Installation et usage Minio
Introduction
Il y a quelque temps, je postais un article sur le stockage persistent sous Kubernetes.
Dans mes explications, j’évoquais le cas du stockage objet.
C’est une méthode de gestion de la donnée qui diffère des classiques structures hiérarchiques.
Dans le stockage objet, les informations sont stockées…sous forme d’objets distincts. Chacun de ces objets se voit associer des données (contenu), des métadonnées (informations descriptives) et un identifiant unique.
C’est cet identifiant qui permet de retrouver facilement l’objet sans avoir à dépendre d’une arborescence et d’un chemin de fichiers.
Le stockage objet offre une grande scalabilité grâce à une conception adaptée aux systèmes distribués.
Contrairement aux méthodes d’accès traditionnels, le stockage objet se manipule avec des API Restful, facilitant ainsi son intégration avec des applications web et cloud.
Par contre il n’est pas optimisé pour les petites données, ni pour la haute performance, ni pour les modifications massives et permanentes d’informations comme on pourrait en rencontrer dans des bases de données.
À l’inverse, il est particulièrement adapté à la donnée non structurée et permet d’offrir un stockage peu coûteux pour de grosses volumétries de données.
C’est par exemple, une alternative possible à la traditionnelle bande pour l’externalisation des backups. Il s’adapte très bien à des cas d’archivage ou de stockage de fichiers médias.
Le service le plus connu est sans aucun doute Amazon S3 (Simple Storage Service). C’est un produit phare du géant du cloud public qu’on retrouve à la base de beaucoup de ses offres. C’est tellement devenu un succès que l’API associée est désormais un standard pour adresser différentes solutions de stockage objet.
Les autres acteurs du cloud public disposent également de leur offre équivalente compatible avec l’API S3.
Mais il n’est pas nécessaire d’avoir un abonnement cloud public pour bénéficier d’un service de stockage objet compatible S3.
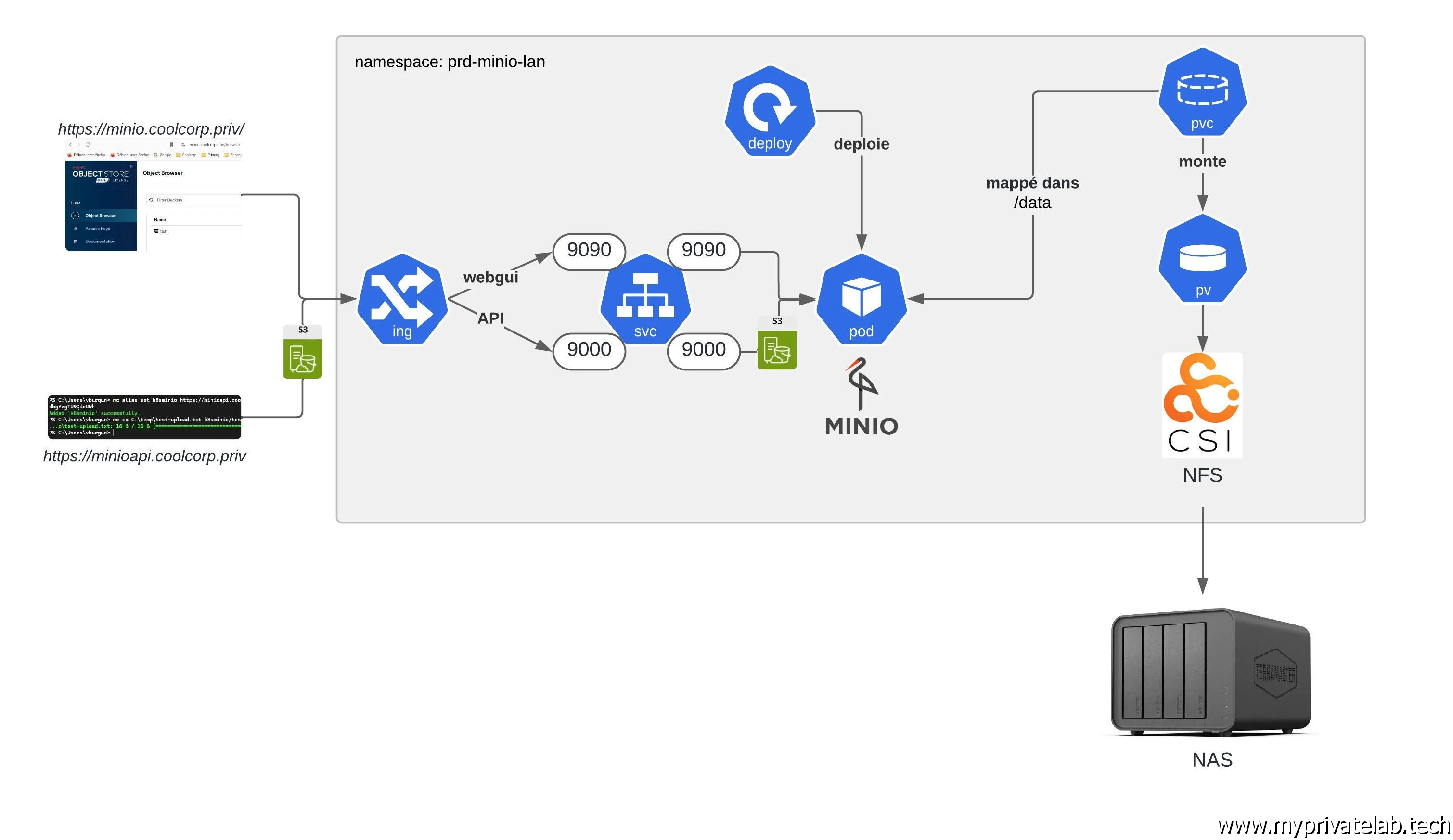
Grâce à des outils comme Minio, il est possible de déployer en interne, un environnement de stockage distribué et évolutif pilotable à travers l’API S3.
Cliquez sur l'image pour l'agrandir.
C’est un logiciel open source largement utilisé. Il offre l’avantage de pouvoir exploiter en backend des systèmes de stockage traditionnels (baie NAS ou SAN) et d’offrir un frontend supportant l’accès objets via l’API S3.
C’est cet usage que nous allons voir ici, avec la création d’un bucket, soit l’unité de stockage de base dans ce type d’accès. Celui-ci qui reposera en fond sur un simple export NFS (Network File System) hébergé sur mon NAS Terramaster.
Ceci me permettra dans mon lab, d’avoir un service S3 « like » que je pourrais utiliser pour différents usages, notamment pour du backup.
Bien entendu, je vais présenter un déploiement de minio sous Kubernetes
Par contre, je ne vais pas suivre un tutoriel basé sur l’usage de helm ou d’installation d’objets customisés.
Installation
Pour commencer, je créer un namespace dédié, basé sur la norme que j’utilise, et que je nomme prd-minio-lan.
La commande est tout simplement : kubectl create ns prd-minio-lan.

Cliquez sur l'image pour l'agrandir.
L’objet qui va suivre est un Secret. Il va correspondre aux identifiants admin d’accès à la solution Minio.
Cette combinaison d’éléments d’authentification va me servir à me connecter sur la GUI fourni avec Minio.
Je créer mon secret avec la commande suivante:
kubectl create secret generic secret-minio-default --from-literal="root_user=mon_user" --from-literal="root_password=mon_password" --namespace=prd-minio-lan

Cliquez sur l'image pour l'agrandir.
La suite consiste à créer le PersistentVolume (pv). En effet, je vais me servir de Minio comme d’un « proxy » S3, mais le stockage final se fera sur mon NAS qui propose un volume NFS.
J’utilise le driver CSI NFS, pour plus d’informations sur ce sujet, je vous renvoie à mon article dédié.
---
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: nfs.csi.k8s.io
name: pv-minio-default
labels:
environment: prd
network: lan
application: minio
tier: default
type: nfs
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
driver: nfs.csi.k8s.io
volumeHandle: /Volume1/BACKUPS/prd-minio-lan
volumeAttributes:
server: 192.168.10.152
share: /Volume1/BACKUPS/prd-minio-lan
Je ne vais pas rentrer dans le détail du contenu, encore une fois n’hésitez pas à lire cet article au besoin.
Ce qui est important c’est le point de montage final NFS que j’utilise qui est /Volume1/BACKUPS/prd-minio-lan hébergé sur mon NAS (Network-attached storage) répondant à l’IP 192.168.10.152.
(cela implique que les IPs de mes nœuds worker K8S soient autorisés à accéder a l’export NFS).
Je poursuis avec le traditionnel PersistentVolumeClaim (pvc). Le contenu du fichier 02-pvc-minio-default.yml est le suivant:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-minio-default
namespace: prd-minio-lan
labels:
environment: prd
network: lan
application: minio
tier: default
type: nfs
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
volumeName: pv-minio-default
storageClassName: ""
Comme je n’utilise pas de StorageClass, je précise le nom du pv directement.
C’est au tour du fichier de Deployment 03-deploy-minio-default.yaml:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-minio-default
namespace: prd-minio-lan
labels:
environment: prd
network: lan
application: minio
tier: default
spec:
replicas: 1
selector:
matchLabels:
environment: prd
network: lan
application: minio
tier: default
template:
metadata:
labels:
environment: prd
network: lan
application: minio
tier: default
spec:
containers:
- name: minio
image: minio/minio:RELEASE.2024-09-09T16-59-28Z
command:
- /bin/bash
- -c
args:
- minio server /data --console-address :9090
env:
- name: MINIO_ROOT_USER
valueFrom:
secretKeyRef:
name: secret-minio-default
key: root_user
- name: MINIO_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: secret-minio-default
key: root_password
ports:
- containerPort: 9000
- containerPort: 9090
volumeMounts:
- name: pv-minio-default
mountPath: "/data"
volumes:
- name: pv-minio-default
persistentVolumeClaim:
claimName: pvc-minio-default
Je ne rentre pas non plus dans le détail du contenu, des informations utiles sur le sujet peuvent être trouvées dans mon exemple de déploiement d’application sous K8S et dans la définition de l’objet.
Mais on peut s’arrêter quelques minutes sur les sections command et args.
Au démarrage du pod, c’est la combinaison de ces deux paragraphes qui va être passée à Minio. Ceci afin qu’il démarre avec les bons paramètres.
C’est-à-dire, en mode server, avec la data mappée dans /data et le port d’écoute du site web sur 9090.
C’est également au niveau du Deployment dans la section env que je passe mes informations d’identifications associées au secret que j’ai créé en début d’installation.
Coté volume, je fais appel à mon pvc afin de monter le pv dans /data au niveau du Pod qui accueillera le conteneur Minio via l’image RELEASE.2024-09-09T16-59-28Z.
On peut passer au Service avec le fichier 04-svc-minio-default.yml:
---
apiVersion: v1
kind: Service
metadata:
name: svc-minio-default
namespace: prd-minio-lan
labels:
environment: prd
network: lan
application: minio
tier: default
spec:
type: ClusterIP
ports:
- name: api
port: 9000
targetPort: 9000
- name: webui
port: 9090
targetPort: 9090
selector:
environment: prd
network: lan
application: minio
tier: default
À ce niveau, on peut juste préciser que le service expose deux ports:
- Le 9000 : correspondant à l’API S3
- Le 9090 : correspondant à la GUI web
On arrive bientôt au dernier objet, l’Ingress, qui va me permettre d’exposer Minio et sa GUI en dehors du cluster.
Voici le contenu du fichier 05-ing-minio-default.yml:
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-minio-default
namespace: prd-minio-lan
labels:
environment: prd
network: lan
application: minio
tier: default
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
#traefik.ingress.kubernetes.io/router.middlewares: "inf-traefik-lan-middelware-minio-default@kubernetescrd"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- minio.coolcorp.priv
- minioapi.coolcorp.priv
secretName: secret-certificate-minio
rules:
- host: minio.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-minio-default
port:
number: 9090
- host: minioapi.coolcorp.priv
http:
paths:
# Redirection des requêtes vers le port 9000 pour l'API
- path: /
pathType: Prefix
backend:
service:
name: svc-minio-default
port:
number: 9000
À l’image du service, j’utilise deux urls distinctes pour renvoyer vers chacun des ports respectifs.
L’url minio.coolcorp.priv est dédiée à l’accès à la GUI web et renvoi donc vers le port 9090.
L’url minioapi.coolcorp.priv est dédiée à l’API et donc au port 9000.
Dans les deux cas, j’utilise le même certificat, dont le contenu est dans le Secret secret-certificate-minio.
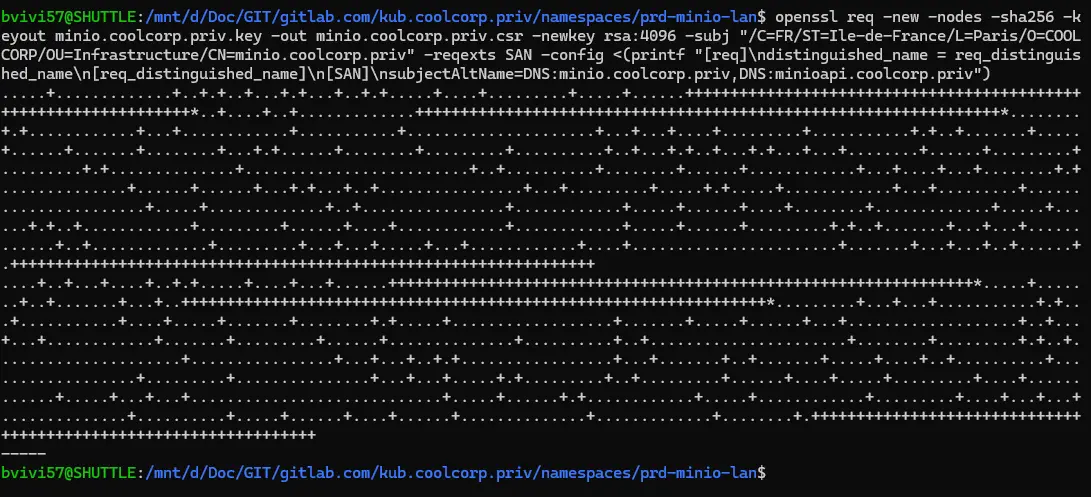
Pour peupler ce secret, j’ai créé un combiné clef privée/certificat à partir de la commande openssl suivante:
openssl req -new -nodes -sha256 -keyout minio.coolcorp.priv.key -out minio.coolcorp.priv.csr -newkey rsa:4096 -subj "/C=FR/ST=Ile-de-France/L=Paris/O=COOLCORP/OU=Infrastructure/CN=minio.coolcorp.priv" -reqexts SAN -config <(printf "[req]\ndistinguished_name = req_distinguished_name\n[req_distinguished_name]\n[SAN]\nsubjectAltName=DNS:minio.coolcorp.priv,DNS:minioapi.coolcorp.priv")
Cliquez sur l'image pour l'agrandir.
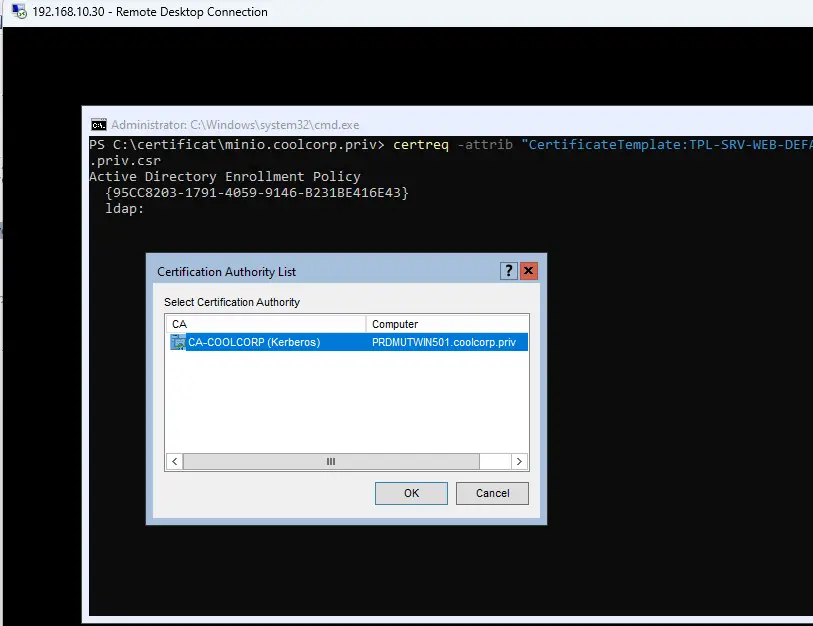
Cette dernière m’a permis d’obtenir un csr (Certificate Signing Request) que j’ai fourni à ma PKI (Public key infrastructure) Microsoft interne pour obtenir un certificat. Je ne vais pas détailler spécifiquement ce point. Chacun dispose potentiellement de solution différente pour l’obtention d’un certificat. À la fin j’ai bien certificat autorisant les deux noms DNS définis dans mon Ingress.
Cliquez sur l'image pour l'agrandir.
Je stocke ma clef privée et mon certificat dans le secret via la commande.
kubectl create secret generic secret-certificate-minio --from-file=tls.crt=minio.coolcorp.priv.cer --from-file=tls.key=minio.coolcorp.priv.key --namespace prd-minio-lan

Cliquez sur l'image pour l'agrandir.
Plutôt que d'avoir à appliquer chaque objet unitairement, comme tous mes yamls sont dans le même dossier, j'applique simplement la commande kubectl apply -f mon_fodler pour déclarer tous mes objets d'un coup.

Cliquez sur l'image pour l'agrandir.
Arrivée à ce stade, on peut vérifier que le Pod est bien exécuté avec la commande: kubectl get pod -n prd-minio-lan
Cliquez sur l'image pour l'agrandir.
Après avoir créé les enregistrements DNS nécessaires au renvoi des urls vers mes instances traefik me servant d’Ingress Controler, je peux accéder à la GUI web.
(Si vous souhaitez en apprendre davantage sur Traefik et les Ingress Controler, je vous invite à prendre connaissance de l’article suivant. De plus, n’hésitez pas à lire le descriptif de la plateforme K8S que j’utilise pour mieux comprendre le rôle de chaque composant).
Cliquez sur l'image pour l'agrandir.
Exemple et tests
Il est possible de s’authentifier sur la GUI avec mon compte root (mes identifiants inclus dans le secret généré en début d’installation).
Une fois sur l’interface, je vais pouvoir valider le bon fonctionnement de la solution. Pour cela, je créer un bucket test.
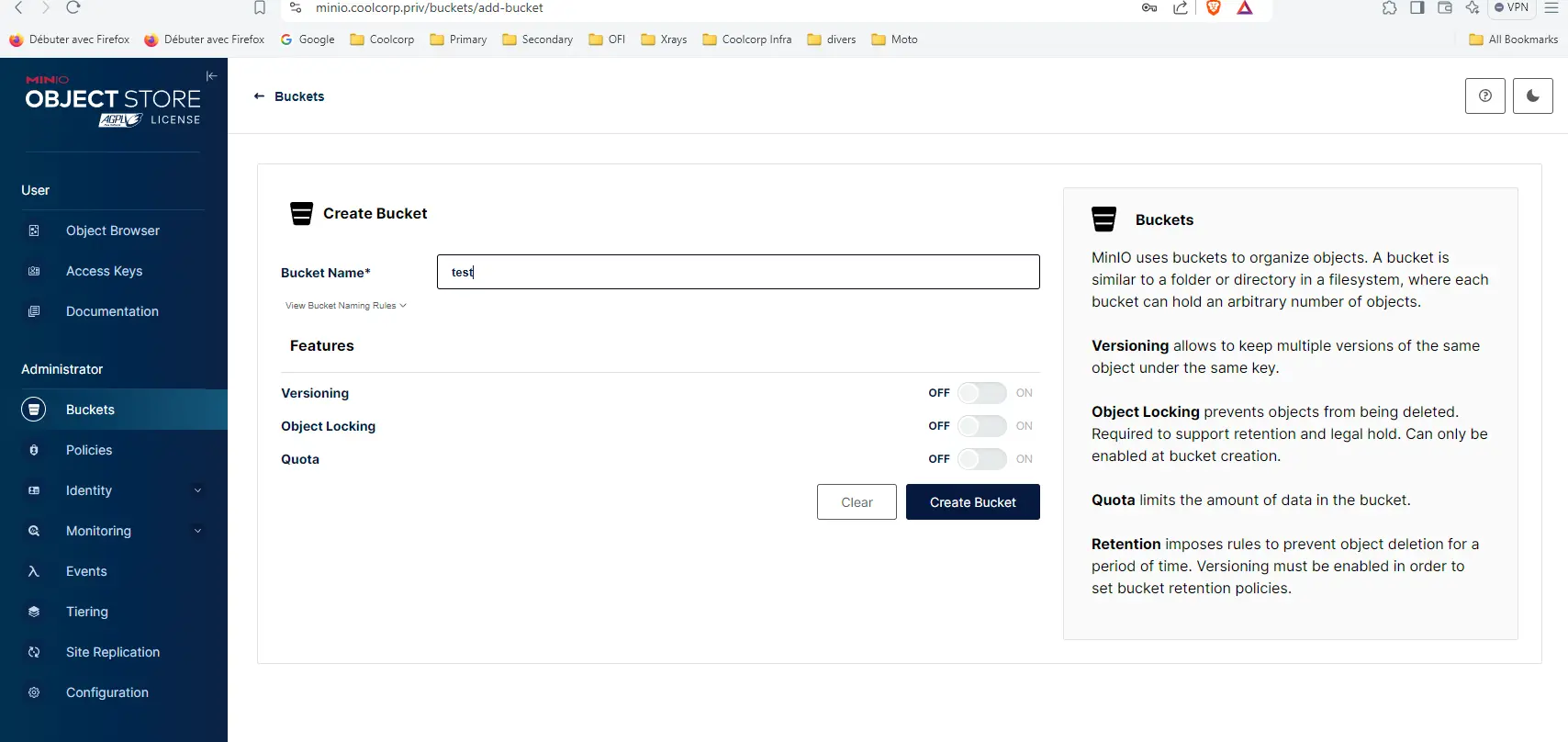
Cliquez sur l'image pour l'agrandir.
Pour rappel un bucket est le contenant de base. C’est lui qui va acceuillir mes premiers fichiers.
Puis je me rends dans l’onglet Policies afin de proposer une politique d’accès à ce bucket.
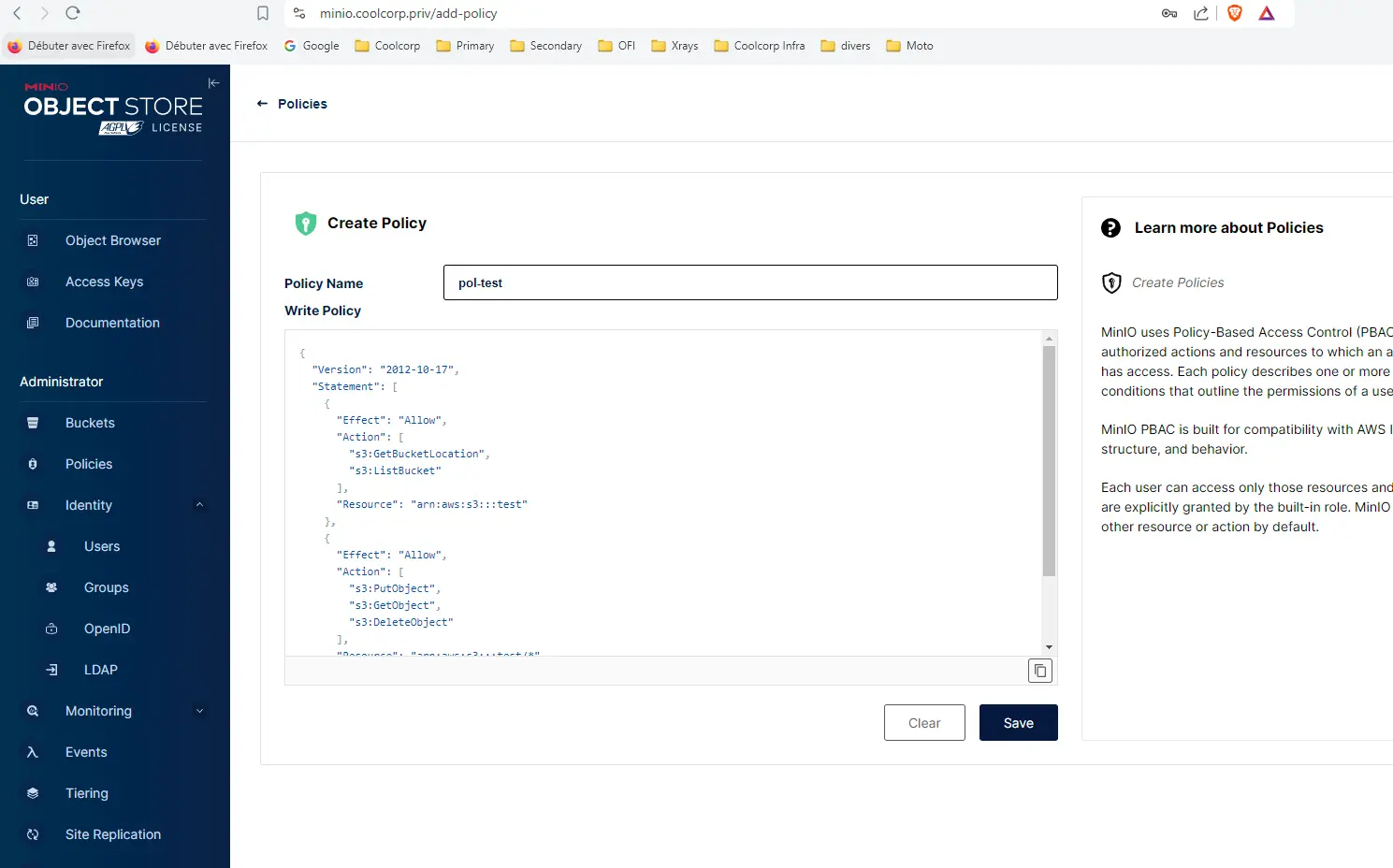
Cliquez sur l'image pour l'agrandir.
Une politique Minio reprend le fonctionnement d’une politique S3 et se décrit dans un fichier JSON.
Je ne suis pas spécialiste du sujet, et un rapide passage vers un outil comme ChatGPT suffit à créer sa première police.
Dans mon cas, ma policie pol-est autorise un accès en lecture/écriture à mon bucket test.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::test"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::test/*"
]
}
]
}
Je créer ensuite un utilisateur test qui va hériter de cette policie.
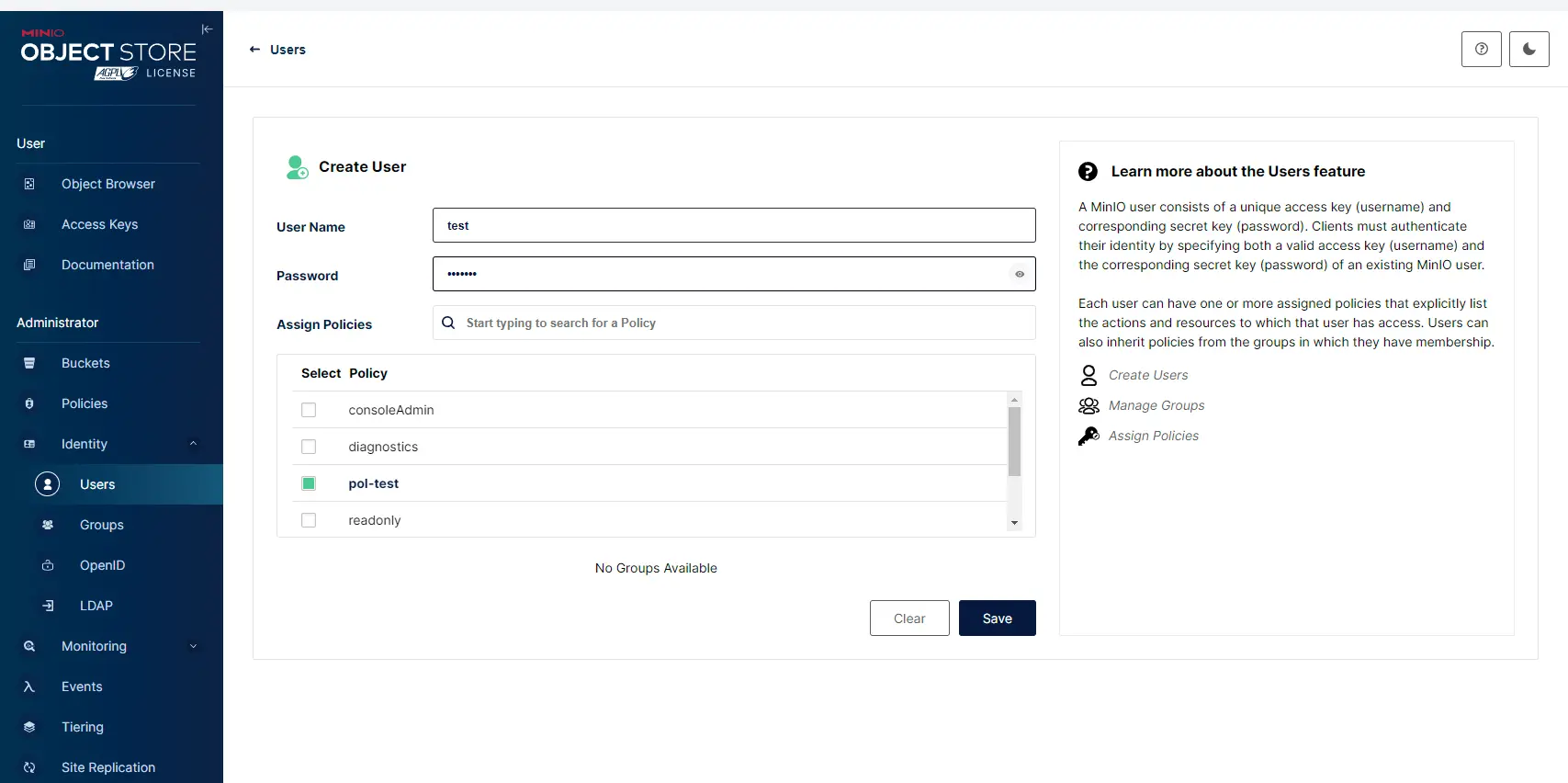
Cliquez sur l'image pour l'agrandir.
Afin de pouvoir exploiter ce user, je vais lui associer une clef d’accès et un secret (pas un secret Kubernetes). Pour cela il suffit de se rendre dans le menu Service Account de l’utilisateur test et de lui générer cette combinaison.
C’est courant dans le stockage objet d’utiliser ce type d’authentification.
Si la clef peut être communiquée, le secret doit bien entendu être protégé. Il est même possible de donner une durée de vie à l'ensemble, ce qui peut s’avérer pratique lorsqu’on souhaite autoriser un accès temporaire à un bucket.
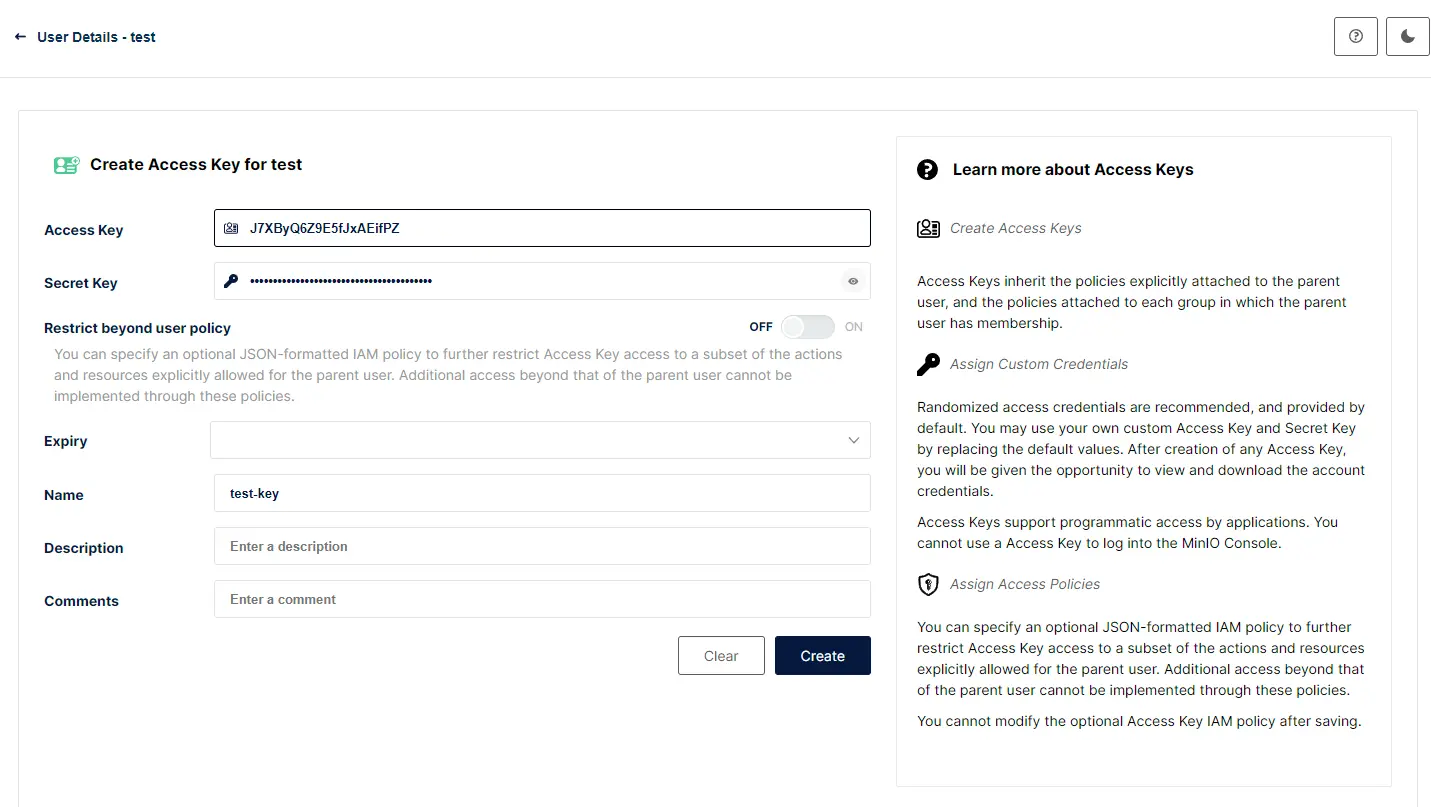
Cliquez sur l'image pour l'agrandir.
J’ai maintenant tout le nécessaire pour évaluer Minio.
Je vais m’appuyer sur l’outil mc, qui n’est autre que le client officiel Minio. Celui-ci est disponible à cette URL pour Linux, mac et Windows. Il s’agit d’un simple binaire à placer dans son chemin système afin de pouvoir y faire appel depuis une console.
Sur mon poste Windows 11, je peux ensuite passer la commande suivante:
mc alias set k8sminio https://minioapi.coolcorp.priv ma_key mon_secret
Cette commande me permet d’initier ma cible en y indiquant l’url du serveur minio (en l’occurrence ici l’url de l’API) puis la combinaison clef/secret créée précédemment.
La cible est associée à un alias que je choisis arbitrairement d’appeler k8sminio.
Je peux ensuite faire une tentative d’upload, m’appuyant sur cet alias et en fournissant un fichier test présent sur mon poste.
mc cp C:\temp\test-upload.txt k8sminio/test

Cliquez sur l'image pour l'agrandir.
Il ne me reste plus qu’à vérifier que le fichier est maintenant bien présent dans le bucket via la GUI.
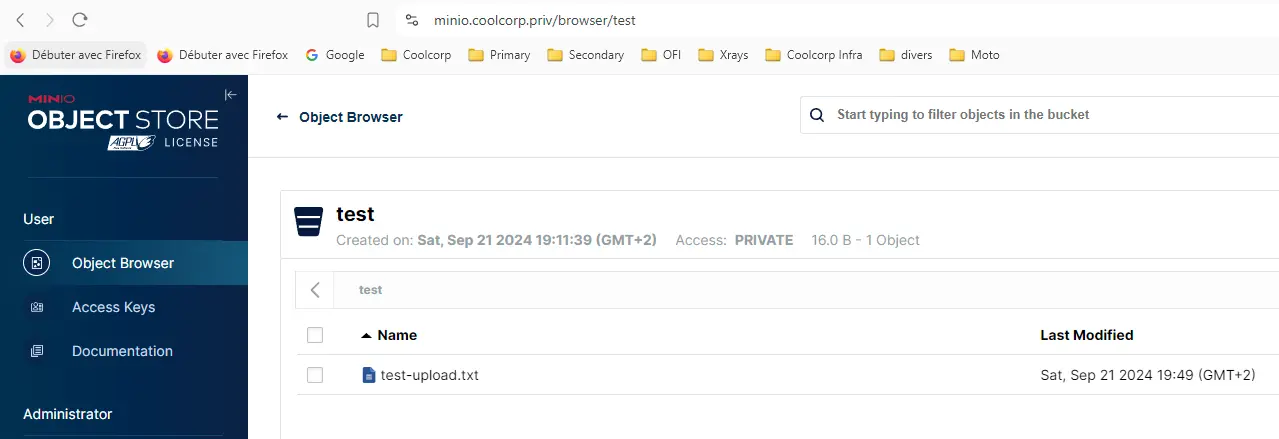
Cliquez sur l'image pour l'agrandir.
Ce qui est intéressant à observer c’est la forme de la donnée du côté du NAS. Si on browse le volume NFS à l’emplacement du pv, on retrouve un dossier « test » correspondant au nom du bucket, puis un dossier au nom de mon fichier, dans lequel on retrouve un fichier xl.meta.
C’est un binaire propre à Minio qui contient mon fichier, mais sous sa forme objet avec ses metadatas. Il m’est impossible de récupérer son contenu.
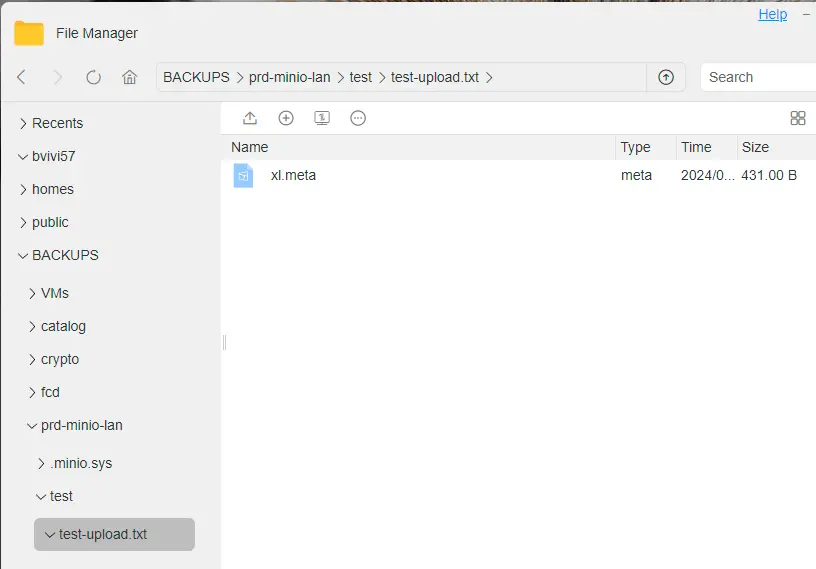
Cliquez sur l'image pour l'agrandir.
Pour cela je dois repasser par Minio, soit par l’API soit par la GUI.
Conclusion
Je dispose maintenant d’un service de stockage objet compatible S3 qu’il me sera possible d’utiliser à l’intérieur et à l’extérieur du cluster K8S.
Minio est une solution simple, rapide à déployer et largement utilisée. Si certains ont des doutes sur l’intérêt d’un tel produit pour associer à un partage NFS un accès type objet, sachez que ceci ouvre bien des possibilités. On n’en verra d’ailleurs un usage bien précis avec la solution de sauvegarde velero…mais c’est prévu pour plus tard.
À noter que si j’ai utilisé le client mc, il est bien sûr possible d’utiliser des librairies spécifiques propres à son langage de script préféré, comme Python ou PowerShell, voire même de se passer de librairies pour construire ses propres requêtes d’accès à l’API. C’est l’une des grandes forces du stockage objet, son approche API Rest lui permet de s’intégrer beaucoup plus facilement dans les applications que d’autres méthodes plus classiques.
J'ai appris également qu'il n'est pas toujours conseillé de rattacher Minio à un partage NFS. Il est plus optimisé d'exploiter des ressources disques natives. J'aurais pu par exemple utiliser un volume type VMFS avec le CSI vSphere, mais mon usage de Minio est avant tout tourné vers la sauvegarde et j'avais surtout à coeur d'illustrer son fonctionnement. Dans un usage en production, mon exemple n'est peut être pas optimum, mais le principe est la.
Je n’ai fait que survoler les capacités de Minio. Il permet de faire bien plus de choses, notamment comme tout stockage objet, d’offrir des solutions de versionning, de réplication et autres usages avancés.
N’hésitez pas à vous faire votre propre avis sur l’application et à en tirer le meilleur pour vos usages.