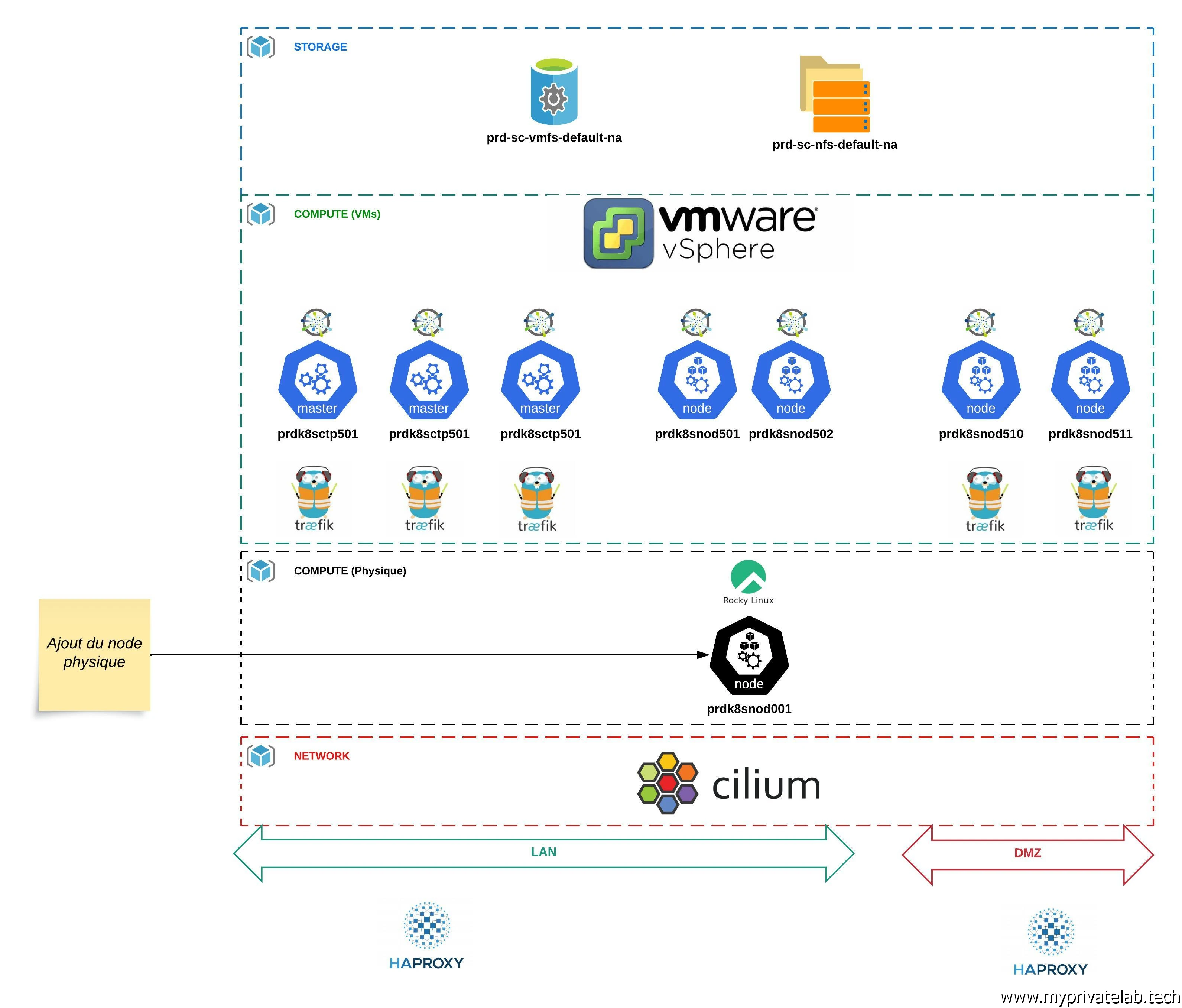
Dans mon cas, je vais étendre mon cluster Kubernetes présenté dans mon cookbook et reposant sur mon infrastructure de lab, avec l’ajout d’un nœud physique.
Je reprends une grande partie de ce que j’ai déjà pu expliquer dans différentes étapes de la mise en œuvre d’un cluster K8S. Je vous invite fortement à prendre connaissance de la partie traitant du déploiement de la configuration sous Ansible, car je vais réutiliser cette logique pour préparer mon nouveau serveur.
Habituellement j’utilise des VMs sous PhotonOS. Mais je souhaiterais avoir un worker plus performant afin d’y exécuter des applications pouvant nécessiter un besoin important de ressources. Or j’ai retrouvé au fin fond de mon placard, un mini PC d’une obscure marque chinoise (XCY) que j’avais à l’époque quelque peu boosté en disque et en mémoire.
Malgré qu’il date de 2020, avec un CPU 4 cores (i5-8259U), 32Go de RAM et un SSD de 512Go, il a de quoi pouvoir retrouver une seconde jeunesse au sein de mon cluster.
Pour démonter le côté « multimarque » de Kubernetes, je ne vais pas déployer PhotonOS, mais Rocky Linux 9.4. Un OS bien plus standard, issue des changements opérés par RedHat autour de CentOS ayant conduit le créateur d’origine de ce dernier à concevoir ce Rocky Linux. Le but étant de continuer d’offrir un système d’exploitation compatible avec les binaires RHEL (Red Hat Enterprise Linux) tout en étant 100% libre et gratuit.
C’est un très bon choix pour des besoins professionnels avec une large communauté et une très bonne stabilité.
L’idée est également de l’inclure à mes playbook Ansible, de manière à ce que je puisse y déployer les prérequis K8S de la même manière que pour mes VMs sous PhotonOS.
Cliquez sur l'image pour l'agrandir.
Installation de Rocky Linux
Je ne vais pas détailler l’installation de Rocky Linux. Le système s’installe depuis une ISO copiée sur USB et présente un installateur assisté identique à ce que l’on retrouve dans la famille des OS RedHat.
Je suis parti de l’ISO minimale. J’ai simplement configuré une IP sur mon LAN, un nom de machine prdk8snod001 (avec le suffixe .coolcorp.priv pour le nom complet), un compte utilisateur et j’ai laissé les options de partitionnement pas défaut.
Intégration à Ansible
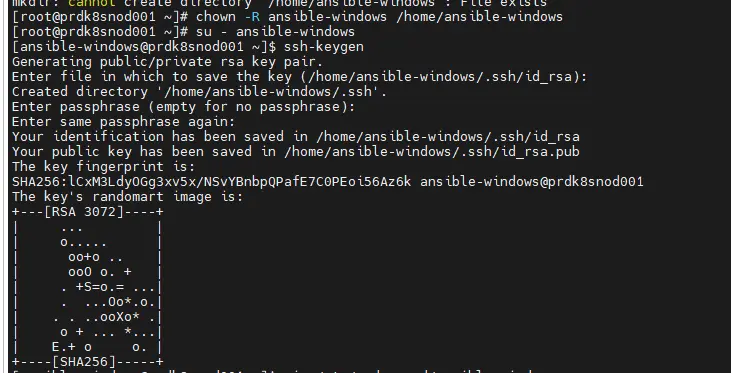
Une fois démarré et accessible en SSH, j’ai appliqué les mêmes paramètres de bases que pour mon template PhotonOS afin de le rendre accessible à mon instance Ansible déployée sur mon poste de travail via WSL.
- Création d’un utilisateur ansible-windows (du nom du compte que j'utilise sur mon instance Ansible)
- Bascule dans le profil de cet utilisateur pour:
- Créer une combinaison clef publique/clef privée via la commande ssh-keygen
- Inscription dans le fichier ~/.ssh/authorized_keys de la clef publique de mon utilisateur Ansible utilisé pour me connecter à mes serveurs.
- Retour en root pour la création d’un fichier sudo pour autoriser le compte ansible-windows à exécuter des commandes root sans exiger de mot de passe.
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
La logique étant que depuis mon poste de travail, je puisse exécuter Ansible afin qu’il se connecte en SSH au serveur et puisse y exécuter toutes les actions exigées par mes playbooks. N’hésitez pas à passer par cet article et cet article pour plus de détails.
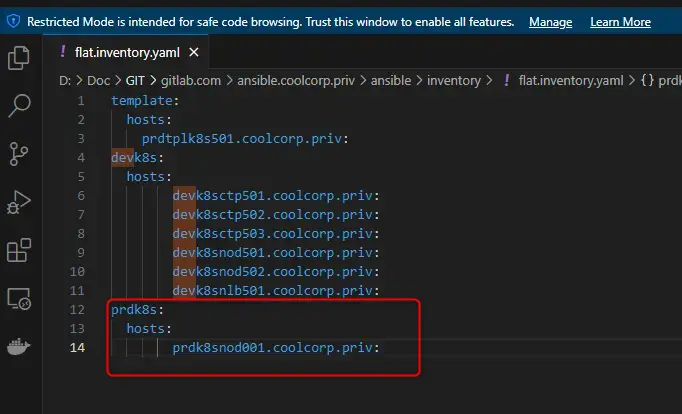
Le serveur n’étant pas une VM, je ne vais pas pouvoir reprendre la logique d’inventaire dynamique Ansible basée sur l’interrogation de mon vCenter et des tags rattachés aux VMs (plus de détails ici).
Je vais simplement partir sur un inventaire Ansible statique sous la forme d’un fichier flat.inventory.yaml. Au du sein du fichier j’associe un groupe prdk8s à mon host prdk8snod001.coolcorp.priv.
prdk8s:
hosts:
prdk8snod001.coolcorp.priv:
De cette manière tout rôle que j’appliquerais au groupe prdk8s pourra être exécuté sur mon serveur physique prdk8snod001.
Cliquez sur l'image pour l'agrandir.
Traitement des prérequis (avec Ansible)
Maintenant que le node physique est accessible et pilotable via Ansible, je vais adapter mes fichiers yamls utilisés dans mon playbook de déploiement de Kubernetes aux spécificités de mon nouveau worker et plus particulièrement à Rocky Linux.
Je ne vais pas représenter à nouveau la structure de mon rôle Ansible role_k8s_deploy, celui-ci est détaillé dans cet article.
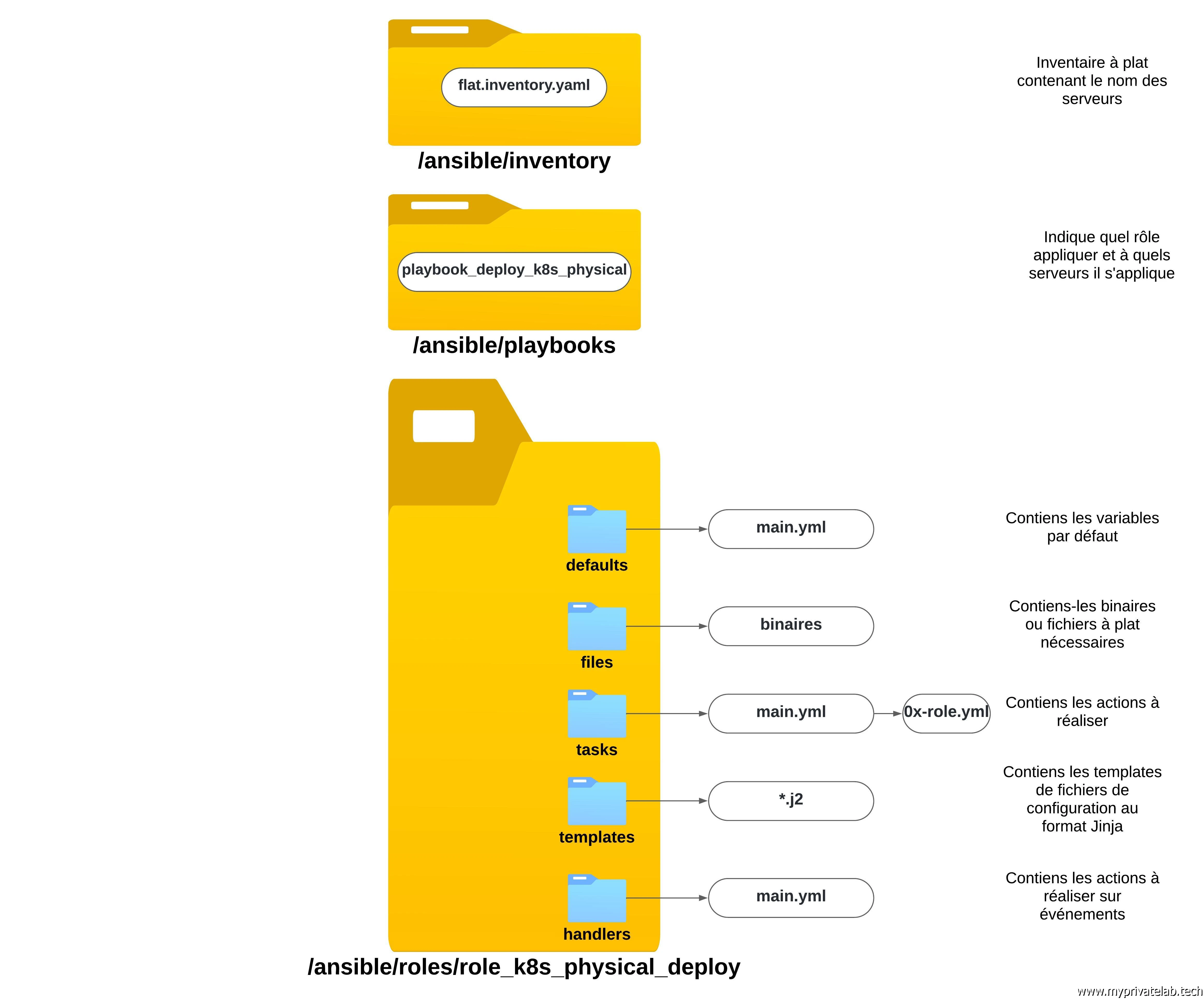
Je pourrais le modifier pour y ajouter les instructions propres à ce nouveau serveur physique. Mais pour plus de praticité, je vais plutôt le cloner pour créer un nouveau rôle role_k8s_physical_deploy pour isoler le déploiement d’un node physique.
Ce n’est pas forcément la meilleure manière de faire. Idéalement sous Ansible on n’essaye de mutualiser le maximum d’instructions et de travailler par exceptions et conditions pour pouvoir traiter au sein d’un même rôle tout ce qui pourrait y être rattaché.
Mais dans mon cas, par simplification, je vais me contenter de reprendre la configuration de mon serveur physique dans un rôle spécifique.
Je ne vais pas rentrer dans le détail tous les yamls utilisés. Dans les grandes lignes, ils sont identiques à ceux utilisés pour PhotonOS dont vous pouvez trouver une description ici.
Voici la reprise de l’arborescence du rôle:
Cliquez sur l'image pour l'agrandir.
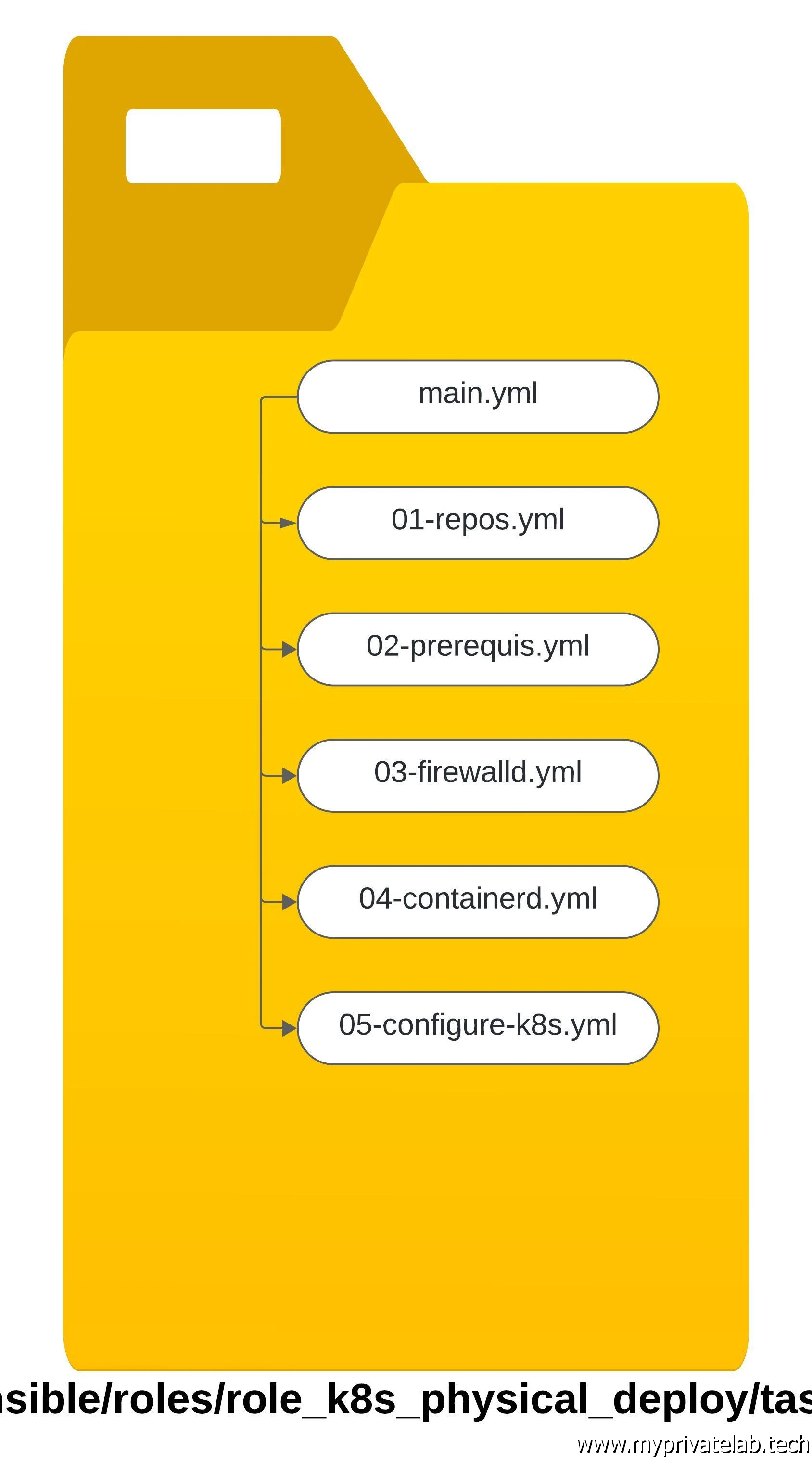
Cliquez sur l'image pour l'agrandir.
En termes de paquet à installer en prérequis, je dois modifier quelque peu la liste par rapport à PhotonOS pour arriver à ce listing que je définis dans ma variable var_k8s_packages_worker contenu dans mon fichier main de mon répertoire defaults.
#Liste des paquets à déployer sur les nodes
var_k8s_packages_worker:
- kubeadm-{{ var_kub_version }}
- nfs-utils
- wget
- tar
- kubelet-{{ var_kub_version }}
- runc
(Les paquets kubeadm et kubelet sont issues des repos officiels de Kubernetes et non des repos par défault de l'OS. Ces repos sont configurés lors de l'exécution des taches décrites dans 01-repos.yml. PhotonOS et Rocky Linux expoitant tout deux le même format de paquets, je n'ai pas eu à revoir cette partie. Plus de détails disponibles ici).
C’est surtout l’ajout de runc qui est important, runc étant le runtime de plus bas niveau utilisé pour la conteneurisation. N’hésitez pas à parcourir le second schéma présent ici pour plus de détails.
Rocky Linux exploite dnf comme gestionnaire de paquet, je dois donc passer mon yaml 02-prerequis.yaml de l’usage du module tdnf à dnf.
#installation des packages sur les workers (liste des paquets défini dans "main.yml" du dossier "defaults")
- name: Install basic packages for worker
become: yes
dnf:
update_cache: yes
name: "{{ var_k8s_packages_worker }}"
state: present
when: inventory_hostname.startswith('prdk8snod')
tags: role_k8s_deploy.prerequis.packages_worker
C’est aussi dans ce même fichier, que je dois revoir ma manière de désactiver la swap. Pour l’instant K8S n’est pas à l’aise avec la swap, il faut donc la retirer et ceci nécessite pour mon installation de Rocky Linux de commenter son usage dans le fichier fstab de l’OS.
- name: Permanently disable swap in /etc/fstab
become: yes
replace:
path: /etc/fstab
regexp: '^([^#].* swap .*)$'
replace: '# \1'
Toujours dans ce yaml 02-prerequis.yaml, j’ai dû ajouter l’usage d’un template kubeadm-flags.env.j2 dans lequel on retrouve ce contenu:
KUBELET_KUBEADM_ARGS="--container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --pod-infra-container-image=registry.k8s.io/pause:3.9 --resolv-conf=/etc/resolv.conf"
Le fichier doit être renommé en kubeadm-flags.env et placé dans /var/lib/kubelet/kubeadm-flags.env lors de l’appel à Ansible. Il est destiné à être utilisé par l’agents Kubelet.
Lors de mes premiers essais, je me suis aperçu que ce que positionné comme paramètre kubeadm à l’initialisation du cluster dans ce fichier n’était pas suffisant pour autoriser le démarrage de l’agent.
C’est notamment cette option --resolv-conf=/etc/resolv.conf qu’il est nécessaire d’ajouter.
Ensuite, Rocky Linux exploite firewalld et non iptable comme le fait PhotonOS. Il m’a donc fallu reprendre mon fichier 03-firewalld.yaml pour basculer vers le module ansible firewalld. Les ports et protocoles utilisés restant les mêmes, je n’ai pas eu à revoir le détail de l’ouverture des ports (juste une syntaxe à corriger pour les plages de ports, liés à la bascule du module iptable vers firewalld).
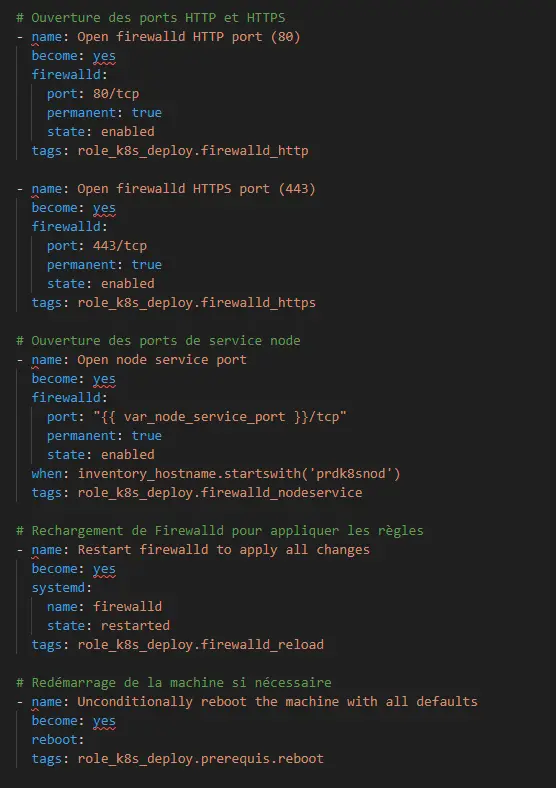
Cliquez sur l'image pour l'agrandir.
(Pour plus de détails sur les ports à ouvrir vous pouvez consulter cet article).
Je n’ai pas besoin de toucher aux restes, c'est toujours containerd qui sera déployé via les binaires directement récupéré sur le site. Il me suffit de simplifier un maximum les yamls pour y retirer tout ce qui n’a pas d’intérêt pour un worker physique.
J’enlève tout ce qui peut toucher à vSphere, au prérequis associé à un nœud control plane ou à HAproxy.
Vous pouvez retrouver le rôle complet dans mon github.
Il ne me reste plus qu'à associer mon inventaire statique et mon role role_k8s_physical_deploy via le playbook global playbook_deploy_k8s_physical.yml:
---
- name: Deploy K8S Physical
hosts: prdk8s
roles:
- role_k8s_physical_deploy
Puis de lancer l'exécution du playbook avec la commande ansible-playbook playbooks/playbook_deploy_k8s_physical.yml pour traiter mon serveur physique et configurer tous les prerequis nécessaires sous Rocky Linux pour supporter l'exécution d'un node worker K8S.
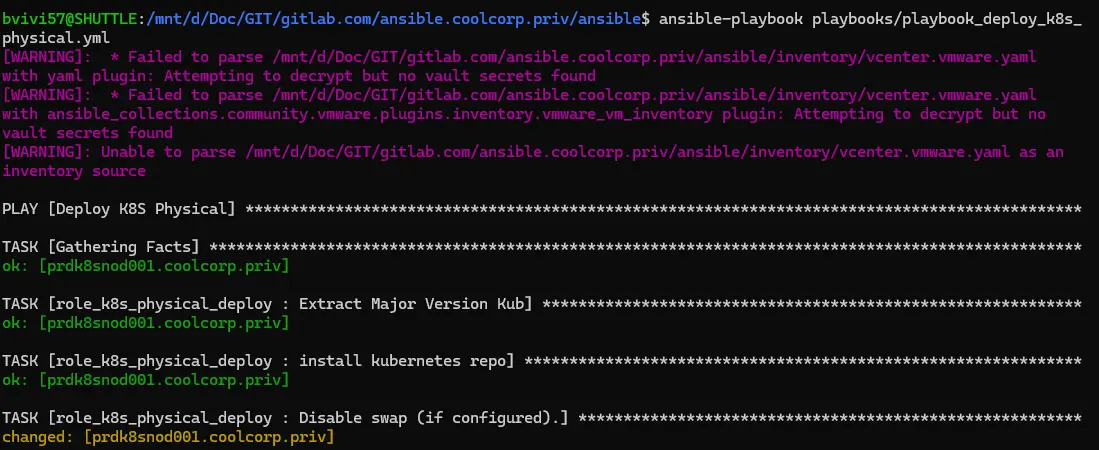
Cliquez sur l'image pour l'agrandir.
Ajout du node
Je peux maintenant enfin, démarrer l’opération d’ajout du node en tant que telle.
Pour cela je me connecte en root sur mon premier control plane.
J’exécute la commande kubeadm token create --print-join-command.
Celle-ci me génère l’instruction à taper sur mon nouveau worker pour qu’il puisse rejoindre le cluster.

Cliquez sur l'image pour l'agrandir.
On n’y trouve notamment le token qui va permettre au node de s’enregistrer auprès de l’API K8S. Attention, ce token n’est valable que 20 min, il faut donc l’utiliser rapidement sur le nœud physique.
Je bascule en root sur ce dernier pour y copier la ligne récupérée plus haut.
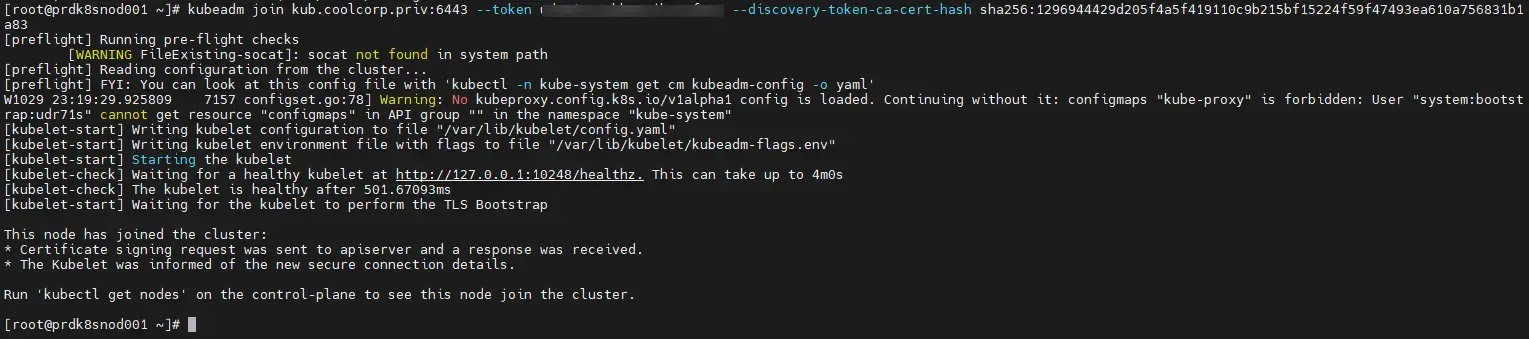
Cliquez sur l'image pour l'agrandir.
Kubeadm va s’occuper du reste et au bout de quelques minutes, le nœud est ajouté au cluster.
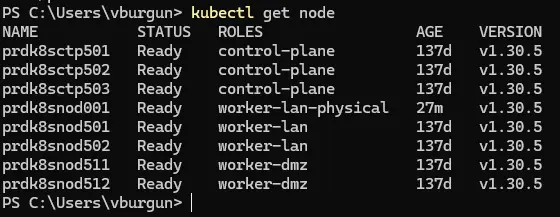
On peut le vérifier en tapant la commande kubectl get node depuis son environnement de travail.
Il est possible que le node apparaisse pendant un temps en not ready, car il est nécessaire qu’un certain nombre de composants du cluster se lancent et se configure pour prendre en compte ce nouveau node. C’est le cas par exemple du CNI (Container Network Interface) Cilium (plus de détails ici).
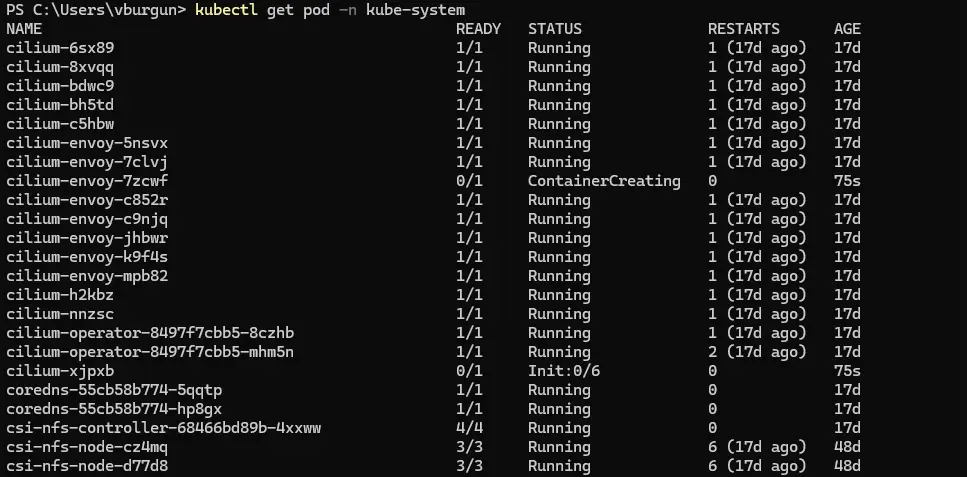
Cliquez sur l'image pour l'agrandir.
D’ailleurs attentions aux ouvertures de flux, mon cluster Kubernetes mixant des nodes en LAN et en DMZ, j’ai dû mettre à jour mes règles firewall pour autoriser le trafic nécessaire au réseau interne Cilium établi entre les différents serveurs du cluster.
Cliquez sur l'image pour l'agrandir.
Ajustement des composants tiers
Ce nœud étant physique, certains composants n’ont par contre pas à s’exécuter sur ce dernier. C’est le cas notamment du driver CSI (Container Storage Interface) vSphere (plus de détails ici).
Par défaut, le driver tente de s’initialiser sur tout nouveau node, mais dans ce cas, il tombe en erreur puisqu’il ne s’agit pas d’une VM.

Cliquez sur l'image pour l'agrandir.
Il faut donc procéder à la modification du déploiement associé au CSI vSphere pour qu’il ignore un node de type physique.
Mais avant, il faut labéliser et teinté notre nouveau node pour le rendre identifiable facilement au sein du cluster.
Pour ça j’applique d’abord le même label network que pour mes autres node du lan, puisqu’il est dans la même zone réseau, par contre, j’applique un nouveau label type que je place à physical ainsi qu’un nouveau label node-role.kubernetes.io/worker-lan-physical=.
On peut observer l’impact du label, si on rappel la commande kubectl get node.
J’applique également un taint sur mon node avec la commande suivante:
kubectl taint nodes prdk8snod001 node-role.kubernetes.io/worker-lan-physical=:NoSchedule

Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Pour rappel un taint permet de marquer un serveur afin d’éviter que celui-ci ne soit utilisé par un pod à moins que ce dernier ne soit configuré explicitement avec une toleration à ce marquage.
Pour être néanmoins certains que mon CSI vSphere ne s’applique pas, je vais modifier la configuration de l’objet K8S associé.
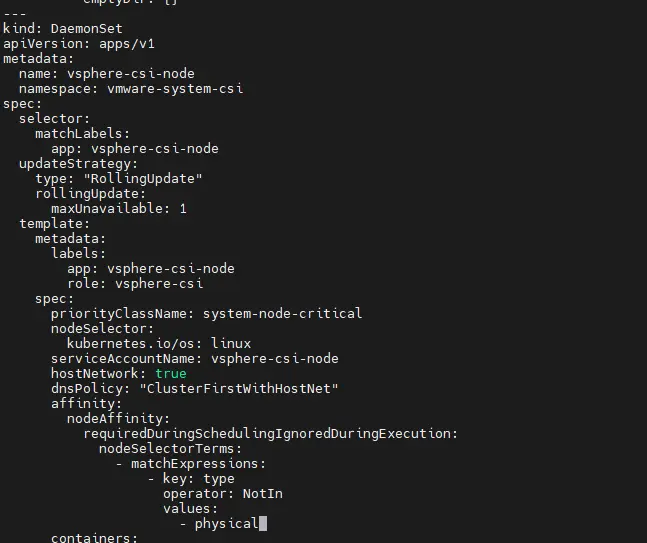
J’édite le fichier vsphere-csi-driver.yaml que j’utilise pour déployer le CSI (plus de détail ici). Ce fichier contient la définition de l’objet DaemonSet, nommé vsphere-csi-node. Un DaemonSet est proche de l’objet deployment, mais a comme caractéristique d’automatiser le déploiement du pod rattaché sur tout nouveau node qui s’inscrit dans le cluster et qui répond au critère d’éligibilité du DaemonSet.
C’est pratique dans des cas où l’on veut s’assurer en permanence qu’un composant soit exécuté sur chaque node, et ceci dès son ajout dans le cluster.
Dans mon exemple, par contre, c’est problématique puisque le driver tente de s’initialiser sur un serveur qui n’est pas compatible. Je dois donc modifier le DaemonSet pour inclure une notion d’affinity dans laquelle j’indique explicitement que le pod ne peut être déployé que sur un node qui n’a pas le label physical .
---
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: vsphere-csi-node
namespace: vmware-system-csi
spec:
selector:
matchLabels:
app: vsphere-csi-node
updateStrategy:
type: "RollingUpdate"
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
app: vsphere-csi-node
role: vsphere-csi
spec:
priorityClassName: system-node-critical
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: vsphere-csi-node
hostNetwork: true
dnsPolicy: "ClusterFirstWithHostNet"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: NotIn
values:
- physical
Cliquez sur l'image pour l'agrandir.
J’applique mon fichier mis à jour:
Kubectl apply -f vsphere-csi-driver.yaml
Ainsi, le CSI en erreur va disparaitre et K8S ne va plus chercher à le déployer sur mon nouveau worker physique.
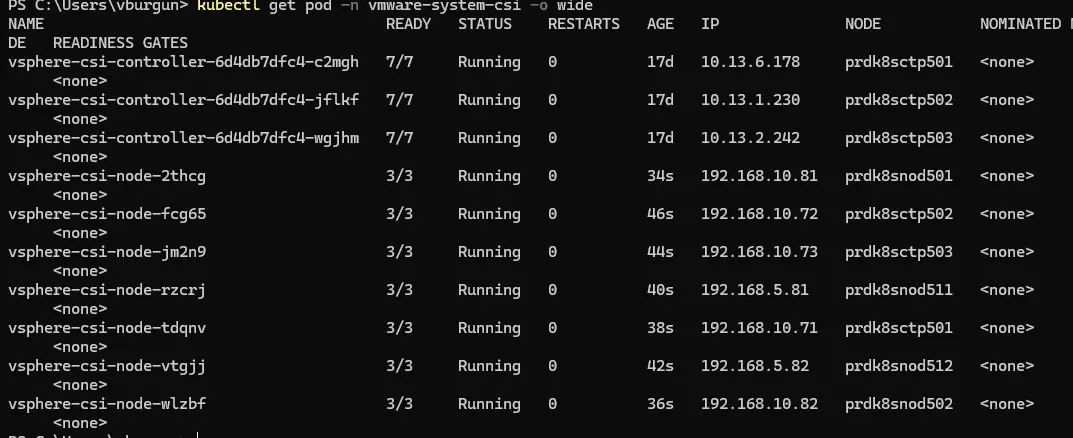
Cliquez sur l'image pour l'agrandir.
Conclusion
Mon cluster dispose désormais d’un nœud particulier, reposant non pas sur une VM sous PhotonOS, mais sur un serveur physique sous Rocky Linux 9.4.
Grâce à son marquage particulier, je peux contrôler finement ce que je souhaite y voir exécuter.
L’article peut paraitre long pour simplement expliquer l’ajout d’un worker à un cluster existant, opération qui comme vous avez pu le constater est extrêmement simple et rapide.
Mais j’avais comme volonté de démontrer la capacité d’un cluster Kubernetes à héberger des serveurs de types différents et d’OS différents.
Le fait également de choisir des outils comme Ansible comme solution de déploiement n’est pas bloquant, puisqu’on peut modifier l’existant et l’adapter aux spécificités de la nouvelle cible.
Kubernetes est une plateforme ouverte et qui peut s’adapter à de nombreux usages. Fonction de vos compétences et de vos préférences, un cluster K8S peut être déployé dans deux nombreux écosystèmes et vous pouvez composer vos node à votre convenance.
De mon côté, il ne me reste plus qu’à capitaliser sur ce nouveau serveur: pour le use case à base d'IA c'est par là!