KubeVirt: Partie 2 - Deploiement de KubeVirt
Introduction
Mon article précédent établit une introduction à Kubevirt avec une description de ses composants et quelques explications sur son fonctionnement.
Durant l’article sont donnés les prérequis à mettre en œuvre pour obtenir un node Kubernetes capable d’exécuter des VMs sous KubeVirt.
Je ne vais donc pas ici rappeler les fondamentaux et vous encourage vivement à lire le premier article avant de poursuivre celui-ci.
C’est maintenant le moment de se lancer dans la réalisation concrète de la cible détaillée dans ce schéma.
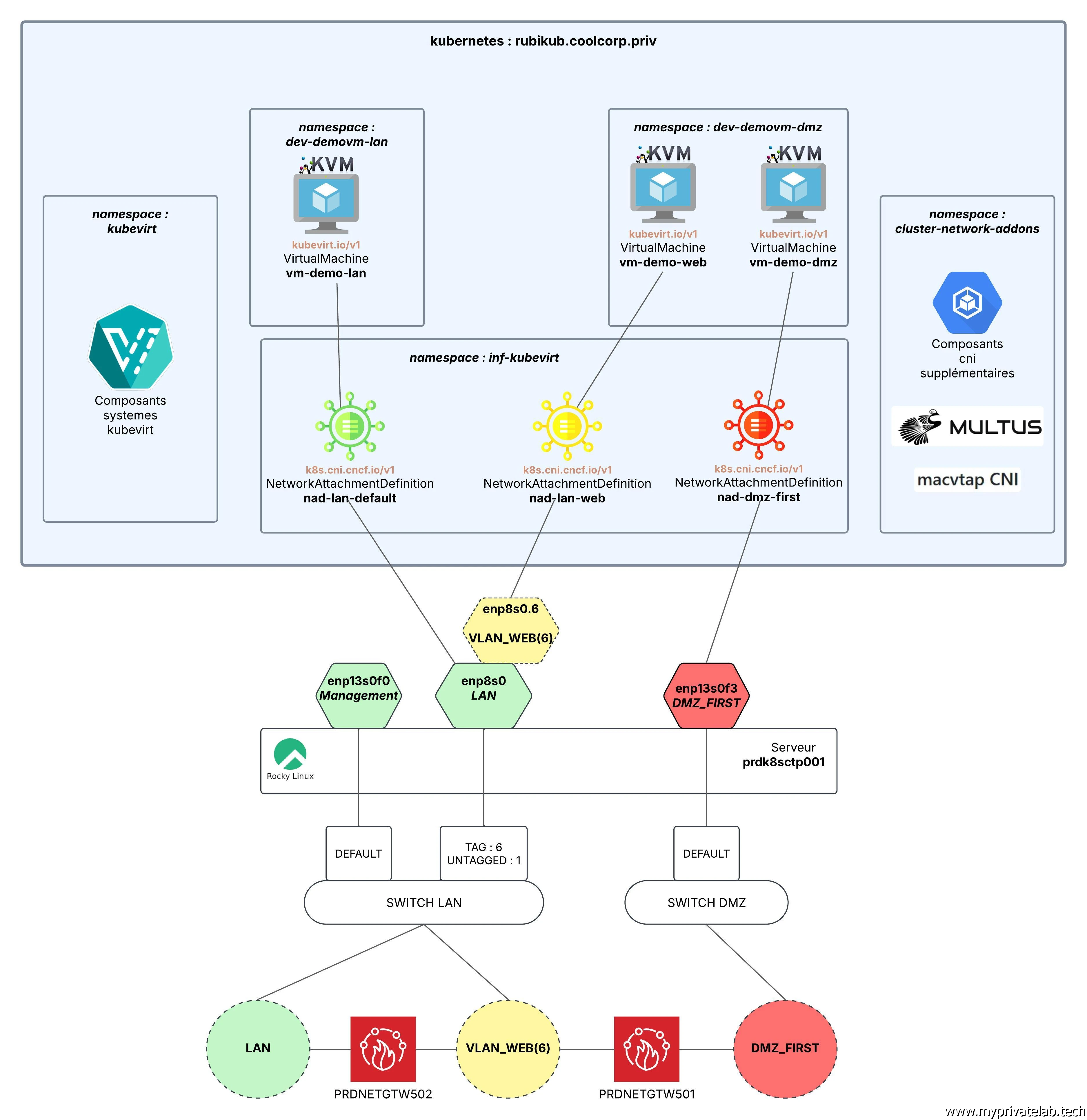
Cliquez sur l'image pour l'agrandir.
Si vous avez suivi les quelques manipulations décrites dans l’article précédent, vous devriez savoir qu’à ce stade on dispose d’un seul node Kubernetes, servant à la fois de master et de worker, sur lequel n’a pas encore été déployé un CNI (Container Network Interface).
Une fois de plus, il est important que vous soyez familier avec le concept de CNI avant d’aller plus loin. Pour cela vous pouvez passer par là.
Installation de Cilium
Le CNI retenu est le même que pour mon cluster principal, il s’agit de Cilium.
Il va servir à traiter la connectivité de base pour les pods et les VMs.
Comme je l’ai fait dans l’article dédié à l’usage d’un GPU sous Kubernetes avec l’installation de cilium sur une architecture mononode, je vais utiliser helm avec ce fichier de configuration (cilium-values.yaml):
kubeProxyReplacement: true
k8sServiceHost: 192.168.10.160
k8sServicePort: 6443
ipam:
mode: "cluster-pool"
operator:
clusterPoolIPv4PodCIDRList:
- "10.13.0.0/16"
hubble:
relay:
enabled: true
ui:
enabled: true
frontend:
server:
ipv6:
enabled: false
tls:
auto:
enabled: true
method: helm
certValidityDuration: 1095
operator:
replicas: 1
Cilium doit donc se déployer sur mon node associé a l’API serveur répondant à l’IP 192.168.10.160 (l'IP de mon serveur prdk8sctp001 ) sur le port 6443.
Un subnet dédié aux pods sous gestion réseau de cilium est défini à 10.13.0.0/16. Bien entendu cette plage doit être réservée au cluster et ne pas être utilisée par un autre réseau externe à la plateforme.
On va exploiter cilium dans la totalité de ses fonctionnalités puisqu’on remplace également la couche basique de Kubernetes kube-proxy.
Kube-proxy assure habituellement la distribution du trafic entre les pods et les services. Il est possible de s’appuyer sur ce dernier ou de le remplacer totalement avec certains CNI comme cilium. Ce n’est pas une obligation, mais cela permet de meilleures performances et des capacités de filtrage supérieures grâce à l’intégration eBPF (Extended Berkeley Packet Filter) native de cilium.
eBPF est une technologie intégrée au noyau Linux autorisant l’exécution de code personnalisé directement dans le kernel. Il devient ainsi possible d’apporter des fonctions de filtrage de paquets, de loab balancing et de surveillance du trafic de manière bien plus optimisée et efficace.
Se passer de kube-proxy nécessite de ne pas l’avoir déployé avant...C’est pourquoi dans mon cookbook sur K8S, lorsque j’utilise kubeadm pour initier mon cluster je passe comme argument --skip-phases=addon/kube-proxy.
Si celui-ci est actif sur votre cluster, il faudra le supprimer au préalable, généralement avec la commande:
kubectl delete daemonset kube-proxy -n kube-system
Dans mon cas, ce n’est pas nécessaire, mon cluster ayant été initié sans kube-proxy. On peut passer au déploiement de cilium directement.
On va utiliser le gestionnaire de package helm. J'évoque ce dernier dans la partie 3 de mon cookbook dédié à Kubernetes. C’est un simple binaire qui exploite vos accès au cluster pour y déployer des applications via une logique de repository et de packaging, simplifiant ainsi leur installation et leur mise à jour.
Voici la commande:
helm install --version 1.17.1 --namespace=kube-system cilium cilium/cilium --values=./cilium-values.yaml --set hubble.relay.tolerations[0].key="node-role.kubernetes.io/control-plane" --set hubble.relay.tolerations[0].operator="Exists" --set hubble.relay.tolerations[0].effect="NoSchedule" --set hubble.relay.tolerations[1].key="node-role.kubernetes.io/master" --set hubble.relay.tolerations[1].operator="Exists" --set hubble.relay.tolerations[1].effect="NoSchedule" --set hubble.ui.tolerations[0].key="node-role.kubernetes.io/control-plane" --set hubble.ui.tolerations[0].operator="Exists" --set hubble.ui.tolerations[0].effect="NoSchedule" --set hubble.ui.tolerations[1].key="node-role.kubernetes.io/master" --set hubble.ui.tolerations[1].operator="Exists" --set hubble.ui.tolerations[1].effect="NoSchedule" --set cni.exclusive=false
(la version de Cilium est à adapter au fur à mesure de la sortie des releases)

Cliquez sur l'image pour l'agrandir.
Elle peut paraitre très longue, mais c’est principalement lié à l’usage d’un seul node sur lequel se retrouve les composants d’un control plane. Par défaut certains éléments de Cilium ne peuvent pas se déployer sur un master.
Dès l’article précédent, j’ai levé la notion de taint associé à un control plaine pour autoriser l’exécution d’application sur le node. (Ce qui ne faut jamais faire en production !).
Malgré cela, j’insère dans ma commande, les tolérances nécessaires pour que Cilium exécute l’intégralité de ses composants, même s’ils ne disposent que d’un seul node.
Si vous exploitez un vrai cluster avec plusieurs noeuds, vous pouvez rester sur la commande:
helm install --version 1.17.1 --namespace=kube-system cilium cilium/cilium --values=./cilium-values.yaml --set cni.exclusive=false
Même dans cette version simplifiée, j’attire votre attention sur le paramètre --set cni.exclusive=false
Il est très important car dans le cadre de KubeVirt nous allons devoir déployer d’autres CNI. Sans cette option, cilium écrasera automatiquement toute configuration tierce d’un autre CNI s’accaparant l’exclusivité de la gestion réseau du cluster.
À ce stade on peut vérifier le déploiement de cilium:
kubectl get pod -n kube-system
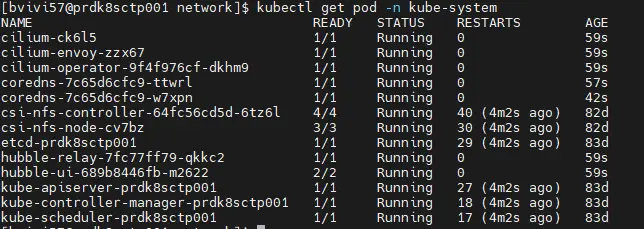
Cliquez sur l'image pour l'agrandir.
Le node est désormais en statut « ready ».
kubectl get node

Cliquez sur l'image pour l'agrandir.
Installation de KubeVirt
Il est temps de passer par l’installation de KubeVirt.
Pour ça on va suivre le guide officiel en commençant par fixer en variable la version cible à déployer.
export RELEASE=$(curl https://storage.googleapis.com/kubevirt-prow/release/kubevirt/kubevirt/stable.txt)

Cliquez sur l'image pour l'agrandir.
Au moment de la rédaction de cet article c’est la version 1.4.
Cliquez sur l'image pour l'agrandir.
On s’appuie ensuite sur cette variable pour récupérer et exécuter les yamls nécessaires directement depuis le repo du projet.
kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${RELEASE}/kubevirt-operator.yaml
kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${RELEASE}/kubevirt-cr.yaml
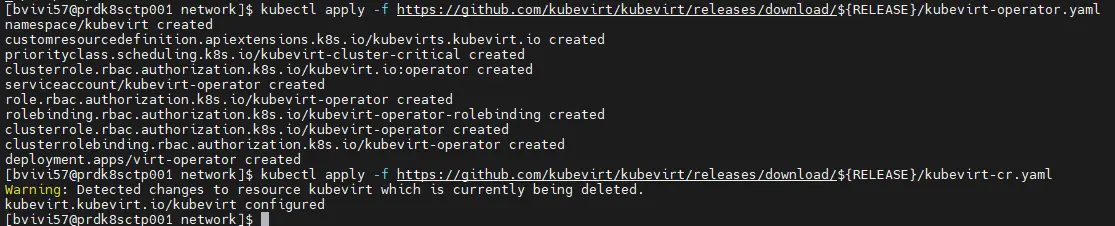
Cliquez sur l'image pour l'agrandir.
Après quelques minutes, on peut vérifier l’état des composants kubevirt avec la commande:
kubectl get all -n kubevirt
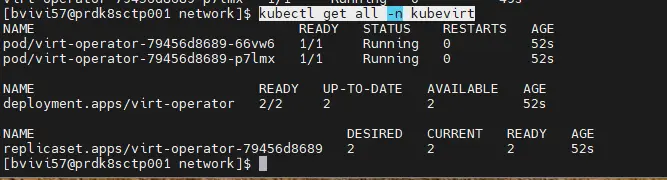
Cliquez sur l'image pour l'agrandir.
Si on résume ce qui a été déployé, on n’arrive à ce tableau:
| Composant | Rôle |
|---|---|
| KubeVirt Operator | Gère l’installation et les mises à jour de KubeVirt |
| Virt-API | Fournit l’API REST pour gérer les VMs |
| Virt-Controller | Gère la création, planification et migration des VMs |
| Virt-Handler | S’exécute sur chaque nœud pour interagir avec QEMU/KVM |
| Virt-Launcher | Conteneur qui exécute la VM via QEMU/KVM dans un pod |
À noter qu’on n’a pas cherché à customiser le namespace hébergeant les ressources. On utilise celui par défaut proposé avec l’installation: kubevirt.
Installation de la CLI
Vous commencez peut-être à en avoir l’habitude si vous avez déjà suivi certains de mes articles comme celui consacré à Velero ou si vous êtes déjà coutumier de l’écosystème K8S, mais il va falloir récupérer un binaire supplémentaire pour pouvoir tirer partir de toutes les fonctionnalités de KubeVirt.
Celui-ci se nomme virtctl et se télécharge directement via son repo.
Il faut retenir une version identique à la version de kubevirt déployée et compatible avec l’OS client utilisé pour piloter son cluster.
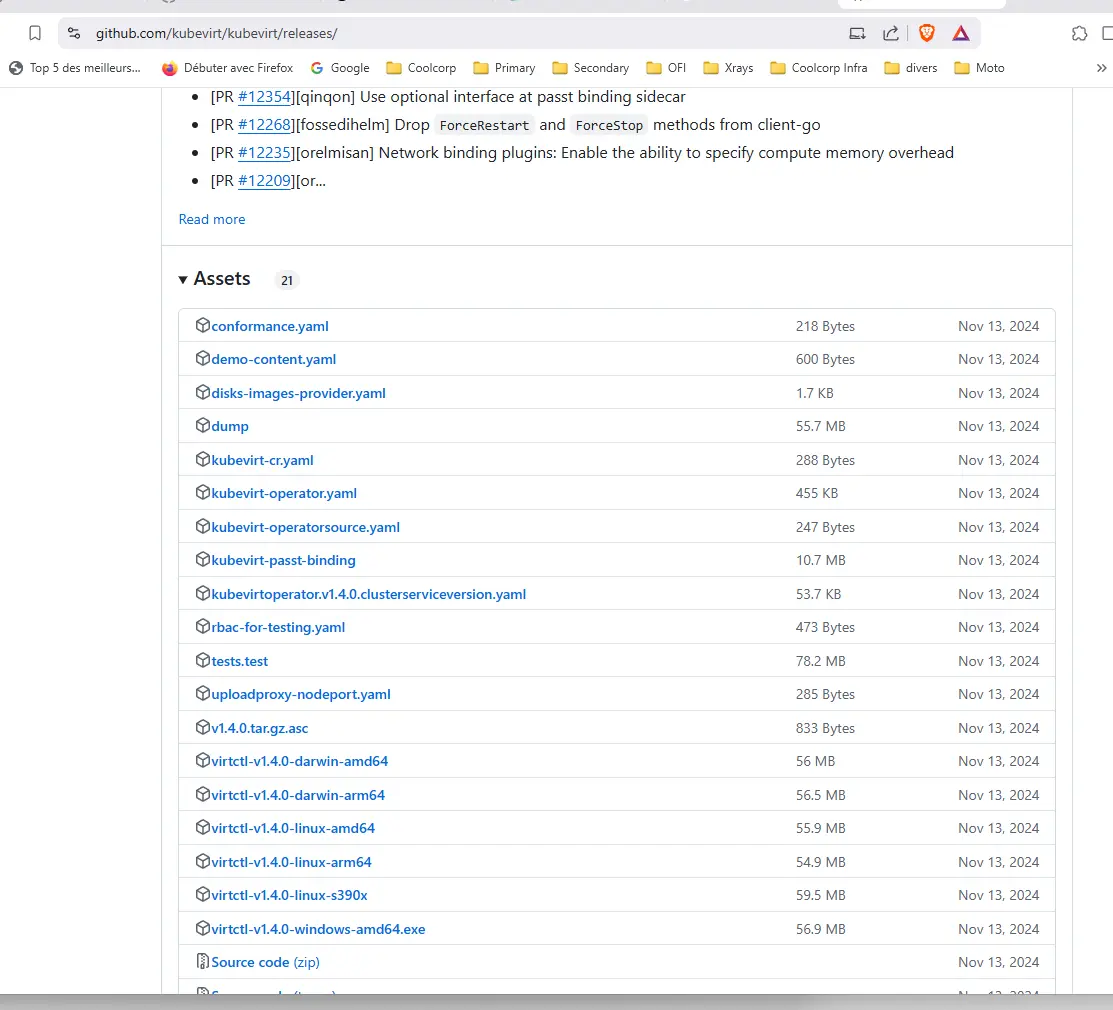
Cliquez sur l'image pour l'agrandir.
virtctl s’appuie classiquement sur votre fichier de config d’accès utilisé par kubectl. N’hésitez pas à parcourir mon sujet sur les principes d'administration de k8S si vous souhaitez plus d’informations à ce niveau.
Récupérez le binaire souhaité et placez-le dans votre path d’exécution propre à votre OS pour pouvoir l’appeler depuis n’importe quel emplacement.
Par exemple sous Linux:
wget https://github.com/kubevirt/kubevirt/releases/download/v1.4.0/virtctl-v1.4.0-linux-amd64
mv virtctl-v1.4.0-linux-amd64 virtctl
chmod +x virtctl
sudo mv virtctl /usr/local/bin/
Vous pouvez ensuite tester le tout avec la commande:
virtctl version

Cliquez sur l'image pour l'agrandir.
Déploiement des addons réseau
Comme expliqué dans l’article précédent , il va être nécessaire de déployer d’autres CNI pour offrir davantage de services réseau aux pod et aux VMs.
- Multus: pour autoriser plusieurs interfaces réseau.
- Macvtap: pour autoriser le mappage d’une interface réseau physique directement au sein d’une VMs.
Chacun de ces CNI pourrait s’installer individuellement et se paramétrer de son côté.
Ce n’est pas ce que l’on va retenir, car le projet KubeVirt propose un opérateur complémentaire à déployer sur le cluster simplifiant l’installation de ces CNI additionnels.
Le repo du projet est celui-ci.
L’installation de l’opérateur passe par les trois commandes suivantes:
kubectl apply -f https://github.com/kubevirt/cluster-network-addons-operator/releases/download/v0.98.1/namespace.yaml
kubectl apply -f https://github.com/kubevirt/cluster-network-addons-operator/releases/download/v0.98.1/network-addons-config.crd.yaml
kubectl apply -f https://github.com/kubevirt/cluster-network-addons-operator/releases/download/v0.98.1/operator.yaml
Après ces actions, on dispose d’un namespace cluster-network-addons et l’accès à un nouvel objet K8S NetworkAddonsConfig déclaré dans la branche networkaddonsoperator.network.kubevirt.io/v1.
On va capitaliser sur ce nouvel objet pour créer le fichier 01-networkaddonconfig-macvtap-multus.yml dont le contenu est le suivant:
---
apiVersion: networkaddonsoperator.network.kubevirt.io/v1
kind: NetworkAddonsConfig
metadata:
name: cluster
spec:
imagePullPolicy: IfNotPresent
macvtap: {}
multus: {}
En l’appliquant avec la commande kubectl apply -f 01-networkaddonconfig-macvtap-multus.yml, on va automatiquement déployer macvtap et multus. Avec cette méthode on peut ajouter autant de plugin réseau que supporté par l’opérateur (liste visible dans le repo github).

Cliquez sur l'image pour l'agrandir.
On se contentera des deux dont on n’a besoin. D’ailleurs si on liste les pods du namespace cluster-network-addons on retrouve des éléments propres à nos deux CNI.
kubectl get pod -n cluster-network-addons

Cliquez sur l'image pour l'agrandir.
Si on veut s’assurer qu’on dispose bien de nouveaux CNI on peut également lister le contenu du répertoire /etc/cni/net.d/.
Vous devriez vous retrouver avec une arborescence de ce genre:

Cliquez sur l'image pour l'agrandir.
À noter qu’on ne trouve pas de fichier associé à macvtap, mais c’est normal celui-ci n’en utilise pas à ce niveau et seul cilium et multus sont présent.
configuration de macvtap
Justement macvtap nécessite une configuration spécifique qu’on va devoir lui apporter sous forme d’un configmap (cm).
Ce configmap (macvtap-deviceplugin-config) existe par défaut dans le namespace cluster-network-addons. Il est créé par l’opérateur au déploiement de macvtap.
Le problème c’est que ce configmap autorise macvtap à utiliser n’importe lesquelles des cartes réseau présentes sur le serveur (on peut lire son contenu avec la commande kubectl get cm macvtap-deviceplugin-config -n cluster-network-addons -o yaml).
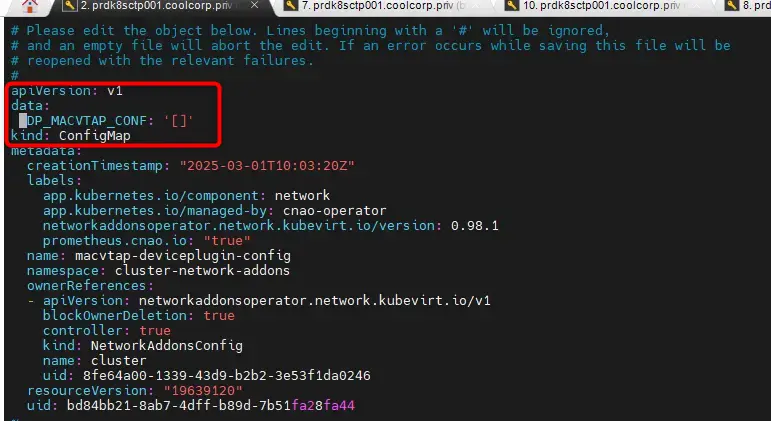
Cliquez sur l'image pour l'agrandir.
Ce n’est pas ce qu’on veut. Si vous reprenez le schéma d’architecture cible en début d’article, on ne veut exploiter que:
- enp8s0 : interface de base pour l’accès au lan
- enp8s0.6 : interface taguée avec le VLAN6 pour l’accès à la zone VLAN_WEB
- enp13s0f3 : interface de base pour l’accès à la DMZ
Le configmap associé doit donc être celui-ci (contenu du fichier 02-cm-macvtap-default.yml):
kind: ConfigMap
apiVersion: v1
metadata:
name: macvtap-deviceplugin-config
namespace: cluster-network-addons
labels:
app.kubernetes.io/component: network
app.kubernetes.io/managed-by: cnao-operator
immutable: true
data:
DP_MACVTAP_CONF: |
[
{
"name": "enp8s0",
"lowerDevice": "enp8s0",
"mode": "bridge",
"capacity": 30
},
{
"name": "enp8s0.6",
"lowerDevice": "enp8s0.6",
"mode": "bridge",
"capacity": 30
},
{
"name": "enp13s0f3",
"lowerDevice": "enp13s0f3",
"mode": "bridge",
"capacity": 30
}
]
À chaque section correspond une interface, avec le mode à utiliser, bridge, et le nombre de sous interfaces virtuelles autorisées, soit 30 dans mon exemple.
Le problème c’est que ce configmap est sans cesse écrasé par la conf par défaut de l’opérateur. Si on le modifie, il ne sera appliqué que quelques secondes avant de revenir à ses valeurs d’origine.
Je n’ai pas réussi à trouver comment changer ce comportement via l’opérateur, je me suis donc permis un petit contournement en positionnant dans ma conf, l’option immutable: true.
Avec ce paramètre dans le yaml, j’interdis à K8S de venir modifier ce configmap. Il ne reste donc plus qu’à supprimer le configmap par défaut et dans la foulée le recréer avec ma configuration.
kubectl delete cm macvtap-deviceplugin-config -n cluster-network-addons
kubectl apply -f 02-cm-macvtap-default.yml
Le faite qu’il soit immutable, l’opérateur ne pourra plus le modifier de lui-même.Ce n’est pas vraiment l’idéal, mais c’est une astuce qui fonctionne.
D’ailleurs si on relance le déploiement du CNI macvtap avec la commande:
kubectl rollout restart daemonset/macvtap-cni -n cluster-network-addons

Cliquez sur l'image pour l'agrandir.
Puis qu’on interroge les logs du pod associés:
kubectl logs macvtap-cni-bj5d6 -n cluster-network-addons
On s’aperçoit que la conf est bien chargée en ne voyant que nos interfaces au démarrage du contrôleur rattaché au CNI.
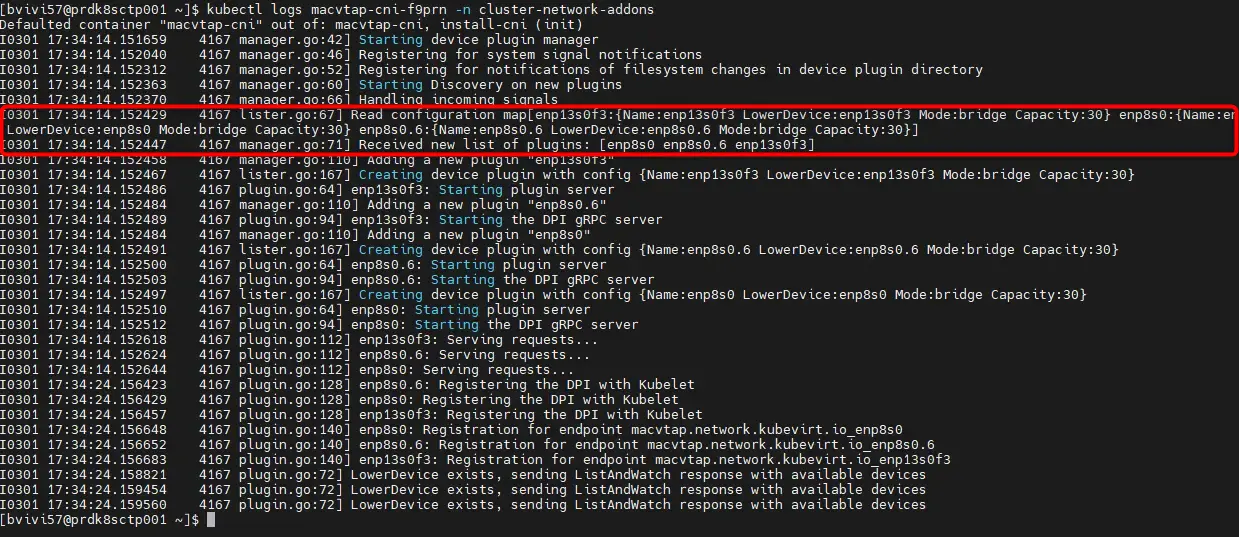
Cliquez sur l'image pour l'agrandir.
Patching de KubeVirt
Avant d’aller plus loin, il reste encore quelques ajustements à faire…
Comme j’ai pu l’expliquer dans l’article précédent, l’écosystème kubevirt n’est pas encore totalement stable, notamment sur l’usage du réseau et l’exploitation de certains addons.
C’est le cas avec macvtap. Si on veut vraiment mapper des interfaces physiques dans nos VMs via ce CNI, il va falloir lever certaines restrictions sur le déploiement de kubevirt.
Nous allons patcher l’installation de kubevirt en autorisant des fonctionnalités qui sont pour l’instant considérées comme en alpha.
Cela passe par l’activation de feature gates.
Voici les commandes à taper:
kubectl patch kubevirt -n kubevirt kubevirt --type=json -p='[{"op": "add", "path": "/spec/configuration/developerConfiguration/featureGates", "value": ["NetworkBindingPlugins"]}]'
kubectl patch kubevirt -n kubevirt kubevirt --type=json -p='[{"op": "add", "path": "/spec/configuration/developerConfiguration/featureGates/-", "value": "NetworkBindingPlugins"}]'

Cliquez sur l'image pour l'agrandir.
kubectl patch kubevirts -n kubevirt kubevirt --type=json -p='[{
"op": "add",
"path": "/spec/configuration/developerConfiguration/featureGates/-",
"value": "NetworkBindingPlugins"
}]'
kubectl patch kubevirts -n kubevirt kubevirt --type=json -p='[{"op": "add", "path": "/spec/configuration/network", "value": {
"binding": {
"macvtap": {
"domainAttachmentType": "tap"
}
}
}}]'
Ça fait pas mal de choses, mais c’est ce qu’il faut pour que kubevirt redémarre avec la prise en charge de binding de carte.
Il est fort possible que cette partie du tutoriel évolue avec le temps. Fonction du moment où vous lirez ces lignes, ces opérations ne seront peut-être plus nécessaires.
Je vous invite à suivre ce lien pour vous permettre de rester informé sur l’évolution de la prise en charge de macvtap et de binding d’interface par kubevirt.
Containerized-Data-Importer (CDI)
KubeVirt permet de s’appuyer sur certains objets existants de Kubernetes pour fournir des services aux VMs. C’est le cas du stockage. KubeVirt utilise les principes de pv (persistent volume) et pvc (persistent volume claim) pour proposer des disques aux VMs ou d’autres sources de données.
Pour simplifier cette intégration, il est conseillé d’installer l’addon Containerized-Data-Importer (CDI). Ce n’est pas obligatoire, mais CDI permet de générer des pvc directement à partir d’image de VMs, de volumes conteneurisés existants ou d’ISOs.
On utilisera ces capacités plus tard pour déployer nos VMs.
L’installation passe par les commandes suivantes:
- On fixe la version à télécharger via une variable
export TAG=$(curl -s -w %{redirect_url} https://github.com/kubevirt/containerized-data-importer/releases/latest)
export VERSION=$(echo ${TAG##*/})
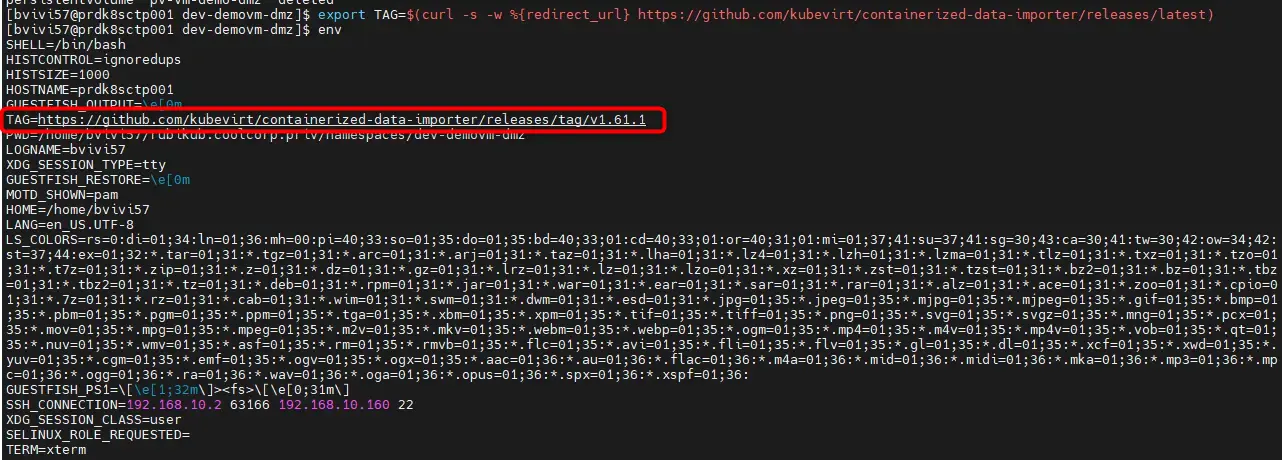
Cliquez sur l'image pour l'agrandir.
- Puis on installe l’opérateur et les nouvelles ressources propres à CDI:
kubectl create -f https://github.com/kubevirt/containerized-data-importer/releases/download/$VERSION/cdi-operator.yaml
kubectl create -f https://github.com/kubevirt/containerized-data-importer/releases/download/$VERSION/cdi-cr.yaml

Cliquez sur l'image pour l'agrandir.
On peut vérifier que le déploiement a réussi avec la commande:
kubectl get all -n cdi
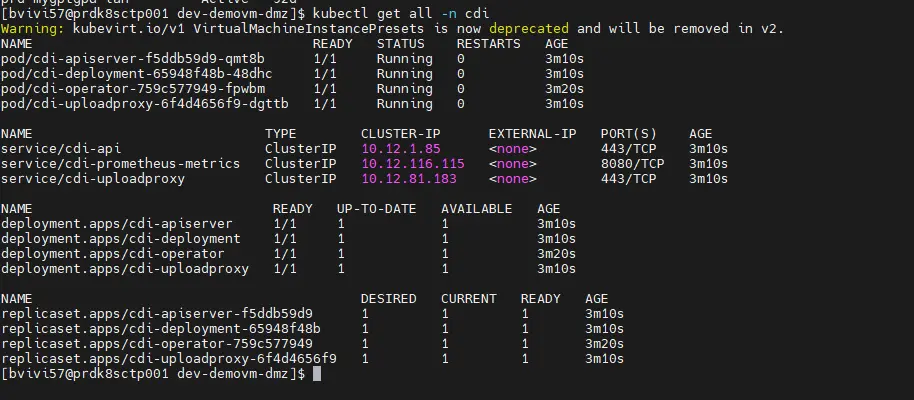
Cliquez sur l'image pour l'agrandir.
On observe l’utilisation d’un namespace spécifique cdi.
Plus tard, nous utiliserons Containerized-Data-Importer pour copier une image ISO au sein d’un pvc. Pour cela, CDI expose un service de proxy d’upload qu’il faut rendre accessible à l’extérieur du cluster.
On doit donc créer un ingress. En l’occurrence, je vais me reposer sur l’ingress controleur traefik déployé sur le node K8S. Je ne reviendrais pas spécifiquement sur ce sujet, vous trouverez des explications ici.
Avant de créer l’ingress, j’ai besoin de générer un certificat. Là aussi je ne rentrerais pas dans le détail, il s’agit simplement de créer une clef privée, faire un CSR (Certifiat Signing Request) pour obtenir ensuite un certificat auprès d’une PKI.
Pour le besoin de ce tutoriel, je génère une clef et un CSR pour l’URL cdi.coolcorp.priv:
openssl req -new -nodes -sha256 -keyout cdi.coolcorp.priv.key -out cdi.coolcorp.priv.csr -newkey rsa:4096 -subj "/C=FR/ST=Ile-de-France/L=Paris/O=COOLCORP/OU=Infrastructure/CN=cdi.coolcorp.priv" -reqexts SAN -config <(printf "[req]\ndistinguished_name = req_distinguished_name\n[req_distinguished_name]\n[SAN]\nsubjectAltName=DNS:cdi.coolcorp.priv")
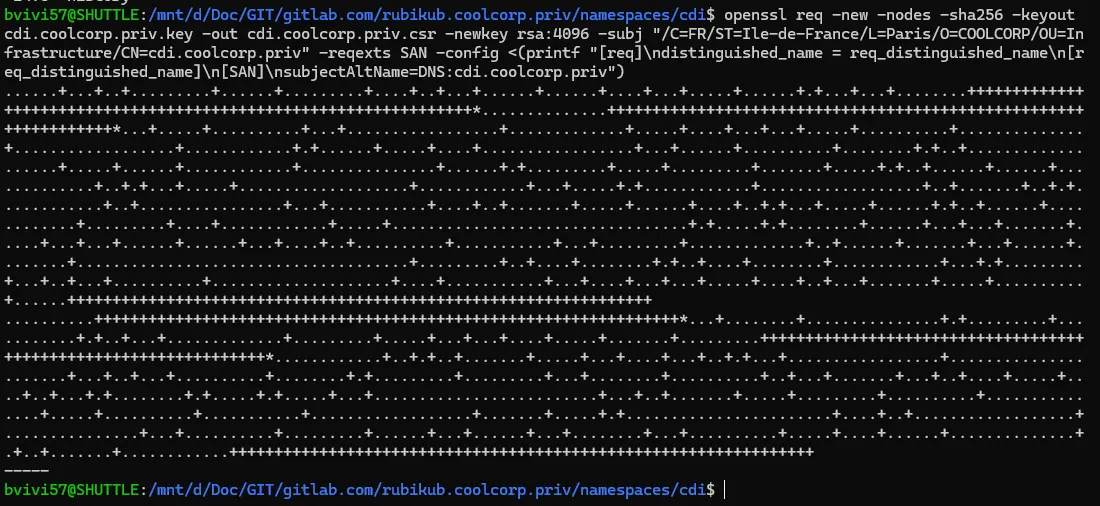
Cliquez sur l'image pour l'agrandir.
Je présente le CSR à ma PKI Interne (une PKI Windows, j’utilise donc l’exe certreq et mon template custom spécifique au site web).
certreq -attrib "CertificateTemplate:TPL-SRV-WEB-DEFAULT" -submit .\cdi.coolcorp.priv.csr
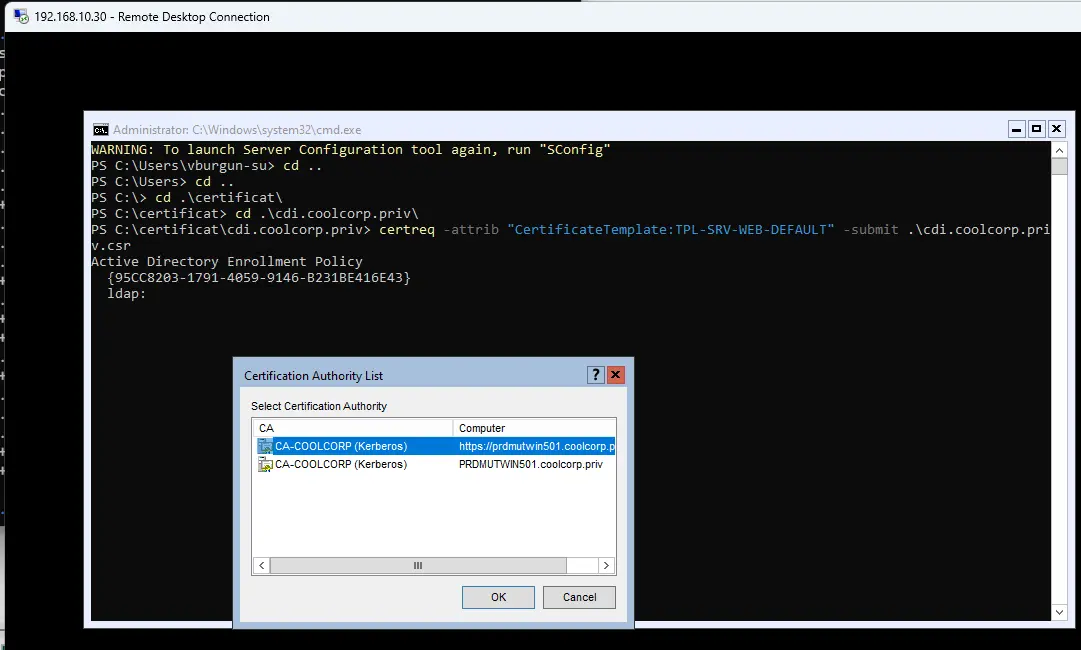
Cliquez sur l'image pour l'agrandir.
Une fois le certificat et la clef rapatriés dans un même dossier, il suffit de créer le secret chargé de stocker l’ensemble:
kubectl create secret tls sec-cdi-cert --cert=cdi.coolcorp.priv.cer --key=cdi.coolcorp.priv.key -n cdi

Cliquez sur l'image pour l'agrandir.
On liste les services déployés par l’installation de CDI pour identifier celui qu’on va devoir rattacher à notre ingress.
kubectl get svc -n cdi

Cliquez sur l'image pour l'agrandir.
Il s’agit du service cdi-uploadproxy sur le port 443.
Voici donc l’ingress déclaré dans un fichier 01-ing-cdi-proxy.yml:
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-cdi-proxy
namespace: cdi
labels:
environment: prd
network: lan
application: cdi
tier: proxy
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- cdi.coolcorp.priv
secretName: sec-cdi-cert
rules:
- host: cdi.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: cdi-uploadproxy
port:
number: 443
On n’y retrouve le secret sec-cdi-cert pour le certificat et on renvoit bien l’URL cdi.coolcorp.priv vers le service cdi-uploadproxy.
Il ne reste plus qu’a s’assurer d’avoir une entrée DNS qui correspond bien a traefik, donc au node kubernetes.
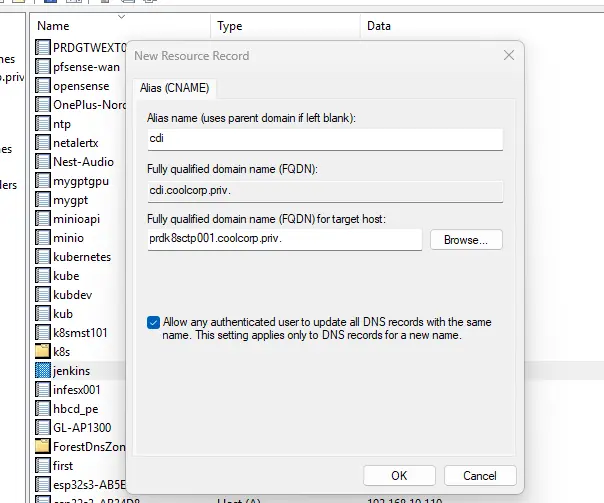
Cliquez sur l'image pour l'agrandir.
On peut appliquer le fichier
kubectl apply -f .\01-ing-cdi-proxy.yml

Cliquez sur l'image pour l'agrandir.
Pour terminer, il reste à créer une storage class (sc).
En effet, nous aurons par la suite à traiter des ISOs, notamment pour l’installation d’OS. L’objectif est d’utiliser CDI pour provisionner des pvc (et donc des volumes) à partir d’une ISO donnée en input.
On va donc dédier une sc pour la création automatique de ces pvc. Si vous n’êtes pas familier avec les sc, pv et pvc, je vous invite à faire un tour ici et ici.
Voici la sc décrite dans un yaml 04-sc-local-storage-nfs-iso.yml:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-local-storage-nfs-iso
provisioner: nfs.csi.k8s.io
parameters:
# Le serveur NFS
server: 192.168.10.152
# L'export contenant la racine des dossiers ISO
share: /Volume1/nfsshare/tools/pv-iso/
reclaimPolicy: Retain
volumeBindingMode: Immediate
Comme vous le voyez, il va s’agir d’exploiter le CSI (Container Storage Interface) NFS et un export NFS sur mon NAS dédié à l’hébergement de ces pvc contenant les ISOs.
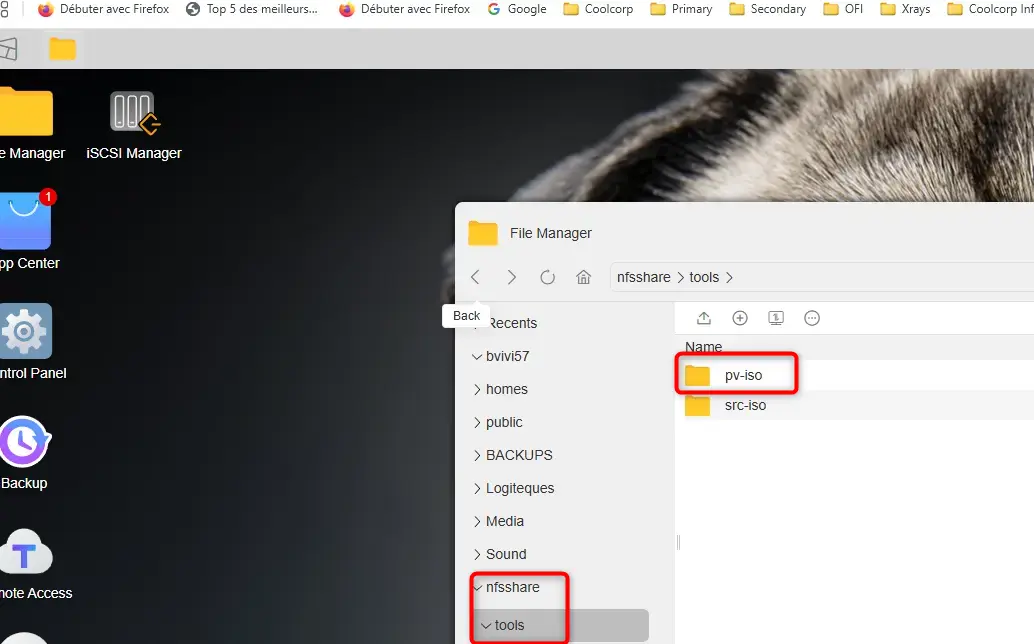
Cliquez sur l'image pour l'agrandir.
On applique la sc:
kubectl apply -f 04-sc-local-storage-nfs-iso.yml

Cliquez sur l'image pour l'agrandir.
On peut vérifier que celle-ci est bien déclarée:
kubectl get sc

Cliquez sur l'image pour l'agrandir.
Conclusion
C’est la fin de cette seconde partie consacrée à KubeVirt. Après les prérequis vus dans le précédent article, on n’a désormais pu déployer KubeVirt et tous les addons nécessaires à notre ambition de départ.
Il reste maintenant à capitaliser sur tous ces composants pour enfin déployer les VMs: le troisième article est disponible ici !