Définition K8S : Le namespace
Explications
Un namespace (nom court ns) au sein d’un cluster Kubernetes est un espace d’exécution spécifique dans lequel peuvent être déclarés d’autres objets.
On peut appliquer à un namespace des règles d’accès particulières et des quotas de ressources (cpu/ram/disque).
Les namespaces permettent d’utiliser un seul et même cluster Kubernetes pour différents usages et différents publics. C'est une maniere de segmenter logiquement son cluster. En dehors de certains objets spécifique, un objet défini dans un namespace verra sa porté limitée à ce namespace.
On peut ,par exemple, créer un namespace production administré et accessible par un pool d’utilisateurs spécifique et un namespace developpement administré et accessible par un pool d'autres personnes.
Plusieurs découpages peuvent être imaginés, comme par exemple un découpage par service ou famille d’application. Si une équipe cross-compétence (la fameuse pizza team ou devsecops/sre/nouveauté du moment) a la charge d’une application particulière, on peut lui déléguer un namespace spécifique dans lequel elle est parfaitement autonome. Une autre équipe, en charge d’une autre application disposerait également d’un namespace dédié.
Une équipe ne pouvant pas déployer de ressources dans le namespace d’une autre, voire mieux, ne pourrait avoir absolument aucune visibilité sur ce qui tourne en dehors de son namespace.
Namespace par default
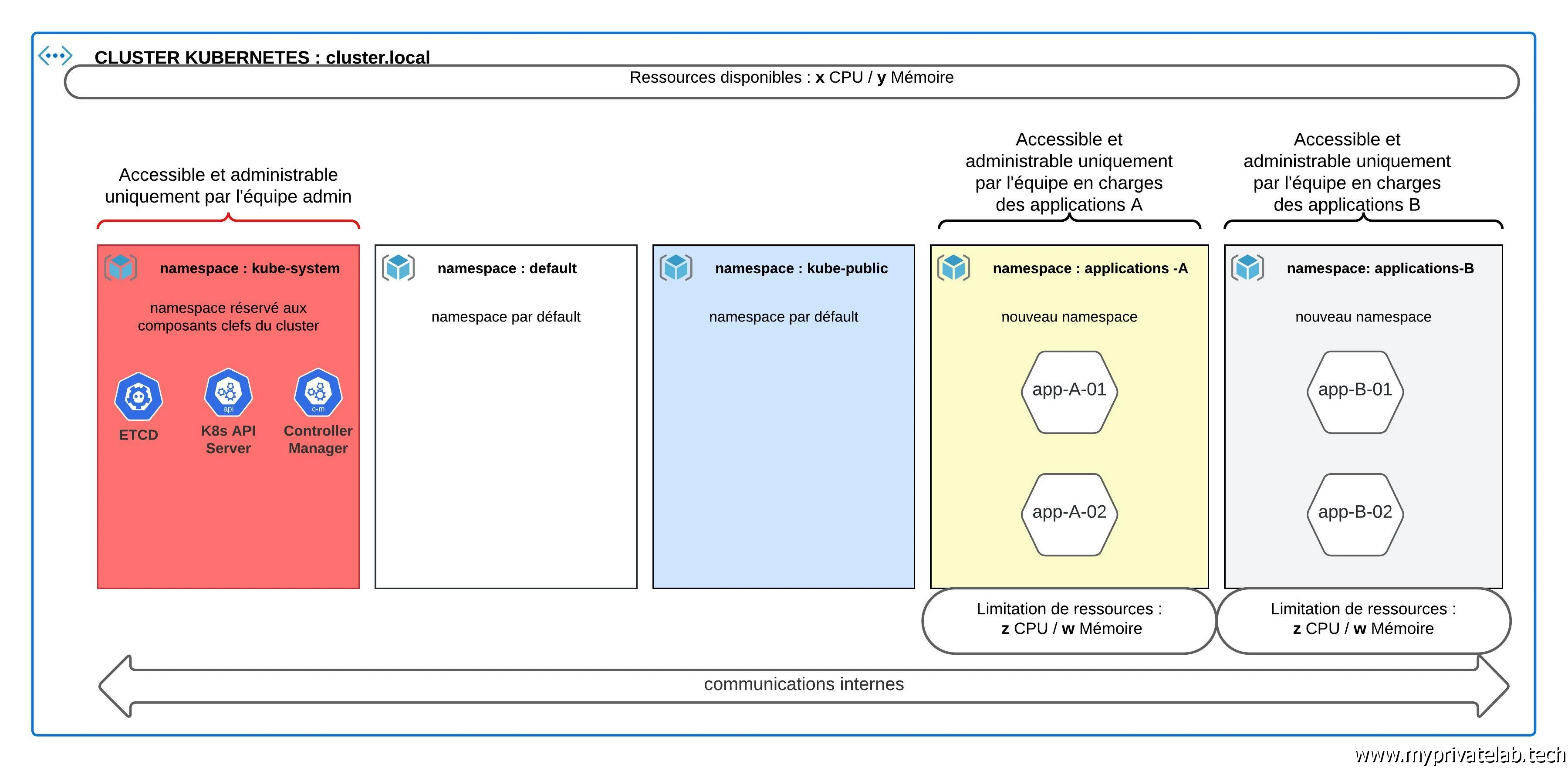
Lorsque vous déployez un cluster, trois namespaces par défaut vont être créés.
- kube-system : son nom est assez explicite, puis ce que c’est dans ce namespace que vous allez retrouvez tous les composants « système » du cluster : l’api server, le server DNS….Autant vous dire que l’accès à ce namespace doit être particulièrement contrôlé. D’ailleurs dans certaines offres Kubernetes As A service , ce namespace ne vous ait pas accessible.
- default : si vous ne précisez rien dans vos déploiements et dans vos commandes, c’est le namespace qui sera utilisé. Attention, si votre objectif est de déployer une solution de production, ce n’est pas forcément une bonne idée d’utiliser ce namespace. Vous aurez vite fait de mélanger les torchons et les serviettes, autant réfléchir à une architecture de namespace dès le départ.
- kube-public : c’est un namespace ouvert à tous destiné à accueillir des objets sans restriction d’accès. La aussi il est conseillé en production de ne pas forcément utiliser ce namespace.
Cliquez sur l'image pour l'agrandir.
Communication inter namespaces
Attention, par défaut avoir des objets dans des namespace différents n’empêche pas ces derniers de communiquer entre eux. Kubernetes applique plutôt une logique de tout le monde peut parler à tout le monde Dans mon exemple précédent, ce n’est pas parce que deux équipes ont la charge d’une application différente que ces deux applications n’ont pas besoin d’échanger entre elles.
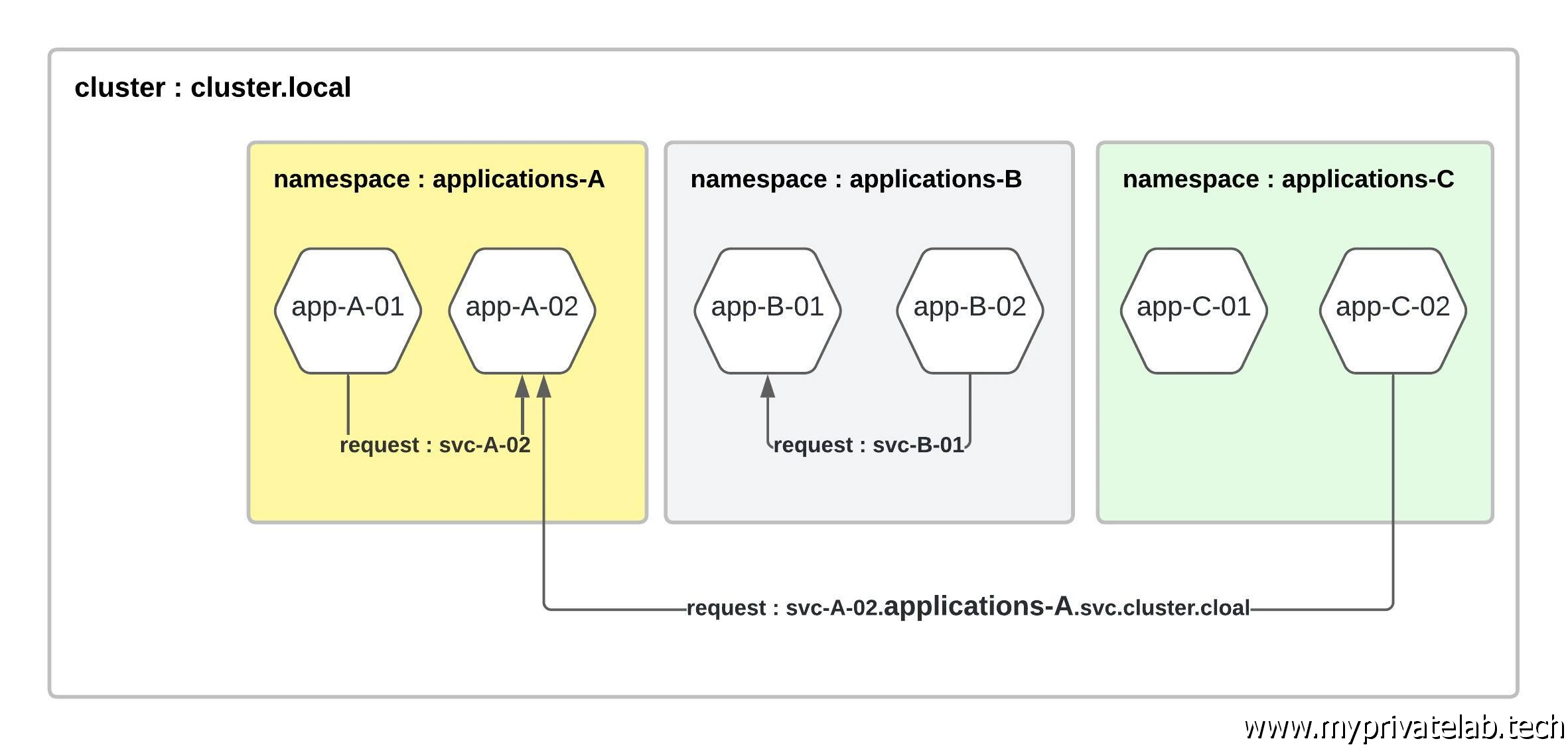
Si deux services (au sens K8S : objet permettant l'exposition d'un pod) ne sont pas dans le même namespace, ils peuvent s’appeler l’un et l’autre via une logique de nom reposant sur DNS. En effet, tout cluster Kubernetes dispose d’une résolution DNS interne et un namespace est vu comme un espace de nom.
Le plus haut niveau est cluster.local , c’est le domaine « root ». Puis on descend au niveau des services svc pour ensuite arriver au niveau namespace, puis enfin au nom du service lui-même.
Par exemple, une application SuperApps qui serait exposée à travers un service svc-superapps dans un namespace developpement répondrait au sein du cluster par le nom DNS : svc-superapps.developpement.svc.cluster.local.
Si une application partage le même namespace, alors elle peut faire appel à SuperApps, directement avec son som court svc-superapps mais si elle est issue d’un autre namespace, alors il faudra qu’elle sollicite SuperApps avec son nom complet.
Bien entendu, il est possible de restreindre les échanges réseau d’un namespace à un autre, mais cela nécessite de la configuration supplémentaire. Retenez simplement que par défaut, si un namespace vous permet de limiter les accès utilisateurs aux objets qu’il héberge, il n’applique aucune restriction de communication.
Cliquez sur l'image pour l'agrandir.
Utilisation et manipulation
La déclaration d’un namespace se fait comme n’importe quel objet kubernetes dans un fichier yaml.
---
apiVersion: v1
kind: Namespace
metadata:
name: mon-namespace
Le namespace est décrit dans la documentation kubernetes
Conclusion
Ce qu’il est finalement important de retenir avec les namepaces, c’est qu’il s’agit d’éléments structurants pour votre cluster.
II est très important de réfléchir en amont de la création du cluster à l’organisation que vous allez appliquer au niveau des namespaces.
Se passer des namespace est possible, mais ça serait une grosse erreur en production. Il est très important d’organiser ses objets kubernetes fonction de la logique que vous souhaitez adopter en termes de sécurité d’accès et de distribution des ressources.
Même si par défaut, les communications internamespaces sont autorisées, les namespaces permettent via d'autres mécanismes déployés par la suite, de se donner la possibilité de filtrer les flux entre les objets qu'ils hébergent.
Travailler avec des namespaces permet aussi d'optimiser son infrastructure matérielle. Là où l'on pourrait imaginer devoir créer plusieurs clusters K8S pour des questions de segmentation et d'usage, on peut basculer sur un seul cluster, mais reposant sur l'usage de plusieurs namespaces correctement configurés.
En appliquant des règles d'accès, des limitations de consommation de ressources et du filtrage de flux, un seul cluster pourrait suffire si une segmentation logique est considérée comme suffisante dans les contraintes de sécurité.