Étape 10: Déploiement d'une application
Introduction
Cet article conclut cette partie du site consacré au CookBook Kubernetes Onprem.
Concevoir et mettre en œuvre une infrastructure d’exécution, n’a de sens que si elle est destinée à porter des applications souhaitées par les métiers.
L’infrastructure doit aussi pouvoir répondre au besoin des développeurs. Proposer l’architecture qui nous parait techniquement la plus élégante n’a aucun intérêt si elle n’est pas adoptée par ceux qui vont l’utiliser pour y déployer leurs assets.
C’est pourquoi il était important de finir ce tutoriel autour de Kubernetes par la mise en œuvre d’une application qui va pouvoir tirer parti de tout ce qui a été présenté précédemment.
À titre, d’exemple c’est le CMS (content management system) Wordpress qui va être utilisé. Loin des applications microservices, on n’est plutôt sur un logiciel "classique", mais largement utilisé et mise en œuvre dans de nombreux écosystèmes et entreprises.
Le but est aussi de montrer que Kubernetes n’est pas réservé à des architectures logicielles spécifiques, mais peu très bien héberger tous types d’applications.
Afin de mieux appréhender la suite, il est conseillé d’avoir suivi les articles précédents dans l’ordre de leur publication, a minima la première partie chargée de présenter la cible Kubernetes mise en œuvre et les grands principes qui s’y rattachent.
Quelle cible pour le cluster et quels choix d'architecture retenir.
Usage de Terraform/OpenTofu pour déployer les VMs.
Usage d'Ansible pour préparer les serveurs et installer les dépendances.
Templatisation des fichiers de configuration et copie de ces derniers à la cible.
Installation de HAProxy en front et préparatifs divers.
Déploiement de K8S, du CNI Cilium, mise en place des alias et des taints.
Déploiement du CPI/CSI vSphere pour le stockage persistant.
Usage de Traefik pour exposer les applications à l'extérieur.
Déploiement de CertManager pour automatiser le cycle de vie des certificats.
Je vous invite également fortement à prendre connaissance des différentes définitions rédigées sur ce site, notamment la définition de Kubernetes, du Pod, du Namespace, du Deployment et du Service.
La mise en place d’une application sous K8S consiste principalement à manipuler des objets qui vont s’articuler entre eux pour assurer l’exécution de l’application et son accès aux utilisateurs.
Avant de démarrer l'exemple, il est conseillé d'avoir à minima le modèle de base en tête. La logique minimaliste est d'exploiter un Namespace, dans lequel un Deployment va gérer le cycle de vie d'un Pod. Les conteneurs hébergés dans ce Pod pourront être exposés à l'aide d'un Service. La capacité d'un Deployment à gérer le Pod et la capacité du Service à exposer le Pod dépendront d'un ensemble de labels qui permettront d'associer les objets entre eux.
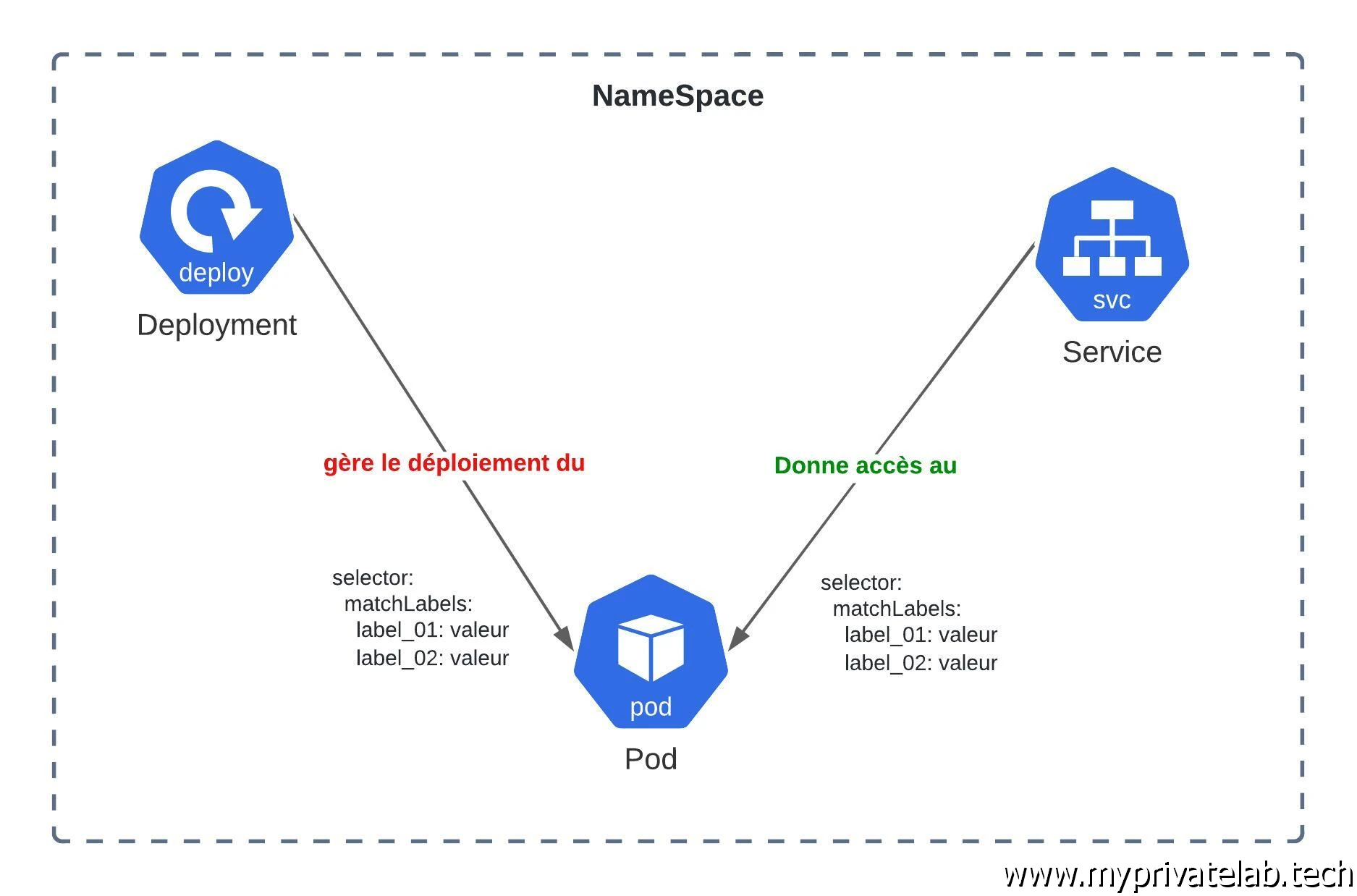
Cliquez sur l'image pour l'agrandir.
Préparatifs
Pour déployer une application sous Kubernetes, il est d’abord intéressant d’analyser les différentes briques qui la composent, pour pouvoir ensuite y associer les objets Kubernetes qu’il nous sera nécessaire de créer.
Dans le cas de Wordpress, on est dans une configuration assez classique d’une application reposant sur une base de données et un frontal web.
On arrive déjà rapidement à la conclusion qu’il nous faudra déployer deux composants principaux:
- Un moteur de base de données: Wordpress étant compatible avec plusieurs solutions, j’ai décidé de retenir MariaDB dans sa version 10.5 (une version un peu ancienne mais fonctionnelle).Sous une forme conteneurisée, elle nécessitera un stockage persistent performant accessible uniquement par un seul conteneur à la fois. Son exposition n’a pas vocation à se faire à l’extérieur du cluster.
- Un front: basé sur l'image officiel Wordpress, j’ai choisi de retenir la version 6.6.1. L’image inclut un serveur web Apache. Cette partie de l’application nécessite également un stockage persistant, mais destiné à héberger uniquement des fichiers à plat. Il va être possible d’imaginer plusieurs instances du front qui se partage ce stockage.
Ces deux composants vont devoir discuter entre eux et le front devra pouvoir accéder à sa base via des identifiants de connexions.
Le front devra être joignable de l’extérieur, et sur un protocole sécurisé HTTPS (Hyper Text Transfer Protocol Secure).
Cette décomposition n’a rien d’exceptionnel, mais elle permet de se projeter en termes d’objets Kubernetes.
Identification des objets
Pour des raisons d’isolation et des besoins éventuels de segmentation d’administration et de ressources, le premier objet Kubernetes à utiliser est un namespace.
Cela va nous permettre d’établir un périmètre d’exécution de l’application.
Dans ce namespace, nous allons être amenés à déployer nos deux composants.
Nous allons donc avoir un deployment dédié à la base de données qui va s’appliquer à gérer un pod hébergeant l’image de MariaDB.
Le second deployment sera dédié à la partie web et chargé du cycle de vie des pods hébergeant les instances front Wordpress.
Le pod associé à la base de données aura besoin d’un stockage persistant de type bloc et passera donc par l’usage d’un PersistentVolumeClaim (pvc), qui lui-même fera appel à un PersistentVolume (pv).
Les pods associés à la partie front auront quant à eux besoin d’un stockage partagé, qui reposera sur un filesystem de type NFS (Network File System), mais toujours avec un PersistentVolumeClaim (pvc), et un PersistentVolume (pv).
Si vous êtes un peu perdu sur le storage, n'hésitez pas à lire cet article du cookbook qui détaille le principe des pv et pvc.
Le pod de la BDD devra être exposé à l’intérieur du namespace pour être accessible aux pods front.
Les pods front devront être exposés à l’extérieur du cluster, avec un certificat associé à leur URL.
Enfin, les pods front accèderont au pod BDD en se présentant avec des identifiants qu’il faudra stocker dans un Secret.
Le plus simple et de résumer le tout dans un schéma:
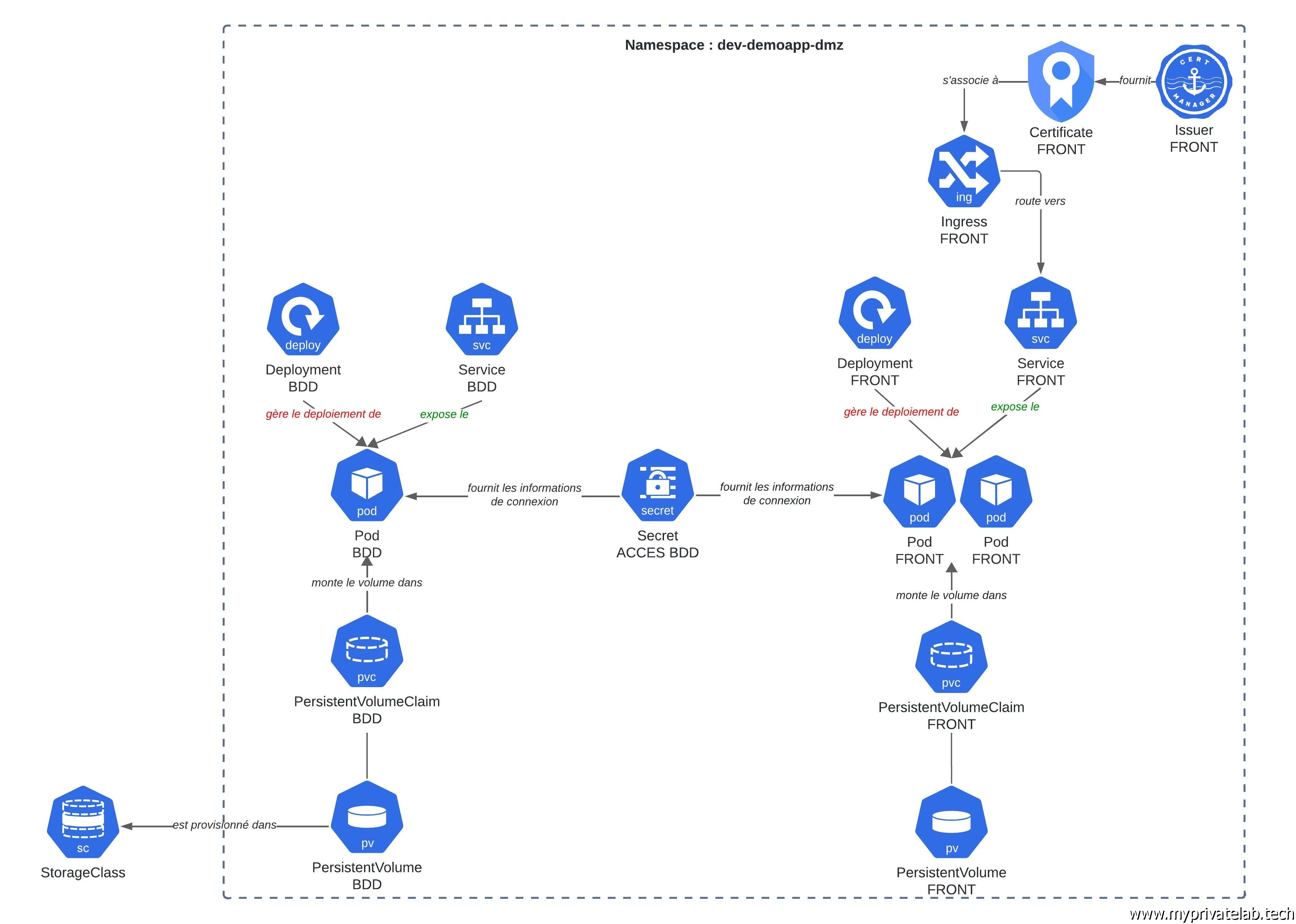
Cliquez sur l'image pour l'agrandir.
Creation des objets
Maintenant que nous savons de quoi nous avons besoin, nous allons pouvoir démarrer l’écriture de nos yaml, en s’appuyant sur la nomenclature décidée lors de la définition de notre cluster k8s.
Namespace: 01-ns-demoapp-default-dmz.yml
Le namespace peut se décrire dans le fichier 01-ns-demoapp-default-dmz.yml.
---
apiVersion: v1
kind: Namespace
metadata:
name: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
Très peu d’informations à préciser dans le fichier en dehors du nom du namespace (ici dev-demoapp-dmz). On n’oublie pas les labels pour clairement identifier l’objet.
Secret: 02-secret-demoapp-bdd-dmz.yml
On poursuit par le Secret. Celui-ci a vocation à stocker trois informations confidentielles.
- Le mot passe root mariadb.
- Le mot de passe utilisateur de la base de données.
- Le login de l’utilisateur de la base de données.
En effet, on ne va se contenter d’utiliser le compte par défaut root mais on va bien créer un utilisateur dédié.
Ce n’est pas parce qu’on n’est en conteneur qu’on n’en oublie les bonnes pratiques.On conserve nos labels et on peut décrire le tout dans un fichier 02-secret-demoapp-bdd-dmz.yml.
---
apiVersion: v1
kind: Secret
metadata:
name: secret-demoapp-bdd-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: bdd
type: Opaque
data:
mariadb-root-password: mot_de_passe_en_base64
mariadb-user-password: mot_de_passe_en_base64
mariadb-user: user_en_base64
Point très important à noter sur les Secrets. Ils n’ont finalement de secret que leur nom…en effet un Secret stocke ses informations en base64 (c'est sous cette forme qu'il faudra les renseigner dans le yaml). Ils ne sont absolument pas chiffrés.
Cela implique que tout utilisateur disposant d’accès au cluster et ayant le droit de lire le contenu d’un Secret peut retrouver les mots de passe d’origine. C’est pourquoi si l’usage des Secrets est une première bonne pratique en termes de sécurité, on peut par la suite exploiter des outils tiers comme Vault pour héberger ses Secrets de manière vraiment sécurisée. Mais ce n’est pas le but de cet article, a minima assurez-vous toujours que les objets de type Secret ne puissent être manipulés que par des utilisateurs clairement identifiés et limités.
PersistentVolumeClaim: 03-pvc-demoapp-bdd-dmz.yml
On s’attaque ensuite au pvc dédié à la base de données. Celui-ci va permettre de provisionner à la demande un volume dans la StorageClass (sc) prd-sc-vmfs-default-na correspondant à notre driver CSI (Container Storage Interface) vSphere.
N’hésitez pas à lire cet article pour bien comprendre ce point.
Voici le contenu du fichier 03-pvc-demoapp-bdd-dmz.yml:
---
kind: "PersistentVolumeClaim"
apiVersion: "v1"
metadata:
name: pvc-demoapp-bdd-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: bdd
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: "10Gi"
storageClassName: prd-sc-vmfs-default-na
En termes d’informations, on retrouve le mode d’acces ReadWriteOnce. En effet, le moteur mariadb n’acceptera pas de travailler sur un filesytem pouvant être accédé en simultané à d’autre assets.
On n’est dans un modèle d’instance de base classique ou celle-ci accède à sa donnée à travers un filesytem local. Sauf qu’ici ce filesytem local sera en réalité un VMDK (volume vSphere) mappé à la volée au node qui exécutera le pod mariadb.
Le VMDK suivra le pod si celui-ci est amené à être exécuté sur un autre node, en cas d’incident par exemple…mais à instant T il n’y aura toujours qu’un seul pod mariadb autorisé à accéder au volume.
(À noter que cet exemple s'appuie sur le CSI (Container Storage Interface) vSphere et donc sur une technologie de stockage VMware (d'ou le VMDK). La logique reste cependant applicable à tout autre driver CSI et solution de stockage tiers compatible.)
Le volume provisionné aura une taille de 10Gi.
Deployment: 04-deploy-demoapp-bdd-dmz.yml
On peut maintenant s’attaquer à l’objet deployment de notre base de données.
Voici le contenu du fichier 04-deploy-demoapp-bdd-dmz.yml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-demoapp-bdd-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: bdd
spec:
replicas: 1
selector:
matchLabels:
environment: dev
network: dmz
application: demoapp
tiers: bdd
template:
metadata:
labels:
environment: dev
network: dmz
application: demoapp
tiers: bdd
spec:
nodeSelector:
network: dmz
tolerations:
- key: "node-role.kubernetes.io/worker-dmz"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: mariadb
image: mariadb:10.5
ports:
- containerPort: 3306
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "1Gi"
cpu: "1"
env:
- name: MARIADB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: secret-demoapp-bdd-dmz
key: mariadb-root-password
- name: MARIADB_DATABASE
value: wordpressdb
- name: MARIADB_USER
valueFrom:
secretKeyRef:
name: secret-demoapp-bdd-dmz
key: mariadb-user
- name: MARIADB_PASSWORD
valueFrom:
secretKeyRef:
name: secret-demoapp-bdd-dmz
key: mariadb-user-password
volumeMounts:
- name: mariadb-storage
mountPath: /var/lib/mysql
livenessProbe:
exec:
command:
- /bin/sh
- -c
- mysqladmin ping -u root -p$MARIADB_ROOT_PASSWORD
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
exec:
command:
- /bin/sh
- -c
- mysql -u root -p$MARIADB_ROOT_PASSWORD -e "SELECT 1"
initialDelaySeconds: 5
periodSeconds: 10
volumes:
- name: mariadb-storage
persistentVolumeClaim:
claimName: pvc-demoapp-bdd-dmz
En termes de spécifications, nous allons travailler sur un replica de 1, car dans notre modèle, on ne peut pas avoir plusieurs instances de moteur de base de données.
On n’y reprend nos labels habituels, sauf qu’ils apparaissent à plusieurs reprises. C’est très important à comprendre.
Il y'a d’abord les labels associés à l’objet Deployment en tant que tel, puis dans la partie spec, dans la sous partie selector on retrouve les labels qui vont permettre au deployment de rattacher les pods dont il a la charge.
Enfin, on retrouve ces labels dans la partie template qui seront appliqués au pod exécuté. Si les labels qui se trouvent au niveau du template du pod ne sont pas cohérent avec les labels qui se trouvent dans la partie selector du Deployment, alors cela ne fonctionnera pas (revoyez le premier schéma de l'article).
Si on poursuit dans la section template, on retrouve toutes les caractéristiques de notre Pod. À savoir que celui-ci n’hébergera qu’un seul conteneur reposant sur l’image mariadb:10.5.
Là aussi c’est très important de figer la version des images à utiliser. Rester sur un tag de type latest est une très mauvaise idée, car vous ne maitrisez plus les versions potentielles des applications qui s’y rattachent. Si côté registry docker, le tag latest est mis à jour, vous risquez d’avoir une montée de version non souhaitée de votre base.
Une autre bonne pratique consiste à utiliser des options de ressources.
Cela permet de fixer les besoins de votre container selon deux principes:
- Requests: ce sont les ressources minimales à avoir pour que votre conteneur puisse démarrer. Dans l’exemple, j’impose au minimum 512 MiB (mébibytes) de mémoire et 500 milliCPU, soit 0,5 vCPU (1CPU = 1 cœur CPU sur la machine hote). C’est un peu barbare comme unité, mais ça permet de s’assurer que le conteneur démarre avec des ressources minimums pour fonctionner correctement. Attention, cela implique aussi que dans le cas où ces ressources ne sont pas disponibles sur le cluster, alors Kubernetes n’exécutera jamais le pod.
- Limits: ce sont les ressources maximales autorisées à être consommées par le conteneur. En l’occurrence dans l’exemple 1 GiB (gibibyte) de mémoire et 1vCPU. Si pour une raison ou pour une autre, la mémoire venait à dépasser cette limite, alors le conteneur sera "killé" par Kubernetes pour être relancé. Par contre, il n’y aura pas de coupure pour le CPU, car dans tous les cas, le conteneur ne pourra jamais occuper plus d’un vCPU.
Il est très important de mettre en place une politique sur les ressources.
Cela va permettre d’établir une QoS (Qualite Of Service) qui peut prendre trois positionnements:
- Garantie : vos ressources positionnées en request sont égales à vos ressources positionnées en limits. De cette manière vous garantissez l’éxécution de vos assets avec toujours le meme niveau de ressources et le cluster s'assurera d’avoir toujours de la disponibilité (jusqu'au maximum possible). Par contre, vous pouvez gaspiller de la ressources. Si vos conteneurs ne consomment pas ce que vous avez déclarés, étant donné que vous les avez fixé notamment au niveau request, pour le cluster c’est considéré comme un réservation obligatoire et non réaloubale.
- Burstable : Vos request sont inferieures à vos limits. De cette manière vous autorisez vos pods à dépasser ce qu’il sont censé consommé jusqu’à une certaines limits. Vous pouvez ainsi optimisez davantage l’usage de vos ressources en dimunant la capacité du cluster a garantir tout ce que vous avez besoin.
- BestEffort : vous ne fixez rien, pas de request et pas de limits. Ce qui est déconseillé car votre cluster ne disposant d’aucune consigne se contentera de faire au mieux avec le risque que tout le monde se marche dessus.
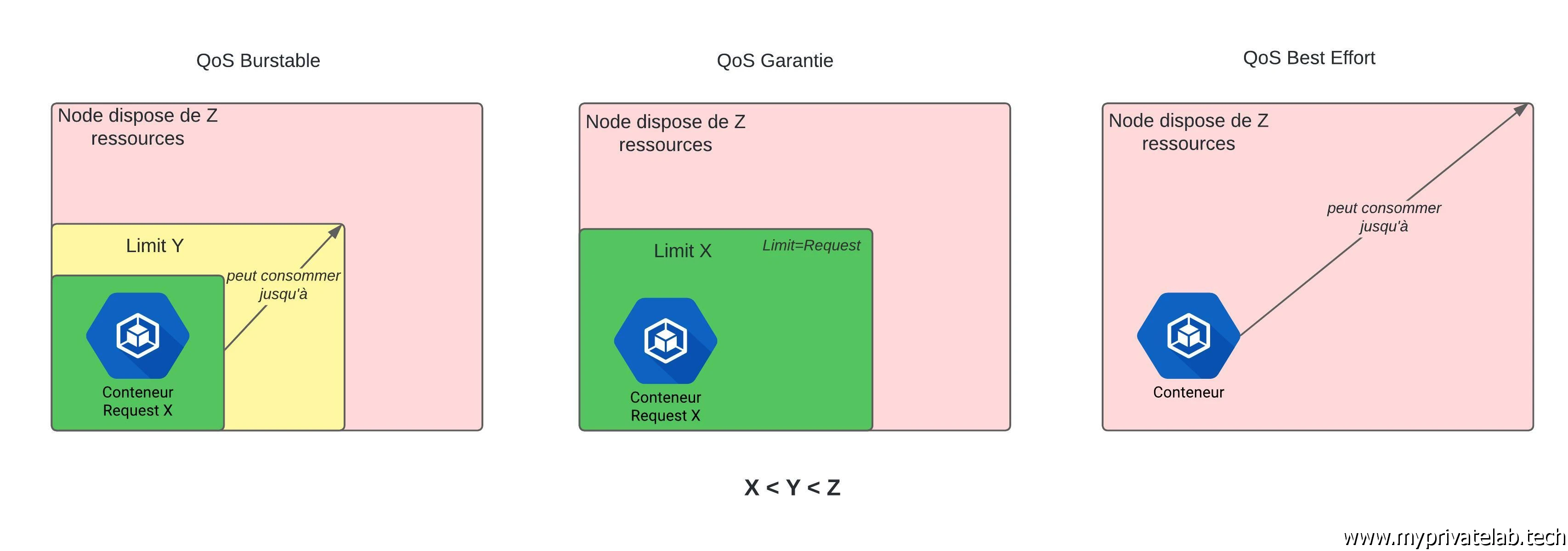
Cliquez sur l'image pour l'agrandir.
Le pire reste de ne rien mettre (Best Effort). Il ne faut pas oublier qu’une infra Kubernetes est destinée à faire tourner énormément d’assets. Il faut savoir garder la maitrise de sa consommation…au risque de voir des conteneurs pénaliser d’autres conteneurs.
La partie env permet de préciser toutes les variables d’environnement qui vont pouvoir être passées au conteneur. Il s’agit simplement de s’appuyer sur la documentation de l’image mariadb qui renvoie vers les noms à utiliser.
La subtilité est que si certaines variables sont fixées directement dans le deployment, comme le nom de la base de données via MARIADB_DATABASE, d’autres, plus critiques, pointent vers notre Secret créé précédemment.
Même si un secret ne chiffre pas son contenu, le fait de l’utiliser permet de concevoir un fichier deployment qui ne contient aucun mot de passe ou donnée critique. Il peut donc être librement partagé. La personne qui l’écrit n’a pas à connaitre les identifiants de la base.
On poursuit avec la section volumeMounts. Le but est d’associer un volume (dont la référence est plus bas dans le fichier) au point de montage dans le conteneur, à savoir ici /var/lib/mysql.
Ce qui suit est très intéressant et très important. Il s’agit de définir les sondes à utiliser pour permettre à Kubernetes de connaitre l’état du conteneur.
On trouve deux types de sondes.
- livenessProbe: cette sonde détermine si le conteneur est en bonne santé ou non. Il n’est pas impossible d’avoir des cas de figure ou le process associé au conteneur est toujours up, mais pour autant il est défaillant et ne répond pas correctement…dans ce cas Kubernetes maintient en vie un conteneur qui ne répond plus au service demandé. L’usage d’une sonde type livenessProbe va permettre à K8S d’exécuter une commande au sein du conteneur et, fonction de la sortie, prendre la décision de redémarrer le conteneur (donc le pod). En l’occurrence il s’agit ici de faire une commande de ping mysql, 30 secondes après le démarrage du conteneur et exécutée par la suite toutes les 10s.
- readinessProbe: cette sonde détermine si le conteneur est apte à accueillir des requêtes. On peut très bien se trouver dans une situation ou le conteneur est démarré, il répond à sa sonde livenessProbe, mais pour autant il n’est pas encore prêt à traiter des requêtes. C’est souvent le cas avec des applications Java par exemple qui vont nécessiter un certain temps et des conditions spécifiques avant de pouvoir prendre en compte des traitements. En l’occurrence ici il s’agit de faire une requête en base. Si la requête répond, alors Kubernetes acheminera le trafic vers le pod, si ce n’est pas le cas, le pod sera mis en statut notready et les requêtes seront mises en attentes.
Pour résumer notre exemple, on s’assure en permanence que le moteur mariadb est UP, si c’est le cas le conteneur reste en vie et on s’assure que le moteur puisse répondre à des requêtes.
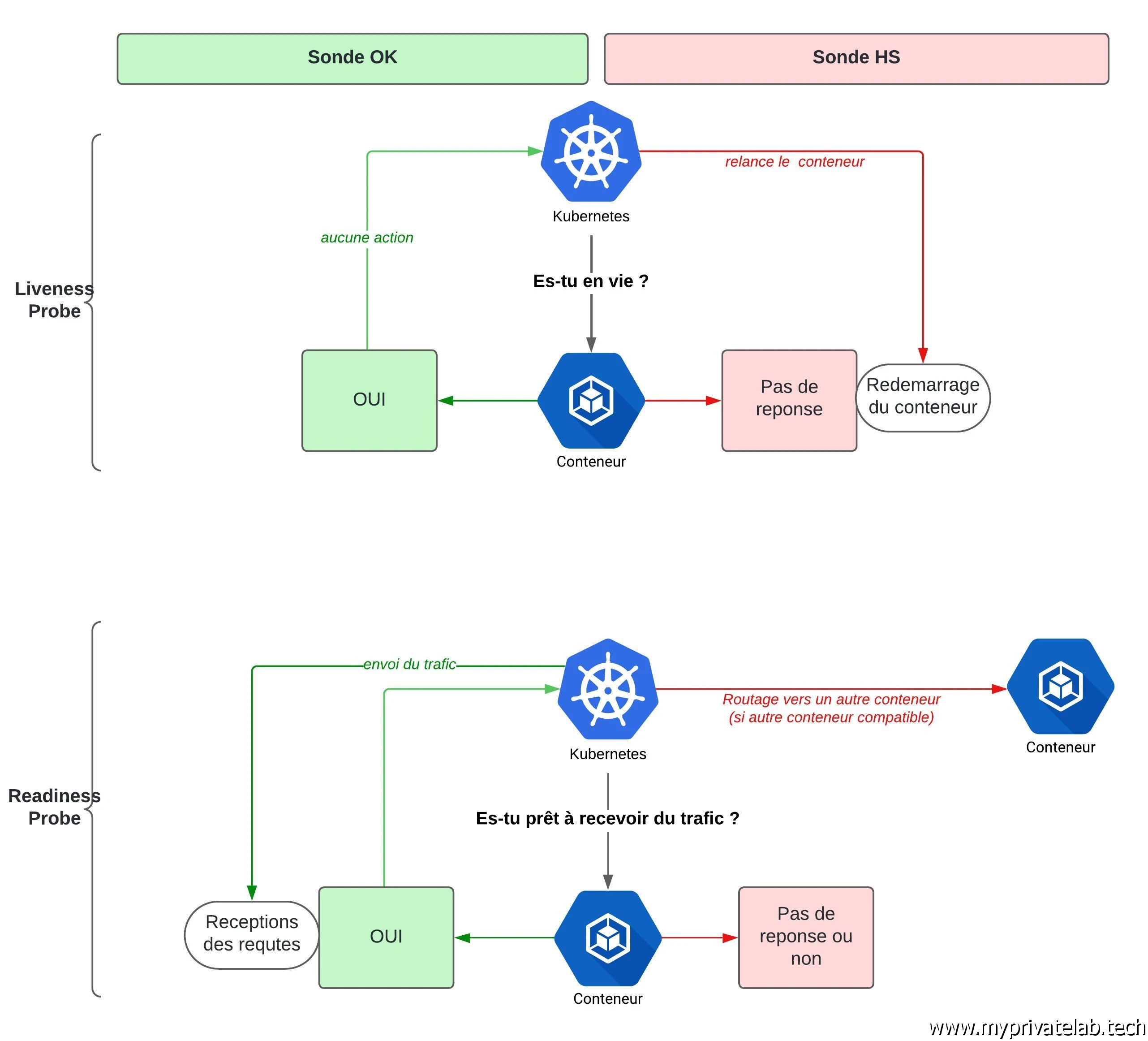
Cliquez sur l'image pour l'agrandir.
L’usage de sonde est extrêmement important. Ne pas les utiliser vous expose à laisser tourner des conteneurs fantômes qui ne remplissent pas leur rôle.
Enfin on termine par la définition du volume. Celui-ci fait directement référence à notre pvc. Le deployment va donc faire appel au pvc qui lui-même va provisionner le pv dans notre sc. Ce volume sera nommé mariadb-storage pour être ensuite monté dans le chemin /var/lib/mysql du conteneur.Si vous suivez c’est en faite le VMDK provisionné par le driver CSI vSPhere qui va se retrouver mappé.
Il est temps de s’arrêter un peu avant de poursuivre. Ce deployment est bien plus complexe que celui présenté en définition. C’est un point important à comprendre, car un objet Kubernetes n’impose pas forcément toutes les propriétés qu’il est possible de lui associer.
Seuls quelques attributs minimums sont obligatoires…Ce qui ne veut pas dire que vous devez vous contenter des bases. L’usage de sondes et de ressources est par exemple très importants à intégrer.
Service: 05-service-demoapp-bdd-dmz.yml
La base de données à besoin d’être accessible au front, il faut donc l’exposer via un service.
Celui-ci est décrit dans le fichier 05-service-demoapp-bdd-dmz.yml:
apiVersion: v1
kind: Service
metadata:
name: service-demoapp-bdd-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: bdd
spec:
type: ClusterIP
ports:
- port: 3306
targetPort: 3306
selector:
environment: dev
network: dmz
application: demoapp
tiers: bdd
Sur ce fichier, l’important est bien entendu la partie label, au niveau de la section selector. Comme pour le deployment, il faut que ces labels soient en adéquation avec ceux positionnés au niveau du pod.
C’est ainsi que le service sera en mesure de rediriger ce qui lui arrive sur le port 3306 vers le port 3306 du pod.
La partie mariadb est maintenant complète.
On peut s’attaquer au front.
PersistentVolume: 06-pv-demoapp-front-dmz.yml
On démarre par la création d’un PersistentVolume (pv). Contrairement à la base de données, on ne passe pas par une StorageClass (sc), on ne pourra pas avoir une création automatique du volume.
Voici le contenu du fichier 06-pv-demoapp-front-dmz.yml:
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-demoapp-front-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.10.152
path: /Volume1/nfsshare/kub.coolcorp.priv/namespaces/dev-demoapp-dmz/wordpress
Dans ce fichier, on précise les caractéristiques de notres pv. À savoir un accès possible depuis plusieurs pods avec l’option ReadWriteMany et une capacité de 10Go.
Comme on n’exploite pas une sc on indique directement que ce pv exploite un serveur NFS (Network File System) en y indiquant l’IP du serveur et l’export associé. Cela implique bien entendu que vous ayez ce type de storage de disponible et de configuré.
En termes d’accès NFS, il faut que l’export soit autorisé à être accessible à tous les nodes du cluster susceptible de faire tourner les pods Wordpress.
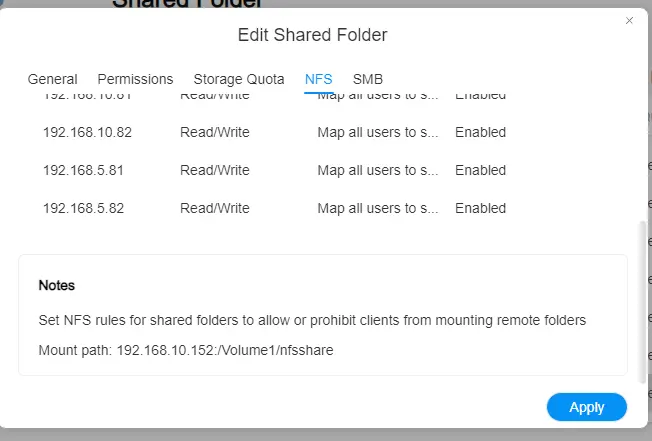
Cliquez sur l'image pour l'agrandir.
(Update 16/06/2024) À noter que dans cet exemple, je manipule un pv directement sans passer par un driver au standard CSI. Si au moment d'écriture de cet article cela reste possible, dans les futures versions de Kubernetes, ce type d’usage ne sera plus permis. Il y’aura l’obligation de passer par un driver CSI. Pour plus d’informations sur cette manière de faire pour mapper un volume NFS, n’hésitez pas à jeter un œil à cet article dédié au sujet.
En l’état, je conserve cette méthode legacy dans cette partie du cookbook, car on trouve encore beaucoup d’exemples de ce type, mais je vous invite dès à présent à basculer sur un pv reposant sur un CSI.
PersistentVolumeClaim: 07-pvc-demoapp-front-dmz.yml
On bascule directement avec le pvc qui va en toute logique faire une référence directe au volume que l’on vient de déclarer.
Voici le contenu du fichier 07-pvc-demoapp-front-dmz.yml:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-demoapp-front-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
volumeName: pv-demoapp-front-dmz
N’hésitez pas à passer par là pour plus d’informations sur le fonctionnement du storage sous Kubernetes.
Deployment: 08-deploy-demoapp-front-dmz.yml
C’est au tour du Deployment associé au front.
Voici le contenu du fichier 08-deploy-demoapp-front-dmz.yml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-demoapp-front-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
spec:
replicas: 2
selector:
matchLabels:
environment: dev
network: dmz
application: demoapp
tiers: front
template:
metadata:
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
spec:
nodeSelector:
network: dmz
tolerations:
- key: "node-role.kubernetes.io/worker-dmz"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: wordpress
image: wordpress:6.6.1
ports:
- containerPort: 80
resources:
requests:
memory: "256Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
env:
- name: WORDPRESS_DB_HOST
value: service-demoapp-bdd-dmz
- name: WORDPRESS_DB_NAME
value: wordpressdb
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: secret-demoapp-bdd-dmz
key: mariadb-user-password
- name: WORDPRESS_DB_USER
valueFrom:
secretKeyRef:
name: secret-demoapp-bdd-dmz
key: mariadb-user
volumeMounts:
- name: wordpress-storage
mountPath: /var/www/html
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
volumes:
- name: wordpress-storage
persistentVolumeClaim:
claimName: pvc-demoapp-front-dmz
Je ne vais pas le présenter de manière aussi détaillée que celui utilisé pour la base de données.
On y retrouve les mêmes principes, avec toujours l’importance des labels, notamment entre ceux utilisés dans la section selector et ceux utilisés dans la partie template.
À la différence de la bdd, on autorise deux replicas. Ce qui implique que deux pods seront sans cesse exécutés. Etant donné l’usage d’un file system partagé via notre volume NFS ce n’est pas un problème.
Point que je n’ai pas abordé dans le précédent deployment, on utilise aussi ici la notion de nodeselector et de toleration.
Cela est directement lié à l’usage d’un seul et même cluster K8S pour héberger des assets aussi bien destinés à être exposés en interne que sur le web. N’hésitez pas à revenir la présentation du cluster et sur cet article pour comprend le principe de taint/toleration.
Dans le cas du selector, on impose à Kubernetes d’exécuter les pods sur des nodes ayant le label network : dmz.
Le fait d’ajouter la toleration permet d’autoriser Kubernetes à outrepasser le taint positionné sur nos nœuds en DMZ.
C’est une double assurance pour éviter de se voir exécuter un pod en DMZ alors que celui-ci n’a pas du tout vocation a être exposé dans cette zone.
Dans notre exemple, c’est assumé et souhaité d’exploiter la DMZ, on positionne donc ces options dans le deployment.
On retrouve également une partie env pour positionner aux conteneurs Wordpress (en version 6.6.1) les éléments dont ils ont besoin, notamment les accès à la base de données. On utilise bien sûr le même Secret que pour la bdd puisqu’il s’agit des mêmes informations.
Là encore, il suffit de parcourir la documentation de l’image sur le docker hub pour avoir une description du rôle de chaque variable.
Des ressources sont fixées aussi bien en admission, qu’en limites, pour les mêmes raisons que pour la base de données.
Des sondes livenessProbe et readinessProbe sont employées. Cela mériterait ici d’être optimisé, car les tests réalisés sont les mêmes…ce qui présente peu d’intérêt…mais je n’étais pas plus inspiré…
Bien entendu on retrouve notre pvc en fin de fichier qui va permettre d’associer le pv NFS à un volume wordpress-storage, qui va lui-même se retrouver monté dans le /var/www/html de chaque conteneur.
Noté la différence avec la base de données. La manière de mapper les volumes est identique, mais la finalité est différente. Ici c’est un partage NFS qui va se retrouver mappé à chaque conteneur.
Service: 09-service-demoapp-front-dmz.yml
Les fronts doivent bien entendu être exposés, d’où l’usage d’un service.
Voici le contenu du fichier 09-service-demoapp-front-dmz.yml:
---
apiVersion: v1
kind: Service
metadata:
name: service-demoapp-front-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
spec:
type: ClusterIP
ports:
- port: 80
targetPort: 80
selector:
environment: dev
network: dmz
application: demoapp
tiers: front
Rien de spécial à déclarer, hormis toujours l’importance des labels. Dans notre cas, c’est le port 80 qui sera utilisé côté service pour renvoyer ensuite vers le port 80 de chaque pod qui répond au critère de sélection des labels.
Issuer: 10-issuer-demoapp-front-dmz.yml
Ce n’est pas terminé, car si la base de données n’a vocation qu’à être exposée en interne du cluster, ce n’est pas le cas du front.
Il va donc falloir traiter la partie exposition https.
Pour cela, il va d’abord falloir générer un certificat. On va donc s’appuyer sur un objet de type Issuer amené par CertManager. On reprend donc toute la logique expliquée dans cet article lorsqu’on n’a mis en œuvre CertManager.
Comme expliqué dans l’article dédié, on créer un Issuer chargé de solliciter letsencrypt et de réclamer un certificat via le protocole ACME.
Voici le contenu du fichier 10-issuer-demoapp-front-dmz.yml:
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: issuer-demoapp-front-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
spec:
acme:
email: [email protected]
server: https://acme-v02.api.letsencrypt.org/directory
privateKeySecretRef:
name: sec-issuer-demoapp
solvers:
- http01:
ingress:
class: traefik-dmz
podTemplate:
metadata:
labels:
network: dmz
spec:
nodeSelector:
network: dmz
tolerations:
- key: "node-role.kubernetes.io/worker-dmz"
operator: "Exists"
effect: "NoSchedule"
ingressTemplate:
metadata:
labels:
network: dmz
Certificate/Ingress: 11-ing-demoapp-front-dmz.yml
On pourra donc enchainer avec le fichier 11-ing-demoapp-front-dmz.yml qui va contenir à la fois la définition du certificat et de l’ingress.
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: cert-demoapp-front
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
spec:
commonName: demoapp.myprivatelab.tech
secretName: sec-certificate-demoapp
dnsNames:
- demoapp.myprivatelab.tech
issuerRef:
kind: Issuer
name: issuer-demoapp-front-dmz
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-demoapp-front-dmz
namespace: dev-demoapp-dmz
labels:
environment: dev
network: dmz
application: demoapp
tiers: front
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-dmz
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-dmz
tls:
- hosts:
- demoapp.myprivatelab.tech
secretName: sec-certificate-demoapp
rules:
- host: demoapp.myprivatelab.tech
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service-demoapp-front-dmz
port:
number: 80
Pour le certificat, on fait bien entendu appel à l’Issuer. Le certificat obtenu avec sa clef privée sera stocké dans le secret sec-certificate-demoapp.
L’URL choisie est demoapp.myprivatelab.tech. Pour que le challenge réussisse et que le certificat soit délivré par letsencrypt, il faut que l’entrée DNS soit opérationnelle. Il est nécessaire que la résolution fonctionne avant de lancer la demande de certificat. Encore une fois, n’hésitez pas à lire cette partie du cookbook pour bien comprendre la mécanique.
On termine avec l’Ingress. Celui-ci va être sous le contrôle de l’IngressControler Traefik déployé en DMZ. C’est pourquoi on utilise la section annotations. La aussi, on reprend la logique de ce qui a été expliqué ici.
On applique la configuration TLS en associant le secret qui contient les informations du certificat.
On n’oublie pas de renvoyer toutes les requêtes de l’URL vers le port 80 du service service-demoapp-front-dmz.
On n’est maintenant au complet et on dispose de tous les fichiers yaml chargés de créer tous les objets nécessaires à notre application témoin.
NetworkPolicy: 12-netpol-demoapp-default-dmz.yml
On peut néanmoins encore évoquer un dernier fichier, optionnel, mais fortement conseillé.
Il s’agit du fichier 12-netpol-demoapp-default-dmz.yml qui va nous permettre d’établir une NetworkPolicy:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: netpol-demoapp-default-dmz
namespace: dev-demoapp-dmz
spec:
podSelector:
matchLabels:
application: demoapp
tiers: bdd
ingress:
- from:
- podSelector:
matchLabels:
application: demoapp
tiers: front
ports:
- protocol: TCP
port: 3306
policyTypes:
- Ingress
Très peu évoquée jusque-là, une NetworkPolicy est un objet Kubernetes natif permettant de mettre en place des règles de filtrage réseau, un peu comme un firewall, mais d’une manière un peu différente.
Le support des NetworkPolicy dépend du drivers CNI choisi. Dans notre cas, Cilium, les supporte, et mêmes mieux, il peut utiliser une version améliorée, mais qui ne fait plus partie de l’API par défaut.
Je vais rester sur une NetworkPolicy de base.
L’idée n’est pas de rentrer dans le détail, l’article est déjà assez long comme ça. Mais pour résumer grossièrement, une NetworkPolicy permet de définir des règles en entrée, soit en Ingress ou en sortie soit en Egress d’un ou des pods.
On peut utiliser les labels et différents critères de filtrage sont possibles jusqu’au niveau 3 (filtrage sur IP et port).
Par contre attention, dès lors qu’au moins une règle est spécifiée en Ingress et/ou en Egress, alors tout le trafic non explicitement autorisé par cette règle est implicitement refusé.
Dans notre exemple, je suis resté basique.
Je veux simplement m’assurer que la base de données ne puisse être accessible uniquement que par des pods reprenant les labels associés à mes front wordpress.Je n’utilise donc qu’une section Ingress sur le pod base de données (je filtre en entrée du pod mariadb).
Seul ce qui vient des pods front à destination du port 3306 est autorisé.
Ainsi, aucun autre pods ne répondant pas au critère de labels de la NetworkPolicy ne pourra accéder à la base de données.
L’usage de NetworkPolicy est important, car pour rappel, sous Kubernetes, par défaut tous le monde peut discuter avec tous le monde. Même si vous évoluez dans des namespaces différents.
Il devient vite important de filtrer un peu tout ça…mais il faut savoir rester prudent.
Ce n’est pas un firewall non plus. Trop de network policie ou des network policie trop complexes peuvent amener à des incidents. Soyez toujours bien certains de comprendre ce qu’implique la mise en œuvre d’une network policie.Je sais que Cilium apporte de nombreuses améliorations à ce niveau et qu’il devient possible d’aller jusqu’au niveau 7 soit le niveau applicatif pour créer des règles.
Mais dans ce cas on bascule sur la branche API spécifique à Cilium.
Je ne suis pas encore assez connaisseur sur ce sujet, mais peux être qu’un article dédié pourra se faire par la suite.
Lancement de l'application
Il ne reste plus qu’à lancer notre application.
On n’aurait pu créer un seul fichier yaml pour y déclarer tous nos objets, mais c’est une pratique que je déconseille. Ça peut vite devenir illisible et séparer les fichiers par objets m’a toujours semblé intéressant.
Surtout qu’avec Kubernetes, il suffit d’appliquer la commande kubectl apply -f en passant le dossier qui contient les yaml pour que tous les fichiers soient considérés.
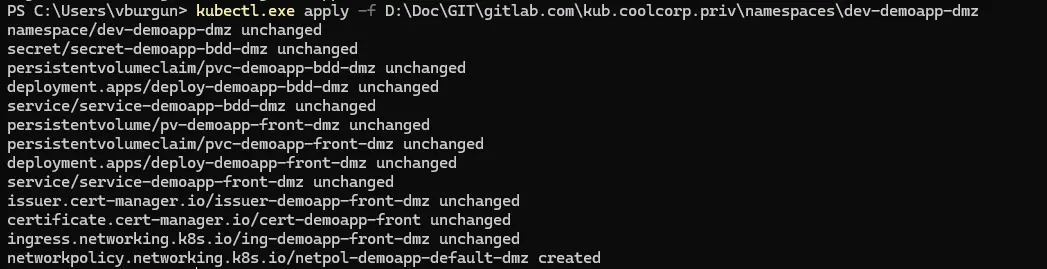
Cliquez sur l'image pour l'agrandir.
(J'avais au préalable déjà lancé la commande une première fois avant la capture, c'est pourquoi sur l'image le retour des objets apparait en unchanged sauf pour la netpol qui n'était pas encore déployée. Vous pouvez rappeler la commande autant de fois que vous le voulez. K8S n'appliquera de changement que s’il détecte une différence entre ce qui est déjà en place et ce qui est décrit dans vos fichiers.)
À noter que dans mon cas je numérote mes fichiers, mais dans les faits, Kubernetes s’en moque totalement. Tant qu’il trouve dans le dossier tous les yaml nécessaires et qu’il n’y a pas d’incohérence, il seront tous traités.
La magie opérante, il ne suffit que de quelques minutes, le temps de récupération des images, pour avoir notre site Wordpress disponible sur son url, avec son certificat.
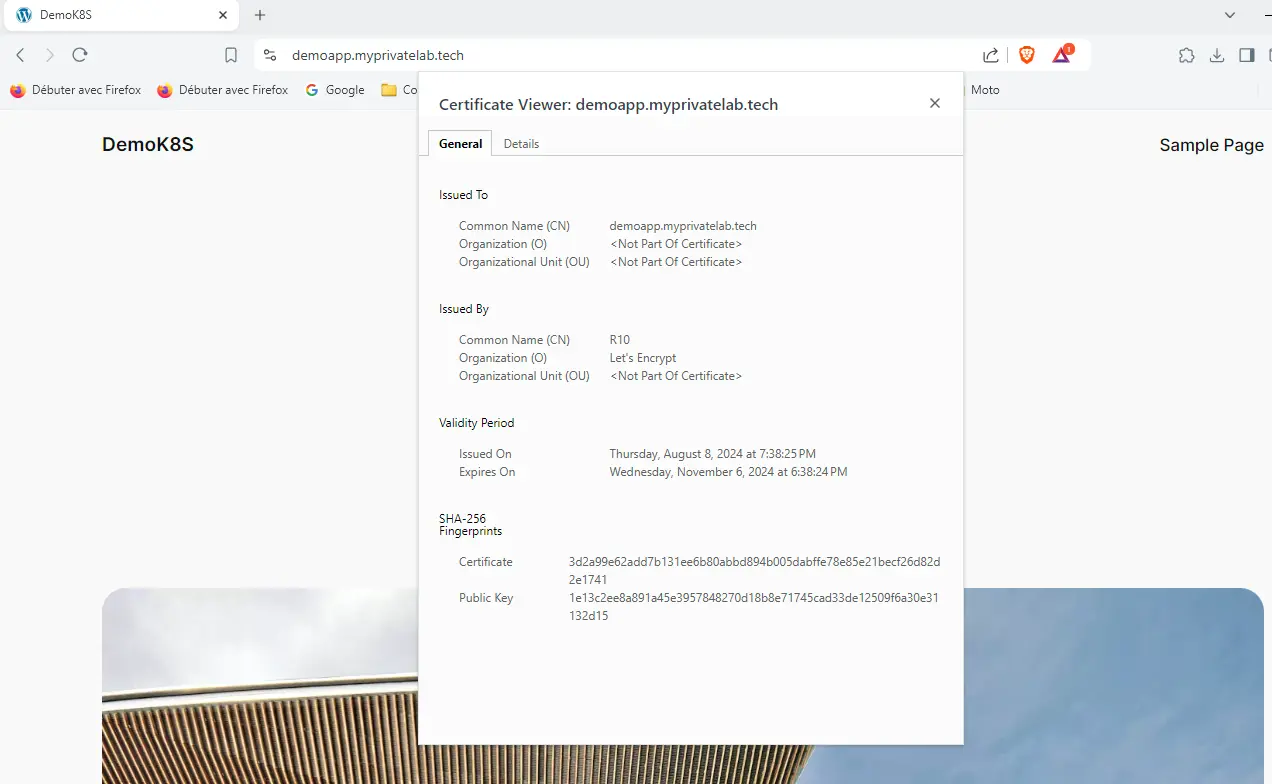
Cliquez sur l'image pour l'agrandir.
Si on liste les pods dans le namespaces via la commande kubectl get pod -n dev-demoapp-dmz -o wide

Cliquez sur l'image pour l'agrandir.
On retrouve bien un pod de base de données, et deux pods de front, tous sûr des nœuds en DMZ.
À noter que sans que je n'aie eu à le préciser, K8S a de lui-même réparti les deux pods front sur des nodes différents. Sachez qu'il est possible d'imposer ce comportement en ajoutant une section affinity dans les Deployments. Plusieurs règles sont possibles, mais je ne vais pas les présenter ici. Sans consigne de votre part, K8S essayera toujours de répartir au mieux, mais ça peut être une bonne pratique de chercher à gérer ce point également.
Si on regarde sur quel node se trouve la base donnée, coté vmware on retrouve bien le VMDK de 10 Go mappé à la VM.
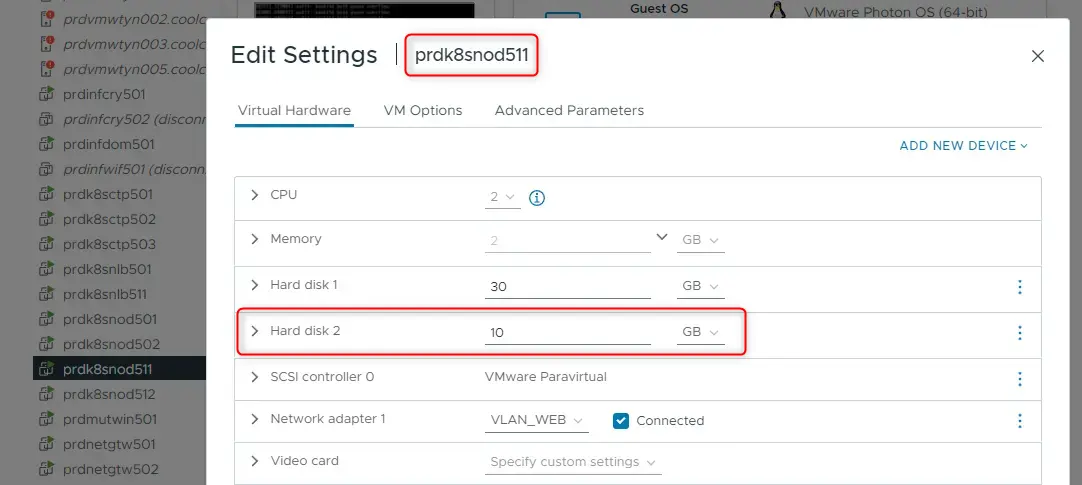
Cliquez sur l'image pour l'agrandir.
Côté partage NFS, on retrouve les fichiers à plat.
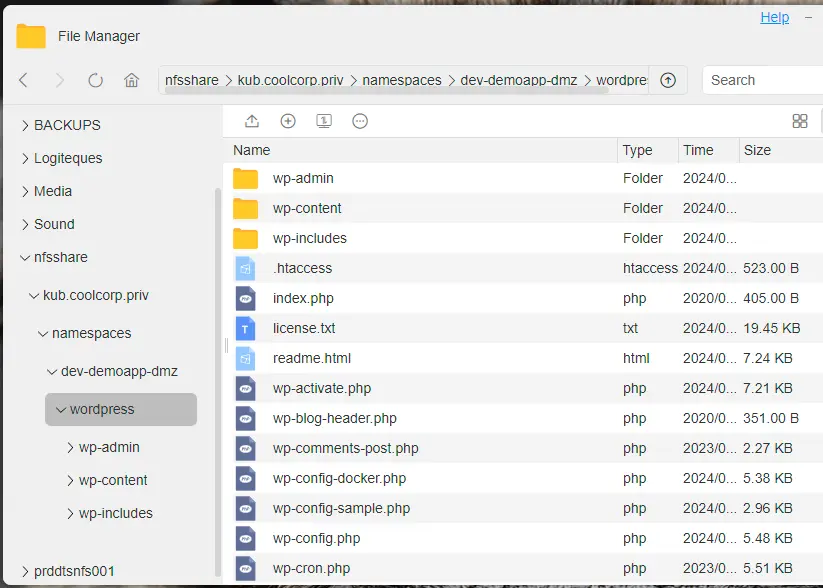
Cliquez sur l'image pour l'agrandir.
En se connectant sur le dashboard Traefik, on retrouve notre Ingress et la règle de routage renvoyant vers notre service.
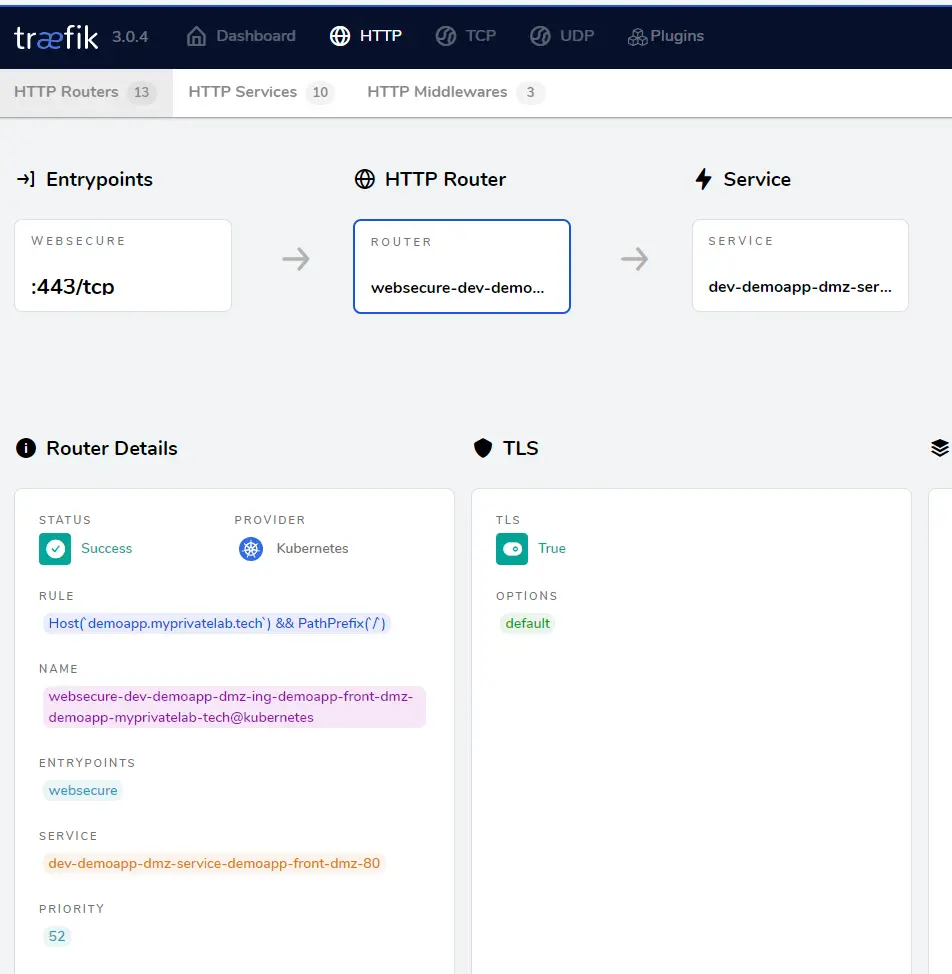
Cliquez sur l'image pour l'agrandir.
Conclusion
Ce cookbook est enfin terminé. J’ai essayé de m’appliquer à décrire le cheminement complet amenant de la définition d’un cluster Kubernetes à l’exécution d’une application. J’ai tenté d’être au plus proche possible des conditions de production, en exploitant des outils d’industrialisation et d’automatisation comme Terraform et Ansible dans la construction du cluster.
Chaque article avait également comme objectif de progressivement amener les différents principes que l’on peut retrouver au sein de Kubernetes, avec un focus sur le réseau et le storage.
J’insiste sur l’importance de poser son architecture et sa logique en adéquation avec ceux et celles qui vont opérer/utiliser le cluster. Il faut être rigoureux et méthodique en comprenant bien ce que l’on fait et surtout pourquoi on le fait.
Capitaliser sur les namespaces, établir une politique de nommage, schématiser son architecture, acter des labels obligatoires sont des activités à ne pas négliger. Que vous vous retrouviez sur un cluster vanilla comme ici ou sur un cluster hébergé, la difficulté de Kubernetes n’est pas tant de déployer des serveurs que d'exploiter correctement l'écosystème qui s'y rattache.
J’espère que ce cookbook pourra être utile a certains, et bien entendu je reste ouvert à la critique et serais ravi d’avoir des retours sur le sujet.
Je suis loin d’avoir la science infuse et il fort possible que je me sois fourvoyé sur certaines explications ou qu’il existe de meilleures manières de faire.Bien sûr qu’a l’époque de ChatGPT, il devient de plus en plus simple d’arriver à un résultat en jouant du prompt. Moi-même j’utilise régulierement l'IA dans mon travail.
Mais sans mon expérience et mes nombreux essais, je n’aurai jamais réussi à aller au bout de l’écriture de ce cookbook.
Kubernetes s’apprend par l’itération et l’amélioration continue. Il ne faut pas hésitez à tester, évaluer, recommencer…de toute façon ça ne sera jamais parfait. Kubernetes évoluant tellement vite, vos connaissances sont en cesse à revoir…sans pour autant tout remettre en cause.
Il y’a maintenant plein d’autres choses à creuser comme l’authentification au sein du cluster, la supervision, la sauvegarde de la configuration et des volumes persistants, ainsi que l'ajout de nouveaux drivers CSI.
Je vous invite à poursuivre sur la procédure d'upgrade déclinée dans une première partie théorique puis dans une seconde partie pratique.
Vous pouvez également étendre le cluster avec d'autres worker. Un exemple est disponible à cette URL.