Etape 1: définition de l'architecture
Introduction
L’article suivant a pour objectif de présenter les bases retenues pour l’architecture Kubernetes (ou K8S/KUB) servant de tutorial et d'herbergement pour mon besoin personnel. Plusieurs concepts propres à K8S seront exposés, mais pas forcément détaillés ici. Il est donc possible que certains principes paraissent confus si vous n’êtes pas déjà familiarisé avec l’écosystème Kubernetes. Ce n’est pas forcement gênant à ce stade.
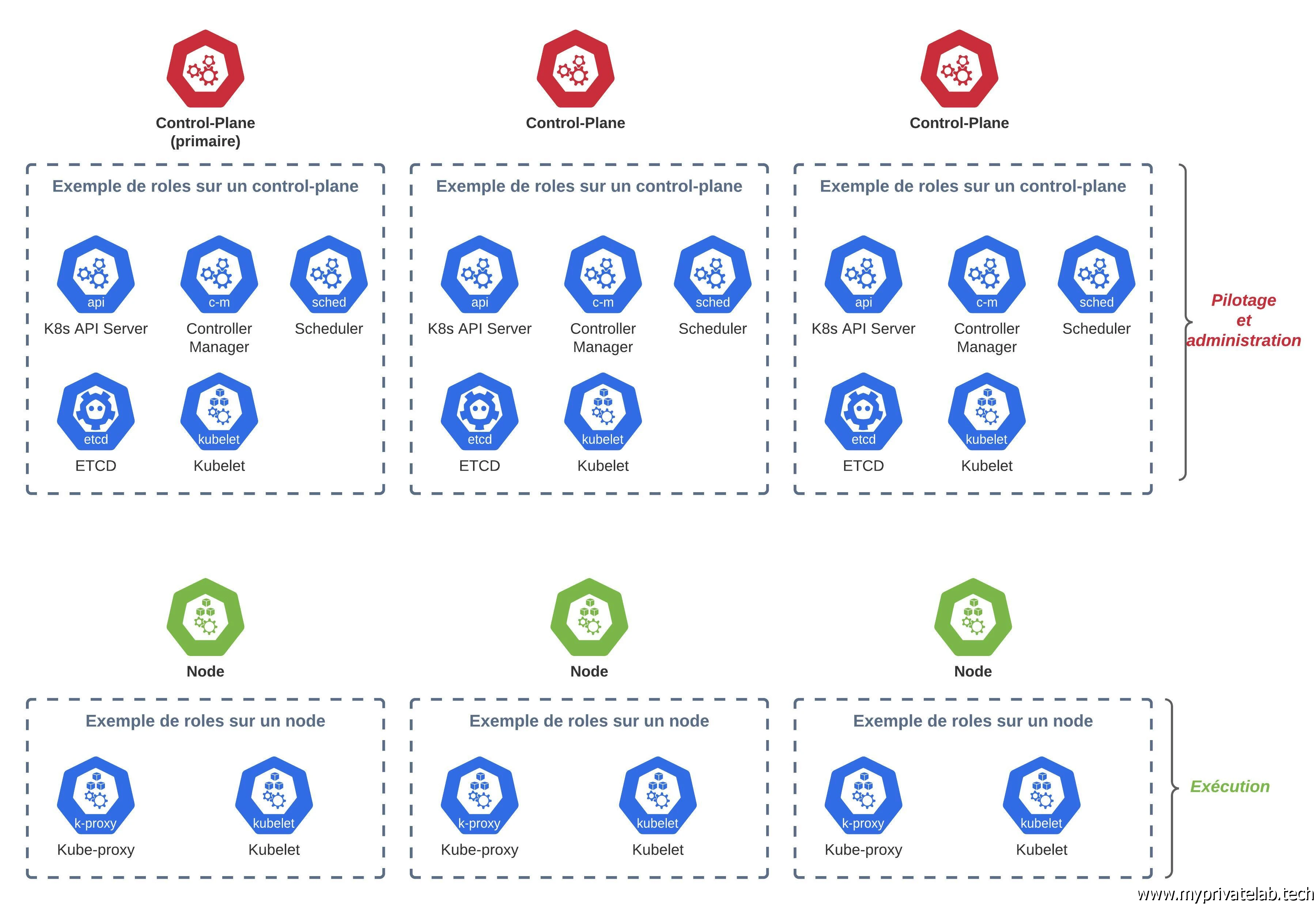
Ce qu’il est important de savoir, c’est que Kubernetes repose sur un principe de modularité. Un cluster Kubernetes est composé de plusieurs serveurs, virtuel et/ou physique sur lesquelles s’exécutent des briques fonctionnelles chargées d’un rôle spécifique.
Certaines de ces briques peuvent être redondées, et sont plus moins critiques pour le bon fonctionnement du cluster. Elles peuvent également être customisées ou enrichies fonction des besoins.
Cliquez sur l'image pour l'agrandir.
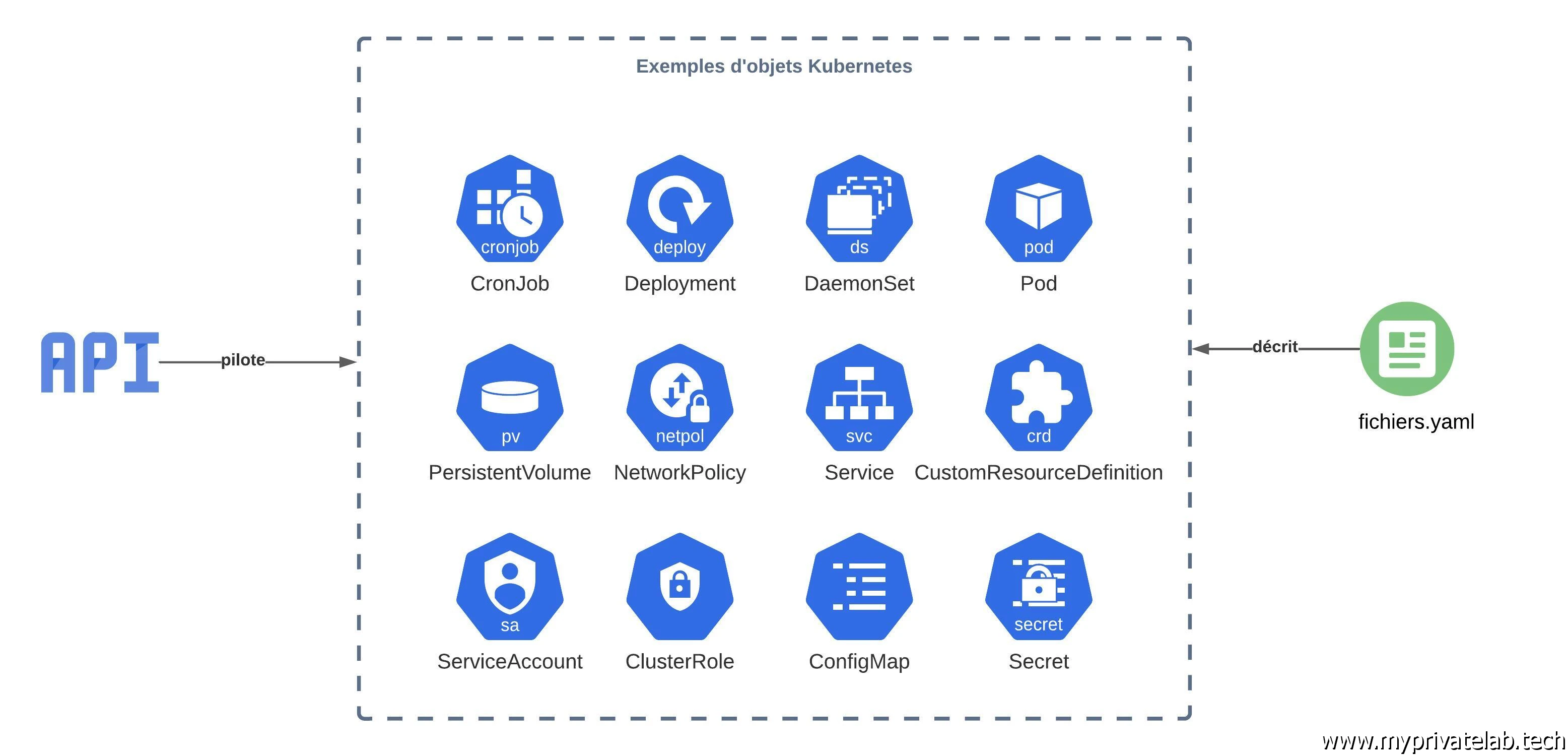
Interagir avec un cluster Kubernetes c’est avant tout interagir avec une API. Cette API dispose de différentes branches dans lesquelles va se retrouver la définition de différents objets.
À chaque objet correspond un usage, et un certain nombre de propriétés, obligatoires et/ou facultatives.
C’est la combinaison de tous ces objets, manipulables à travers l’API qui va vous permettre d’exécuter vos applications.
Vous pourrez ainsi décrire l’état dans lequel vous souhaitez que vos assets se retrouvent et Kubernetes aura à cœur de toujours faire en sorte d’avoir un état d’exécution correspondant à vos exigences.
Le besoin d’une nomenclature
Kubernetes est un écosystème pouvant rapidement devenir complexe. L’exécution d’une application sous K8S est attachée à tout un ensemble d’objets décrit dans une API. Ces objets ont tous un rôle spécifique (la gestion du déploiement, la fourniture d’un espace de stockage, l’exposition d’un service…) et peuvent être dépendants les uns des autres pour fonctionner.
Je détaille davantage le rôle et l’usage de ces objets dans des articles dédiés, mais retenez que leurs manipulations se font principalement (mais pas uniquement) à travers des fichiers yaml dans lesquels on va retrouver un ensemble de propriétés décrivant les caractéristiques de l’objet ciblé.
Cliquez sur l'image pour l'agrandir.
Réfléchir à une nomenclature de ces fichiers en début de projet est un bon réflexe. Cela permet de s’y retrouver une fois l’architecture déployée et simplifie les opérations d’automatisation pour ensuite mettre en place de l’industrialisation.
Il n’y a pas de « bonnes ou mauvaises » nomenclatures, il y’a surtout la nomenclature qui vous parle, à vous et votre équipe. L’essentiel est qu’elle soit partagée par tous les intervenants sur le cluster et respectée scrupuleusement.
Me concernant, j’ai choisi la norme suivante:
env-shortname_object-role-net
- env est un trigramme chargé de représenter l’environnement dans lequel évolue l’objet : prd pour production, int pour intégration, dev pour développement.
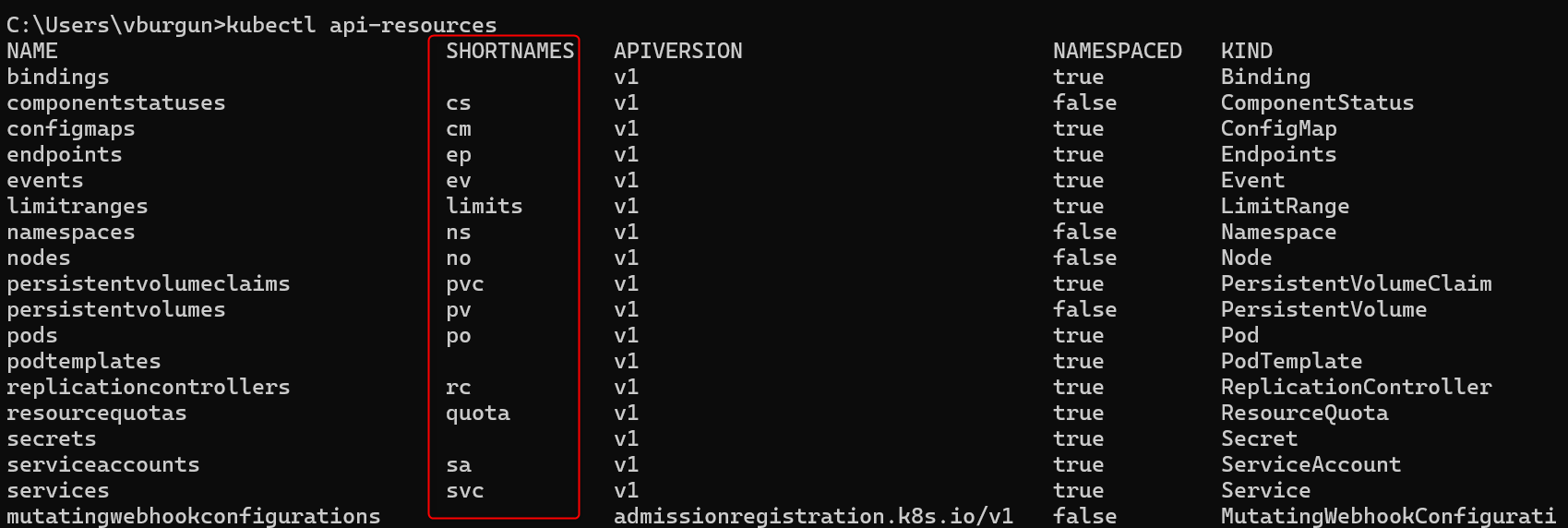
- shortname est la version raccourcie du nom de l’objet telle que définie dans l’API kub. Par exemple, un persistentvolumes, sera référencé sous pv, un deployment est nommé deploy. Ces noms peuvent se retrouver via l’appel à la commande
kubectl api-ressourcesur un cluster actif. - role permet de décrire davantage ce à quoi va servir l’objet. Dans le cas où la description est inutile ou inadaptée, j’emploie le terme « default »
- net représente la zone réseau associée à l’objet. Dans mon cas, soit lan pour une application interne, dmz pour une application exposée sur le web et na pour non applicable.
Cliquez sur l'image pour l'agrandir.
Encore une fois, libre à chacun de choisir la nomenclature de son choix, l’important est d’en adopter une et de s’y tenir.
De la même manière, le nommage des nodes du cluster est important et doit correspondre à une nomenclature définie par avance. Dans mon cas:
envk8srol5YX
- env est un trigramme représentant mon environnement, prd pour la production, int pour l’intégration et dev pour le développement.
- k8s est le trigramme indiquant que cette VM fait partie d’un cluster Kubernetes.
- rol est un trigramme associé au rôle du serveur dans le cluster, soit ctp pour un control plane ou nod pour un nœud d’exécution classique. Ce point sera expliqué plus bas dans l’article.
- 5 est associé à un environnement virtuel
- Y prend 0 s’il s’agit d’une VM dans le LAN, 1 si c’est une vm en DMZ
- X est simplement le numéro du serveur
Schéma d’architecture K8S et principes
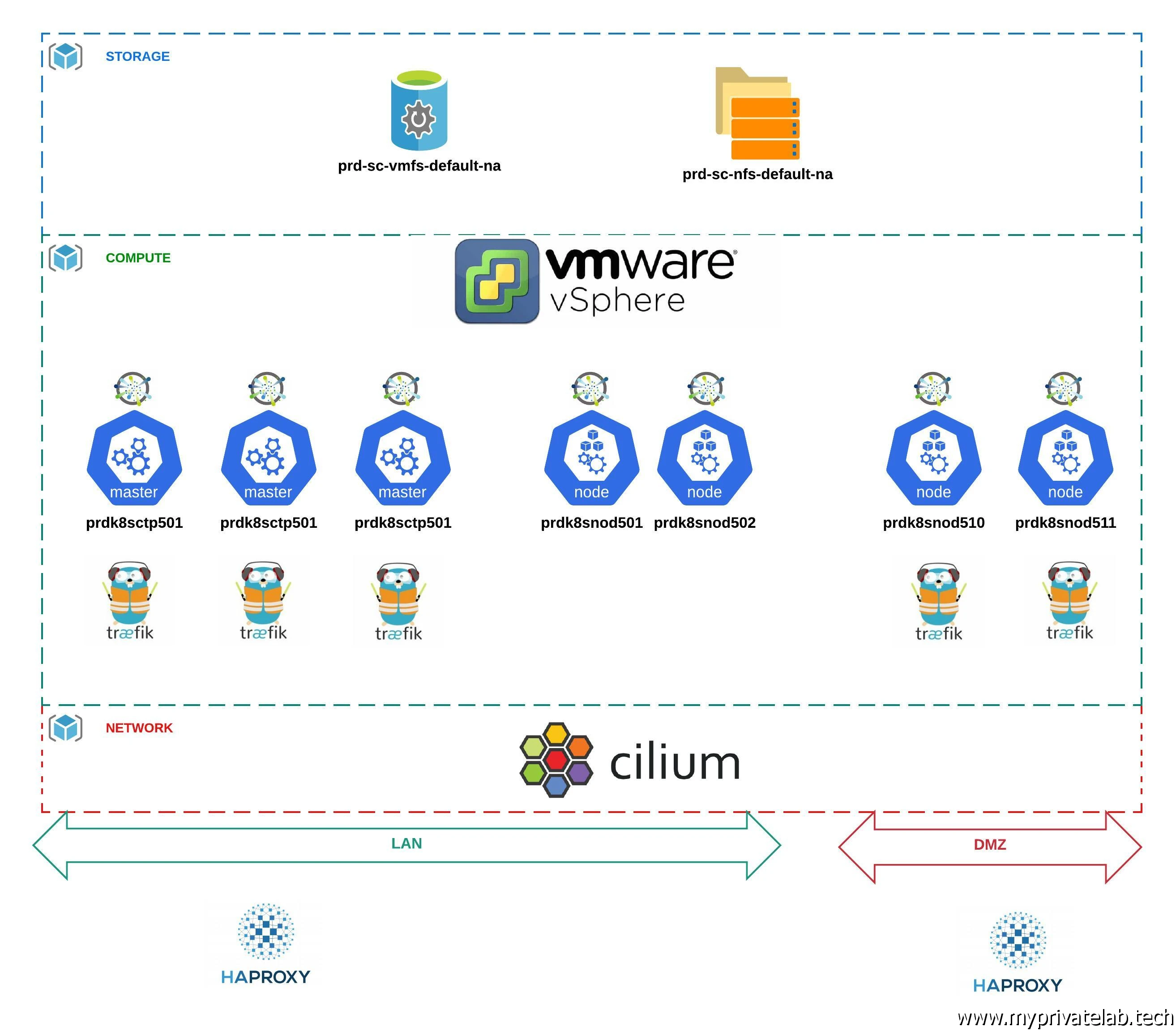
Avant de se lancer tête baissée dans l’installation du cluster, il est bon de définir sur papier la cible à déployer.
Un bon schéma valant mieux qu’un grand discours, voici une rapide présentation de mon cluster.
Cliquez sur l'image pour l'agrandir.
Traitement de la couche stockage
Dans l’univers de la conteneurisation, il est usage de minimiser le besoin de stockage persistant. Un conteneur doit pouvoir s’arrêter et redémarrer sans devoir dépendre de données qui lui sont directement rattachées. Or, ce mode de fonctionnement n’est pas compatible avec tous les usages. Une base de données conteneurisée par exemple aura besoin de retrouver ses bases. C’est pourquoi dans K8S, on sépare la couche d’exécution de la couche de storage. Les deux se traitent via des objets différents et c’est la combinaison des deux qui permettent de concevoir une application. On va notamment parler de persistentvolumes (pv) pour décrire les objets en charge de l’hébergement des données.
Pour mon besoin, deux types de volumes vont être mis en place à travers ce que l’on appelle des storageclasses (sc). Ces objets permettent de définir des espaces de stockage proposant certaines caractéristiques (performance, block ou filer…). Le cluster pourra, fonction des exigences demandées, provisionner automatiquement un persistant volume dans l’une ou l’autre de ces storage classe. Ce provisionnement se fera à travers un troisième objet, appelé persistentvolumeclaims (pvc). Dans la logique, un utilisateur décrira son besoin de stockage dans un pvc, celui-ci sera évalué par le cluster qui proposera en retour un pv issu de la sc correspondant aux caractéristiques attendues.
L’idée n’est pas de rentrer dans le détail ici, mais voici un schéma issu de weng-albert.medium.com qui décrit la logique.
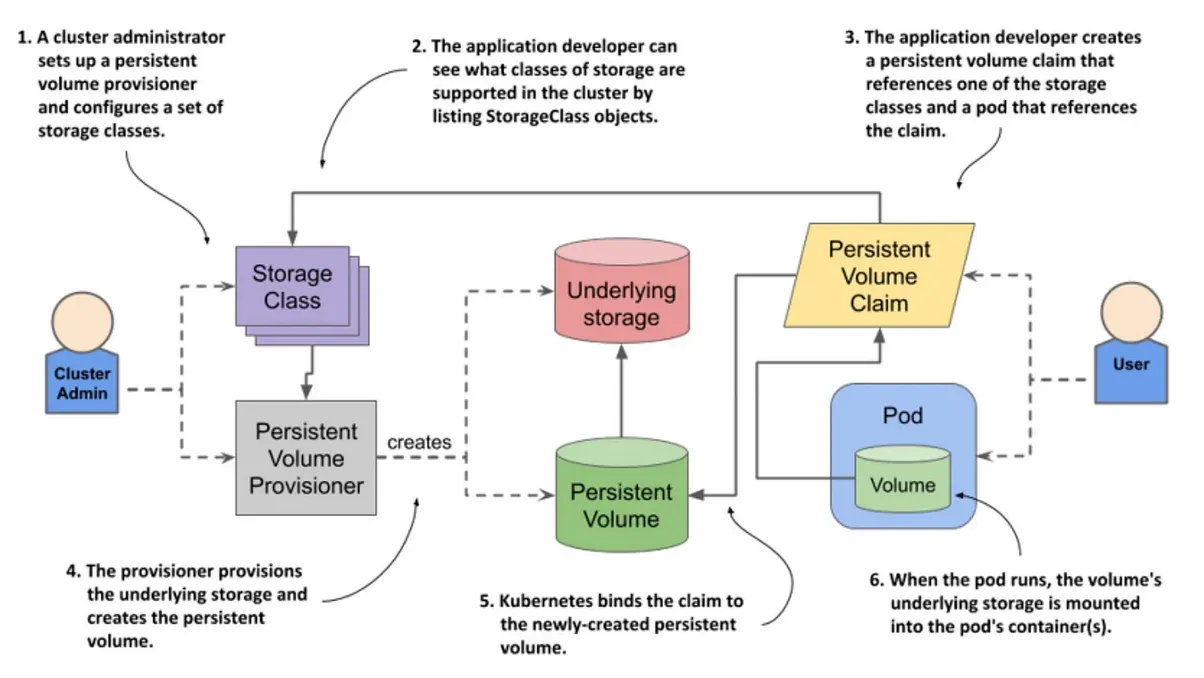
Cliquez sur l'image pour l'agrandir.
Une sc va la plupart du temps s’appuyer sur un CSI pour Container Storage Interface. Une sorte de driver proposé par un tiers et conforme aux normes imposées par le projet kubernetes. Celui-ci va permettre à un cluster de piloter un fournisseur de stockage, comme une solution cloud, une baie spécifique ou un écosystème tiers disposant d’une solution de stockage. C’est un concept extrêmement puissant, puisque sans avoir à se soucier de la solution de stockage finale, la combinaison storage class + CSI va permettre de proposer au sein du cluster, et de manière totalement transparente plusieurs possibilités d’hébergement des données persistantes. D’un côté, les équipes d’infrastructure peuvent choisir le fournisseur de leur choix, dès lors que celui-ci propose un driver CSI, et les développeurs pourront retenir la class de storage qui correspond à leur besoin (ou qu’on leur autorise) sans se soucier du reste. Si le fournisseur de stockage venait à changer, c’est un autre driver CSI qui serait déclaré dans la sc sans impacter les fichiers de déploiement.
Voici donc les deux sc proposées:
- Une storage class prd-sc-vmfs-default-na : cette sc va s’appuyer sur le driver CSI de VMware pour permettre la création de pv directement au sein d’un datastore VMFS . On va pouvoir fournir un stockage performant, orienté block, accessible à une cible à la fois en lecture/écriture. Dans mon cas, c’est typiquement cette sc que je vais utiliser pour des bases de données. Mon cluster s’exécutant sous forme de VM sur une infra VMware, un pv exploitant cette sc se retrouvera sous forme d’un disque mappé à la VM qui exécutera la charge associée à ce volume. Si pour une raison ou pour un autre, le contexte d’exécution change de nœud, le disque sera automatiquement demappé puis remappé à la nouvelle VM associée au nœud retenu.
- Une storage class prd-sc-nfs-default-na : cette sc va s’appuyer sur un NAS proposant un espace NFS. Les pv issus de cette sc pourront être exploités en lecture/écriture par plusieurs cibles à la fois. Dans mon cas, je vais m’en servir pour le contenu statique de mon site ou d’autre besoin de partage entre plusieurs assets.
Traitement de la couche network
Les binaires de bases de K8S sont centrés sur l’orchestration des conteneurs. Pour les fonctionnalités tierces comme le moteur d’exécution des conteneurs, leur stockage ou leur communication entre eux, Kubernetes laisse le choix d’adopter les technologies de son choix. Ces briques annexes peuvent être confiées à des solutions tiers à partir du moment où elles respectent un certain standard et se plient à des normes communes. Concernant le réseau, Kubernetes propose la spécification CNI pour Container Network Interface. Différentes solutions ou “plugins” se basent sur CNI pour traiter la couche réseau au sein d’un cluster K8S. À chacun de choisir le plug-in qu’il souhaite fonction des caractéristiques qu’il propose : protocole de routage pris en charge, possibilité d’exploiter des politiques d’accès…
Les modes évoluent, et depuis que je manipule Kubernetes, j’ai déjà changé 3x de solution CNI. Au moment d’écrire ces lignes, j’ai retenu Cilium qui semble avoir les faveurs du marché…d’ailleurs la société derrière ce projet opensource a été acquise fin 2023 par Cisco… Le succès de Cilium semble en grande partie lié à son implémentation de eBPF (Extended Berkeley Packet Filter) , une technologie lancée dans la branche 4.x du Kernel Linux. Je suis loin de comprendre exactement ce qui se cache derrière, mais concernant Cilium, cela lui apporte des capacités d’observabilité très avancées sur les flux réseau qui circulent au sein d’un cluster Kubernetes.
Autre débat qu’on peut retrouver au sein de la communauté K8S : faut -il utiliser des nœuds en DMZ ou doit-on dédier un cluster complet aux zones réseaux exposées.
Pour moi il n’y a pas de bonnes ou de mauvaises réponses. Comme toujours tout dépend des contraintes que vous pourriez avoir, notamment au niveau de la cybersécurité.
De base, Kubernetes est en dans une logique « tout passe », mais de nombreux mécanismes existent pour isoler des ressources entre elles et segmenter son cluster en zones spécifiques et étanches.
Me concernant, je n’ai pas le luxe de créer davantage de clusters, et vais plutôt m’appuyer sur ces mécanismes de protection pour m’assurer qu’un asset en DMZ ne puisse pas discuter librement avec un asset du LAN en profitant du réseau interne au cluster.
Traitement de la couche compute
En l’état, c’est un cluster VMware avec plusieurs serveurs ESXi qui va servir à héberger mon cluster. Le détail de mon installation est disponible ici
Il est possible qu’avec le temps, je bascule sur une autre solution en raison des problématiques survenues suite au rachat de VMware par Broadcom.
Quoi qu’il en soit, je resterais certainement sur des PhotonOS, peu importe qu’ils s’exécutent sur des nœud vmware, proxmox ou autre. Vous êtes bien entendu libre de choisir l’OS de votre choix. Cela n’aura finalement peu d’importance, car dans mon cas, j’ai décidé de retenir une installation dite « vanilla » grâce à l’outil Kubeadm.
Il faut savoir que Kubernetes reste une solution modulaire dont chaque brique est disponible « à l’unité ». C’est à vous de les assembler et éventuellement de les modifier pour construire votre cluster. C’est un travail qui peut être fastidieux, c’est pourquoi il existe des « distribution » kubernetes qui s’occuperont pour vous de déployer tout le nécessaire sur vos nœuds, virtuel ou physique. Ces « suites » sont proposées avec de nombreux outils associés, comme des GUI et des méthodes de mise à jour assistés. On peut citer OpenShift de RedHat, ou Tanzu de VMware. Même s’il existe des variantes gratuites de ces solutions, on n’est plutôt sur des produits onéreux et dédiés aux entreprises. Une installation dite « vanilla » est justement un déploiement qui ne s’appuie pas sur une distribution, mais sur l’appel aux briques de base directement. Heureusement, ce type d’installation a bien évolué avec le temps et est rendu de plus en plus facile, notamment grâce à Kubeadm.
Kubeadm est l’installateur officiel associé au projet K8S. Il va grandement simplifier le déploiement en préconfigurant pour vous toutes les briques nécessaire fonction d’éléments de configuration que vous lui aurez passée en argument. À noter que d’autres méthodes existent, comme kubespray qui s’appuie sur Ansible.
Me concernant, je vais également utiliser Ansible, mais simplement pour me faciliter la construction des fichiers de configuration du cluster. Enfin sachez que l’une des solutions les plus employées pour installer un cluster kubernetes reste l’offre managée des cloud provider. Azure, AWS ou GCP pour ne citer que les plus connues, proposent des clusters sous gestion déployables en quelques clics.
Cela permet de vous concentrer sur vos applications, et non sur l’administration du cluster.
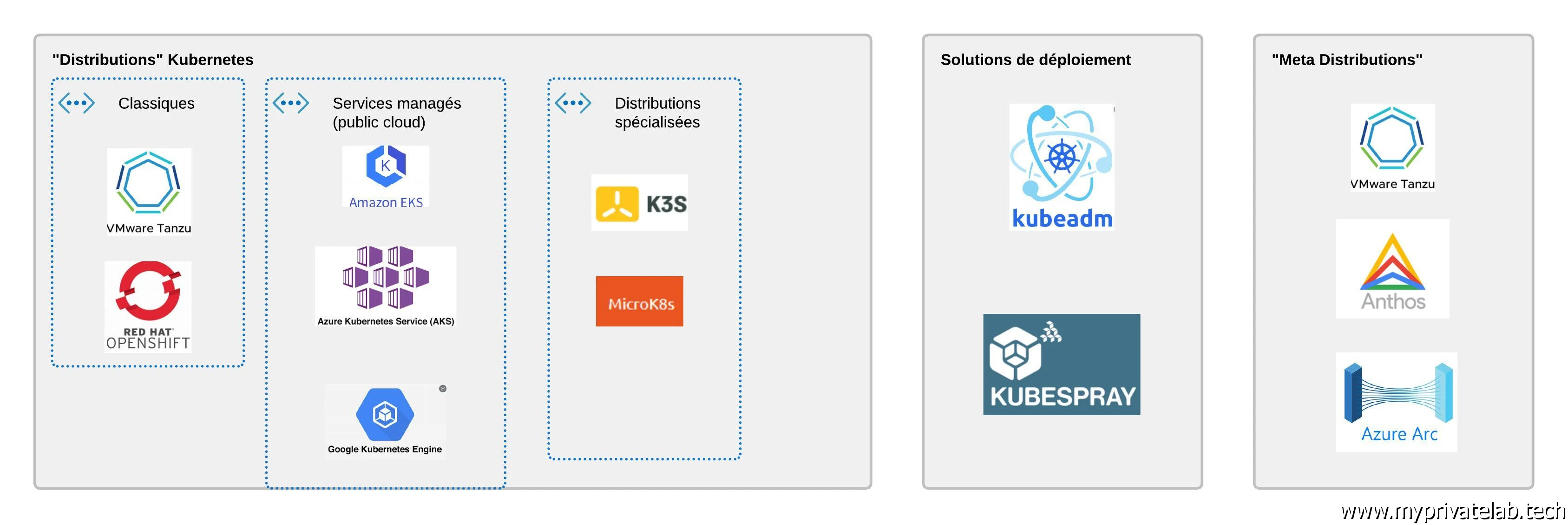
Cliquez sur l'image pour l'agrandir.
Me concernant je préfère rester maitre de mon cluster, quitte à prendre en charge toute la maintenance. C’est aussi pour moi le meilleur choix pour monter en compétence et bien comprendre le fonctionnement de Kubernetes.
Il est important de bien considérer toutes les offres possibles, et même si j’entends beaucoup critiquer le choix d’une installation vanilla en entreprise, ça reste celons moi une solution totalement viable dès lors que vous avez les compétences en interne (ou que vous souhaitez les développer).
Plus globalement, en univers professionnel il n’est pas rare de croiser des mixes d’installation. Un ou plusieurs cluster Onprem, déployés via Kubeadm ou basés sur une distribution dédiée, puis d’autres clusters dans le cloud, pour d’autres besoins et d’autres charges. C’est bien là l’une des plus grandes forces de Kubernetes. Peu importe la plateforme, dès lors qu’elle respecte les standards K8S, il devient possible de concevoir une infrastructure réellement hybride dans laquelle vous pouvez choisir à tout moment d’exécuter vos assets sur telle ou telle plateforme fonction de vos contraintes de performance, de disponibilité, de sécurité et de coût.
Toujours dans un esprit modulaire, le moteur d’exécution des conteneurs est lui aussi au choix de l’utilisateur. C’est particulièrement le cas avec une installation vanilla.
L’univers de la conteurisation a très largement évolué, et si pendant un temps Docker se retrouvait un peu partout, désignant tout et n’importe quoi, ce n’est plus le cas aujourd’hui. En effet, l’industrie s’est mise d’accord sur un standard via l’Open Container Initiative (OCI). Désormais l’exécution d’un conteneur se fait via des runtimes qui respectent ce standard. Le plus connu et d’ailleurs à l’origine de la norme, c’est runc, le composant historiquement utilisé par Docker, « donné » à l’OCI.
runc est vraiment le composant le plus bas niveau. Par-dessus on retrouve souvent containerd qui vient ajouter un environnement de management pilotable le plus souvent à travers une CLI comme celle de Docker.
Mais ce n’est pas fini, Kubernetes propose lui aussi son standard le Container Runtime Interface (CRI). Celui-ci est destiné à définir comment Kubernetes pilote un runtime….
En résumé, on n’a le plus souvent un runtime exécutant un conteneur au standard de l’OCI, additionné d’un environnement complémentaire et pilotable par Kubernetes car compatible avec CRI. Me concernant, je vais rester sur le classique containerd/runc.
Le schéma ci-dessous, reprend ces principes ainsi que ceux précédemment expliqués concernant le réseau et le stockage.
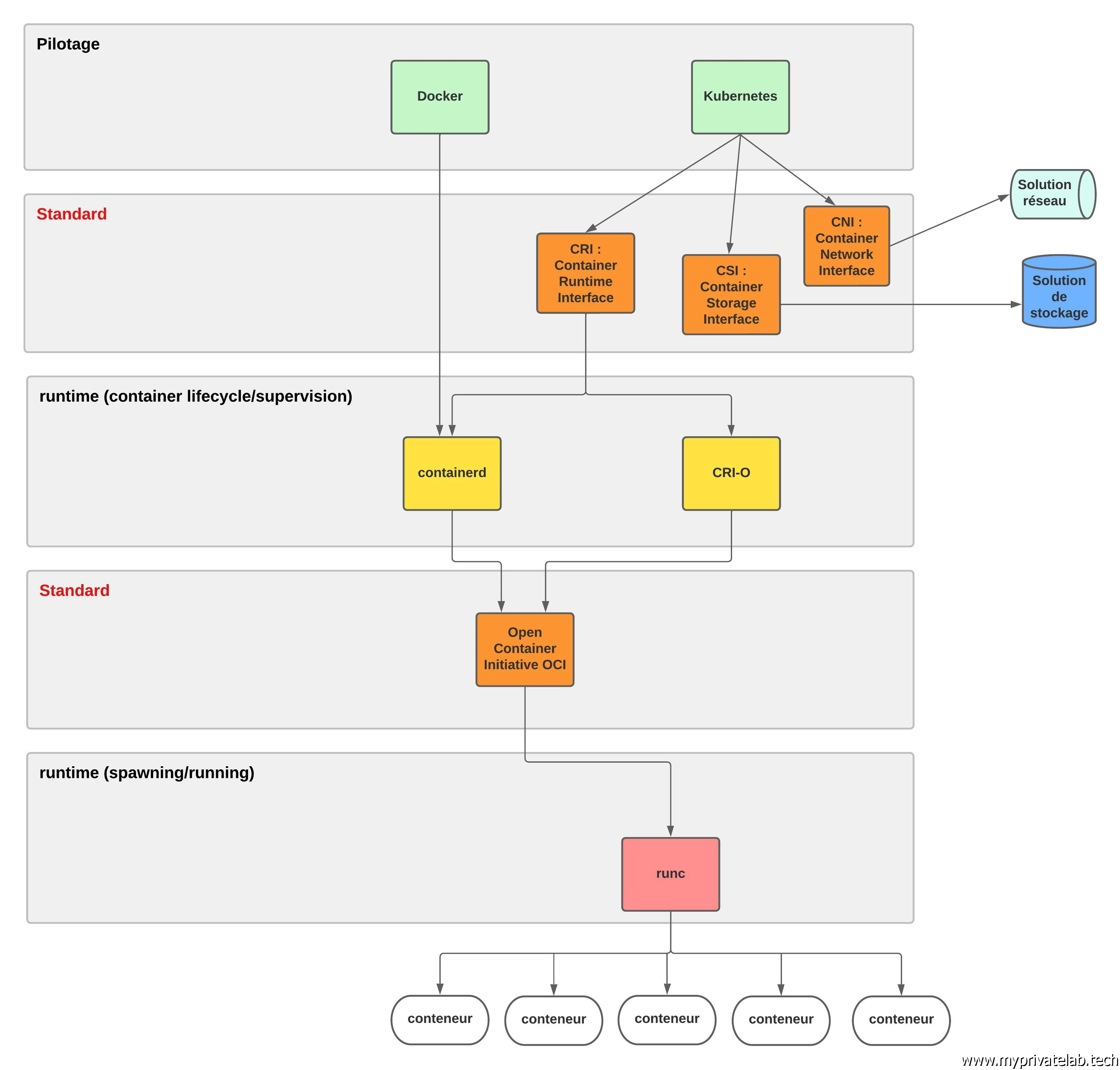
Cliquez sur l'image pour l'agrandir.
Traitement de la couche Kubernetes
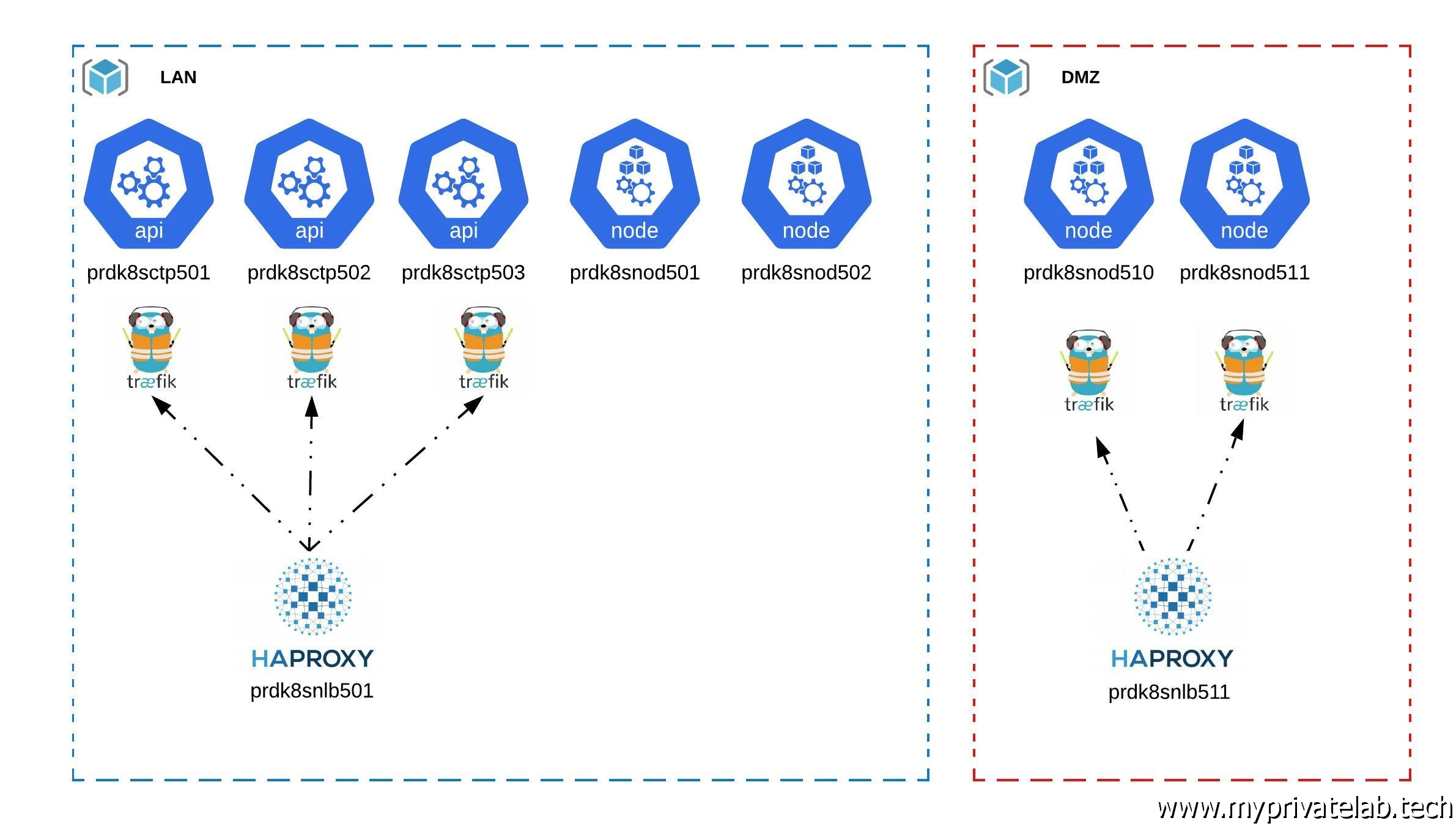
Mon cluster Kubernetes est composé de trois nœuds control plane, 2 nœuds d’exécution en LAN et 2 nœuds d’exécution en DMZ.
Les noeuds control plane sont essentiels au bon fonctionnement du cluster. Ils vont héberger le serveur API sans lequel il est impossible d’interagir avec le cluster et de nombreux autres rôles critiques. Ils vont aussi stocker la base clef/valeur etcd dans laquelle toute la configuration du cluster va se retrouver. (A noter que certains prefèrent utiliser des instances etcd dédiées hébergées en dehors des control plane)
On voit beaucoup d’exemples où l’on exploite un seul master. C’est une très bonne chose pour se former ou pour traiter des environnements non critiques, mais sur des contraintes de production on ne peut se contenter que d’un seul master. Si celui-ci venait à tomber, on impacterait l’interaction avec le Cluster. Avoir un master indisponible ne rend pas les applications déjà en œuvres sur le cluster inopérantes, par contre il n’y a plus d’orchestration et il devient impossible d’opérer son cluster.
À savoir que deux masters n’est pas supporté pour offrir une solution de HA, car c’est insuffisant pour offrir un consensus de l’état du cluster, un troisième master est obligatoire pour permettre à l’ensemble des masters de se mettre d’accord entre eux.
Si maintenir un cluster de control plane vous fais peur, alors les solutions managées des cloud provider sont faites pour vous. Dans ces offres, ce n’est pas vous qui avez la charge des contrôles plane. Vous vous contentez d’échanger avec l’API K8S, mais c’est au cloud provider de s’assurer du bon fonctionnement des nodes.
Concernant la configuration hardware des VMs hébergeant les différents rôles, je vais partir sur le minimum proposé pour les contrôles plane, à savoir 2vCPU et 2Go de ram. 20Go de disque sont suffisants, mais j’arriverais à 60Go me concernant.
Pour les worker, on sera sur 4vCPU et 4Go de ram, et également 60 Go de disque, mais ces chiffres peuvent être revue fonction de la charge du cluster. À noter que les volumétries disque ne sont que pour le système, comme vu dans la partie concernant le stockage, les espaces réservés aux assets sont traités différemment.
Cas des applications tierces
Cliquez sur l'image pour l'agrandir.
Exposition de l'API et des points d'entrées
Comme indiqué juste au dessus, le cluster dispose de trois control plane. Pour qu'ils assurent une haute disponibilité de l'API qu'ils hébergent, il est necessaire de les exposer à travers une virtual IP (VIP) via un load balancer.
J'ai choisi HAproxy car c'est une solution open sources réputée et largement utilisée. Plusieurs HAproxy seront déployés pour couvrir les besoins d'accessibilité de l'API mais aussi les accès externes vers les applications hébergées au sein du cluster.
Exposition des applications
Encore une fois, il est important de retenir que Kubernetes reste sur une logique modulaire. De base, votre application est rendue accessible à travers des objets dédiés appelés des Services (svc). Ces derniers peuvent être de différents types, mais sont principalement faits pour une exposition de vos assets au sein du cluster.
Lorsqu’il s’agit d’exposer vos applications à l’extérieur du cluster, les fonctionnalités de bases restent limitées. Il est conseillé d’exploiter des outils annexes pour offrir davantage de paramètres.
Comme toujours avec Kubernetes, exposer ses apps en dehors du cluster passe par l’usage d’objets dédiés. En l’occurrence on va parler d’ingress (ing), qui eux-mêmes sont rattachés aux svc. Je ne vais pas rentrer dans le détail ici, mais un ingress peut être « piloté » via l’usage d’un ingress contrôleur. Ce dernier va s’appuyer sur l’objet de base pour ensuite traiter la demande et permettre des traitements sur les requêtes.
Me concernant j’ai choisi la solution Traefik. C’est un produit que j’apprécie particulièrement.
Là où d’autres solutions comme NGINX existaient avant K8S pour ensuite se rendre compatibles avec ce dernier, Traefik a été conçu pour Kubernetes et plus globalement pour la conteneurisation (ne me faites pas dire que NGINX n’est pas bien).
Il peut se déployer de deux manières sur un cluster. Soit via l’enrichissement de l’API de K8S. Dans ce cas on parle de CustomResourceDefinition (CRD). Il s’agit d’ajouter aux objets de bases Kubernetes, de nouveaux objets propres à la solution déployée. Cela permet de tirer pleinement parti des capacités de Traefik, mais ne garantit pas de retrouver ces nouveaux objets sur des solutions Kubernetes managées ou associées à une distribution. C’est pourquoi je préfère rester sur l’objet de base Ingress dans lequel des annotations seront ajoutées pour être traité par Traefik.
À noter qu’au moment d’écrire cet article, on parle beaucoup d’un nouvel objet natif Kub, nommé gateway, censé remplacer les objets Ingress. Je serais sans doute amené à les utiliser par la suite, mais en l’état, je ne connais pas bien encore leur fonctionnement.
Conclusion
Comme dit en début d'article, il est possible que pour quelqu'un n'ayant jamais manipulé Kubernetes, certains points restent encore flous. Il s'agissait ici de survoler rapidement quelques grands principes qui pourront être détaillés davantage dans d'autres étapes. L'important est à minima d'avoir une idée des composants à déployer et de la cible à atteindre.
Pour poursuivre le cookbook avec l'étape suivante c'est par ici