KubeVirt: Partie 1 - Théorie et prérequis (deprecated)
Introduction
Cet article est issu d'un ancien tutorial. Son contenu est suceptible d'être obsolète. Je vous invite à poursuivre sur la nouvelle version du cookbook.
Kubernetes pas ci, Kubernetes par là…la plateforme d’exécution et de développement d’applicatifs conteneurisés ne cesse de faire parler d’elle et d’étendre son écosystème.
Au fur à mesure de son adoption, de nouveaux cas d’usage apparaissent.
Dès 2017, RedHat s’est demandé s’il n’était pas possible d’ajouter à K8S la prise en charge de VMs. Ce qui a donné lieu à KubeVirt.
Après quelques années de développement, celui-ci est passé sous la gestion de la Cloud Native Computing Foundation (CNCF). Le projet est toujours en statuts incubating à l’heure de rédaction de cet article.
Cliquez sur l'image pour l'agrandir.
Côté RedHat KubeVirt est intégré à la suite OpenShift, leur distribution commerciale Kubernetes (mais pas que). Cela leur permet aujourd’hui d’avoir une plateforme en capacité à la fois de traiter des conteneurs et des VMs via une seule et même logique d’exécution et d’interaction.
Intéret de KubeVirt
C’est bien là l’intérêt de Kubevirt, capitaliser sur la structure modulaire de Kubernetes et sa manipulation d’objets pour offrir une gestion universelle des workloads conteneurisés et virtualisés.
Sur le papier, c’est génial, dans les faits et dès lors qu’on cherche à implémenter soit même les différents composants nécessaires, surtout sur du matériel « classique », c’est une autre paire de manche…même l’IA peut déclarer forfait (croyez-moi j’ai poncé ChatGPT jusqu’à l’OS…)
Le problème vient du fait qu’on est encore dans une phase de développement et d’ajustement important, principalement autour des briques réseau.
Si en soi KubeVirt s’appuie sur un existant déjà bien présent et maitrisé, notamment KVM et Kubernetes himself, ce n’est pas forcément le cas de toute la suite de drivers et d’applications nécessaires à la cohésion de l’ensemble.
Forcément quand on souscrit une licence commerciale sur OpenShift et qu’on implémente le produit sur du matériel certifié, c’est plus simple que quand on cherche à recomposer toute la logique sur des équipements accessible à tous à chacun.
C’est pourtant ce que j’ai cherché à faire et ce que je vais essayer de détailler à travers différents articles dédiés.
Mais pourquoi ?
Pourquoi ? Parce qu’au vu de l’ambiance actuelle du marché de l’IT et de la défiance autour de VMware depuis son rachat par Broadcom, je me dis qu’il n’est pas inintéressant de creuser un peu le sujet KubeVirt. Cela sans forcément compter sur des suites complètes à la main des géants du secteur avec le risque potentiel de changement de grille tarifaire…attention, je ne tombe pas dans la paranoïa, l’usage de plateforme clef en main reste des choix à considérer et fortement conseillé pour de nombreuses entités : tout dépend du contexte, des contraintes (financières/humaines/légales/sécuritaires) et de la stratégie d’entreprise.
Mais dans tous les cas, savoir ce qui se cache sous le moteur n’est jamais inutile !
Si internet regorge déjà de nombreux tutoriels sur KubeVirt, peu poussent l’expérience jusqu’à une mise en situation concrète.
Dans mon cas, l’objectif premier est déjà d’arriver à une alternative complète à un ESXi incluant la capacité d’exécuter plusieurs VMs dans des zones réseau différentes. Le tout en conservant l’usage premier de Kubernetes à travers le chargement d’applications conteneurisées, via une segmentation compatible avec les contraintes de sécurité ainsi qu'une administration maitrisée des assets déployés.
Je pousserais les besoins au fur à mesure de mes découvertes et expérimentations avec comme objectifs finals de me forger une idée sur la capacité d’un écosystème Kubernetes/Kubevirt à remplacer totalement un écosystème Vmware (et surtout sur les moyens mettre à en œuvre pour le faire).
C’est parfaitement complémentaire à mes essais de la suite XCP-ng/Xen Orchestra. Au moins, j’aurais une expérience minimale sur différents écosystèmes, histoire de ne pas être trop paumé dans ce marché de l’IT si souvent bousculé…du moins sur la technique…côté management/marketing, ça change déjà moins…beaucoup de barreur, peu de rameurs.
La base
On va donc démarrer par un peu de théorie et faire le point sur toutes les briques qu’on va être amené à utiliser et à manipuler.
Je vais repartir de la base utilisée pour mon article sur l’intégration d’un GPU dans une plateforme K8S pour des cas d’usage IA.
Contrairement à mon lab standard sur lequel repose un cluster kubernetes à plusieurs nœuds, servant de référence à mon CookBook sur K8S, je vais exploiter pour l’instant un seul serveur physique nommé prdk8sctp001 avec les caractéristiques suivantes:
- OS: Rocky Linux 9.5
- CPU: Ryzen AMD Ryzen 9 7900X (12 cœurs / 24 threads)
- GPU: NVIDIA 3060 12GO vRAM
- RAM: 96 Go
- Stockage: 2 SSD NVME (1To) + 2 SSD SATA (2 To)
- Network:
- Une carte intégrée RTL8125 2.5GbE
- Une carte PCI-E 4 ports NetXtreme BCM5719 Gigabit
Attention aux cartes réseaux
J’attire votre attention directement sur la configuration matérielle réseau.

Cliquez sur l'image pour l'agrandir.
C’est en effet un point d’attention à avoir si vous souhaitez vous-même vous lancer dans l’aventure, que ça soit pour votre plaisir ou dans votre travail.
Déjà contrairement à mon exemple, éviter l’usage des cartes intégrées type Realtek. Comme vous pourrez le voir plus tard, c’est une plaie à utiliser dans un cadre un peu professionnel. Ensuite, retenez si possible des chipsets compatibles avec la norme SR-IOV, c’est souvent le cas avec les cartes Intels dédiées. J’en reparlerais dans les parties qui suivent, mais lorsqu’on ne dispose pas du matériel compatible, c’est déjà plus complexe même si on finit par s’en sortir.
Me concernant, les cartes ne le sont pas…histoire de corser le challenge…ainsi le tutoriel présenté sera basé sur la situation la moins favorable…
Configuration Kubernetes
Je ne vais pas développer particulièrement l’installation de Kubernetes. Je décris celle-ci dans mon cookbook.
Il s’agit d’une installation « vanilla » à l’aide de kubeadm suivant ce fichier de configuration.
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: 1.31.3
networking:
podSubnet: "10.11.0.0/16"
serviceSubnet: "10.12.0.0/16"
controlPlaneEndpoint: "rubikub.coolcorp.priv:6443"
clusterName: "rubikub"
controllerManager:
extraArgs:
cloud-provider: external
apiServer:
certSANs:
- 192.168.10.160
- rubikub.coolcorp.priv
N’hésitez pas à parcourir cet article si vous souhaitez en savoir plus.
À l’arrivée j’ai un node kubernetes en version v1.31.6.
Spécificité du mono node
Comme je n’ai pas l’attention pour l’instant d’ajouter des nodes au cluster, je doit lever la restriction d’exécution positionnée par défaut sur un nœud control plane.
Me concernant, mon serveur fera également office de worker node. Je suis donc obligé de lever le taint positionné lors de l’initialisation du cluster pour autoriser des composants à se déployer sur ce dernier.
kubectl taint node prdk8sctp001 node-role.kubernetes.io/control-plane:NoSchedule-

Cliquez sur l'image pour l'agrandir.
Attention, je ne conseille pas cette manipulation en production. Si vous disposez déjà d’un cluster complet, inutile, de passer cette commande et réserver votre contrôle plane uniquement aux composants système (et ayez au moins trois control plane).
Arriver à ce stade, on a un simple node physique avec un OS linux installé, en l’occurrence Rocky Linux 9.5, sur lequel s’exécute Kubernetes en version 1.31.6 pour l’instant dépourvue de drivers CNI (Container Network Interface).
C’est pourquoi le retour de la commande kubectl get node retourne un nœud en statut « not ready ».

Cliquez sur l'image pour l'agrandir.
Les CNI
Avant d’aller plus loin, il est nécessaire que vous ayez une connaissance minimale sur ce qu’est un CNI. En l’occurrence c’est un driver réseau exploitable par Kubernetes reposant sur un standard commun à toute plateforme K8S.
N’hésitez pas à faire un tour par ici pour plus d’informations sur ce sujet, notamment sur Cilium, puisque c’est le premier CNI que nous aurons à déployer.
Les composants KubeVirt
Il faut également définir de quoi on parle lorsqu'on évoque KubeVirt.
Rien ne vaut un schéma pour aider à la compréhension:
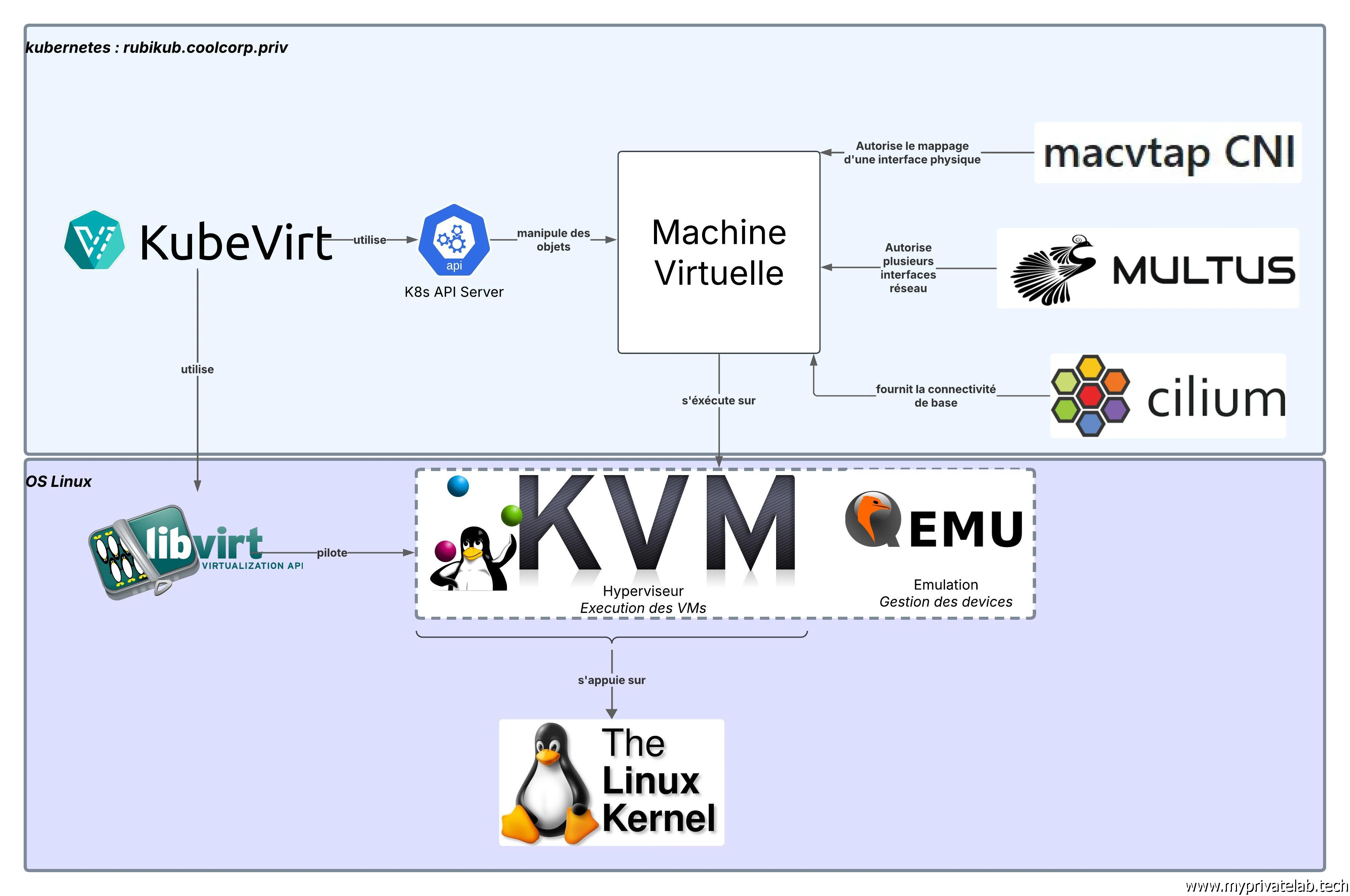
Cliquez sur l'image pour l'agrandir.
Couche de virtualisation
Tout d’abord, traitons de la partie dédiée à l’exécution des VMs.
| Application | Rôle |
|---|---|
| KVM | Hyperviseur libre de type I intégré dans le noyau Linux et utilisé pour exécuter les VMs |
| QEMU | Fournis l’émulation et la gestion des périphériques pour les VMs |
| libvirt | API de gestion des VMs utilisée par KubeVirt |
| KubeVirt | Intègre la gestion des VMs dans Kubernetes et orchestre leur exécution via KVM |
Composants Kubernetes
Si l’on s’attarde plus du côté Kubernetes et spécifiquement sur l’aspect réseau:
| Technologie | Rôle Principal | Utilisation avec KubeVirt |
|---|---|---|
| Cilium | Connectivité réseau pods/VMs | Fournis la connectivité principale aux VMs |
| Multus | Ajoute plusieurs interfaces réseau à un objet K8S | Permets d’ajouter des interfaces réseau supplémentaires aux VMs |
| macvtap | Connexion directe L2 | Attache une interface physique à la VM |
Fonctionnement
Pour fonctionner, Kubvirt va nécessiter le déploiement de Custom Ressource Defintion (CRD) pour étendre l’API Kubernetes avec ces objets:
- VirtualMachineInstance (VMI): Une instance de machine virtuelle en cours d’exécution.
- VirtualMachine (VM): Une VM persistante qui peut être arrêtée et redémarrée.
- VirtualMachineReplicaSet: similaire aux ReplicaSets de Kubernetes, permettant de gérer plusieurs instances de VM.
- VirtualMachineInstancePreset: Modèle pour standardiser la configuration des VM.
D’autres objets dédiés à Multus vont être déployés, il s’agit des NetworkAttachmentDefinition, mais nous en reparlerons plus tard.
Déployer Kubevirt revient à déployer toutes les dépendances nécessaires au traitement des VMs comme il s’agissait d’objet K8S qui vont pouvoir exploiter tout un ensemble d’autres objets natifs à Kubernetes pour fonctionner, comme les PersistentVolume (PVs) pour le stockage.
Pour couvrir l’aspect purement virtualisation, au lieu de s’appuyer sur un moteur de conteneur compatible avec le standard CRI (Container Runtime Interface) comme le fait Kubernetes nativement, Kubevirt va s’appuyer sur KVM, l’hyperviseur star sous Linux. Celui-ci est utilisé par de nombreuses solutions, comme ProxMox par exemple. C’est un hyperviseur de type 1 (n’hésitez pas à faire un tour ici) largement déployé, y compris dans des infrastructures cloud comme celle de GCP ou d’AWS.
La partie QEMU est elle aussi bien connue des Linuxiens et va servir à provisionner les device virtuels qu’on pourra déclarer au sein des VMs.
Kubevirt s’appuie à la fois sur l’API de Kubernetes pour échanger avec le cluster et sur l’API proposée par libvirt pour piloter KVM.
Sur l’aspect réseau, de base il est possible d’utiliser uniquement le CNI que vous aurez décidé de déployer avec votre cluster K8S, par exemple comme dans mon cookbook avec Cilium.
Mais pour l’usage de VMs, ce n’est pas forcément suffisant. En effet, on peut avoir besoin de déployer des machines virtuelles équipées de plusieurs interfaces réseau, ce qui n’est pas possible par défaut avec K8S.
Pour ça on va s’appuyer sur un meta driver CNI, Multus. Celui-ci va s’interfacer avec Cilium et va autoriser les objets K8S, comme les pods, et par extensions les nouveaux objets VM à utiliser plus qu’une interface réseau si nécessaire.
Enfin, pour reproduire une situation plus proche de la réalité ou l’on retrouve souvent sur un hyperviseur plusieurs cartes réseau physiques dédiées à des interconnexions spécifiques, on va utiliser macvtap.
C’est d’ailleurs à ce niveau qu’on note la plus grosse instabilité en raison du côté encore « alpha » de l’usage de macvtap avec Kubevirt. Ce CNI permet de subdiviser une carte physique en de multiples interfaces virtuelles qui vont pouvoir être utilisées par multus pour proposer les interfaces visibles dans les VMs.
En combinant toute ces couches, on peut arriver à gérer plusieurs VMs, mappées chacune à des réseaux spécifiques, voir à plusieurs réseaux spécifiques. On retrouve ainsi un schéma de fonctionnement plus classique, notamment quand on compare à VMware.
Attention, le drivers mactap existe depuis longtemps, mais son usage en tant que CNI est encore récent et pas toujours stable, notamment sur des cartes réseau un peu « exotique » comme ma petite realtek…c’est pourquoi je vous ai conseillé en début d’article d’avoir des chipsets compatibles SR-IOV qui permettent de se passer (en théorie du moins, je n’ai pas testé) de cette couche non stabilité du mappage de driver mactap dans une VM provisionnée par KubeVirt.
Définition de l'architecture cible
C’est bien toutes ces briques qui vont être utilisées pour arriver à la démonstration schématisée dans l’illustration suivante:
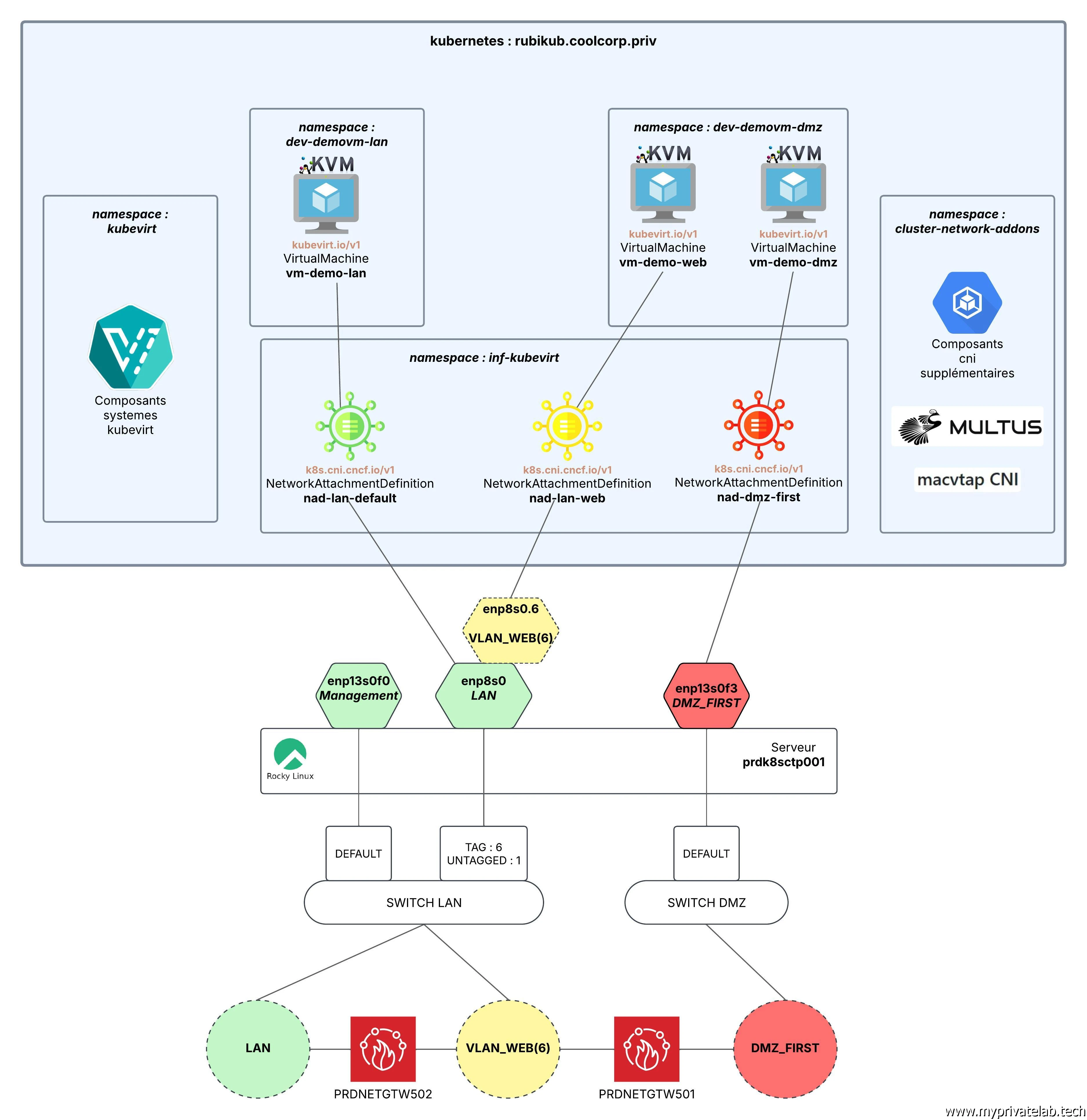
Cliquez sur l'image pour l'agrandir.
L’idée est de pouvoir proposer à la fin trois VMs.
- L’une mappée sur mon LAN: va utiliser l’interface physique realtek enp8s0
- L’une mappée sur mon VLAN WEB: va utiliser l’interface physique realtek enp8s0, mais avec le tag 6 pour générer une interface VLAN enp8s0.6
- L’une mappée sur ma DMZ : va utiliser l’interface physique rattachée au port 3 de ma carte broadcom, soit l’interface enp13s0f3
À noter que j’utilise le port 0 (enp13s0f0) de de ma carte broadcom, elle aussi sur le LAN comme port d’administration, dédiée à l’accès au serveur prdk8sctp001 lui-même et à l’API Kubernetes.
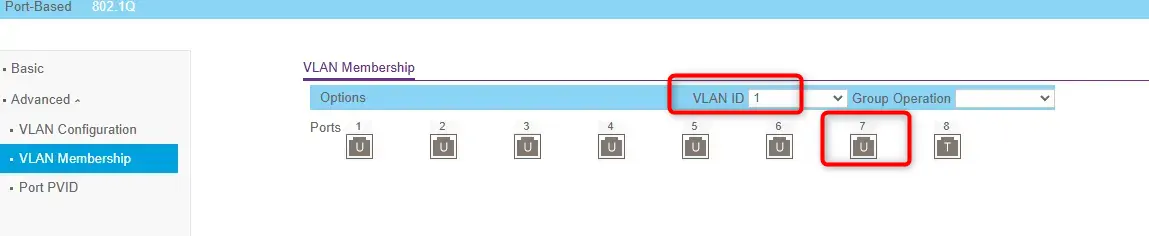
Il faut evidemment que les équipements réseaux en amont du serveur soient configurés correctement. C'est le cas ici sur le port 7 de mon switch (netgear) connecté à mon interface enp8s0: le port du switch et taggé sur le VLAN6 et untagged sur le 1
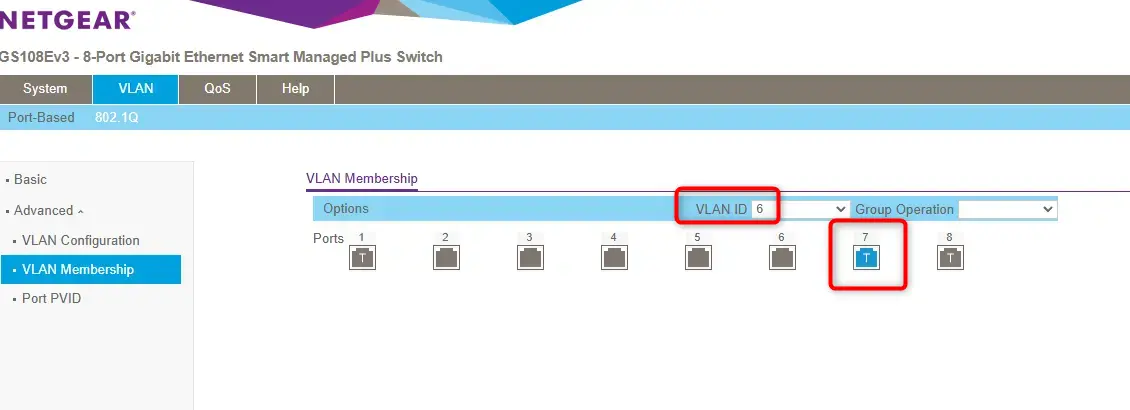
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
On n’aura ainsi une illustration complète basée sur mon lab d’origine et mes zones réseau utilisées dans le cadre de l’hébergement des VMs sous VMware et XCP-NG.
Maintenant que la théorie est exposée, on passe aux premières actions.
Mise en place des prérequis
Changement des drivers par défault Realtek
Première mission, essayer de limiter la casse avec ma carte Realtek. Cette partie est facultative si vous n’avez pas de carte de ce type. Mais j’ai tellement galéré que je me dis que ça pourrait servir à certains.
Dans mon schéma présenté précédemment, cette carte doit à la fois délivrer le LAN et le VLAN WEB à mes VMs sous Kubevirt.
Par défaut, celle-ci exploite un vieux driver nommé R8169 qu’on peut identifier avec la commande:
ethtool -i enp8s0
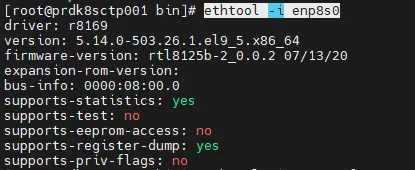
Cliquez sur l'image pour l'agrandir.
Il est clairement inadapté à mon usage et il va falloir se baser sur le driver r8125
Pour cela on commence par retirer le module du driver R8169 (en root):
rmmod r8169

Cliquez sur l'image pour l'agrandir.
Puis on installe un repo complémentaire, elrepo:
dnf install -y elrepo-release
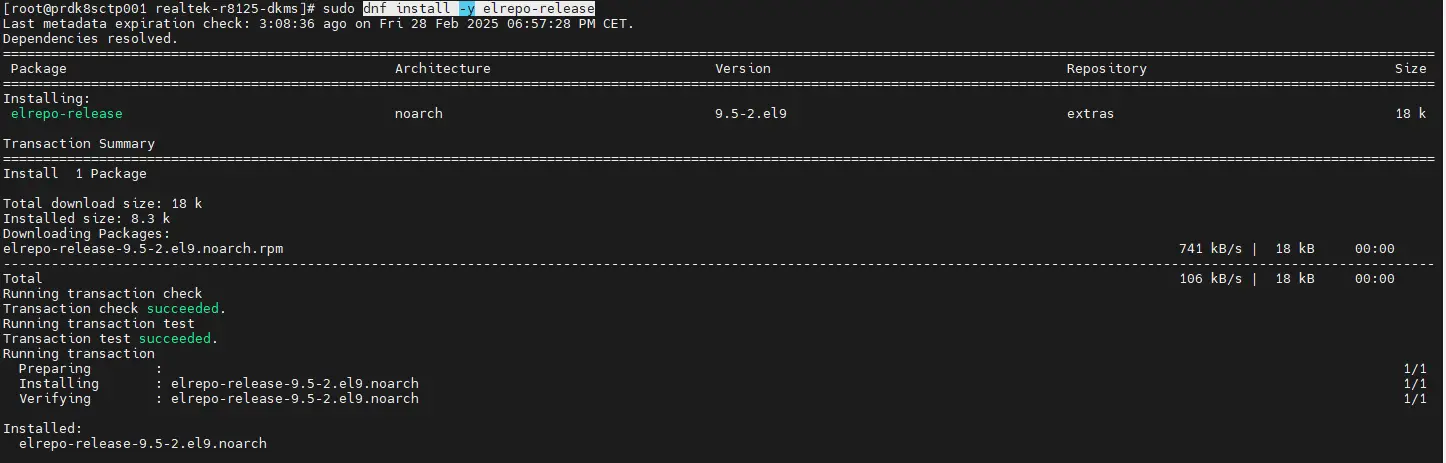
Cliquez sur l'image pour l'agrandir.
Celui va nous permettre d’accéder au driver r8125 et de l’installer:
dnf install -y kmod-r8125
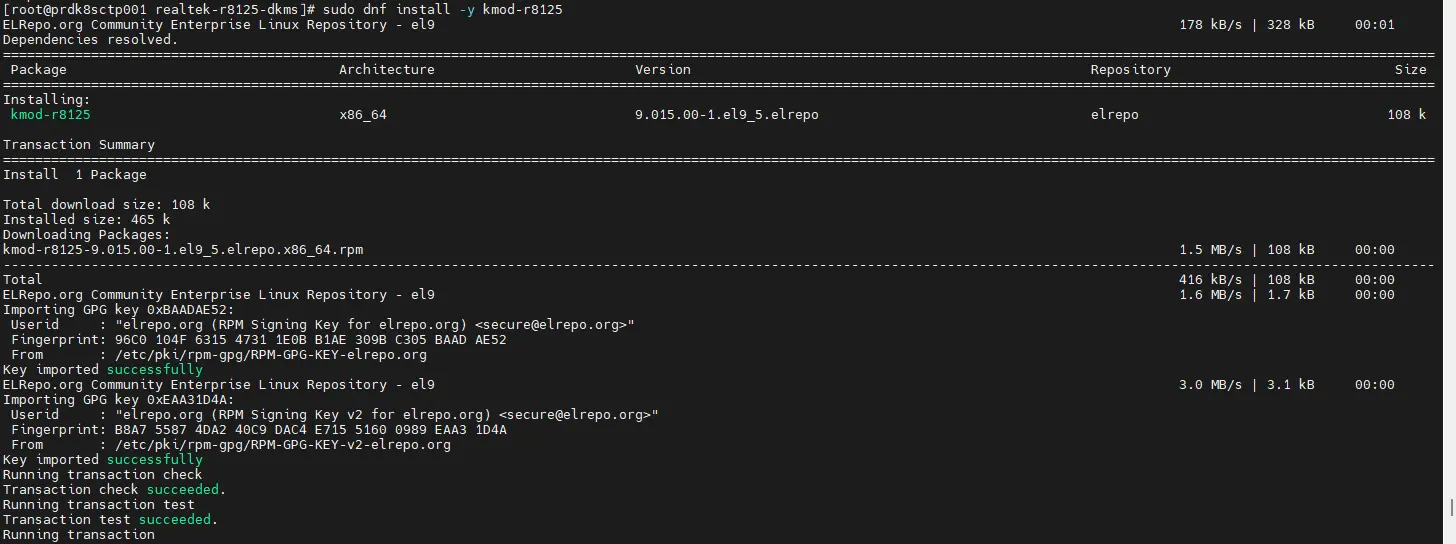
Cliquez sur l'image pour l'agrandir.
On monte le module associé:
modprobe r8125

Cliquez sur l'image pour l'agrandir.
Normalement si on retape ethtool -i enp8s0, on n’a la confirmation que c’est le nouveau driver qui est monté.
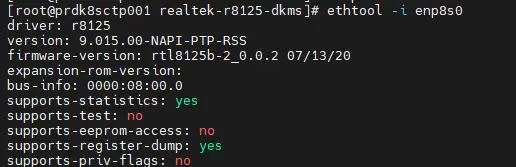
Cliquez sur l'image pour l'agrandir.
Il faut rendre cela persistant, donc on créer un fichier de blacklist pour éviter de charger le module r8169:
echo "blacklist r8169" | sudo tee /etc/modprobe.d/blacklist-r8169.conf
dracut -f
On s’assure du chargement du module r8125 au démarrage:
echo "r8125" | sudo tee /etc/modules-load.d/r8125.conf
dracut -f

Cliquez sur l'image pour l'agrandir.
Puis on reboot pour être sûre de la configuration.
Un petit check via la commande ethtool -i enp8s0 devrait nous rassurer.
Définitions des profils réseau
Pour rendre les choses plus simples pour la suite, il est conseillé d’organiser ses interfaces en réseau en cohérence avec la cible à atteindre.
On peut utiliser pour cela l’outil nmtui.
Cela permet graphiquement de nommer ses interfaces et d’appliquer une configuration de base.
En l’occurrence, on va créer:.
- une configuration data-network rattachée à mon interface enp8s0
- une configuration dmz-network rattachée à mon interface enp13s0f3
- une configuration console-network à mon interface enp13s0f0
Cliquez sur l'image pour l'agrandir.
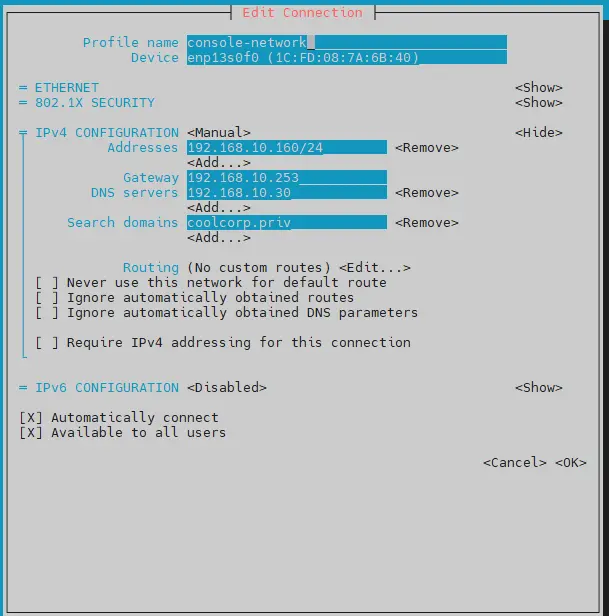
Cliquez sur l'image pour l'agrandir.
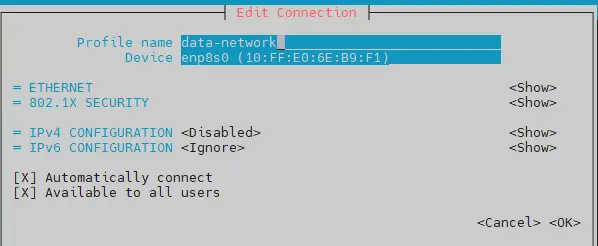
Cliquez sur l'image pour l'agrandir.
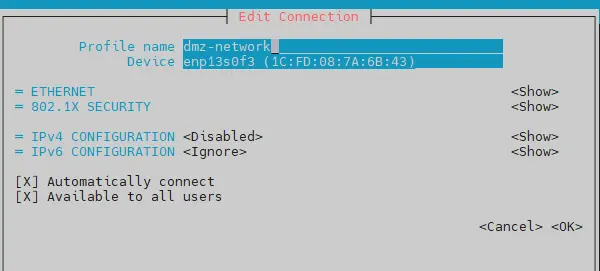
Cliquez sur l'image pour l'agrandir.
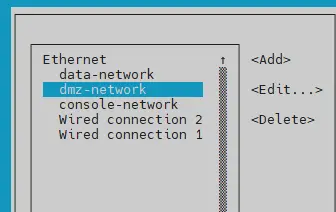
Cliquez sur l'image pour l'agrandir.
La partie console-network est déjà opérationnelle puisque l’interface enp13s0f0 a été utilisée dès l’installation de l’OS pour héberger l’IP de base (192.168.10.160). C’est la seule carte à être utilisée directement.
Pour les autres configurations il n’y a pas d’IP a attribuer puisqu’elles vont être utilisées à travers des interfaces virtuelles qui elles porteront les IP finales.
Une fois les profils déclarés avec nmtui, on peut basculer sur son équivalent en mode CLI, soit nmcli pour simplifier la configuration sur ces profils que nous venons de créer:
nmcli connection modify data-network ipv4.method disabled ipv6.method ignore
nmcli connection modify dmz-network ipv4.method disabled ipv6.method ignore

Cliquez sur l'image pour l'agrandir.
Il manque néanmoins une interface, celle rattachée au VLAN 6. Il faut la « dériver » à partir de la carte enp8s0 pour créer l'interface enp8s0.6 dans un profil vlan-enp8s0.6
On passe la aussi par nmcli:
nmcli connection add type vlan ifname enp8s0.6 dev enp8s0 id 6
nmcli connection modify vlan-enp8s0.6 ipv4.method disabled ipv6.method ignore
nmcli connection up vlan-enp8s0.6

Cliquez sur l'image pour l'agrandir.
Il est nécessaire de bien s’assurer que toutes nos interfaces et les configurations associées soient OK.
nmcli connection show
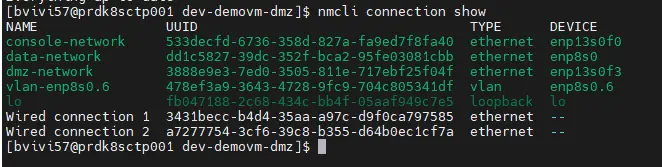
Cliquez sur l'image pour l'agrandir.
Il reste encore un petit point à régler, toujours à cause de realtek…. Certaines fonctionnalités de la carte posent problème avec l’usage que nous souhaitons en avoir, même avec le nouveau driver.
C’est l’accélération des vlan, le genre de fonction censée soulager le CPU et exploiter le hardware de la carte dans la gestion des vlans….ici c’est contreproductif puisque ça ne permet tout simplement pas d’utiliser macvtap correctement.
Il faut donc désactiver cette prise en charge, encore avec nmcli:
nmcli connection modify data-network ethtool.feature-rxvlan off
nmcli connection modify data-network ethtool.feature-txvlan off

Cliquez sur l'image pour l'agrandir.
On peut vérifier que la fonction est bien désactivée avec la commande ethtool -k enp8s0 | grep vlan
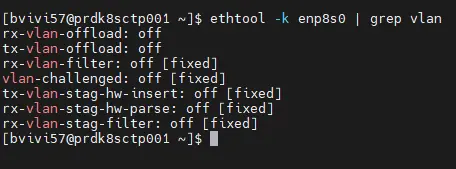
Cliquez sur l'image pour l'agrandir.
(pour rappel le profil data-network est rattaché à la carte realtek enp8s0. A noter que cette désactivation n'est pas forcément à réaliser sur une carte non Realtek, mais ça peut aider si vous rencontrez des problèmes de VLAN).
Installation de KVM
Dernières étapes concernant cette partie sur les prérequis, l’installation de KVM et des dépendances nécessaire à la virtualisation.
Soyez déjà certains d’avoir une configuration matérielle compatible, avec surtout un CPU disposant des instructions devenues depuis longtemps obligatoires pour tout hyperviseur. C’est le cas de tous les processeurs modernes, mais parfois l’option n’est pas activée au niveau du bios de la carte mère.
Pour contrôler, utilisez la commande lscpu | grep Virtualization.

Cliquez sur l'image pour l'agrandir.
Vous devriez obtenir un retour positif qui peut varier fonction de la marque de votre CPU, Intel ou AMD (Intel VT-x / AMD-V). Si rien ne s’affiche, alors faites un tour au niveau de votre bios de carte mère dans les options dédiées au processeur.
Une fois ce contrôle réalisé, vous pouvez basculer à l’installation de KVM avec les commandes
dnf install qemu-kvm libvirt virt-install virt-manager virt-viewer edk2-ovmf swtpm qemu-img guestfs-tools libosinfo tuned
Cliquez sur l'image pour l'agrandir.
Bien entendu, j’utilise ici le gestionnaire de package dnf étant sur un OS « redhat like », à vous d’adapter fonction de votre système.
On s’assurer du démarrage de libvirtd et de son activation au démarrage:
systemctl start libvirtd
systemctl enable --now libvirtd
systemctl status libvirtd
Cliquez sur l'image pour l'agrandir.
je vous encourage également à associer votre utilisateur au groupe libvirt et kvm pour l’autoriser à déployer des VMs. Même si ce n’est pas utilisé côté Kubernetes, vous pourriez en avoir besoin pour des cas de debug.
usermod -a -G libvirt votre_user
usermod -a -G kvm votre_user
Contrôler que le module KVM est bien chargé : lsmod | grep kvm
Cliquez sur l'image pour l'agrandir.
Conclusion
À ce stade du déploiement, je ne peux m’empêcher de comparer cette première expérience avec mes premiers pas sur VMware il y a plus de 10 ans déjà…comme pour l’hyperviseur historique devenu cible à abattre pour beaucoup, kubevirt semble exiger une certaine rigueur dans le choix du matériel, spécifiquement sur les cartes réseaux.
KVM a déjà ses propres contraintes, mais l’ajout de multiples couches CNI n’arrange rien. C’est d’ailleurs aussi une première leçon à retenir…avec Kubevirt on est bien dans la logique K8S…du modulaire et beaucoup d’assemblage de composants tiers partageant des standards communs articulés autour de Kubernetes. C'est comme pour les services IT, on travaille mieux en équipe :).
Nous voilà arrivés au bout de ce premier article. Il y’a déjà beaucoup de fondamentaux à assimiler et il vaut mieux procéder par étape. Pour ceux qui souhaitent poursuivre (maintenant ou plus tard), la suite de l'aventure se passe ici