Déploiement d'une solution IA interne: Ollama + OpenWebUI
Introduction
Dans le cadre d’un article visant à expliquer comment ajouter un node worker à un cluster Kubernetes existant, j’avais intégré à mon propre cluster (dont je décris le déploiement dans un cookbook dédié) un nœud physique.
Le but pour moi était de pouvoir tester la combinaison Ollama et OpenWebUI pour obtenir une solution d’assistant IA locale.
IA: entre Hype et opportunité
Au moment d’écrire ce tutoriel, l’IA est toujours en pleine hype avec une multiplication des annonces, produits et révolutions journalières autour du sujet.
Le mot IA est collé à toutes les sauces. On n’échappe pas au bullshit marketing où des applications diverses et variées se voient soudainement complétées des deux lettres devenues presque obligatoires dans toutes présentations PowerPoint IT qui se respectent.
Je ne pouvais donc pas échapper à l’effet de mode. Je dois avouer qu’une fois la poussière d’étoiles de la fée marketing dissipée, il y’a une vraie (r)évolution derrière l’avènement de ChatGPT, avec un écosystème ultra intéressant à creuser.
Il n’a pas fallu longtemps à l’open source pour établir des projets de qualité portés par d’excellents développeurs motivés pour proposer une alternative aux géants du marché.
L’une des craintes que l’on retrouve souvent en entreprise quant à l’implémentation de l’IA, et plus particulièrement des chatGPT like (MS Copilot, Google Gemini…) c’est l’usage des données et les risques associés: fuite de données, mauvais usages, dépendances à des tiers…. Tout cela a provoqué dans certaines sociétés, une très grosse méfiance et une alerte générale dans beaucoup de cellules cyber…avec en tête de ligne des RSSI et des gestionnaires du risque parfois paniqués à l’idée de voir tous leurs salariés balancer aux serveurs d’OpenAI&CO tous les secrets de l’entreprise.
Il y’a eu exactement le même réflexe avec l’arrivée d’Internet dans le milieu professionnel. J’ai moi-même connu le fameux PC unique à tout le service et seul autorisé à naviguer sur Internet sur autorisation explicite du management (ça ne me rajeunit pas…).
Sauf que la réalité est ce qu’elle est: imaginer travailler demain sans IA…c’est prendre un plus gros risque de passer à côté d’une belle opportunité d’accélérer son business que de voir son entreprise couler à cause d’une sortie de route sur une IA générative.
Je ne dis pas que le danger n’existe pas, mais presque personne ne se pose plus la question aujourd’hui du risque qu’elle prend à faire une recherche sur google, à poster un bout de code sur Stackoverflow ou s’aider des forums communautaires…là aussi il y’a maintes occasions de divulguer involontairement des informations sensibles.
Il est préférable d’éduquer que d’interdire (après tout dépend des environnements professionnels).
Comme n’importe quel outil, l’IA nécessite d’être manipulée correctement, en sachant ce que l’on fait (et surtout dans quel contexte on le fait).
Maintenant, si l’usage de service en ligne présente un trop gros risque pour son activité et qu’on ne souhaite pas dépendre d’un acteur tiers pour exploiter l’IA, il existe des solutions totalement onprem et pouvant s’exécuter sur des serveurs locaux.
Ollama: le store des modèles d'IA
Ollama fait partie de ces outils formidables qui proposent aujourd’hui un accès à de multiples modèles d’IA génératives de manière très simple et efficace.
Fondé en 2023 par Jeffrey Morgan et Michael Chiang, l’application est totalement open source et connait un beau succès.
Son principe est de proposer un accès à de nombreux modèles de réseau neuronal et rendu public comme llama de Facebook ou Mistral de notre startup française.
Chaque modèle est récupérable très facilement à l’aide d’une CLI (Command Line Interface) exploitant des termes basiques (comme "pull"). Il est même possible d’obtenir des versions customisées des modèles, intégrant plus ou moins de paramètres, fonction qu’on cherche à privilégier la rapidité d’exécution ou la précision des réponses.
L’accès aux modèles est inspiré des stores applicatifs, où à travers un simple site web vous pouvez parcourir des centaines de modèles avec une description de leur usage, allant des IA généralistes à des IA spécialisées.
Une fois le modèle récupéré, il s’exécute localement et sa performance dépend donc des ressources que vous avez attribuées à la plateforme sur laquelle est installé Ollama.
Aucune connexion en ligne n’est nécessaire pour solliciter le modèle et toutes informations échangées restent locales à votre instance de Ollama.
Ollama ne fournit pas de GUI (Graphical User Interface), et c’est là qu’intervient le second applicatif: OpenWebUI.
OpenWebUI: une interface pour les gouverner tous
Créé fin 2023 par Timothy Jaeryang Baek et publié en open source également, le projet est parfaitement complémentaire à Ollama avec qui il s’intègre parfaitement. Il permet de fournir une interface graphique très inspirée de ChatGPT grâce à laquelle il devient très simple d’interagir avec les différents modèles que l’on a récupérés via Ollama.
Un exemple de déploiement sous Kubernetes
Après cette longue introduction, il est temps de passer à l’action. Bien entendu, j’ai décidé de déployer le combo gagnant sur Kubernetes et d’exploiter mon nœud physique.
Comme j’ai pu le faire à d’autres reprises, notamment sur la partie traitant d’un déploiement d’une application sous K8S, je vais commencer par décrire mes objets Kubernetes et leur imbrication.
Afin d’isoler mon déploiement, je vais dédier un namespace respectant ma nomenclature: prd-mygpt-lan. (la création de ce dernier se fait via la commande kubectl create ns prd-mygptlan-lan)
Voici une présentation schématique de ce qui va être exécuté sur le cluster.
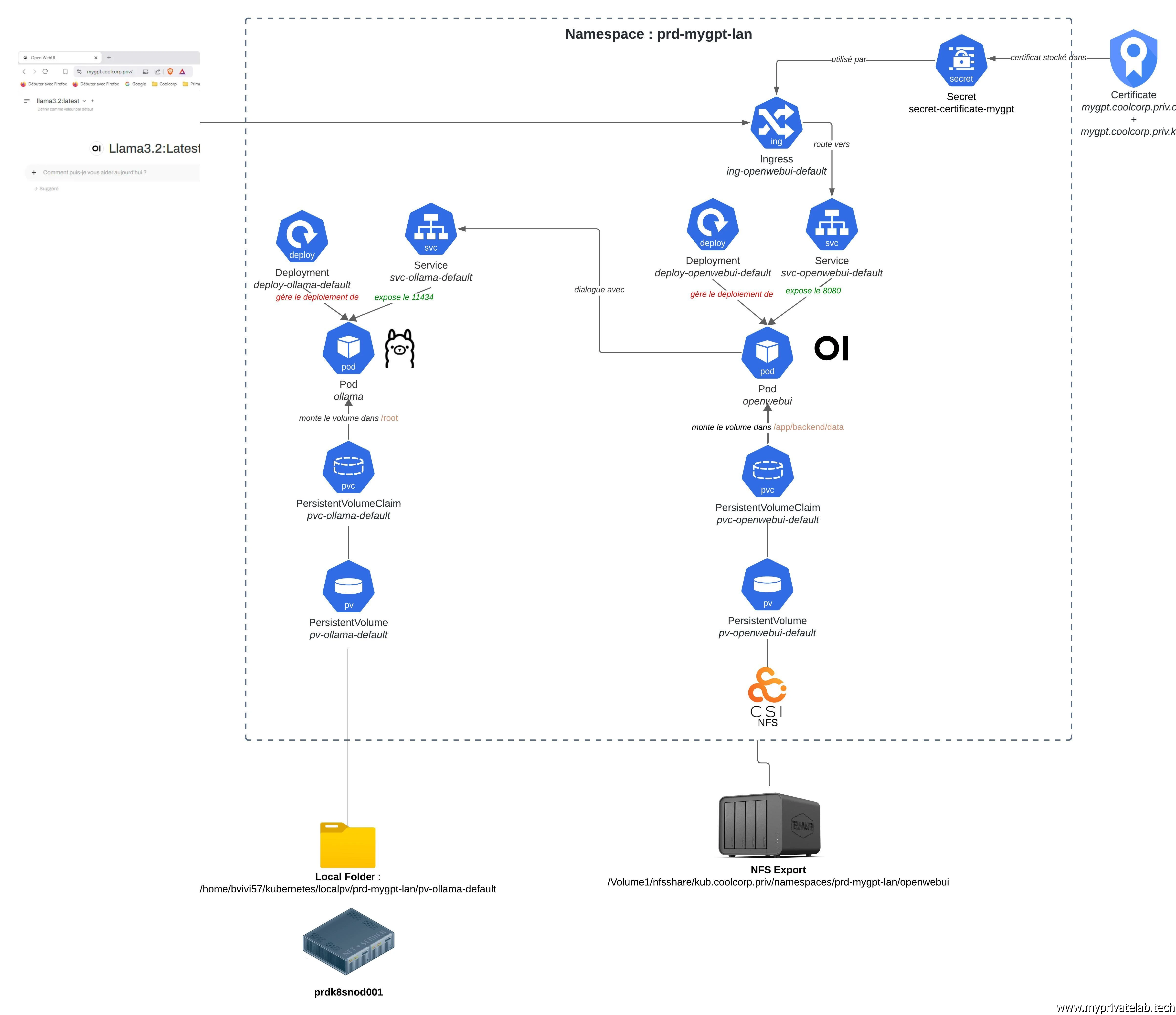
Cliquez sur l'image pour l'agrandir.
Je ne vais pas revenir dans le détail pour chaque objet utilisé. Si vous souhaitez davantage d’informations sur la logique de fonctionnement de K8S et comment déployer une application sur cette plateforme, n’hésitez pas à parcourir mon cookbook sur le sujet et à prendre connaissance des différentes définitions associées au Pod, au Deployment au Service et à Kubernetes lui-même.
Dans le cas de figure qui nous intéresse aujourd’hui, à savoir la mise en place de Ollama et de OpenWebUI, la particularité concerne le volume persistent pour Ollama et son choix de node pour s’exécuter.
En effet, chaque modèle d’IA que l’on souhaite tester va devoir être récupéré localement. En fonction du modèle choisi la taille occupée sur le disque peut-être importante. On va également avoir besoin de performance et il n’est pas certain qu’un PersistentVolume (pv) basé sur un filesystem réseau comme NFS (Network File System) ou SMB (Server Message Block) soit suffisant à ce niveau.
Comme je ne dispose pas d’une infrastructure de storage professionnelle, je vais devoir me reposer sur le stockage local de mon worker physique K8S.
Celui-ci utilise un disque SSD NVME, je vais donc pouvoir proposer un niveau de performance que j’espère suffisant.
Par contre, je vais créer une dépendance entre mon application et le serveur, puisque la donnée sera hébergée localement. Si mon conteneur devait redémarrer sur un autre node du cluster, il partirait sur une donnée vierge.
Au vu du caractère éducatif du projet, ce n’est pas un problème, mais dans un environnement de production, il est évident que l’usage d’un espace de stockage local à un nœud n’est pas à privilégier autrement que pour certains cas où la perte de données n’est pas ou peu problématique (cache applicatif par exemple).
Sinon, sur le reste de la configuration on demeure sur une logique classique. Seule la partie OpenWebUI a besoin d’être associée à un Ingress, car c’est elle qui doit être accessible de l’extérieur du cluster. La partie Ollama a besoin d’être accessible uniquement en interne du cluster par OpenWebUI (via le Service K8S associé à Ollama).
Prérequis à l'usage du stockage local
C’est le paramétrage un peu particulier de cette configuration. Malgré l'usage d'un disque local à un node, il est préférable de déclarer une StorageClass (sc). Celle-ci n’a pour vocation que de conserver une logique habituelle de d'usage des espaces de stockage persistant (StorageClass(sc)/ PersistentVolumeClaim(pvc)/PersistentVolume(pv)).
Cette sc ne repose par contre sur aucun CSI (Container Storage Interface).
Sa création passe par l’intermédiaire du yaml 02-sc-local-storage.yml suivant:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-local-storage
provisioner: kubernetes.io/no-provisioner # Indique qu'il n'y a pas de provisionnement dynamique
volumeBindingMode: WaitForFirstConsumer
Cliquez sur l'image pour l'agrandir.
J’applique le yaml avec la commande kubectl apply -f .\02-sc-local-storage.yml
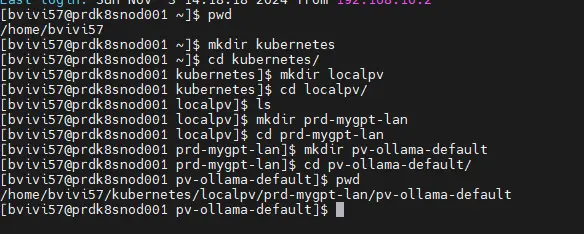
Ensuite du côté de mon node physique, je vais créer un dossier local dédié à l’hébergement des données de ce volume.
Dans mon cas, le choix est totalement arbitraire. Pour plus de simplicité, j’utilise la racine /home qui bénéficie dans le cadre de mon installation de Rocky Linux (sur lequel j’ai déployé le worker K8S) de la plus grande partition.
Bien entendu, vous pouvez choisir ce qui vous convient le mieux.
mkdir -p ~/kubernetes/localpv/prd-mygpt-lan/pv-ollama-default

Cliquez sur l'image pour l'agrandir.
Déploiement de Ollama
Maintenant que les prérequis au stockage persistant pour Ollama sont couverts, je vais pouvoir passer au PersistentVolume (pv) lui-même via le fichier yaml 01-pv-ollama-default.yml.
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-ollama-default
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
capacity:
storage: 250Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: sc-local-storage
local:
path: /home/bvivi57/kubernetes/localpv/prd-mygpt-lan/pv-ollama-default
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- prdk8snod001
Je fais appel à ma sc « fictive » et je pointe vers le dossier que je viens de créer sur mon node physique.
On peut vérifier que le volume est prêt sans être encore mappé puisqu’aucun pvc n’y fait référence.
kubectl get pv

Cliquez sur l'image pour l'agrandir.
C’est au tour du pvc justement maintenant d’être créé via le fichier yaml 02-pvc-ollama-default.yml.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-ollama-default
namespace: prd-mygpt-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
accessModes:
- ReadWriteOnce
storageClassName: sc-local-storage
resources:
requests:
storage: 250Gi
Son contenu fait référence au pv précédent.
Je l’applique avec kubectl apply -f .\02-pvc-ollama-default.yml.
On peut vérifier son statut avec la commande kubectl describe pvc pvc-ollama-default -n prd-mygpt-lan.

Cliquez sur l'image pour l'agrandir.
Étant donné qu’aucune ressource ne l’exploite et qu’aucun Pod n’y fait appel, Kubernetes ne cherche pas à le provisionner et donc à le mapper au volume créé précédemment.
Cela va changer avec le déploiement du pod via le fichier 03-deploy-ollama-default.yml.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-ollama-default
namespace: prd-mygpt-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
replicas: 1
selector:
matchLabels:
environment: prd
network: lan
application: mygpt
tier: ollama
template:
metadata:
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
nodeSelector:
type: physical # Associe le pod aux nœuds ayant le label `type=physical`
tolerations:
- key: "node-role.kubernetes.io/worker-lan-physical"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ollama
image: ollama/ollama:0.4.0-rc6
ports:
- containerPort: 11434
volumeMounts:
- name: pv-ollama-default
mountPath: "/root"
volumes:
- name: pv-ollama-default
persistentVolumeClaim:
claimName: pvc-ollama-default
L’objet Deployment permet d’appliquer des contraintes de placement pour le pod. En effet, je souhaite exploiter exclusivement mon node prdk8snod001 (mon worker physique) puisque les données persistantes sont rattachées à un emplacement local au serveur. Je veux également profiter de toute la puissance disponible pour rendre le plus performant possible l’usage de Ollama en dédiant ce worker à son usage.
Pour cela, j’utilise dans le template du Pod, la notion de nodeselector, pour exploiter le label type: physical qui n’existe que pour mon worker physique, ainsi que la toleration au taint node-role.kubernetes.io/worker-lan-physical. (Plus de détails ici).
N’hésitez pas à adapter cette partie à votre propre usage.
On retrouve également le pvc qui va me permettre de mapper le pv dans /root au niveau du conteneur présent dans le pod.
Concernant le reste rien de spécial à détailler. Encore une fois, n’hésitez pas à passer par la partie de mon cookbook qui parle d’un déploiement d’une apps sous K8S pour en apprendre en plus.
On applique le déploiement via la commande: kubectl apply -f .\03-deploy-ollama-default.yml.
Passé cette étape, on peut observer avec la commande kubectl get pvc -n prd-mygpt-lan que cette fois-ci le pvc est utilisé, et le pv se retrouve dans un état mount.
On peut vérifier que le Pod est bien en place avec la commande kubectl get pod -n prd-mygpt-lan -o wide.

Cliquez sur l'image pour l'agrandir.
On note que le Pod est porté par prdk8snod001, ce qui est bien le souhait de départ.
D’ailleurs si on rentre dans le contexte du conteneur via la commande:
kubectl exec -it deploy-ollama-default-56855dc9dd-vqj7d -n prd-mygpt-lan bash (le nom du pod est à adapter)
et qu’on tente la création d’un fichier dans /root (un simple touch toto), on retrouve bien ce fichier dans /home/bvivi57/kubernetes/localpv/prd-mygpt-lan/pv-ollama-default directement au niveau de l’OS du node.

Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
On n’utilise donc bien un pv rattaché à un espace local au serveur sur lequel le Pod est exécuté.
Tant qu’a être dans le contexte du conteneur Ollama, autant en profiter pour récupérer des modèles d’IA.
Comme j’ai pu l’expliquer en début d’article il suffit de choisir sur la marketplace le modèle de son choix, pour récupérer la commande pull associée et la lancer via le binaire Ollama.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Par exemple, si je veux récupérer le modèle llama3.2, il me suffit de taper:.
ollama pull llama3.2

Cliquez sur l'image pour l'agrandir.
Après quelques minutes, le modèle est récupéré et devient utilisable en interne de mon réseau via Ollama.
On peut essayer avec d'autres modèles:

Cliquez sur l'image pour l'agrandir.
On peut à présent sortir du conteneur pour poursuivre le déploiement des objets Kubernetes.
On enchaine avec le fichier 04-svc-ollama-default.yml afin de déclarer le service qui va rendre accessible l’instance Ollama au sein du cluster K8S.
---
kind: Service
apiVersion: v1
metadata:
name: svc-ollama-default
namespace: prd-mygpt-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
ports:
- name: ollama
port: 11434
protocol: TCP
targetPort: 11434
selector:
environment: prd
network: lan
application: mygpt
tier: ollama
Pas de particularité à ce niveau, on fait juste attention à bien respecter les labels de sélections pour que le Service matche avec le Pod une fois la commande >kubectl apply -f .\04-svc-ollama-default.yml lancée.

Cliquez sur l'image pour l'agrandir.
Plus besoin d’autres objets pour Ollama, on peut maintenant passer à OpenWebUI.
Déploiement de OpenWebUI
L’outil a également besoin d’un stockage persistant, mais cette fois-ci sans exigence de performance particulière. On peut donc s’appuyer sur un pv basé sur le CSI NFS. Pour ceux qui le souhaitent, j’explique le fonctionnement de l’ensemble dans cet article.
Je commence par définir le pv dans le fichier 06-pv-openwebui-default.yml.
---
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: nfs.csi.k8s.io
name: pv-openwebui-default
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
driver: nfs.csi.k8s.io
volumeHandle: /Volume1/nfsshare/kub.coolcorp.priv/namespaces/prd-mygpt-lan/openwebui
volumeAttributes:
server: 192.168.10.152
share: /Volume1/nfsshare/kub.coolcorp.priv/namespaces/prd-mygpt-lan/openwebui
Celui-ci va taper sur mon NAS via le path NFS indiqué.
J’applique le fichier avec la commande kubectl apply -f .\06-pv-openwebui-default.yml.

Cliquez sur l'image pour l'agrandir.
J’enchaine avec le pvc et le fichier 07-pvc-openwebui-default.yml:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-openwebui-default
namespace: prd-mygpt-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 30Gi
volumeName: pv-openwebui-default
storageClassName: ""
Rien de spécial à dire et je l’applique avec la commande kubectl apply -f .\07-pvc-openwebui-default.yml

Cliquez sur l'image pour l'agrandir.
On peut passer au Deployment via le fichier 08-deploy-openwebui-default.yml:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-openwebui-default
namespace: prd-mygpt-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
replicas: 1
selector:
matchLabels:
environment: prd
network: lan
application: mygpt
tier: openwebui
template:
metadata:
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
containers:
- name: open-webui
image: ghcr.io/open-webui/open-webui:main
ports:
- containerPort: 8080
volumeMounts:
- name: pv-openwebui-default
mountPath: "/app/backend/data"
env:
- name: OLLAMA_BASE_URL
value: "http://svc-ollama-default:11434"
volumes:
- name: pv-openwebui-default
persistentVolumeClaim:
claimName: pvc-openwebui-default
J’utilise le pvc pour mapper le pv dans /app/backend/data au niveau du conteneur.
Il faut également renseigner la variable OLLAMA_BASE_URL pour que OpenWebUI puisse communiquer avec Ollama. En l’occurrence on donne le nom du Service K8S rattaché au Pod Ollama qu’on n’a créé juste avant (en précisant le port d'exposition du conteneur: 11434).
Pour rappel, une résolution interne est faite au sein d’un cluster Kubernetes, via le nom du service, OpenWebUI pourra résoudre l’IP associée et échanger en interne du cluster avec Ollama.
Il suffit de taper la commande kubectl apply -f .\08-deploy-openwebui-default.yml pour exécuter OpenWebUI.

Cliquez sur l'image pour l'agrandir.
On peut vérifier que le pod est démarré avec la commande kubectl get pod -n prd-mygpt-lan -o wide.

Cliquez sur l'image pour l'agrandir.
Veuillez noter que pour OpenWebUI aucune contrainte spécifique d’exécution du pod n’a été donnée. Je n’ai pas d’intérêt à ce que l’application s’exécute sur un nœud particulier comme c’est le cas pour Ollama. Je laisse donc le choix à l’orchestrateur du placement du pod.
Puis viens le tour du service associé à OpenWebUI avec le fichier 08-svc-openwebui-default.yml:
---
kind: Service
apiVersion: v1
metadata:
name: svc-openwebui-default
namespace: prd-mygpt-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
ports:
- name: openwebui
port: 8080
protocol: TCP
targetPort: 8080
selector:
environment: prd
network: lan
application: mygpt
tier: openwebui
Pas de particularité à signaler non plus. On travaille sur le port 8080 et on exploite les bons labels pour que le Service redirige vers le Pod OpenWebUI.

Cliquez sur l'image pour l'agrandir.
Il reste maintenant à publier l’URL de OpenWebUI.
Pour cela on a besoin d’un certificat. Je ne vais pas rentrer dans le détail de la logique d’obtention d’un certificat. Cela dépend de vos architectures et de vos systèmes. Pour ceux qui le souhaitent, j’ai rédigé un article pour le déploiement et l’usage de cert-manager, un outil permettant d’automatiser l’obtention des certificats au sein d’un cluster k8s. Vous y retrouverez les grands principes sur les certificats.
Dans ce cas précis, je ne peux pas exploiter cert-manager, car je ne souhaite pas exposer mon application sur le web et donc ouvrir l’URL pour solliciter le protocole ACME avec Let's Encrypt (plus d’explications ici).
Je vais passer par une solution manuelle. Je crée une clef privée et un fichier csr avec openssl via cette commande dans mon instance WSL:
openssl req -new -nodes -sha256 -keyout mygpt.coolcorp.priv.key -out mygpt.coolcorp.priv.csr -newkey rsa:4096 -subj "/C=FR/ST=Ile-de-France/L=Paris/O=COOLCORP/OU=Infrastructure/CN=mygpt.coolcorp.priv" -reqexts SAN -config <(printf "[req]\ndistinguished_name = req_distinguished_name\n[req_distinguished_name]\n[SAN]\nsubjectAltName=DNS:mygpt.coolcorp.priv").
Puis je soumets mon CSR (Certificate Signing Request) à ma PKI (Public Key Infrastructure) interne, en l’occurrence une PKI Windows, sur laquelle je lance la commande certreq -attrib "CertificateTemplate:TPL-SRV-WEB-DEFAULT" -submit .\mygpt.coolcorp.priv.csr pour récupérer un certificat (TPL-SRV-WEB-DEFAULT est le template de certificat que j’utilise en interne pour traiter tous les besoins de publication web).
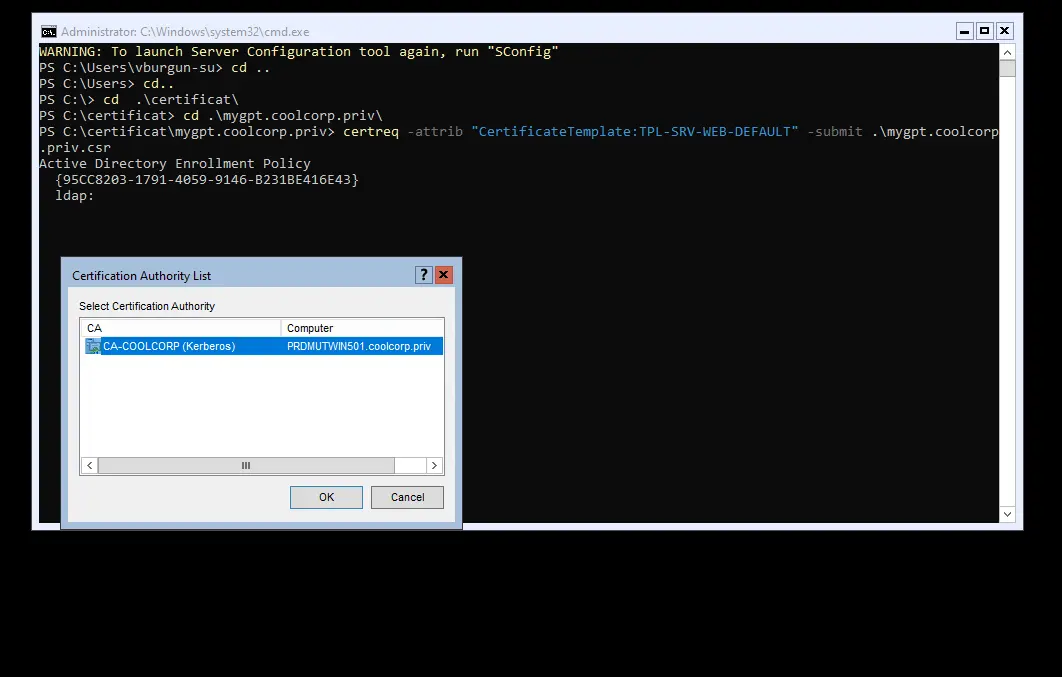
Cliquez sur l'image pour l'agrandir.
Encore une fois, cette logique est propre à mon infrastructure.
Peu importe ce que vous utilisez comme mécanisme de création de certificat, l’important est d’avoir à la fin une clef privée et le certificat rattaché.
Avec ces deux fichiers, mygpt.coolcorp.priv.cer et mygpt.coolcorp.priv.key dans mon cas, on peut créer un secret qui va contenir ces deux éléments.
On utilise pour cela la commande suivante:
kubectl create secret generic secret-certificate-mygpt --from-file=tls.crt=mygpt.coolcorp.priv.cer --from-file=tls.key=mygpt.coolcorp.priv.key --namespace prd-mygpt-lan

Cliquez sur l'image pour l'agrandir.
De cette manière, le secret secret-certificate-mygpt va pouvoir être utilisé pour faire référence à la clef et au certificat.
C’est ce secret que je vais référencer dans mon fichier 09-ing-openwebui-default.yml:
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-openwebui-default
namespace: prd-mygpt-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- mygpt.coolcorp.priv
secretName: secret-certificate-mygpt
rules:
- host: mygpt.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-openwebui-default
port:
number: 8080
Celui-ci va me permettre de créer l’Ingress en charge de rediriger les requêtes de l’extérieur faites sur l’URL mygpt.coolcorp.priv.
C’est mon instance de Traefik sur le lan qui va gérer cette Ingress. Pour plus de détails sur le principe de fonctionnement d’un Ingress contrôleur et le déploiement de Traefik, vous pouvez consulter cet article.
Il ne reste qu’à mettre en place l’ Ingress avec la commande kubectl apply -f .\09-ing-openwebui-default.yml.
Pour ceux qui le souhaitent l'intégralité des fichiers yamls utilisés pour cette démonstration est récupérable ici
Tests
Tout est maintenant prêt, il suffit de créer un alias DNS qui renvoie mygpt.coolcorp.priv vers mon haproxy utilisé en amont du cluster (voir cette partie du cookbook) pour accéder à la page d’accueil de OpenWebUI.
On a bien un certificat valide.
La première étape consiste à se créer un compte.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Ensuite on peut démarrer l’usage du produit. En haut à gauche il est possible de sélectionner le modèle d’IA que l’on souhaite solliciter. Vous retrouverez ici tous les modèles que vous avez récupérés via Ollama.
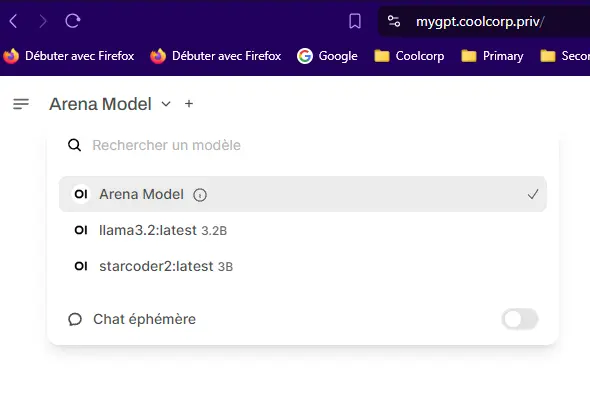
Cliquez sur l'image pour l'agrandir.
Pour le reste, on n’est vraiment sur un usage à la chatGPT ou vous pouvez interagir avec le modèle via une interface type « chatbot »
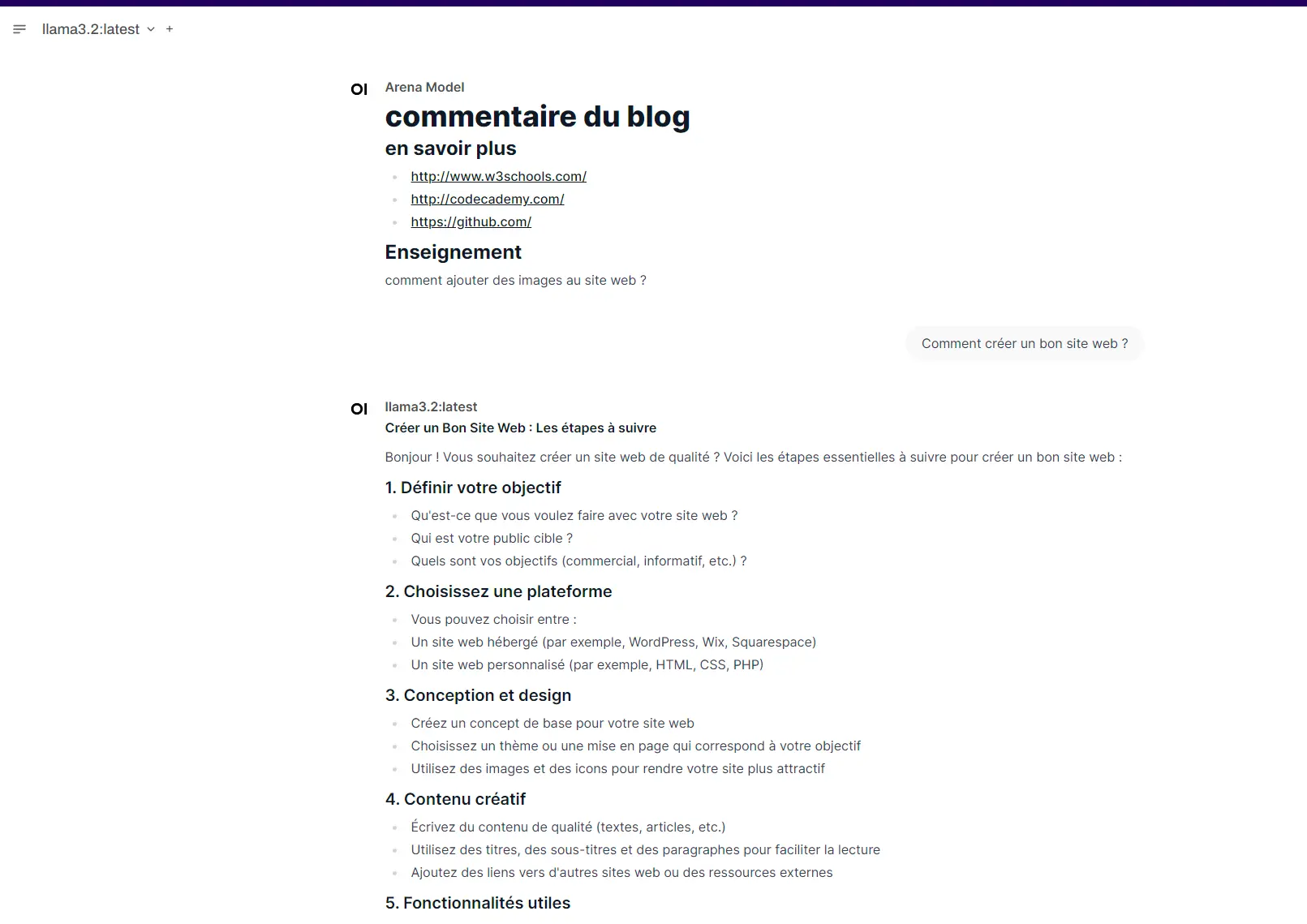
Cliquez sur l'image pour l'agrandir.
Conclusion
La combinaison Ollama et OpenWebUI est bluffante tant elle permet de simplifier le déploiement et l’usage de l’IA en interne d’une infrastructure.
La capacité à pouvoir switcher d’un modèle à un autre de LLM (Large Language Model) est extrêmement intéressante.
On peut comparer les modèles entre eux et s’appuyer sur celui qui nous parait le plus pertinent fonction des besoins. Par exemple retenir un modèle spécialisé sur la rédaction de code comme, Starcoder pour aider au développement et revenir à une IA plus généraliste comme llama3.2 pour d’autres taches.
On peut mettre à jour facilement les modèles et faire encore plein d’autres choses dont je n’ai même pas idée encore au moment d’écrire ces lignes.
En même pas 1 an, la communauté OpenSource a pu mettre dans les mains du plus grand nombre un outillage de plus en plus robuste et simple à utiliser, capitalisant sur l’explosion des LLM.
Par contre attention, si l’accès à l’IA est simplifié et qu’il devient possible d’avoir son propre « ChatGPT like » en interne, ça n’enlève pas les besoins en ressources matérielles.
À titre d’information, mon nœud physique, certes un peu ancien, mais reposant sur un CPU 4 Cores (8 Threats) et 32 Go de RAM donne tout ce qu’il peut au moment où les réponses à mes questions sont faites par Ollama.
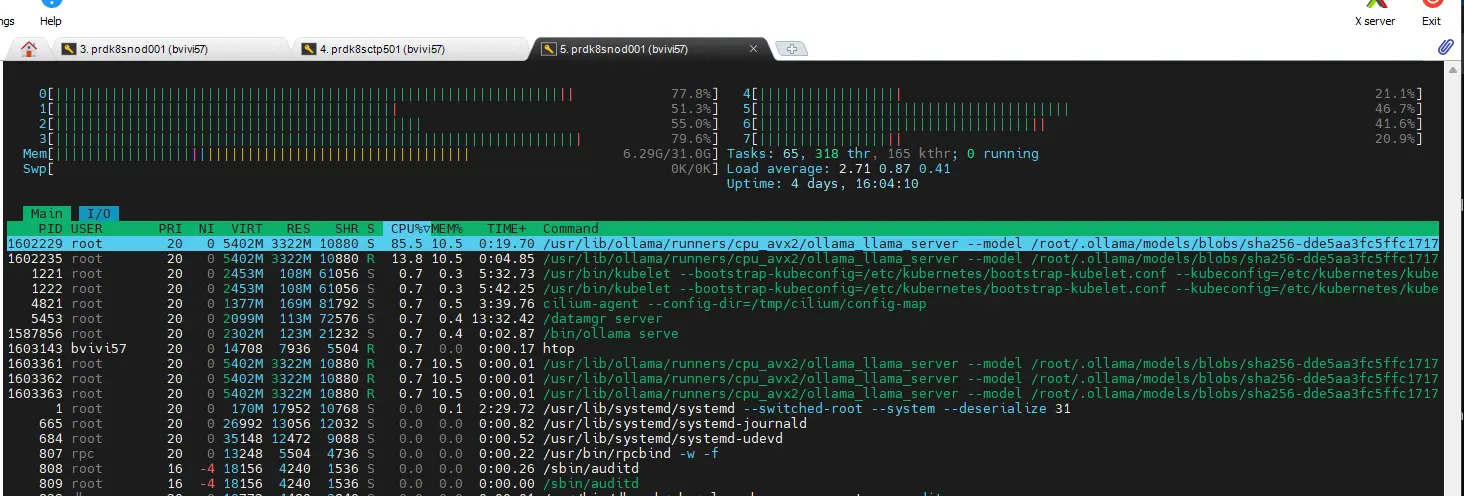
Cliquez sur l'image pour l'agrandir.
J’ai une latence d’environ 1s à chaque lettre. Si vous envisagez un usage en production, il va falloir prévoir de quoi rendre l’usage de l’ensemble fluide. À noter que Ollama supporte les GPUs, c’est même d’ailleurs conseillé…mais pas des GPU intégrés ou basiques.
A priori, l’implémentation des cartes NVIDIA est plus efficace, même si les cartes AMD sont également compatibles. Pour cela il faut revoir l’installation de Ollama et passer les bons arguments au pod avec à priori des dépendances autres. J’aimerais bien pouvoir tester cela, mais je n’ai pas le matériel nécessaire.
Encore une fois, Kubernetes s’est parfaitement adapté à la création de l’application et à l’exécution des pods associés. Cet article m’aura permis également de mettre en avant la capacité de K8S a dédié des nœuds pour certains usages et à mixer ses configurations.
Sachez que K8S intègre également le support des GPU. Les versions récentes de Kubernetes ont beaucoup apporté pour cela et de nombreux travaux sont en cours à ce niveau. Je suis encore novice sur ce sujet, mais si je trouve les moyens financiers suffisants j’essayerais d’investir dans du matériel compatible (d’ailleurs pour ceux qui souhaiteraient me soutenir, c’est par là).
N'hésitez à expérimenter ce duo gagnant Ollama/OpenWebUI, que ce soit sous Kubernetes ou via une installation plus directe, il y’a de quoi réaliser de beaux projets avec ces deux outils…et de passer du bullshit marketing à la réalité du terrain !