Installation et usage des CSI NFS/SMB
Introduction
La gestion du stockage dans des environnements conteneurisés a toujours été une problématique, même si celle-ci s’est estompée avec le temps.
Un conteneur est un composant pensé pour être éphémère. Il se doit de démarrer rapidement et d’être optimisé au mieux pour limiter les dépendances extérieures.
Un conteneur est par définition portable et doit pouvoir changer de contexte d’exécution sans qu’il y’ai d’impact dans le fonctionnement qu’il délivre.
Par défaut, toute donnée générée au sein du conteneur est perdue lorsque celui-ci s’arrête.
Mais toute application ne peut pas se passer de données persistantes. Certaines doivent pouvoir enregistrer de manière permanente les datas qu’elles manipulent. Les conteneurs associés ont nécessité de retrouver leurs informations à chaque démarrage.
C’est pourquoi on utilise la notion de volumes. Ce sont des espaces de stockage montés au sein des conteneurs destinés à persister la données, fonction de différents protocoles et mode d’accès.
Kubernetes n’échappe pas à la règle et dispose d’objets propres qui lui permettent de fournir des solutions de persistance de la data.
L’approche de K8S, comme toujours, se veut modulaire et a évolué dans le temps.
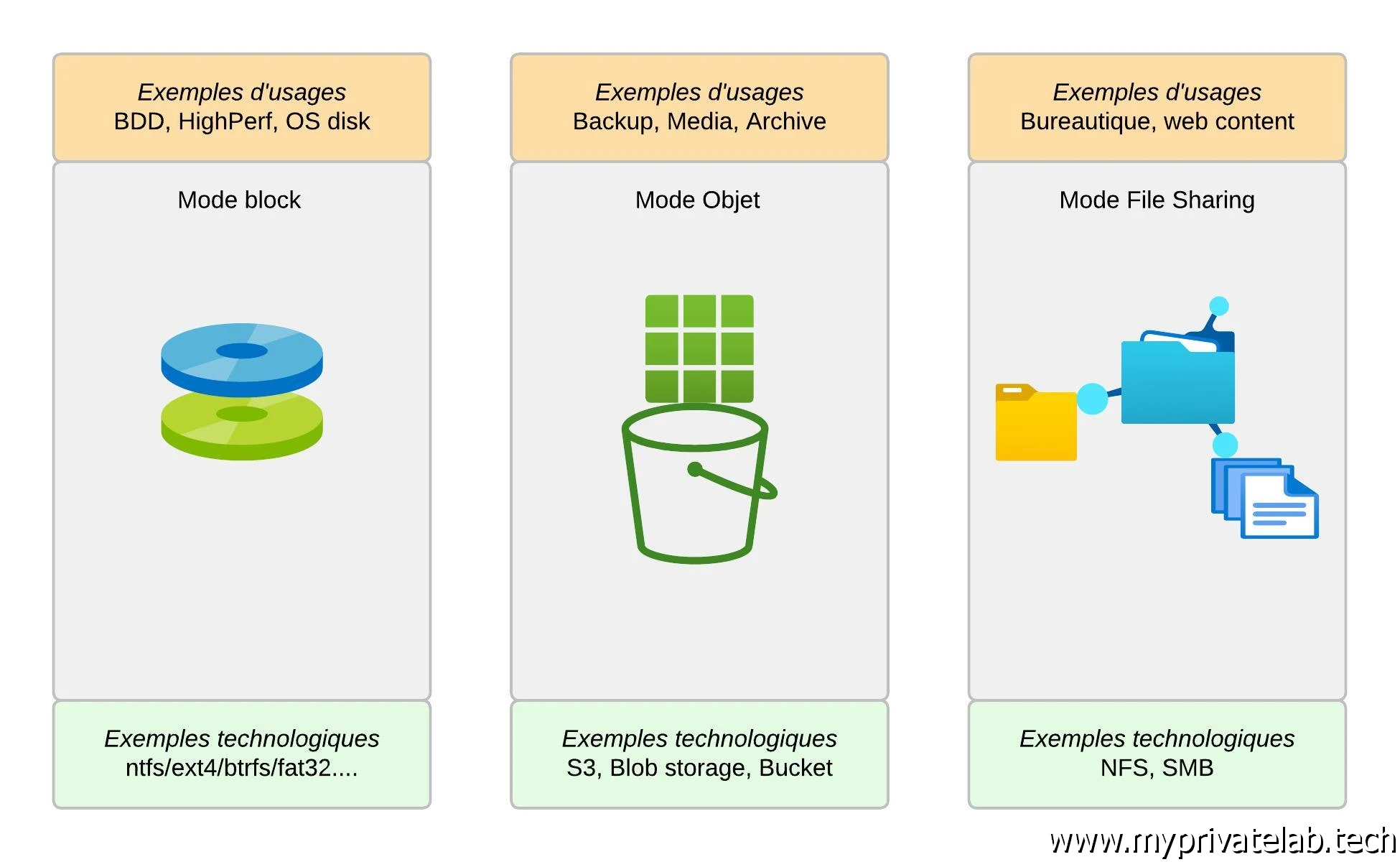
Pour démarrer il est important de distinguer trois modes de stockage possibles:
- Mode block: orienté pour de la haute performance.
Souvent utilisé dans un mode d’accès et d’écriture exclusif, n’autorisant qu’un conteneur à la fois à pouvoir accéder à la donnée.
Cela revient à mapper un disque avec filesystem directement au sein du conteneur.
- Mode objet: orienté multiple accès et haute redondance.
Très utilisé en environnement cloud public, notamment avec les services type S3 « like » qu’on retrouve chez tous les principaux fournisseurs.
Les données sont manipulées à travers des méthodes HTTP.
- Mode file sharing: orienté également multiple accès.
Méthode plus traditionnelle reposant sur des protocoles comme SMB (Server Message Block) ou NFS (Network File System) pour se partager de l’information à travers un réseau d’entreprise.
Cliquez sur l'image pour l'agrandir.
Dans tous les cas, Kubernetes exploite des objets spécifiques.
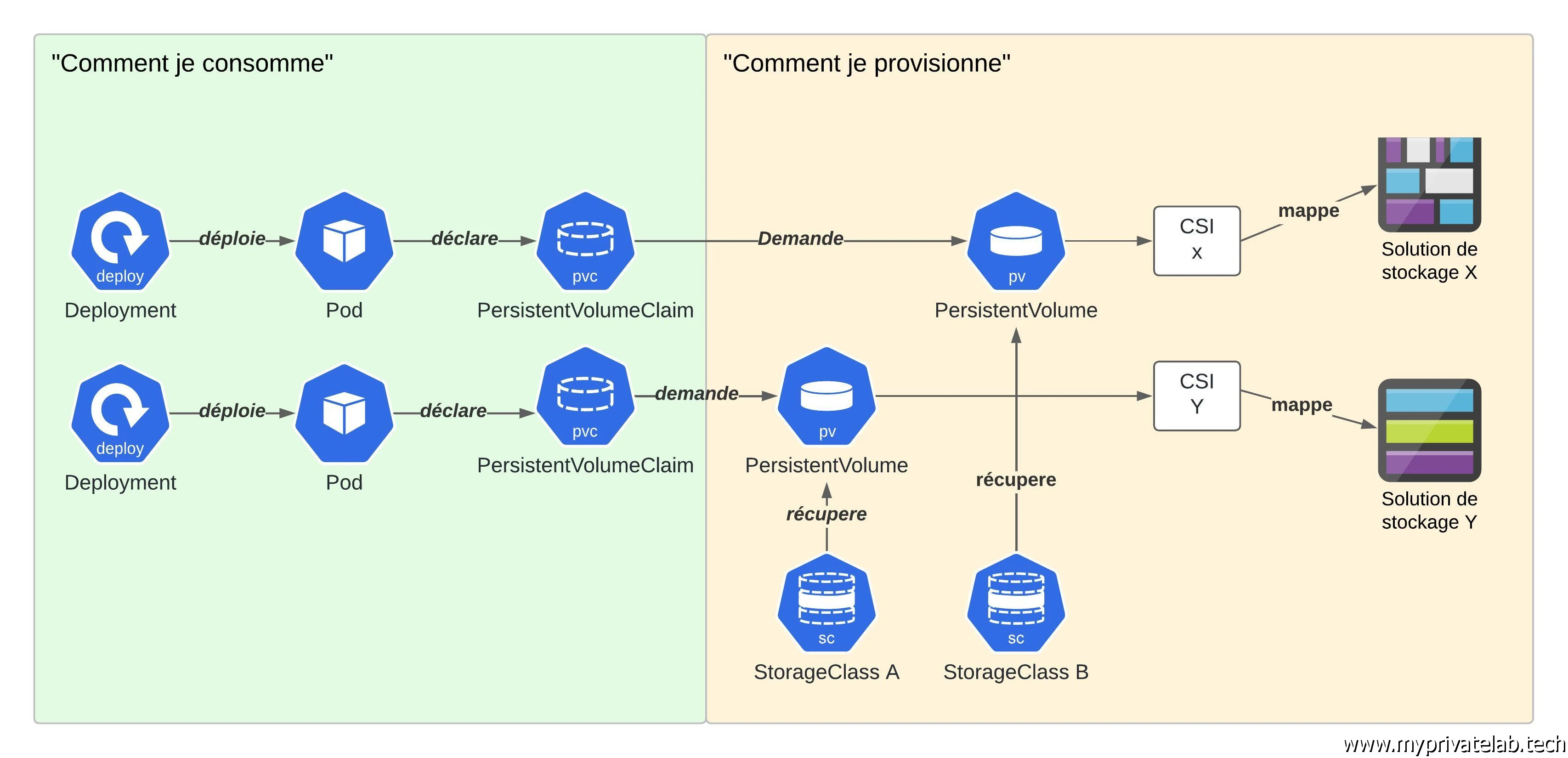
On va partir de l’objet le plus bas niveau, à savoir le PersistentVolume (pv). Il peut être provisionné de manière statique ou dynamique, mais il définit toujours le mode de stockage. C’est lui qui est en charge de persister la donnée.
On retrouve ensuite le PersistentVolumeClaim (pvc). Il correspond à la demande d’un pv. On n’y exprime les caractéristiques attendues (mode d’accès, taille…) et Kubernetes se charge de lui rattacher un pv correspondant si cela est possible:
- Soit en lui proposant un volume existant et disponible, correspondant aux caractéristiques spécifiées (taille et méthode d’accès)
- soit en provisionnant de manière automatique un volume compatible dans une StorageClass (sc)
La StorageClass (sc) justement est le dernier objet associé au stockage. Elle permet de définir un pool de provisionnement répondant à certains critères dans lequel Kubernetes peut piocher pour créer, à la volée, des pv réclamés par des pvc.
Cela évite d’avoir à s’occuper de déclarer des pv, en amont des pvc.
Généralement une sc est rattachée à une technologie de stockage, et plus particulièrement va se baser sur un driver CSI (Container Storage Interface) dont le pv héritera.
Voilà encore un concept à appréhender…mais très important. A la date de l’écriture de cet article, Kubernetes embarque avec lui un certain nombre de drivers lui permettant nativement d’exploiter des protocoles de stockage, comme NFS, pour manipuler des pv. On parle de driver In-Tree.
Seulement cet usage est maintenant déprécié et remplacer par des drivers reposant sur le standard CSI. Pour des questions de maintenabilité et d’efficacité, il n’est plus prévu d’intégrer nativement des drivers de stockage au sein de Kubernetes. CSI permet à qui le souhaite de publier ses propres drivers, souvent pour sa propre solution de stockage pour ensuite pouvoir les intégrer à un cluster K8S et permettre à celui-ci de s’appuyer sur la solution en question.
Dès lors que le standard CSI est respecté, on peut, par exemple, proposer une StorageClass (ou un pv directement) pour offrir aux pods des capacités de persistance de la donnée propre aux caractéristiques associées au driver CSI.
L’ensemble peut paraitre compliqué, mais en réalité cela permet de bien différentier, le provisionnement des PersistentVolumes de leur consommation.
Cliquez sur l'image pour l'agrandir.
Toute la partie CSI, StorageClass et PersistentVolume peut être adressée par des équipes dédiées (ou pas) sans lien direct avec ceux qui expriment des besoins de stockage persistant à travers les pvc.
Le développeur par exemple, n’a pas besoin d’avoir le détail de comment est provisionné un volume. Ce qu’il souhaite c’est bénéficier dans son application d’un espace de x Go accessible ou pas à plusieurs pods à la fois. Peu importe qu’en bout de parcours, les données finissent sur une baie de stockage, un partage de fichier ou autre.
De même l’administrateur de stockage peut faire évoluer ses équipements, proposer des StorageClass répondant à différentes exigences de performance ou de disponibilité indépendamment du reste.
Pour le constructeur de matériel de stockage ou pour les clouds provider, ils ont la liberté de développer un driver CSI pour leur solution afin de les rendre compatibles avec Kubernetes.
Enfin pour K8S, les développeurs du projet peuvent se concentrer sur le cœur de la solution, l’orchestration de conteneurs, sans se préoccuper de maintenir des drivers de stockage en interne. Laissant ce travail à ceux qui sont les mieux placés pour le faire : les fournisseurs de solution de stockage.
Dans cet article c’est sur le mode de file sharing que nous allons nous concentrer. Pour le mode block, n’hésitez pas à faire un tour dans cette partie de mon Cookbook Kubernetes qui décrit l’usage de ce mode dans un contexte VMware (mais la logique est applicable à d’autres écosystèmes). Vous y trouverez également des explications complémentaires sur la persistance de la donnée au sein du Kubernetes.
On va donc traiter deux cas de figure NFS et SMB.
Cliquez sur l'image pour l'agrandir.
Je ne parlerais que très de de StorageClass pour l’usage de ces deux protocoles. Le driver CSI associé à chacun d’entre eux permet sans problème l’usage de StorageClass, mais je me concentrerais ici sur un usage pv/pvc, avec un provisionnement manuel du pv.
CSI NFS
NFS est le protocole historique de partage de fichier en environnement Linux. Très utilisé en entreprise, il a connu plusieurs versions (la 4.2 au moment de cet article) et reste très largement employé en entreprise.
Il est performant et permet sans difficulté de créer des partages accessibles à la fois en écriture et en lecture à plusieurs cibles. Je ne rentrerais pas plus dans le détail du fonctionnement de NFS ici, ce n’est pas le but de l’article.
Prérequis
Pour commencer, il est nécessaire que les workers K8S respectent certaines conditions. Ils doivent avoir les outils NFS installés et le service rpcbind actif. Les commandes à taper peuvent varier d’une distribution à une autre. Me concernant, et exploitant des VMs sous PhotonOS, les instructions sont les suivantes:
tdnf install nfs-utils
tdnf install rpcbind
systemctl enable rpcbind
systemctl start rpcbind

Cliquez sur l'image pour l'agrandir.
Chaque node worker (et même si ce n’est pas forcement nécessaire, les control plane aussi) doivent avoir ces packages de déployés et le service rpcbind démarré.
N’hésitez pas à passer par un outil comme Ansible pour s’assurer de ça.
Installation
Une fois les prérequis en place, il faut installer le driver CSI correspondant à l’usage de NFS.
Même s’il est encore possible de se passer de ce dernier au moment de l’écriture de cet article en s’appuyant sur les drivers In-Tree (comme j’ai pu le faire ici), il est conseillé de prendre l’habitude dès à présent de passer par le CSI. Les drivers In-Tree finiront à un moment ou un autre d’être totalement retirés de K8S.
Le driver CSI NFS s’installe via helm. Si vous n’avez pas encore installé helm sur votre cluster, c’est le moment, helm étant un gestionnaire de package pour Kubernetes largement utilisé et très facilement utilisable : il suffit de récupérer le binaire.
Voici les commandes à taper.
helm repo add csi-driver-nfs https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/charts
helm install csi-driver-nfs csi-driver-nfs/csi-driver-nfs --namespace kube-system --version v4.9.0
Cliquez sur l'image pour l'agrandir.
(La version est suceptible d'évoluer avec le temps). Vérifiez le github attaché au driver.
On n’utilise aucune customisation et on déploie le driver CSI NFS avec sa conf par défaut dans le namespace kube-system. Certains préféreront peut-être y dédier un namespace spécifique. À vous de voir.
Usage
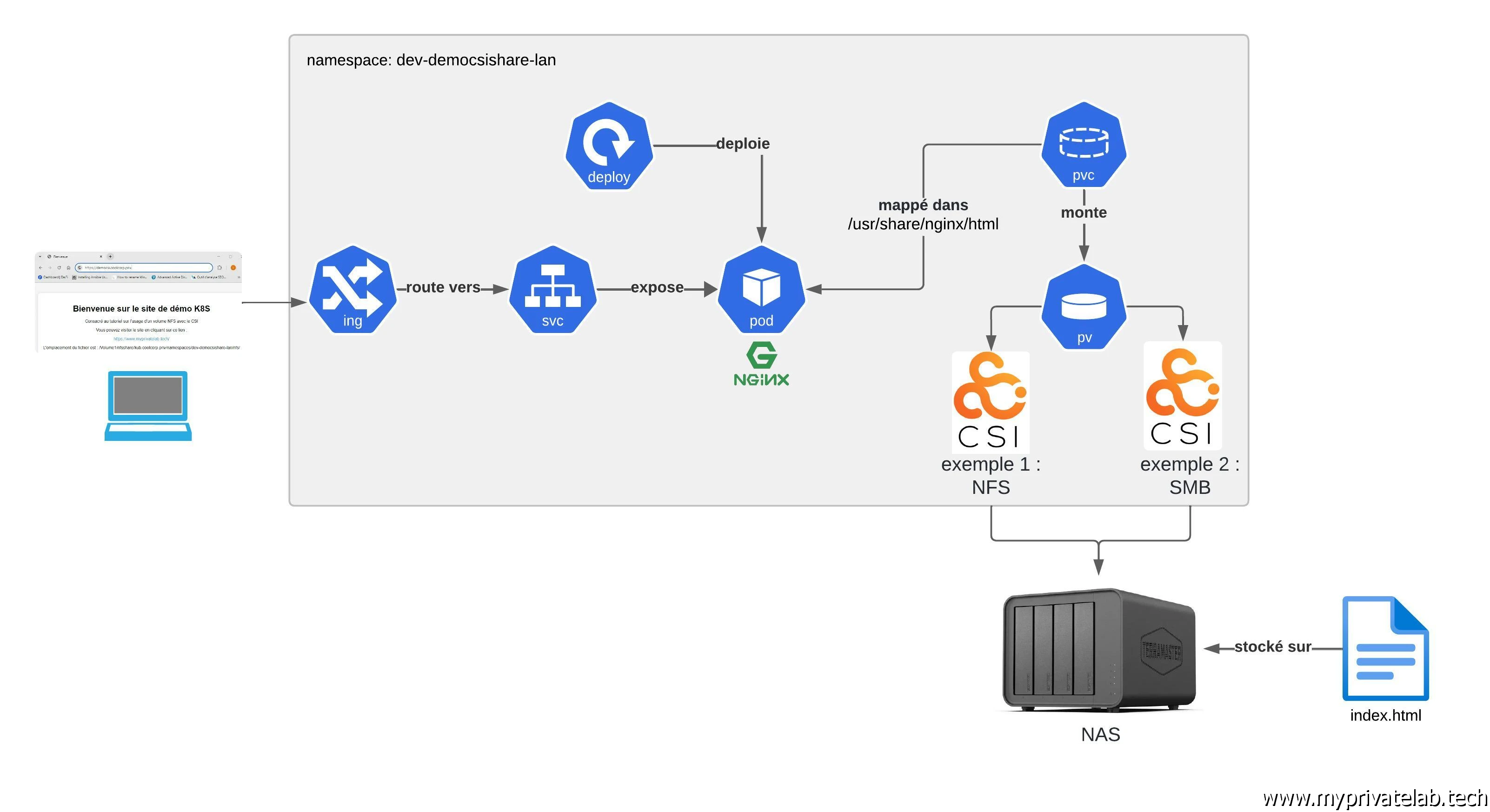
Une fois déployé, on peut directement commencer à créer un volume exploitant ce driver CSI.
Pour le besoin de l’article, je vais passer par un namespace dédié dev-democsishare-lan.
C’est donc la première chose que je vais générer avec la commande kubectl.exe create ns dev-democsishare-lan.
Ensuite, on peut décrire notre pv via le fichier 01-pv-democsishare-nfs.yml:
---
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: nfs.csi.k8s.io
name: pv-democsishare-nfs
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: nfs
tier: default
type: nfs
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
driver: nfs.csi.k8s.io
volumeHandle: /Volume1/nfsshare/kub.coolcorp.priv/namespaces/dev-democsishare-lan/nfs/
volumeAttributes:
server: 192.168.10.152
share: /Volume1/nfsshare/kub.coolcorp.priv/namespaces/dev-democsishare-lan/nfs/
(L'emplacement du partage est donné ici comme exemple et doit etre adapté à votre usage).
Celui-ci reprend les bonnes pratiques que j’ai l’habitude d’utiliser, à commencer par les labels.
Les éléments les plus importants se retrouvent dans la partie spec :.
C’est ici qu’on va déclarer l’espace de stockage souhaité. Dans mon exemple 1Gi.
Petit point important sur cette notion. Dans le cas de NFS (et de SMB) où on expose un partage et non un disque, la volumétrie n’est ici donnée qu’à titre indicatif.
Un partage peut très bien reposer sur une volumétrie disque sous-jacente bien plus grosse que la taille demandée dans le PV. Néanmoins, cela permet de classifier le pv et de donner une indication sur le besoin en volumétrie.
On va également définir la méthode d’accès:
- ReadWriteMany (RWX): permets à plusieurs nœuds d'accéder au pv en lecture et en écriture.
- ReadWriteOnce (RWO): permets à un seul nœud à la fois de monter le pv en lecture et en écriture.
- ReadOnlyMany (ROX): permets à plusieurs nœuds de monter le pv, mais uniquement en lecture.
Pour mon cas, j’utilise ReadWriteMany (RWX).
On retrouve également le politique de suppression de volume: que faire si celui-ci n’est plus réclamé par un pvc ? Plusieurs modes sont possibles:
- Retain: si l’application est supprimée et que le pv n’est plus utilisé, celui-ci reste tout de même au sein du cluster et la donnée est conservée.Il est alors possible de remapper à nouveau ce volume et retrouver la data si nécessaires.
- Recycle: si l’application est supprimée, le pv est alors purgé de ses données, mais reste disponible pour un nouvel usage.
- Delete: si l’application est supprimée, le pv est supprimé (et la donnée avec).
J’ai choisi ici Retain, c’est une politique conservatrice, mais attention, on peut vite se retrouver avec des pv non montés un peu partout et il faut de temps en temps faire le ménage.
On poursuit avec la sous-section csi. C’est ici qu’on va indiquer quel driver utiliser, en l’occurrence nfs.
Le reste des paramètres dépend du driver utilisé, mais l’option volumeHandle est commune à tous les drivers CSI .C’est l’identification unique du volume.
C’est extrêmement important, car c’est de cette identification que dépendent les opérations telles que l’attachement, le détachement et le montage du volume. Dans le cas d’un provisionnement dynamique, la valeur du volumeHandle est générée automatiquement, mais dans un cas ou l’on crée un pv manuellement, il faut s’assurer de choisir un id unique.
Hormis l’interdiction de certains caractères, il n’y a pas de restriction sur la manière de construire cet identifiant.
Me concernant, je réutilise l’emplacement de la cible réseau. Mais cela peut ne pas être suffisant (vous pouvez avoir plusieurs pv qui point vers le même export nfs), veuillez bien à ce que cette valeur reste unique au sein du cluster. Car oui un pv est un objet qui ne dépend pas d’un namespace et reste commun à tout le cluster.
Les options qui suivent sont celles que l’on retrouve couramment pour un montage nfs. Le nom du serveur, le nom de l’export…On pourrait aussi y trouver des options avancées, comme la version de NFS à utiliser (par défaut la 3). Tout cela se retrouve dans la documentation du driver CSI NFS.
Petit aparté, les options de modes d’accès, de politique de suppression et le driver CSI seraient également à utiliser dans le cas d’un StorageClass.
Tous les volumes provisionnés dynamiquement dans cette StorageClass hériteraient de ces caractéristiques.
Il suffit de lancer la création du pv avec la commande kubectl apply -f 01-pv-democsishare-nfs.yml.
Arrivé à cette étape, on peut déjà vérifier que le pv est disponible avec la commande
kubectl get pv nom_du_pv

Cliquez sur l'image pour l'agrandir.
Il est bien renseigné, mais non monté.
C’est normal puisque nous n’avons pas encore écrit le pvc. Le voici justement issu du fichier 02-pvc-democsishare-nfs.yml:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-democsishare-nfs
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: nfs
tier: default
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
volumeName: pv-democsishare-nfs
storageClassName: ""
Il reprend les mêmes caractéristiques que le pv, en dehors du CSI. En effet, dans le pvc, il n’y a pas à connaitre le détail de comment le volume est géré. On se contente d’exprimer le mode d’accès souhaité, la volumétrie dont on n’a besoin et dans notre cas, le nom du volume à utiliser.
Avec une StorageClass on n’aurait pas le nom du volume à préciser. Attention, ici pour éviter tout problème, il vaut mieux mettre l’option StorageClass quand même, mais laisser le paramètre vide…car si K8S peut ne pas tenir compte du nom du volume, s’il trouve une StorageClass qui correspond à ses attentes…si c’est le cas, il va provisionner un nouveau volume dans cette sc plutôt que d’utiliser le pv que vous lui avez indiqué.
Une fois le pvc appliqué (kubectl apply -f 02-pvc-democsishare-nfs.yml), on peut maintenant revérifier le statut du pv. Celui-ci est désormais monté, et on retrouve le nom du pvc associé.

Cliquez sur l'image pour l'agrandir.
On peut également vérifier le statut du pvc avec la commande kubectl get pvc nom_pvc -n nom_namespace:

Cliquez sur l'image pour l'agrandir.
Cette fois-ci il faut préciser le namespace, car le pvc est propre à un namespace. Le pvc est également dans un statut bound puisqu’un volume a été trouvé et qui répond à ses exigences (en l’occurrence notre pv créé manuellement).
On peut poursuivre avec l’objet Deployment. Je ne vais pas décrire spécifiquement sa configuration, je vous invite à lire cet article pour plus d’informations sur son usage et à lire la définition rattachée.
Voici le contenu du fichier 03-deploy-democsishare-nfs.yml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-democsishare-nfs
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: nfs
spec:
strategy:
type: Recreate
selector:
matchLabels:
environment: dev
network: lan
application: nfs
template:
metadata:
labels:
environment: dev
network: lan
application: nfs
spec:
nodeSelector:
network: lan
containers:
- name: demo-nginx-democsishare-nfs
image: nginx:1.27
resources:
requests:
memory: "8Mi"
cpu: "250m"
limits:
memory: "256Mi"
cpu: 1
livenessProbe:
initialDelaySeconds: 5
periodSeconds: 5
exec:
command:
- ls /usr/share/nginx/html
ports:
- containerPort: 80
volumeMounts:
- name: pv-democsishare-nfs
mountPath: "/usr/share/nginx/html"
volumes:
- name: pv-democsishare-nfs
persistentVolumeClaim:
claimName: pvc-democsishare-nfs
Ce qui nous intéresse ici c’est la section de fins volumes. C’est ici qu’on associe le pvc créé précédemment à un volume au sein du pod. Attention, le volume n’est pas directement le pv, même si ici j’utilise le même nom pour simplifier la correspondance. Le volume est une notion propre au pod.
C’est d’ailleurs plus haut dans la définition du container rattaché au pod, qu’on n’indique que ce volume va être monté dans /usr/share/ngingx/html.
On n’a donc notre pv qui se retrouve rattaché à notre pvc, ce même pvc est appelé dans le Deployment pour créer un volume, volume qui sera mappé dans un path local au conteneur du pod.
Une fois le Deployment lancée avec la commande kubectl apply -f 03-deploy-democsishare-nfs.yml, on peut visualiser cette association
Après avoir vérifié que le pod est lancé via la commande kubectl get pod -n nom_namespace.
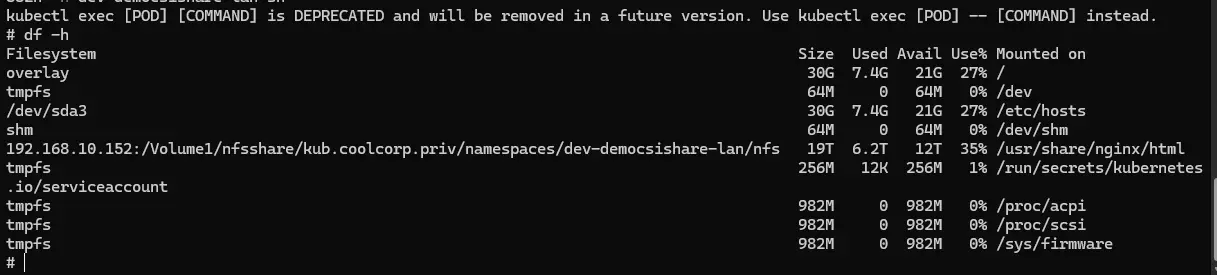
On se connecte en interactif dans ce dernier avec la commande kubectl exec -it nom_pod -n nom_namespace sh et on utilise la commande df -h pour lister les points de montage.
On retrouve bien notre partage NFS rattaché au sein du conteneur dans le path souhaité.
Cliquez sur l'image pour l'agrandir.
Bien entendu, cela sous-entend que coté baie de storage, vous ayez autorisé les IPs des node K8S à se connecter à l’export nfs.
Le partage a beau être monté dans le conteneur, l’IP vu côté baie de stockage est l’IP du node qui exécute le conteneur. Pensez bien à déclarer tous vos nodes, car le pod peut être exécuté sur chacun d’entre eux si les règles de déploiement l’autorisent.
D’ailleurs si vous souhaitez exploiter du NFS 4, il faudra mettre en place les bonnes informations d’authentifications dans les options du driver au niveau du pv.
Dans mon cas, j’ai simplement autorisé les IP de mes nodes sur mon NAS Terramaster pour l’export en question.
On continue la démonstration avec la suite des objets. Je ne vais pas les détailler ici, ce n’est pas le but. Mais on va passer par un Service chargé d’exposer le pod, puis un Ingress pour l’accès au service depuis l’extérieur du cluster, avec un certificat pris en compte sous Traefik.
Si tout cela ne vous dit pas grand-chose, n’hésitez pas à faire un tour ici (principe des ingress) et ici (exemple du déploiement d’une application complète).
A titre d'information voici le contenu du fichier 04-svc-democsishare-nfs.yml chargé de la définition du Service:
---
kind: Service
apiVersion: v1
metadata:
name: svc-democsishare-nfs
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: nfs
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
environment: dev
network: lan
application: nfs
Puis le contenu du fichier 05-ing-democsishare-nfs.yml pour le certificat et l'Ingress:
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-democsishare-nfs
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: nfs
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- democsinfs.coolcorp.priv
secretName: sec-certificate-democsinfs
rules:
- host: democsinfs.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-democsishare-nfs
port:
number: 80
Maintenant que tout est en place, je vais positionner au sein du partage NFS, directement via mon NAS, un fichier index.html.
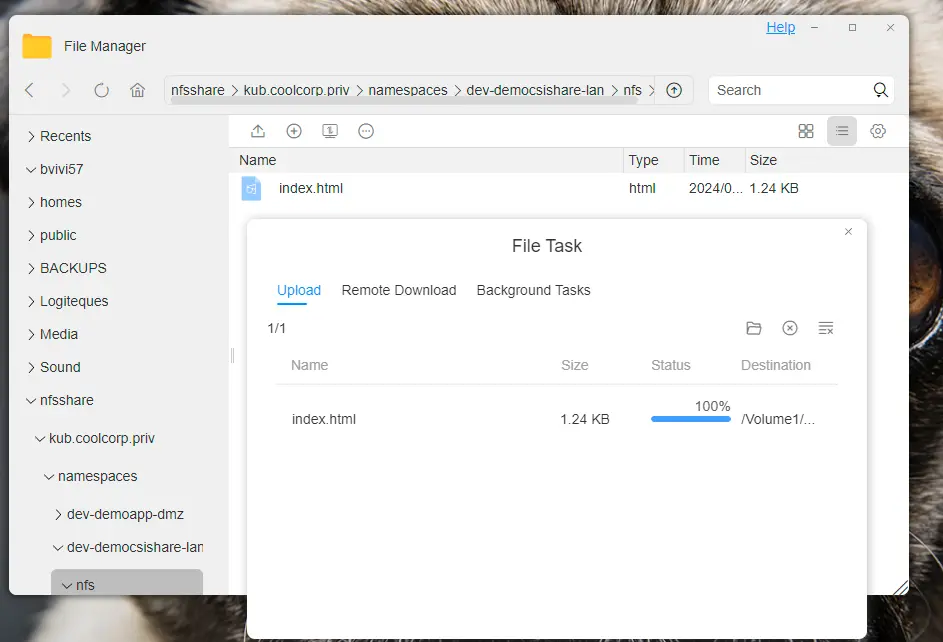
Cliquez sur l'image pour l'agrandir.
De cette manière l’image NGINX qui tourne au sein du conteneur présent dans mon pod va pouvoir délivrer le contenu du code HTML qui s’y trouve.
J’ai bien entendu pris soin auparavant de mettre une entrée DNS renvoyant l’URL décrite dans l’ingress pour accepter les requêtes.
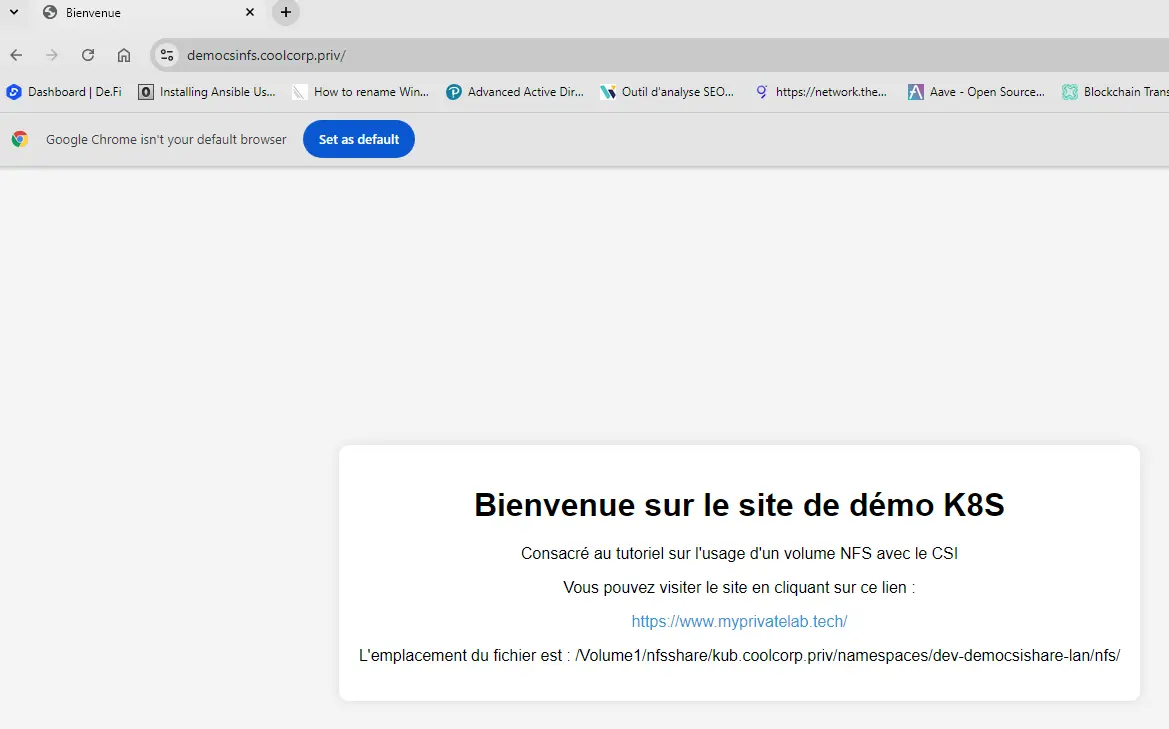
C’est bien le contenu de mon fichier index.html qui s’affiche dans mon navigateur. Si maintenant je venais à redémarrer mon pod (donc mon conteneur), la data reste puisqu’elle est sur le partage.
De la même manière, si je souhaite augmenter le nombre de pods, en mettant à jour mon Deployment pour autoriser un replica plus important d’instance de mon pod, chaque pod pourra disposer de l’accès au partage et donc délivrer le rendu attendu. Cela est rendu possible puisque je suis dans un mode ReadWriteMany. J’assure ainsi une haute disponibilité de mon instance NGINX.
Cliquez sur l'image pour l'agrandir.
CSI SMB
SMB (Server Message Block) est le protocole de partage de fichiers utilisé du côté des environnements Microsoft.
À noter que vous entendez souvent parler également de CIFS (Common Internet File System). Or depuis maintenant plusieurs années, CIFS qui était une version spécifique de SMB développé par Microsoft n’est plus d’actualité.
Prérequis
C’est désormais SMB dans sa version 3 qui fait foi…mais on n’a tendance à mélanger les deux et on continue souvent d’employer le terme de CIFS pour désigner des partages SMB.
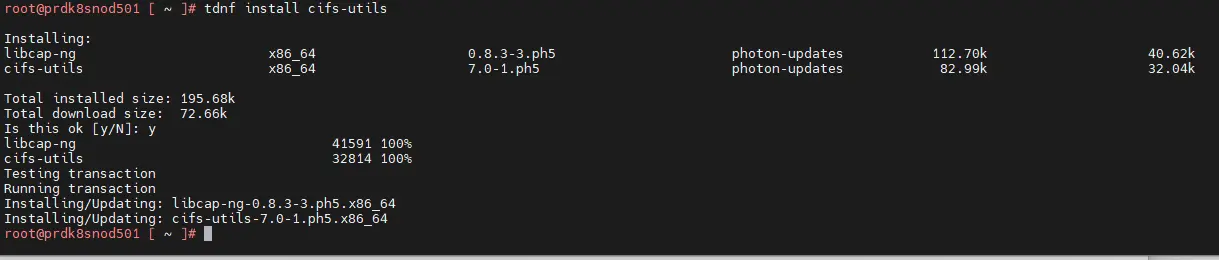
D’ailleurs l’un des prérequis à déployer sur les nodes K8S est l’installation du paquet cifs-utils...Dans mon cas et sous PhotonOS, la commande est tdnf install cifs-utils.
Cliquez sur l'image pour l'agrandir.
Installation
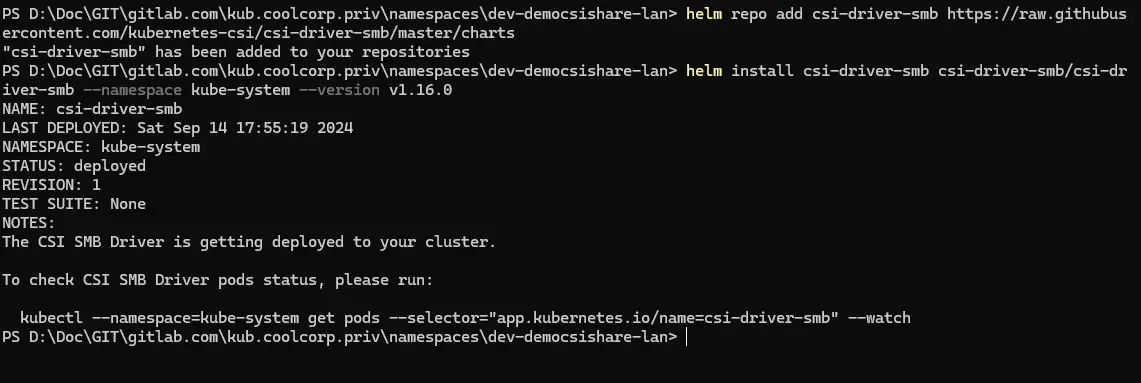
Comme pour NFS, le driver CSI SMB peut se déployer avec Helm. Les commandes sont les suivantes:
helm repo add csi-driver-smb https://raw.githubusercontent.com/kubernetes-csi/csi-driver-smb/master/charts
helm install csi-driver-smb csi-driver-smb/csi-driver-smb --namespace kube-system --version v1.16.0
Cliquez sur l'image pour l'agrandir.
(La version est suceptible d'évoluer avec le temps). Vérifiez le github attaché au driver.
Usage
On va retrouver dans l’usage du CSI SMB la même logique que pour NFS. Sauf qu’on va avoir besoin d’identifiants de connexion pour l’accès au partage.
Dans un environnement d’entreprise, les partages SMB sont souvent en corrélation avec un annuaire Active Directory (AD). L’accès au partage est soumis à la présentation d’un compte de domaine disposant des accès adéquate au partage.
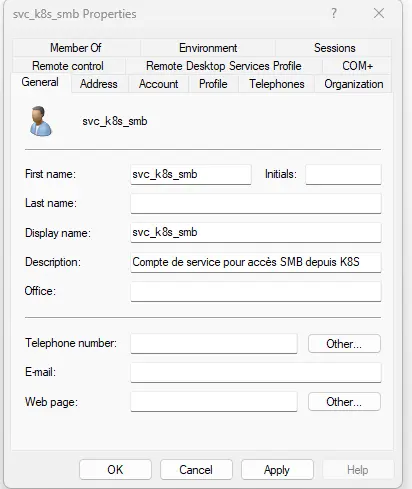
Je vais donc avoir besoin de créer un compte de service dans l’annuaire AD de mon lab.
Cliquez sur l'image pour l'agrandir.
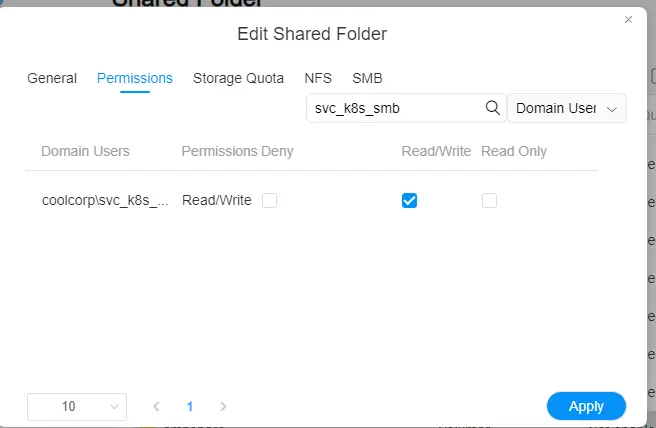
Ce compte svc_k8s_smb de mon domaine coolcorp.priv va être déclaré comme disposant des droits d’écriture sur mon partage, toujours assuré par mon NAS Terramaster, mais cette fois-ci via le protocole SMB.
Cliquez sur l'image pour l'agrandir.
D’ailleurs en me donnant également les droits à mon propre compte, je peux directement browser le partage depuis mon poste de travail.
Il est nécessaire de stocker les identifiants de connexions fraichement créés dans un Secret Kubernetes pour que celui-ci puisse être utilisé par le driver CSI SMB au sein d’un pv.
Attention au choix du mot de passe de votre compte de service, certains caractères spéciaux peuvent être mal interprétés lors de la création d’un secret. Soyez vigilant, le secret est créé, mais le password est faux.
Dans mon cas, je déclare le secret en mode interactif et dans un namespace dédié inf-lan-smb que j’ai créé précédemment (kubectl create ns inf-lan-smb).
Voici la commande:
kubectl create secret generic nom_du_secret --from-literal username=nom_du_compte --from-literal password="password_du_compte" --from-literal domain=domaine_nom_court -n nom_namespace

Cliquez sur l'image pour l'agrandir.
J’ai fait le choix de dédier un namespace inf-smb-lan pour y stocker le secret. Cela me permet de centraliser les identifiants nécessaires à l’accès à mes partages SMB. Attention pour rappel, un secret K8S ne fait qu’offusquer en base64 les informations qu’il contient. Soyez toujours vigilant de l’accès au secret.
On peut s’attarder maintenant sur le fichier 01-pv-democsishare-smb.yml qui va contenir la définition du pv:
---
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: smb.csi.k8s.io
name: pv-democsishare-smb
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: smb
tier: default
type: smb
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
mountOptions:
- dir_mode=0777
- file_mode=0777
csi:
driver: smb.csi.k8s.io
volumeHandle: //storage.coolcorp.priv/smbshare/kub.coolcorp.priv/namespaces/dev-democsishare-lan/smb
volumeAttributes:
source: //storage.coolcorp.priv/smbshare/kub.coolcorp.priv/namespaces/dev-democsishare-lan/smb
nodeStageSecretRef:
name: secret-smb-default
namespace: inf-smb-lan
On est très proche de ce qu’on a vu pour NFS. On retrouve la logique d’accesModes, de persistanceVolumeReclaimPolicy avec en plus des mountOptions .
En effet lorsque le pv va être présenté au pod, et monté dans le ou les conteneurs associés, il faut indiquer les droits équivalents Linux avec lesquels monter le partage. Ici on ne s’embête pas et on utilise l’horrible 777 qui autorise tout groupe et tout users des conteneurs. Mais ce n’est pas si gênant, puisque de toute façon l’accès est en fait réalisé par le compte de service.
Compte de service qu’on retrouve en fin de fichier dans la section nodeStageSecretRef: qui reprend le secret créé précédemment.
Cette sous-section est dans la section CSI dans laquelle cette fois-ci on indique l’usage du driver smb.csi.k8s.io. Comme pour NFS, on retrouve la notion de volumeHandle à laquelle il faut prêter une attention toute particulière pour s’assure de l’unicité de sa valeur.
Puis on fait référence au partage.
On applique le fichier pour créer le volume avec la commande kubectl apply -f 01-pv-democsishare-smb.yml.
On peut s’assurer que celui-ci est disponible avec la commande kubectl get pv nom_pv.
Pour l’instant le pv est non associé à un pvc, mais ce n’est que temporaire, puisque justement voici le contenu du fichier 02-pvc-democsishare-smb.yaml qui décrit le pvc:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-democsishare-smb
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: smb
tier: default
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
volumeName: pv-democsishare-smb
storageClassName: ""
Rien de nouveau sous le soleil, on n’est à l’identique de celui utilisé par NFS, hors nom et label. Mais comme pour NFS, n’apparait pas dans le pvc la notion de driver CSI. Je précise juste le type d’accès, taille et le nom du pv.
J’espère que vous commencez maintenant à voir l’intérêt de la logique. Dans notre exemple, on pourrait passer de NFS à SMB et inversement sans qu’on est à remettre en cause les pvc.
Si j’avais choisi des noms plus génériques pour mes pv, j’aurais très bien pu décider de changer de protocole de mon côté, en changeant de drivers CSI et en mettant à jour la conf de mes pv, sans que cela nécessite de modifications côté pvc (Par contre attention, cela nécessite tout de même de redéployer les pvc).
Une fois appliqué avec la commande kubectl apply -f 02-pvc-democsishare-smb.yaml, on peut rappeler la commande de controle du pv pour observer que celui-çi est désormais associé au pvc.

Cliquez sur l'image pour l'agrandir.
Pour le reste, on déploie l’application via le Deployment 03-deploy-democsishare-smb.yml avec en bas de fichier la définition du volume, qui s’appuie sur le pvc afin de monter le pv dans le contexte du conteneur nginx dans /usr/share/nginx/htlm.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-democsishare-smb
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: smb
spec:
strategy:
type: Recreate
selector:
matchLabels:
environment: dev
network: lan
application: smb
template:
metadata:
labels:
environment: dev
network: lan
application: smb
spec:
nodeSelector:
network: lan
containers:
- name: demo-nginx-democsishare-smb
image: nginx:1.27
resources:
requests:
memory: "8Mi"
cpu: "250m"
limits:
memory: "256Mi"
cpu: 1
livenessProbe:
initialDelaySeconds: 5
periodSeconds: 5
exec:
command:
- ls /usr/share/nginx/html
ports:
- containerPort: 80
volumeMounts:
- name: pv-democsishare-smb
mountPath: "/usr/share/nginx/html"
volumes:
- name: pv-democsishare-smb
persistentVolumeClaim:
claimName: pvc-democsishare-smb
Comme pour NFS, après avoir lancé le déploiement avec la commande kubectl apply -f 03-deploy-democsishare-smb.yml.
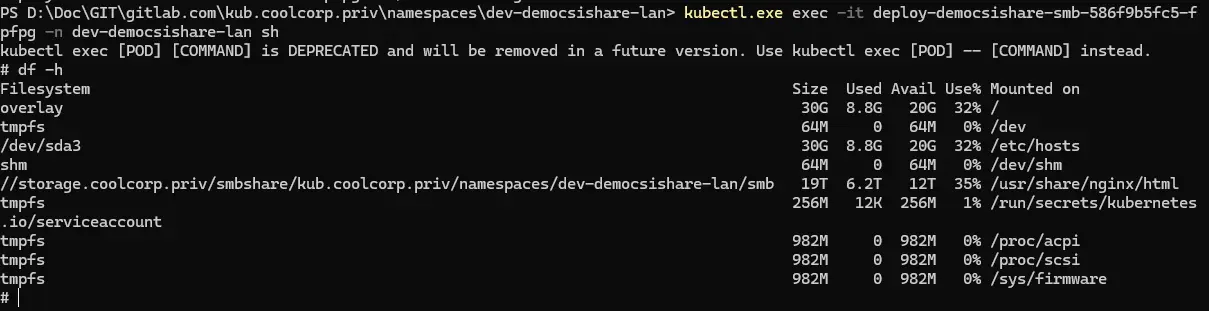
On s’assure que le pod est actif et on peut vérifier le montage dans son contexte avec les commandes:
kubectl exec -it nom_pod -n nom_namespace sh
df -h
Cliquez sur l'image pour l'agrandir.
Je poursuis la suite en appliquant les objets restants:
Le service via le fichier 04-svc-democsishare-smb.yml:
---
kind: Service
apiVersion: v1
metadata:
name: svc-democsishare-smb
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: smb
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
environment: dev
network: lan
application: smb
Puis l'Ingress avec le fichier 05-ing-democsishare-smb.yml:
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-democsishare-smb
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: smb
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- democsismb.coolcorp.priv
secretName: sec-certificate-democsismb
rules:
- host: democsismb.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-democsishare-smb
port:
number: 80
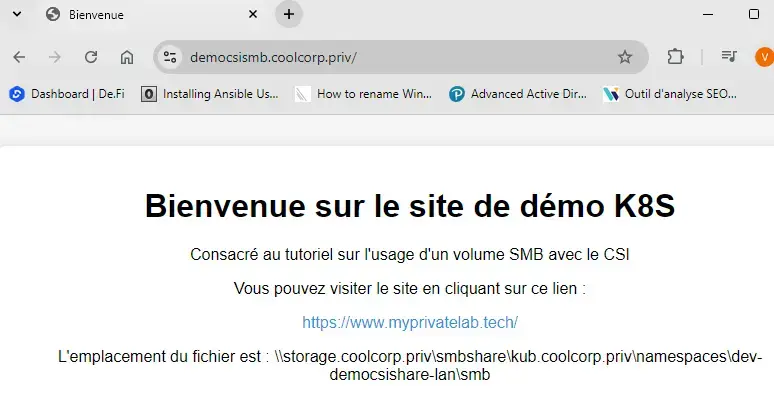
Je place un fichier index.html cette fois-ci dans le partage SMB et je tente un accès au site via l’URL que je lui ai dédiée.
Cliquez sur l'image pour l'agrandir.
Cette fois-ci c’est bien le contenu de mon fichier index.html présent dans mon partage SMB qui est traité par NGINX.
Cliquez sur l'image pour l'agrandir.
Utilisation d'un sous dossier
Je profite également de SMB pour mettre en avant un autre principe pouvant s’avérer pratique, l’usage de subpath.
Cette option fonctionne aussi bien avec SMB qu’avec NFS.
Admettons que je souhaite accéder à un sous-répertoire de mon partage, sans avoir à dédier un pv à ce sous-dossier.
Je peux simplement ajouter l’option subPath: au niveau de mon Deployment. Si je reprends mon exemple précédent avec SMB en redéployant mon application, mais cette fois-ci avec les options suivantes.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-democsishare-smbsub
namespace: dev-democsishare-lan
labels:
environment: dev
network: lan
application: smb
spec:
strategy:
type: Recreate
selector:
matchLabels:
environment: dev
network: lan
application: smb
template:
metadata:
labels:
environment: dev
network: lan
application: smb
spec:
nodeSelector:
network: lan
containers:
- name: demo-nginx-democsishare-smb
image: nginx:1.27
resources:
requests:
memory: "8Mi"
cpu: "250m"
limits:
memory: "256Mi"
cpu: 1
livenessProbe:
initialDelaySeconds: 5
periodSeconds: 5
exec:
command:
- ls /usr/share/nginx/html
ports:
- containerPort: 80
volumeMounts:
- name: pv-democsishare-smb
mountPath: "/usr/share/nginx/html"
subPath: subfolder
volumes:
- name: pv-democsishare-smb
persistentVolumeClaim:
claimName: pvc-democsishare-smb
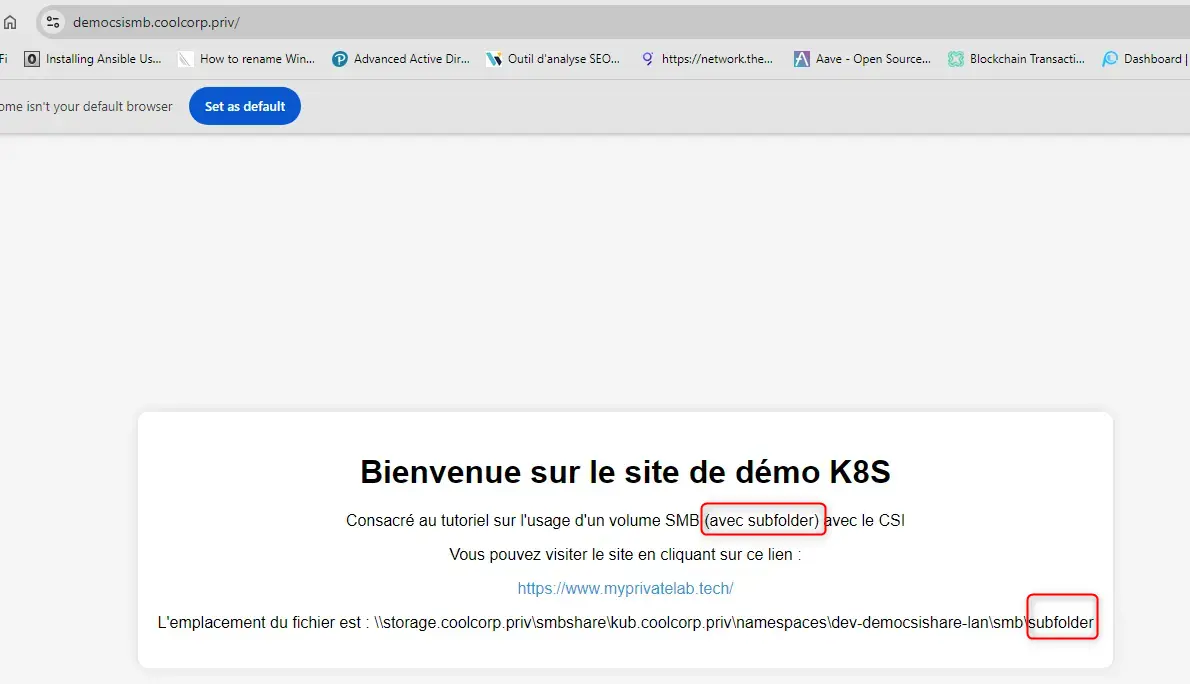
J’accède au fichier index.html positionné dans le sous-répertoire subfolder de mon partage, c’est désormais à cet index htlm que mon application NGINX accède. Je n’ai pas eu à modifier le pv ou le pvc.
Cliquez sur l'image pour l'agrandir.
Principes à retenir
Avant de conclure, j’aimerais lister une petite liste de règles concernant les pv/pvc.
- La relation pv/pvc est unique. On ne peut pas avoir plusieurs pvc qui font référence au même pv et inversement. Dans le cas d’un mode File Sharing, comme ici, si vous devez exposer le même partage à plusieurs pods issues de Deployment distinct, il vous faudra créer autant de pv et de pvc que de Deployment…avec pour chaque pv un volumeHandle unique, mais avec une configuration identique au niveau du partage recherché.
- Pour les CSI NFS et SMB présentés dans cet article, l’usage de StorageClass est possible permettant ainsi de se passer du besoin de définir le pv, celui-ci se provisionnant automatiquement dans la StorageClass. Mais dans ce cas, un sous dossier spécifique sera créé automatiquement pour chaque volume. Le nom de ce sous-dossier sera généré automatiquement et vous n’avez pas la possibilité de le choisir.
- Une fois créé un pvc n’est plus modifiable. Il faudra passer par une suppression du pvc (en faisant attention à la politique de space reclaim appliqué au volume) pour modifier ces caractéristiques. Certains drivers CSI autorisent des storageClass dont on peut activer les fonctionnalités de volume expansion, mais c’est plutôt pour des usages en mode block. Dans ce cas on peut redimensionner un pvc qui donnera lieu à redimensionnement du pv qui aura été automatiquement provisionné.
- Un pv rattaché à un pvc n’est pas supprimable, pour libérer un pv, il faut d’abord supprimer le pvc qui l’exploite.
Une fois le pvc supprimé, c’est la politique de space reclaim qui s’applique.
- Il est possible de rattacher un pv disposant d’une politique de space reclaim à Retain, mais cela passe des opérations spécifiques (que je décrirais dans un article à part)
- Attention aux bascules automatiques en cas de perte de node pour des pv exploitant un accès ReadWriteOnce. Par définition cette méthode d’accès n’autorise pas plusieurs pods à accéder à la donnée. Si un node tombe brutalement et ne donne plus signe de vie, Kubernetes ne peut pas savoir si ce node est isolé (auquel cas il accède toujours à la donnée) ou s’il est vraiment HS (et ne verrouille plus la donnée). Les pods ne basculeront pas forcément automatiquement sur les nodes survivants tous simplement parce que Kubernetes n’a plus de vue sur l’accès à la donnée. Il ne veut pas prendre le risque de remonter un pv prévu pour un accès exclusif à d’autres nodes. Il faudra sans doute intervenir manuellement pour libérer les pv et forcer ces derniers à être remontés ailleurs.
Conclusion
L’usage de la donnée persistante n’est pas des plus simples sous Kubernetes. Mais une fois la logique assimilée, on comprend qu’elle offre une grande modularité et s’inscrit totalement dans une logique cloud ou l’on cherche à séparer le compute du storage. Il ne faut pas hésiter à manipuler les pv, pvc et sc pour se familiariser avec chacun des concepts et ne pas tomber dans une facilité d’exploiter le restant des drivers in tree.
Je ne l’ai pas précisé, mais on pourrait exploiter des pv directement sans se préoccuper des pvc, mais c’est une mauvaise pratique qui risque sur le long terme de vous poser des problèmes de gestions. Privilégier donc toujours, la combinaison pv/pvc avec ou sans StorageClass et l’usage de driver CSI.
Comme expliqué en début d’article, j’ai focalisé sur SMB et NFS pour des besoins orientés filesharing. Vous pouvez retrouver néanmoins des explications sur le mode block et l’usage de StorageClass dans la section dédiée au driver CSI vSPhere de mon CookBook Kubernetes.
N’oubliez pas que tout le monde n’a pas les mêmes usages de son stockage et que les besoins peuvent varier d’une entreprise à une autre, voir d’une application à une autre. Je n’ai pas non plus illustré le stockage cloud (objet), avec par exemple l’usage d’un pv reposant sur un bucket S3, mais la logique reste la même que celle présentée ici.
C’est l’avantage de Kubernetes, son côté modulaire et orienté objet peut être compliqué à appréhender au début, mais ensuite vous arriverez facilement à décliner les concepts, peu importe l’infrastructure sous-jacente.
Pour ceux qui le souhaite, mes fichiers exemples sont disponibles sur mon github.