Gestion des droits et des accès à Kubernetes
Introduction
L’accès à un cluster Kubernetes se fait via une API, celle-ci est gérée par le composant kube-apiserver hébergé sur un nœud control plane.
Bien entendu, l’interaction à cette API est soumise à une authentification.
Kubernetes supporte plusieurs moyens pour cela: de l’usage d’un simple fichier sous format texte à l’interrogation d’un annuaire d’entreprise.
De base, l’authentification à un cluster se fait grâce à une combinaison clef privée/certificat. Un système utilisé dans bien d’autres cas d’usage et qui permet un niveau de sécurité intéressant pour peu qu’on ait une gestion correcte de ses clefs privées et de son fichier de config.
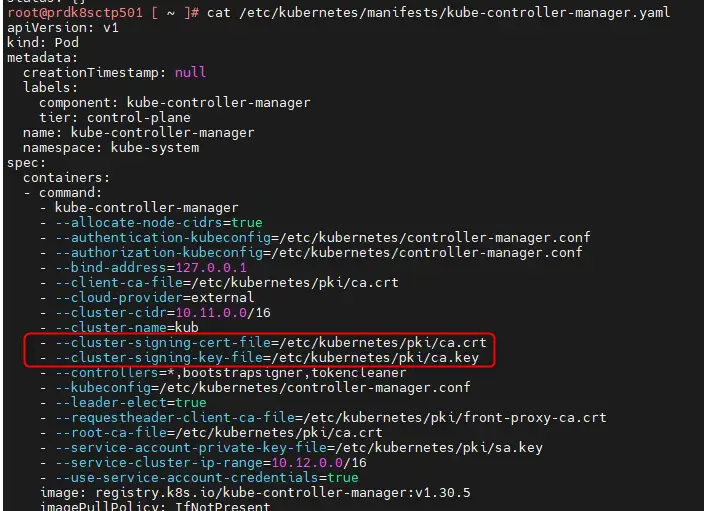
Lorsque vous déployez un cluster Kubernetes, notamment avec kubeadm, le composant appelé kube-controller-manager est paramétré pour inclure une autorité de certification (CA), et donc permettre l’émission de certificat.
Si vous observez par exemple, le manifest de déploiement d’un contrôleur manager sur un control plane, vous retrouverez ce genre de chose:
cat /etc/kubernetes/manifests/kube-controller-manager.yaml
Cliquez sur l'image pour l'agrandir.
Bien entendu, une CA tierce peut être utilisée et d’autres configurations peuvent être rencontrées.
Dans la suite de l’article, nous resterons sur l’exploitation de l’autorité de certification déployée par défaut. Il est conseillé d’avoir quelques notions sur l’usage des certificats et des clefs privées pour être à l’aise avec le sujet. Je vais essayer néanmoins d’être le plus clair possible.
Mes objectifs sont de:
- Créer une nouvelle clef privée associée à un nouvel utilisateur de mon cluster.
- Soumettre une demande de certificat issue de cette clef à l’autorité de certification présente dans mon cluster.
- Utiliser mon compte administrateur du cluster pour valider cette demande de certificat.
- Récupérer le certificat généré.
- Déclarer le certificat et cette clef privée dans mon fichier de config utilisé par kubectl sur mon poste.
- Créer un rôle spécifique à cet utilisateur sur mon cluster.
- Me connecter à mon cluster avec cet utilisateur.
On pourra ainsi voir la logique de base autour de l’authentification et la gestion des droits sous Kubernetes.
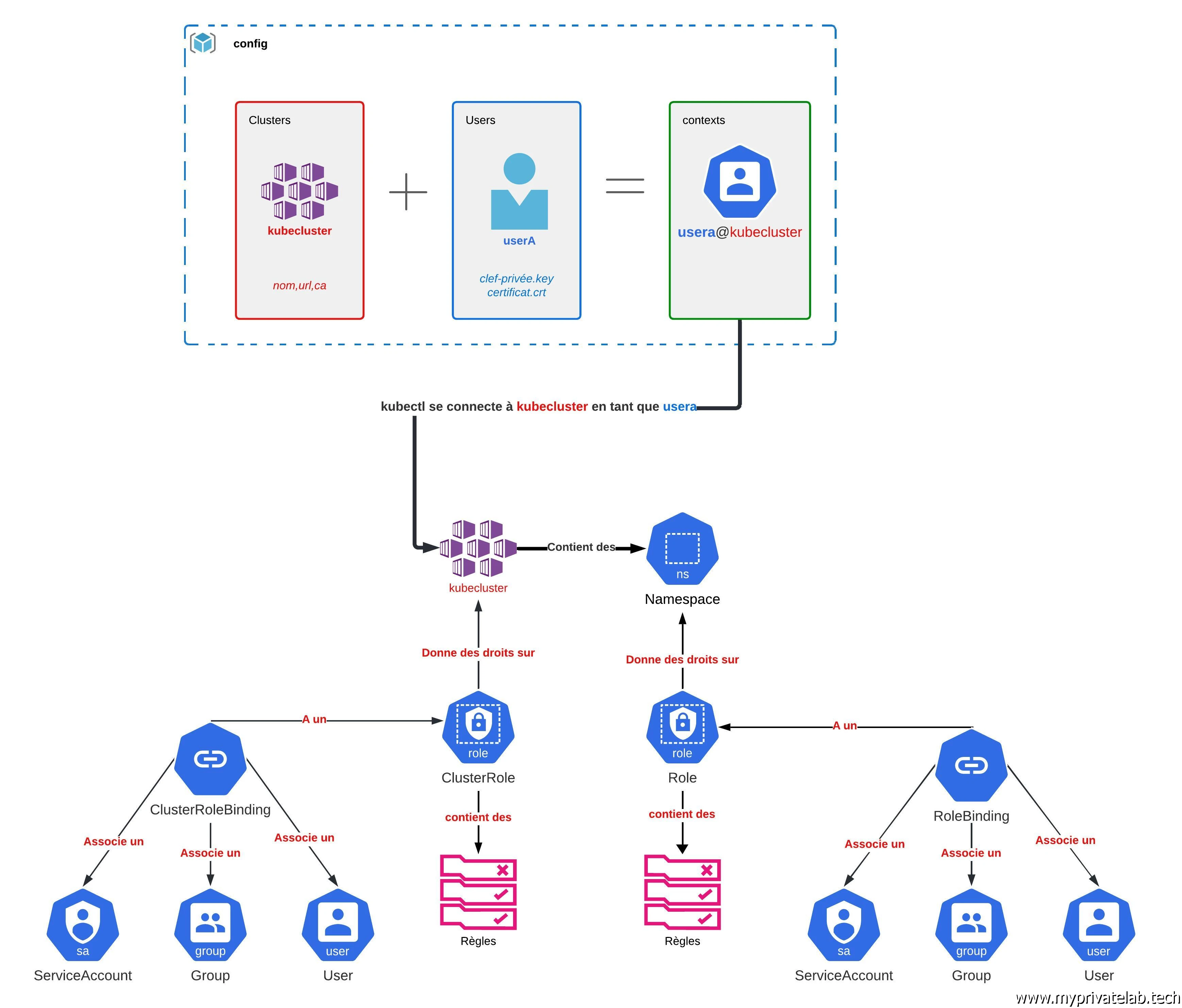
Le schéma ci-dessous résume les éléments que nous allons traiter dans cet article. N'hésitez pas à vous y référencer au fur à mesure du déroulé des explications.
Cliquez sur l'image pour l'agrandir.
Génération de la clef et obtention du certificat
Génération de la clef privée
La première étape consiste à générer sa clef privée. C’est totalement indépendant de Kubernetes. On peut utiliser tout bêtement openssl pour le faire (par exemple sous Windows avec WSL).
openssl genrsa -out mon_user.key 4096

Cliquez sur l'image pour l'agrandir.
J’attire votre attention sur la criticité de la clef générée. Elle doit bien entendu être protégée et non partagée. Elle vous « représente » et vous identifie de manière unique. Vous pourriez la sécuriser avec un mot de passe, mais je n’ai pas réussi à exploiter une clef de ce type et n’est pas trouvé d’information à ce sujet.
Génération du CSR
On reste sur un fonctionnement classique d’usage de certificat en créant une demande CSR (Certificate Signing Request) à partir de la clef privée et en spécifiant comme CN (canonical name) le nom de l’utilisateur. Fonction des éléments que vous pourriez indiquer dans votre CSR, Kubernetes peut traduire différents besoins, comme par exemple les groupes auxquels l’utilisateur doit appartenir. Mais nous allons rester basiques et utiliser juste le CN. C’est sous ce nom que sera référencé l’utilisateur dans Kubernetes.
openssl req -new -key mon_user.key -subj "/CN=mon_user" -out mon_user.csr

Cliquez sur l'image pour l'agrandir.
Soumission de la demande et récupération du certificat
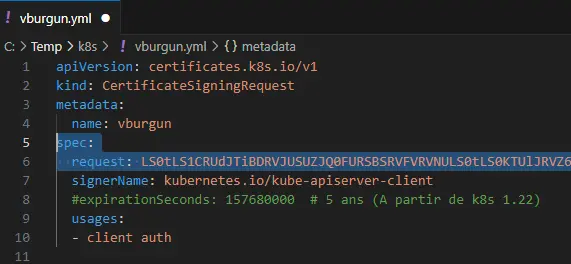
Une fois le CSR obtenu, il va falloir le soumettre au CA du cluster Kubernetes. Comme toujours dans Kubernetes, cela passe par un objet, ici un CertificateSigningRequest.Le yaml correspondant est le suivant:.
apiVersion: certificates.k8s.io/v1
kind: CertificateSigningRequest
metadata:
name: mon_user
spec:
request: csr_en_base_64
signerName: kubernetes.io/kube-apiserver-client
#expirationSeconds: 157680000 # 5 ans (A partir de k8s 1.22)
usages:
- client auth
Le contenu est assez simple. Le nom d’utilisateur, correspondant au CN dans la demande de certificat et renseigné dans la section metadata.
L’élément le plus important est dans la partie spec, l’option request. Il s’agit de la valeur de du CSR obtenu précédemment, mais en base 64.
Pour l’obtenir rien de plus simple, par exemple sous Linux ou via WSL sous Windows.
cat mon_user.csr | base64 | tr -d "\n"
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Une fois récupéré et renseignez dans le yaml, on peut appliquer l’objet via la
commande kubectl apply -f mon_path\user.yaml.

Cliquez sur l'image pour l'agrandir.
La subtilité est que cette commande nécessite d’avoir déjà un accès au cluster, puisqu’on fait appel à kubectl pour appliquer au cluster un objet de type CertificateSigningRequest.
On peut imaginer plusieurs scénarios possibles, comme par exemple fournir le CSR à un administrateur du cluster qui dispose déjà des accès suffisants pour soumettre le fichier.
Dans mon exemple, j’utilise mes accès par défaut récupérés lors de l’initialisation du cluster pour me permettre de passer la commande.
En entreprise, il y’a généralement une population autorisée à valider les demandes de certificats, et ces personnes ne sont pas forcément administrateurs. Comme nous le verrons un peu plus tard, la notion de rôle présente dans Kubernetes, permet d’attribuer des droits pour réaliser certaines actions.
On interroge le cluster pour savoir si des demandes de certificats sont actuellement en cours
kubectl get csr

Cliquez sur l'image pour l'agrandir.
On retrouve bien ma demande. On pourrait d’ailleurs avoir des détails sur cette dernière en consultant les propriétés de l’objet associé.
On va donc valider la demande
kubectl certificate approve mon_user

Cliquez sur l'image pour l'agrandir.
Celle-ci étant maintenant approuvée, elle devrait contenir un certificat.
kubectl get csr mon_user -o yaml
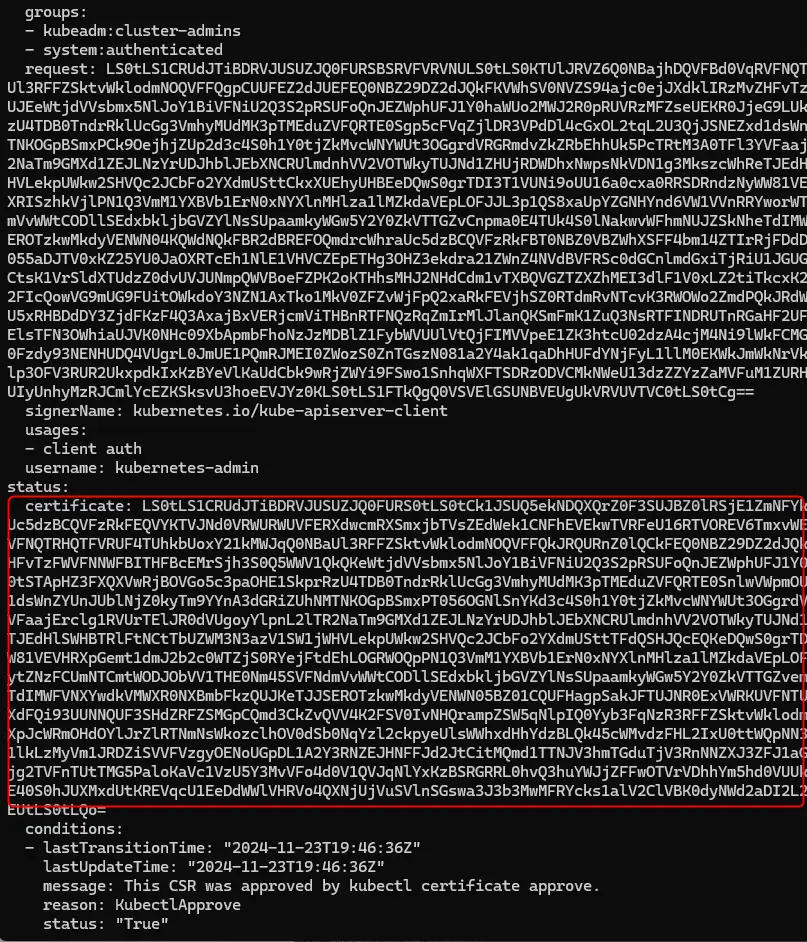
Cliquez sur l'image pour l'agrandir.
Il est possible d’accéder à ce certificat directement en extrayant ce dernier de l’objet et en convertissant son contenu depuis sa forme en base 64.
kubectl get csr mon_user -o jsonpath='{.status.certificate}'| base64 -d > mon_user.crt
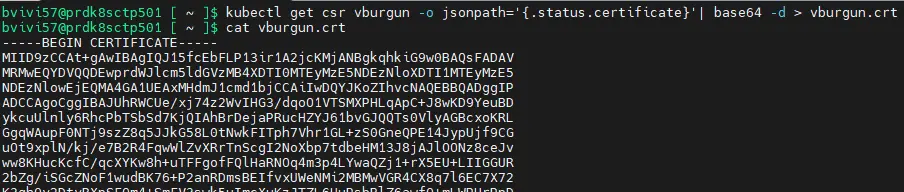
Cliquez sur l'image pour l'agrandir.
(la commande est réalisée sous un serveur Linux ou WSL)
Il faut bien comprendre qu'arrivé à cette étape, l'utilisateur est "connu" du cluster, du moins son certificat est renseigné dans la PKI (Public key infrastructure) interne au cluster.
Si une connexion est soumise à l'API via proposition du certificat et de la clef privée associée auquel il est rattaché, alors la connexion sera reconnue par l'API. L'identité de l'utilisateurs sera celui renseigné dans le CN du certificat.
Usage du fichier de config de kubectl
Disposant maintenant du certificat et de la clef privée, il est possible d’utiliser ces derniers dans le fichier config présent généralement dans le dossier .kube du profil utilisateur.
Cliquez sur l'image pour l'agrandir.
Ce fichier est lu par kubectl pour y trouver les informations d’authentification et de connexion.
À lui seul il permet de piloter différents clusters en empruntant différentes identités.
Son emplacement peut changer d’un OS à un autre, mais il aura toujours la même logique.
Le fichier reprend la syntaxe d’un objet k8s avec des rubriques spécifiques.
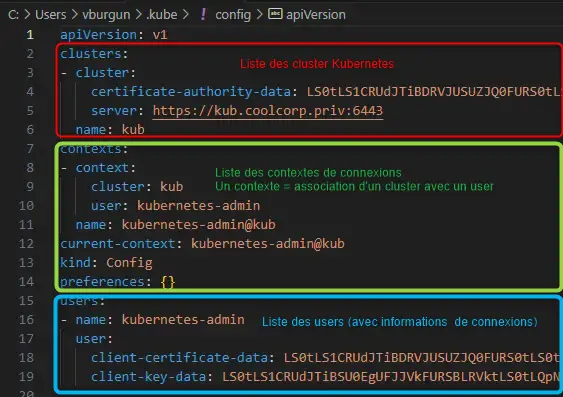
Cliquez sur l'image pour l'agrandir.
- La rubrique « clusters » : contiens l’ensemble des clusters auquel vous pouvez vous connecter. Pour chaque cluster, vous y trouvez son nom, l’URL d’accès à son API et le certificat en base64 du CA rattaché.
- La rubrique « users » contient l’ensemble des utilisateurs pour lesquels vous pouvez prendre l’identité. Pour chaque user on retrouve son nom ainsi que les identifiants de connexions. Ces identifiants peuvent soit faire référence à des fichiers externes, soit directement contenir les informations en base64.
- La rubrique « contexts » : un contexte est l’association d’un cluster et d’un user. Vous pouvez créer autant
de combinaisons et donc de contextes que vous avez d’associations possibles entre un utilisateur et un
cluster. Le nom d’un contexte est donné sous la forme user@cluster. Vous pourrez ainsi vous présenter
non seulement à plusieurs clusters, mais également au sein d’un même cluster vous présentez avec un
utilisateur différent (et donc des droits différents). On retrouve également la notion de
current-context. Il s’agit tout simplement du contexte « par défaut » dans lequel vous allez vous
trouver au lancement de kubectl. Autre point important, vous pouvez surcharger votre contexte d’un namespace et ainsi permettre de passer toutes vos
commandes dans un namespace spécifique sans avoir à
préciser son nom.
Autre petite subtilité, l’ordre des sections dans le fichier de config n’a pas d’importance. La section user peut être avant, au milieu ou en fin de fichier comme ici par exemple, de même pour les autres sections.
Un point très important: la criticité de votre fichier de config. Il contient les éléments nécessaires pour l’accès à vos clusters. Faites très attention à son contenu et à son exposition.
Dans l’exemple ci-dessous, c’est le fichier config obtenu après avoir déployé un cluster. Par défaut il contient les informations de connexions pour un accès full admin au cluster.
La clef privée et le certificat associé sont directement renseignés sous leur forme en base64.
Ce qui implique que quiconque qui puisse récupérer ce fichier est en mesure de se connecter au cluster avec le plus haut niveau de droit (sous réserve des accès réseau à l’API).
Vous comprendrez donc qu’il est primordial que ce fichier soit sécurisé et accessible uniquement à un nombre de personnes limitées.
Dans le cas de création du nouvel utilisateur et de la combinaison clef privée/certificat citée précédemment, on va procéder différemment.
On ne va pas directement fournir la valeur de ces éléments en base64, mais plutôt y faire référence en tant que fichier.
Cela consiste à ajouter au config existant, un utilisateur supplémentaire dans la section users, et créer un nouveau contexte associant ce nouvel utilisateur avec le cluster déjà déclaré.
Ajout dans la section context
- context:
cluster: nom_cluster
user: nom_user
name: nom_user@nom_cluster
Ajout dans la section user
- name: nom_user
user:
client-certificate: emplacement du certificat
client-key: emplacement de la clef
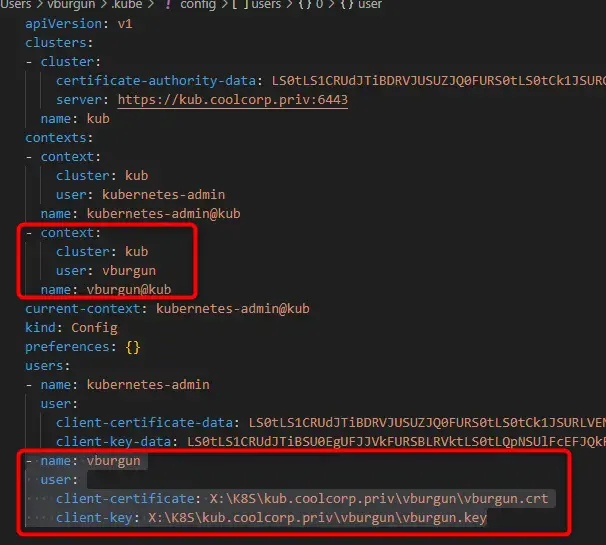
Cliquez sur l'image pour l'agrandir.
Avec cette manière de faire, il n’y a plus directement les informations de connexions dans le fichier config, et celui-ci n’est plus autonome dans son usage puisqu’il faut également que la clef privée et le certificat soient disponibles.
(Pour bien faire dans mon exemple, je devrais également retirer les références au compte admin par défaut, mais je vais le conserver à titre d’explication pour la suite).
Au finale, ce qui reste vraiment critique est le fichier contenant la clef privée.
Maintenant que le config dispose de deux contextes de connexion, je vais pouvoir basculer sur le contexte de l’utilisateur qui vient d’être déclaré sur le cluster.
Il suffit d’utiliser la commande:
kubectl config use-context user@cluster

Cliquez sur l'image pour l'agrandir.
Toutes les actions qui vont suivre vont donc se faire sous l’identité du user que je viens de créer et non plus avec le compte administrateur par défaut.
Si on tente un bête kubectl get nod
On se retrouve avec un message d’erreur indiquant que l’utilisateur n’est pas autorisé à lister la ressource demandée.

Cliquez sur l'image pour l'agrandir.
C’est bien normal, puisque si l’utilisateur existe désormais auprès du cluster, il n’a aucun droit attribué.
Rôles et droits
Kubernetes utilise la notion de RBAC (Role-based access control). C’est une méthode de gestion des ressources très courante, qu’on retrouve également chez les principaux opérateurs cloud publics et dans de nombreux logiciels.
Le principe est d’associer des actions à des rôles, puis d’associer ces rôles à des utilisateurs (ou des groupes d'utilisateurs).
Un rôle peut contenir tout un ensemble d’actions, certaines pouvant donner des droits importants sur une partie d’objets du cluster, d’autres plus contraignantes (accès en lecture seul par exemple).
Combiné à la notion d’objet de K8S, il est possible de proposer une politique d’accès très fine, avec une granularité par objet. (lister les pods, mais pas les secrets par exemple).
La liste des actions possibles incluant leur niveau d’interaction avec les objets constitue une liste de règle (rules) contenue au sein du rôle.
Kubernetes, propose deux types de rôles:
- Les rôles classiques (kind: Role): ces rôles sont appliqués à un namespace. Toutes les actions qui vont y être décrites n’ont de valeur qu’au sein de ce namespace. Ces rôles sont souvent réservés aux utilisateurs standards ou à des équipes spécifiques. Tout dépend de la logique retenue dans l’adoption des namespace sur le cluster. Par exemple on peut imaginer un rôle « developpeur » qui ne pourrait agir que sur les namespace impliquant des applications de développements. Attention, si les applications sont dans plusieurs namespaces, il y’aura un rôle par namespace, sachant qu’un utilisateur peut avoir plusieurs rôles.
- Les clusters rôles (kind: ClusterRole): comme leur nom l’indique ces rôles sont transverses aux namespaces. Ils sont plutôt réservés aux taches d’administrations et impliquent des règles d’actions possibles sur l’ensemble du cluster ou sur des ressources dissociées de la notion de namespace.
Les rôles classiques (kind: Role)
On peut commencer par la création d’un objet rôle.
Il s’agit tout simplement de décrire sous forme de règles le type d’actions autorisées, sur quels types d’objets et dans quel namespace. Dans l’exemple ci-dessous, on autorise les actions get (interroger), watch( surveiller) , list (lister) les pods au rôle « pod-reader » dans le namespace inf-velero-lan.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: mon-namespace
name: role-pod-reader
rules:
- apiGroups: [""] #
resources: ["pods"]
verbs: ["get", "watch", "list"]
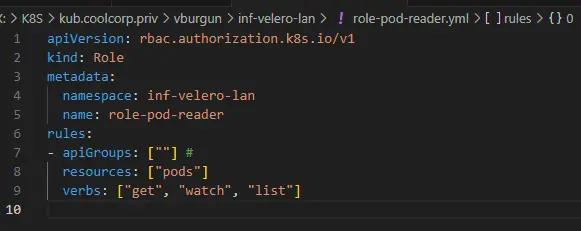
Cliquez sur l'image pour l'agrandir.
Au niveau de la règle, on précise:
- apiGroups: la branche de l’API qui contient les objets sur lesquels on veut autoriser des actions.
- resources: ce sont les objets de la branche API.
- verbs: ce sont les actions qu’on autorise.
Le caractère * est possible pour généraliser des actions à tous les objets d’une branche.
De même plusieurs rules sont déclarables dans un rôle…mais toujours pour le même namespace.
Appliquer le rôle, revient à faire un kubectl apply -f mon-role.yaml.
Par contre, il me faut revenir dans un contexte administrateur, si je veux que l’API accepte mon objet rôle.
Pour cela rien de plus simple, je reviens dans le contexte par défaut de mon fichier de config.
kubectl config use-context kubernetes-admin@kub

Cliquez sur l'image pour l'agrandir.
Je peux ensuite appliquer le rôle:
kubectl apply -f role-pod-reader.yml.

Cliquez sur l'image pour l'agrandir.
Le rôle étant créé, il faut l’associer au nouveau user. Pour cela on passe par un objet RoleBinding. Cet objet permet tout simplement d’associer un rôle à un utilisateur au sein d’un namespace.
En l’occurrence dans l’exemple, mon utilisateur « vburgun » va se retrouver
associer à mon rôle « pod-reader » dans le namespace «
inf-velero-lan »
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: mon-namespace
subjects:
- kind: User
name: mon-user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
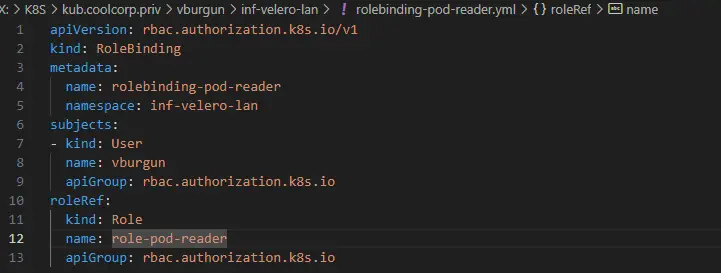
Cliquez sur l'image pour l'agrandir.
On applique l’objet RoleBinding avec la commande
kubectl apply -f mon-role-binding.yaml.

Cliquez sur l'image pour l'agrandir.
Je peux maintenant rebasculer dans le contexte de mon utilisateur.
kubectl config use-context vburgun@kub

Cliquez sur l'image pour l'agrandir.
Si je rappelle ma commande kubectl get node, j’ai toujours une erreur.

Cliquez sur l'image pour l'agrandir.
Ce qui est normal, puisque le rôle que j’ai créé ne permet que de lister les pods dans le namespace inf-velero-lan.
Voyons voir si cela est possible avec la commande:
kubectl get pod -n inf-velero-lan
Cette fois j’ai bien une réponse de l’API.
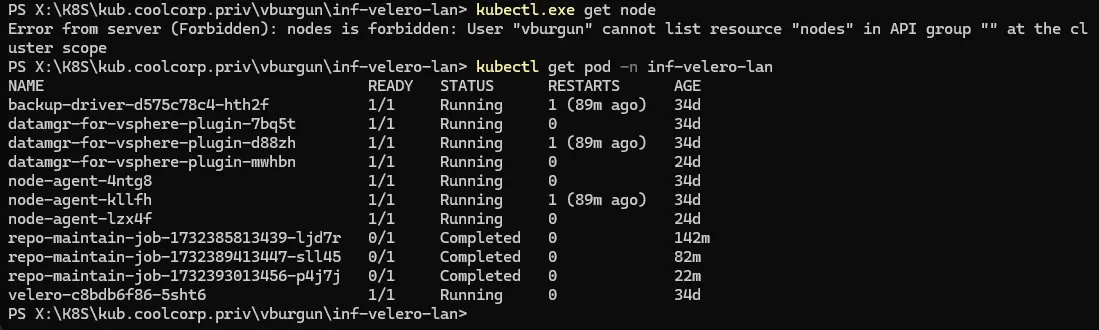
Cliquez sur l'image pour l'agrandir.
Les clusters rôles (kind: ClusterRole)
Si je souhaite maintenant autoriser ma commande kubectl get node pour
mon utilisateur vburgun, il va falloir exploiter non plus un rôle classique, mais un ClusterRole,
car les nodes sont des ressources globales au cluster et non propres à un namespace.
Je vais déjà rebasculer dans un contexte d’administrateur.
kubectl config use-context kubernetes-admin@kub

Cliquez sur l'image pour l'agrandir.
Sachez qu’il existe de base des ClusterRole. D’autres sont ajoutés automatiquement lorsque vous déployez des applications tierces ou des addons pour le cluster (comme cert-manager par exemple).
Vous pouvez lister les clusterroles avec la commande:
kubectl get clusterrole
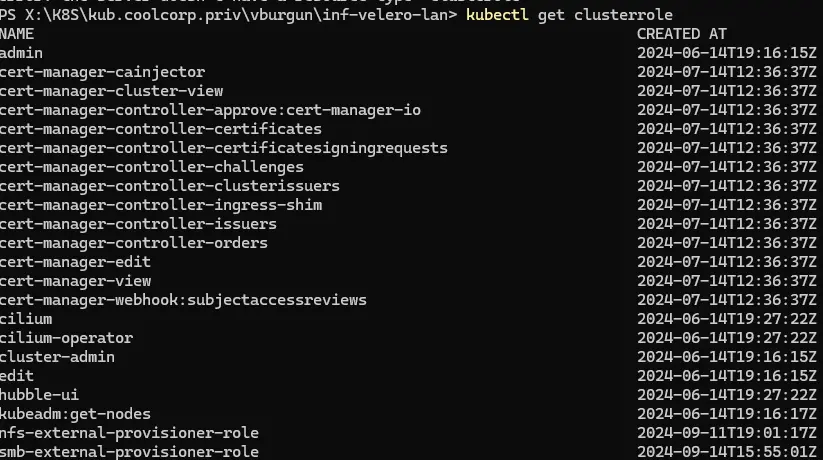
Cliquez sur l'image pour l'agrandir.
Le ClusterRole le plus connu (et le plus critique) est le cluster-admin. C’est ce rôle que vous obtenez par défaut lorsque vous installez le cluster. Ce sont les identifiants d’accès au super administrateur par défaut associé à ce ClusterRole qui sont inscrits dans le fichier config généré en fin d’installation.
Commençons par créer dans un fichier yaml clusterrole-list-nodes.yml, le cluster rôle clusterrole-list-nodes:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: clusterrole-list-nodes
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
Contrairement au rôle classique, il n’y a pas de référence à un namespace.
Du côté de la rule, j’autorise simplement les actions de get, list et watch sur les ressources de type node de l’api group par défaut.
Je l’applique avec kubectl apply -f clusterrole-list-nodes.yml.

Cliquez sur l'image pour l'agrandir.
Il me reste à l’associer à mon user vburgun, mais cette fois-ci via un objet ClusterRoleBinding que je décrie dans le fichier clusterrolebinding-list-node.yml.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: clusterrolebinding-list-node
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: clusterrole-list-nodes
subjects:
- kind: User
name: vburgun
apiGroup: rbac.authorization.k8s.io
J’associe mon ClusterRole clusterrole-list-nodes à mon user vburgun.
J’applique le fichier avec la commande:
kubectl apply -f clusterrolebinding-list-node.yml

Cliquez sur l'image pour l'agrandir.
Essayons de voir maintenant, en revenant dans le contexte de mon utilisateur (via
la commande kubectl config use-context vburgun@kub) si je peux enfin lister les nodes.
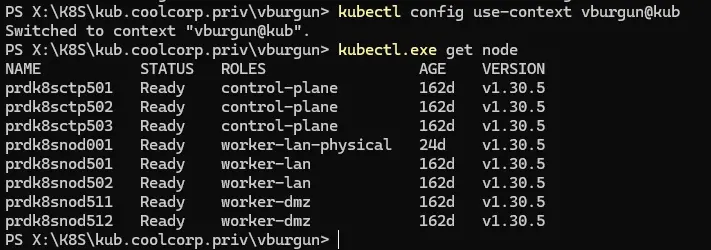
Cliquez sur l'image pour l'agrandir.
Conclusion
Définir une politique d’accès à un cluster Kubernetes est une chose très importante.
Il est nécessaire de bien comprendre le mécanisme d’authentification utilisé et les principes qui s’y rattachent, notamment la logique RBAC (Role-based access control).
Il faut également assimiler la distinction entre les droits donnés pour un namespace des droits donnés pour tout le cluster.
La bonne pratique est toujours d’essayer de privilégier le moindre privilège pour construire des objets Role et ClusterRole qui collent au plus proche des besoins des utilisateurs amenés à interagir avec le cluster. Ni plus. Ni moins.
Maintenant ce n’est pas toujours simple, et on n’est vite tenté d’utiliser les ClusterRole par défaut, notamment le cluster-admin. Ce qui n’est clairement pas la meilleure des choses à faire.
Attention toutefois à l’excès de zèle. Par expérience, j’ai pu constater qu'aller trop loin dans la définition des rôles avec une politique trop agressive peut amener à de la frustration dans les équipes et encourager les portes dérobées.
Il faut pouvoir tenir compte du contexte d’utilisation et adapter les bonnes pratiques à la taille et au niveau de ses équipes. Bien entendu, il faut également considérer la criticité des assets hébergés et de l’activité de l’entreprise pour laquelle le cluster exécute des applications.
Il faut donc trouver le bon équilibre entre la ségrégation des droits et le maintien en condition opérationnelle, pour éviter l’usine à gaz, qui est souvent l’un des inconvénients d’une logique RBAC avec la multiplication des rôles.
Un review des accès au cluster est une bonne chose. Faire le point de temps en temps sur les rôles en place et les besoins d’intervention des équipes sur le cluster, permet de maintenir un référentiel à jour et d’éviter d’accumuler des rôles inutiles ou devenus inadaptés.
Attention également au fichier de config lu par kubetcl. Ce dernier peut contenir des données très sensibles avec des niveaux de privilèges importants. Il permet d’effectuer des actions sous différentes identités et pour différents clusters. Un simple fichier config peut contenir des informations d’authentifications pour de nombreuses architectures, onprem comme cloud.
C’est une logique de fonctionnement extrêmement puissante et pratique grâce au passage d’un contexte à un autre, mais c’est aussi une cible privilégiée pour des personnes malveillantes.
J’ai également vu par retours d’expérience, trainer des fichiers de config sur des partages réseaux et retrouver tout un ensemble d’utilisateurs utiliser le même compte local sur le cluster à travers l’usage du même fichier de config de kubectl.
C’est pourquoi, en guise d’évolution, il est préféré de mapper son cluster à des solutions d’authentification externes, pouvant simplifier les choses, notamment à un annuaire d’entreprise. Un exemple d'intégration avec Microsoft Entra ID est disponible ici.
De manière générale et d’un point de vue personnel, quand on touche à la sécurité:
prioriser la formation à l'interdiction

Cliquez sur l'image pour l'agrandir.
et simplifier c’est souvent sécuriser.

Cliquez sur l'image pour l'agrandir.