Les agents IA: découverte du protocole MCP
Introduction
Depuis sa démocratisation par l’arrivée de ChatGPT fin 2022, l’IA ne cesse d’être adoptée et développée.
Après la guerre des prompts, il est temps maintenant de connecter les fameux LLMs (Large Language Models) à nos outils de tous les jours.
C’est le moment des agents IA. Derrière ce nouveau buzzword se cache la volonté de profiter de la capacité des LLMs pour construire des IA spécialisées, capable de travailler en synergie pour piloter tout un workflow.
Imaginez pouvoir gérer une chaine de CICD entièrement en langage naturel. Un premier agent IA pourrait par exemple se charger de récupérer votre code source sur GIT, de le soumettre à une analyse de bonnes pratiques et de recherches de failles, pour éventuellement déléguer les corrections identifiées à une autre IA spécialisée dans le code.
Une fois cette étape passée, une autre IA se chargerait de compiler le code, puis de l’envoyer dans un gestionnaire d’artefact. Là aussi, une IA pourrait prendre le relais, exécuter le code dans un environnement de tests, puis acter de son bon fonctionnement pour ensuite suggérer à une autre IA de déployer les binaires en productions, voire même à créer un conteneur.
Pour arriver à ce résultat, il convient de relever deux défis:
- Permettre à des IA de communiquer entre elles: pour cela, il faut établir un protocole de communication commun et standardisé, traité de la même manière par chaque IA.
- Faire communiquer les IA avec les outils à leur disposition. Dans notre exemple cela reviendrait à fournir à des IA la capacité d’interagir avec des applications comme SonarQube (ou Oasis), Gitlab, Jenkins, Kubernetes…Il faut alors un système de plugin permettant aux IA de se connecter aux outils et de pouvoir identifier la liste des actions réalisables.
Plusieurs standards apparaissent sur le marché, mais l’un d’eux fait de plus en plus parler de lui: MCP pour Model Context Protocol.
Le protocole MCP
Cliquez sur l'image pour l'agrandir.
Les origines
MCP a été proposé par Anthropic à la fin de 2024. Il a été présenté comme un standard ouvert permettant aux LLMs d’interagir dynamiquement avec des outils, fichiers et bases de données, de manière uniforme et interopérable.
Anthropic est une entreprise d’IA fondée en 2021 à San Francisco, elle est principalement connue pour son modèle LLM Claude, concurrent de ChatGPT. La société se démarque par son discours autour de la transparence et la sécurité de l’IA avec une forte implication communautaire. Si elle reste la mainteneuse principale du projet github MCP , elle encourage aux développements associés et laisse les sources ouvertes.
Principes
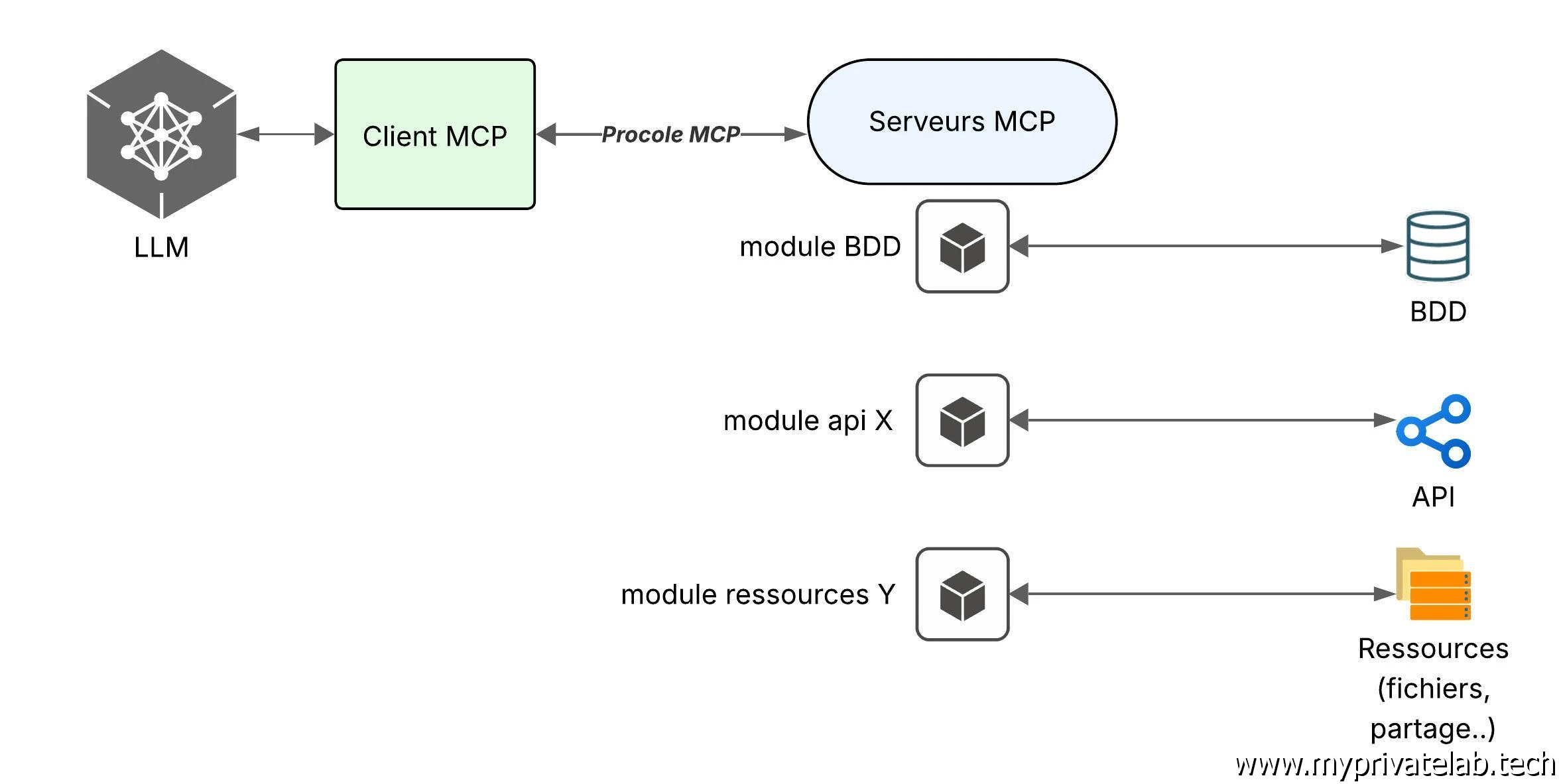
MCP repose sur un fonctionnement client-serveur
Cliquez sur l'image pour l'agrandir.
Un client (l’exécution d’un modèle LLM) se connecte à un serveur MCP. Ce serveur MCP annonce au client ses capacités, soit les actions possibles sur les outils associés. Le client enregistre ces capacités au sein du modèle.
Par la suite l’utilisateur peut solliciter le modèle qui peut décider de quels outils il a besoin pour ensuite transmettre une requête au serveur MCP. Le serveur exécute l’action demandée et retourne le résultat.
Chaque serveur MCP va pouvoir être accompagné d'un module, chaque module etant associé à des capacités spécifiques. Chaque module vient avec sa configuration et ses autorisations potentielles.
Le client peut solliciter chaque serveurs MCP fonction des requetes affichées par le client.
Demonstration
Mode "online"
Un des moyens le plus rapides de s’essayer au MCP et d’utiliser Claude Desktop. Il s’agit du client lourd de l’IA d’Anthropic.
Il est disponible pour plusieurs plateformes, dans mon cas, je vais l’installer sous Windows.
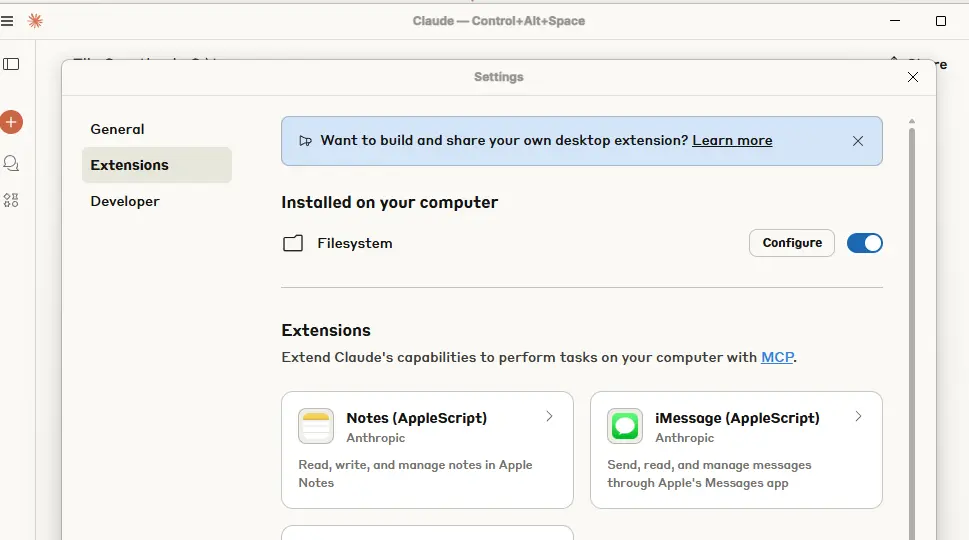
En allant dans les fonctions avancées du produit, on peut activer le serveur MCP intégré à l’outil et exploiter les modules fournis de base, comme celui autorisant l’IA à interagir avec votre filesystem.
Il faudra simplement indiquer les emplacements de votre arborescence ou l’IA pourra agir.
Cliquez sur l'image pour l'agrandir.
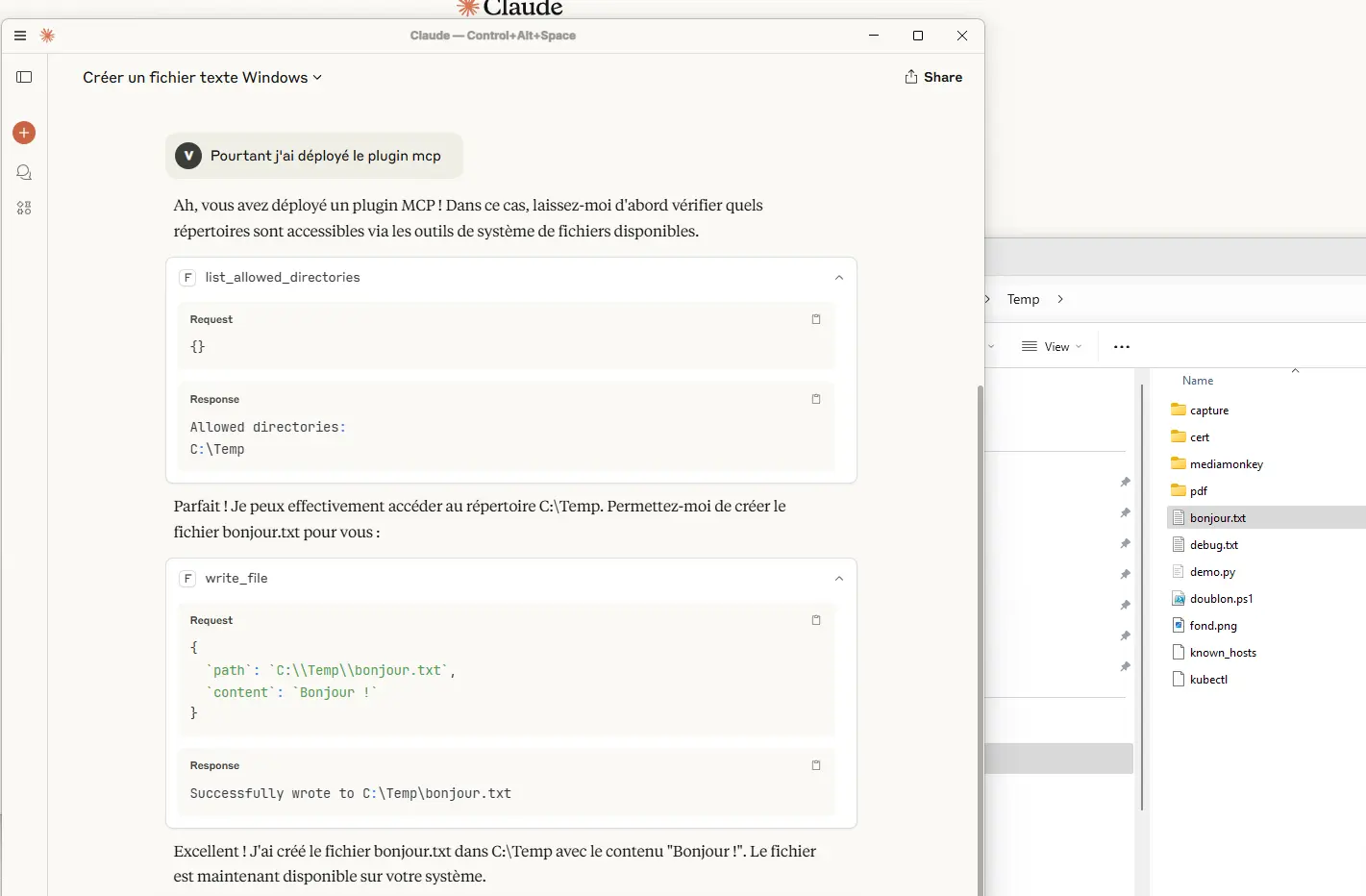
Une fois la configuration en place, on peut demander à l’IA d’accéder à votre filesytem, dans les emplacements autorisés.
Par exemple, lui demander de créer un fichier bonjour.txt dans c:\temp.
Cliquez sur l'image pour l'agrandir.
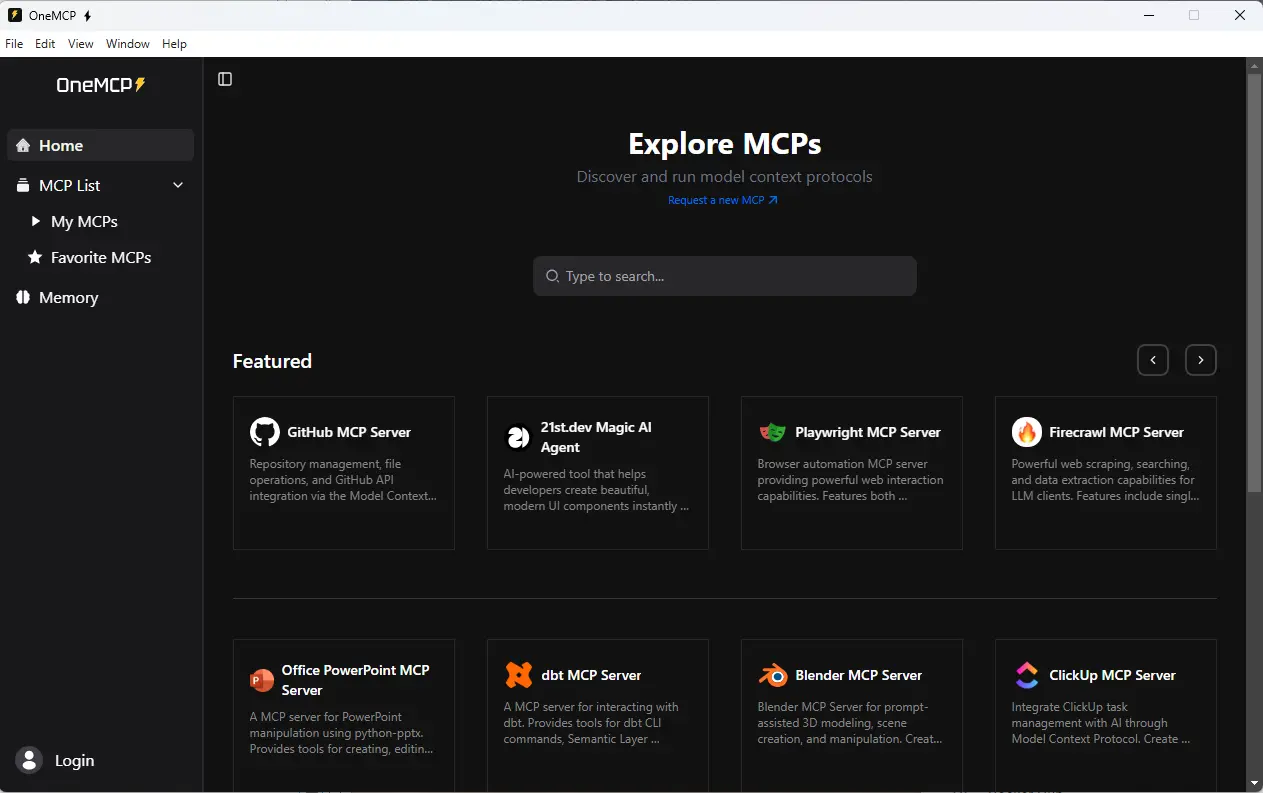
C’est très basique, mais ce n’est que le sommet de l’iceberg. Bien d’autres modules MCP sont disponibles, et l’un des outils les plus pratiques pour les trouver et les configurer est OneMCP.
OneMCP est disponible pour PC et MAC, il s’installe très facilement.
Lorsqu’on l’exécute, OneMCP va référencer tous les serveurs MCP dont il a connaissance. Il va pouvoir les récupérer, vous fournir une GUI de configuration et va vous permettre de les exécuter.
Cliquez sur l'image pour l'agrandir.
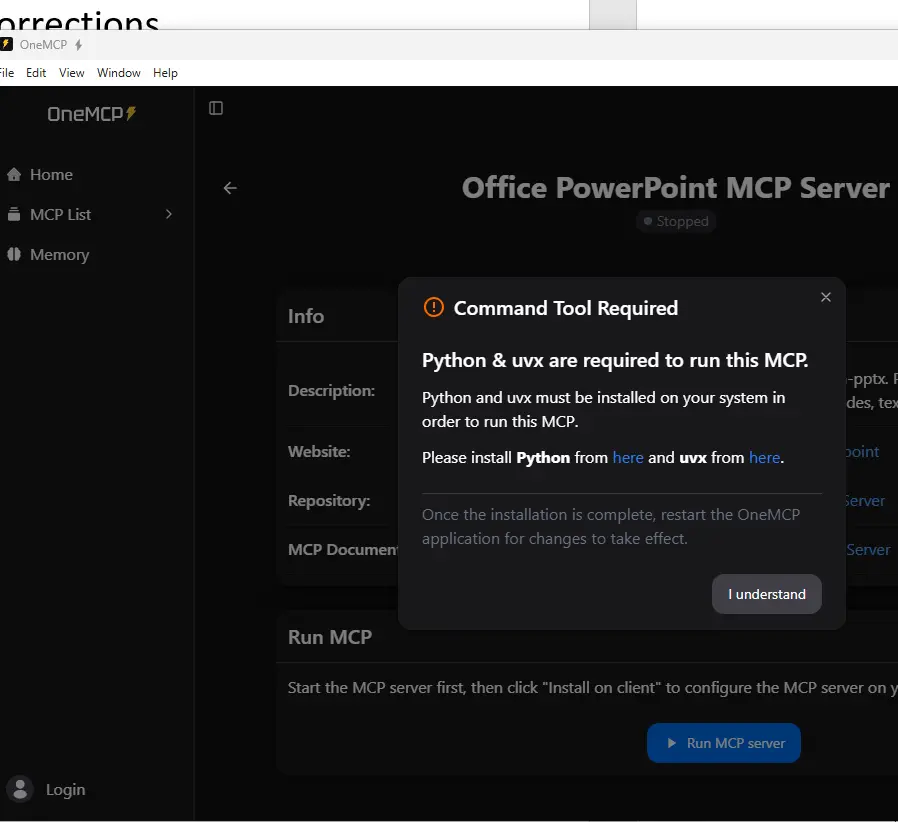
Certains modules nécessitent des prérequis additionnels, comme des librairies ou des binaires complémentaires, OneMCP vous guide à ce niveau.
C’est le cas du module pour piloter PowerPoint, par exemple.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
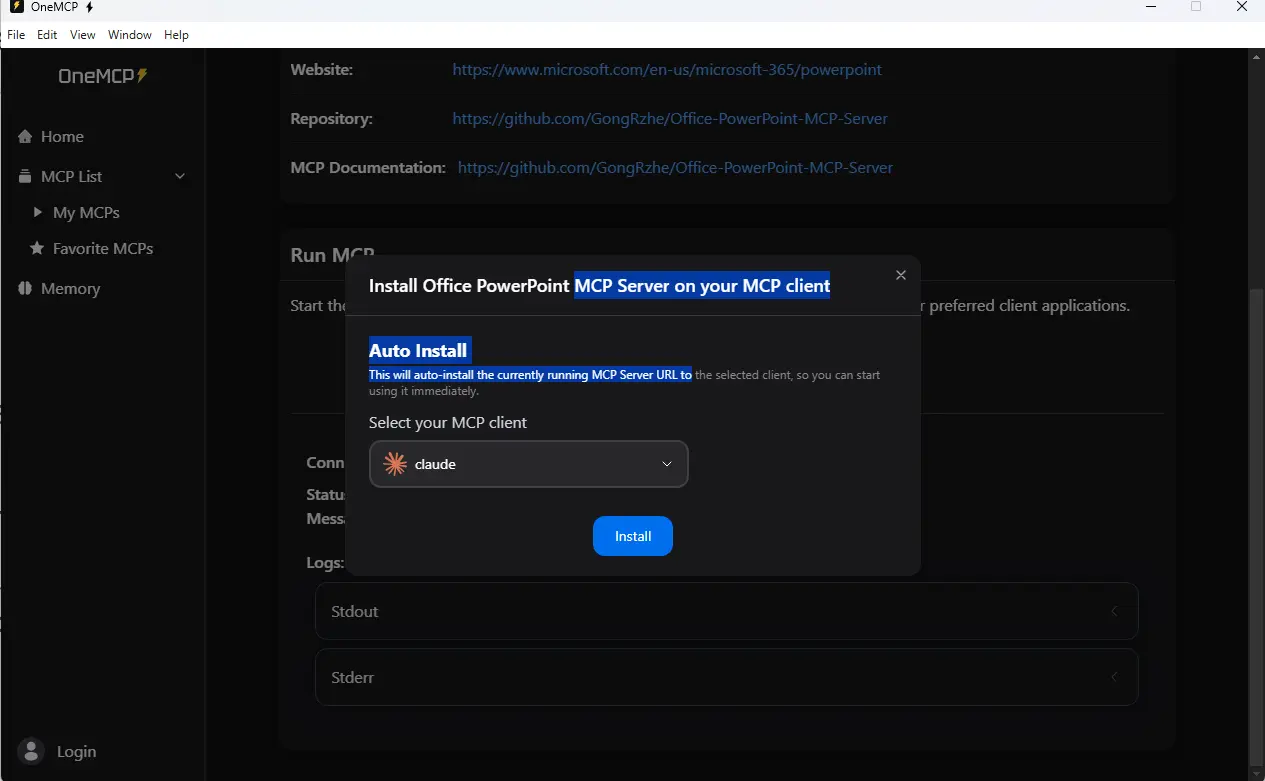
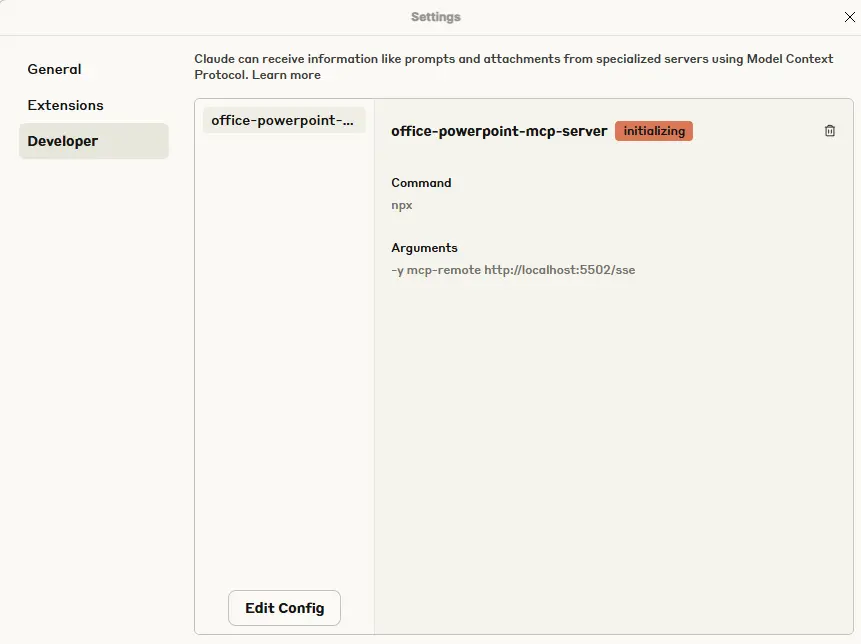
Mais une fois ces prérequis remplis, on peut mapper Claude Desktop à OneMCP pour exploiter ce nouveau module à travers le serveur MCP associé.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Essayons par exemple de demander la création d’un PowerPoint sur MCP.
La magie opère rapidement, et l’on assiste à la réflexion de l’IA sur le sujet. Il se peut que vous ayez à valider quelques accès durant le processus.
Cliquez sur l'image pour l'agrandir.
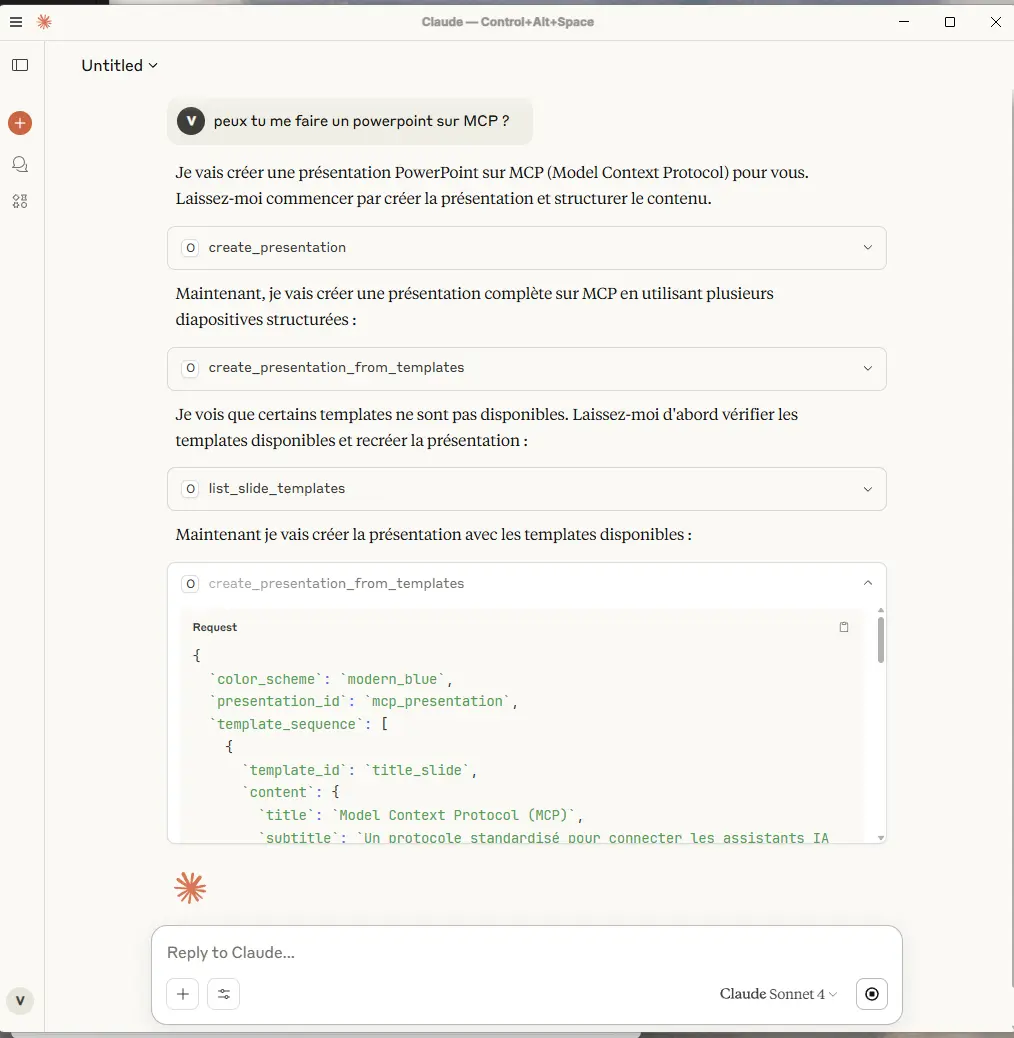
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
En bout de chaine, on a un diaporama généré sur le sujet…certes un peu fade, mais le contenu est là.
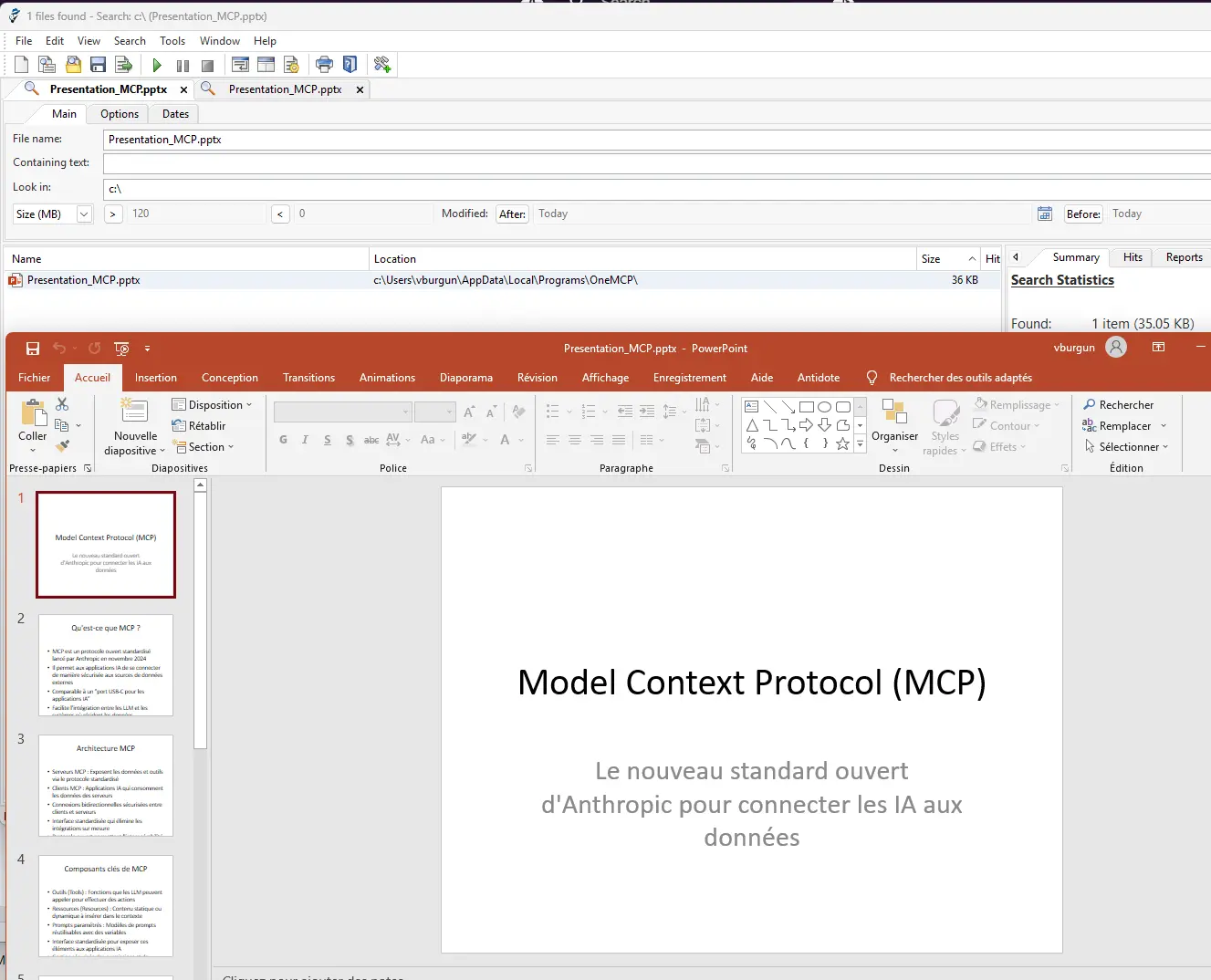
Cliquez sur l'image pour l'agrandir.
Et surtout, si vous bénéficiez d’un abonnement à Claude, vous pouvez aller plus loin en lui demandant davantage de requêtes pour améliorer le fichier et enrichir son contenu.
Mode "offline"
À ce stade, il y a déjà de quoi faire énormément de choses. L’inconvénient de cette intégration est d’exploiter une IA en ligne.
Ce n’est pas toujours possible en entreprise, et certaines activités sensibles demandent à ne pas dépendre d’un modèle LLM exécuté sur des serveurs distants.
MCP étant ouvert, rien n’empêche son implémentation sur des IA locales…comme avec Ollama 😊 !
J’ai déjà présenté ce formidable outil qu’est Ollama dans cet article. N’hésitez pas à le lire, j’y décris comment l’installer sous Kubernetes et comment profiter d’un GPU pour l’exécution de modèles LLM open source.
L’idée est de partir de mon installation actuelle de Ollama sur mon cluster.
Aujourd’hui j’exploite Ollama à travers la GUI OpenWebUI, présenté également dans ce même article.
Cela me permet d’avoir à la maison un équivalent « light » à ChatGPT avec la possibilité de comparer plusieurs modèles LLMs entre eux.
Je n’ai jamais eu à ouvrir l’accès à l’API de Ollama en dehors de mon cluster. Mais pour cet article, je vais devoir créer un ingress complémentaire chargé d’exposer l’API d’Ollama sur mon réseau afin qu’il puisse joindre un serveur MCP.
L’objectif n’est pas de décrire en détail la configuration K8S connexe. Je vous suggère plutôt d’explorer mon site pour en apprendre davantage sur la technologie Kubernetes et sur la manière de rendre des applications accessibles via des objets de service et des ingress.
En l’état, je vais juste faire un ingress associé à un certificat pour exposer l’API Ollama sur l’URL interne https:\\ollama.coolcorp.priv afin de rendre celle-ci accessible pour solliciter, depuis mon réseau, les modèles LLMs hébergés sur ollama.
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-ollama-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- ollama.coolcorp.priv
secretName: sec-ollama-cert
rules:
- host: ollama.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-ollama-default
port:
number: 11434
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: cert-ollama-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
dnsNames:
- ollama.coolcorp.priv
commonName: ollama.coolcorp.priv
secretName: sec-ollama-cert
privateKey:
algorithm: RSA
size: 4096
issuerRef:
name: clusterissuer-acme2certifier
kind: ClusterIssuer

Cliquez sur l'image pour l'agrandir.
Si cette partie ne vous parle pas, sachez qu'il est tout à fait possible d'installer Ollama localement sur votre poste de travail. Vous pouvez continuer la suite du tutorial même avec une instance Ollama écourant sur votre localhost
À l’origine de cet article, j’aurais souhaité exploiter un serveur MCP conteneurisé pour l’intégrer sur mon cluster K8S. L’idée aurait été d’avoir un triptyque Ollama, OpenWebUI, MCP Serveur où je puisse interagir avec le modèle LLM de mon choix hébergé sur Ollama à travers l’UI de OpenWebUI avec une sollicitation du serveur MCP au besoin.
Malheureusement, je n’ai pas trouvé de serveur MCP compatibles avec cet usage…ou du moins, je n’ai pas réussi à implémenter ce que je voulais au vu de mes compétences limitées.
Tiny Agent
J’ai toutefois évalué la fonction MCP intégré à Tiny Agent de Hugging Face.
Hugging Face est une société franco-américaine fondée en 2016 à Paris (mais son siège actuel est à New York). Elle s’est spécialisée dans la manipulation des LLMs en concevant et en proposant en open source beaucoup de bilibothèques Python (Transformers) destinés à simplifier l’usage de modèles comme GPT, LLaMA, Mistral…
Elle fournit également des jeux de données pour entrainer des IA. Hugging Face propose aussi des services d’hébergement destinés à la publication et aux tests autour des LLMs.
C’est une entreprise avec une forte vision communautaire qui s’est donnée comme mission de rendre l’IA plus accessible et plus ouverte.
Elle propose dans sa collection d’outils un agent compatible MCP appelé Tiny Agent.
En fait, l’agent Tiny embarque le client d’inférence de Huggin Face avec une extension MCP. Celle-ci lui permet d’exécuter des serveurs MCP avec les modules associés.
Tiny Agent est nativement proposé en JS, mais une extension Python est disponible pour l’utiliser en CLI depuis son poste.
Dans la doc de Tiny Agent on peut, voir la référence à un mode server à travers le parametre serv.
C’est ce que j’ai essayé de faire en conteneurisant l’application à travers un simple docker file
FROM node:20-slim
# Définir le répertoire de travail
WORKDIR /app
# Installer le CLI Tiny Agents
RUN npm install -g @huggingface/[email protected]
# Copier le fichier de config (ou monté plus tard via ConfigMap)
COPY agent.json ./agent.json
# Port d'exposition du serveur HTTP
EXPOSE 8000
# Commande par défaut pour lancer l'agent
CMD ["tiny-agents", "serve", "/app"]
Malheureusement, a date de l’écriture de cet article et dans la version 0.2.3 de Tiny Agent, ce mode n’est pas supporté.

Cliquez sur l'image pour l'agrandir.
Cela impose une interaction avec la GUI du poste sur lequel est exécuté Tiny Agent, ce qui le rend incompatible en l’état avec un hébergement Kubernetes.
Mais ce n’est pas bloquant pour tester le produit. On peut justement s’appuyer sur le module python et tenter un usage depuis son PC Windows. Nous allons simplement configurer Tiny Agent pour qu’il exploite l’API ollama venant tout juste d'être rendue accessible à travers un ingress pour le pilotage du LLM de notre choix.
Pour simplifier, Tiny Agent va reprendre le role de Claude Desktop et OneMCP de l’exemple précédent, sauf qu’au lieu d’envoyer les requêtes pour traitement sur les serveurs d’Anthropic, il va les relayer sur Ollama.
Pour commencer, il faut déployer les prérequis sur son poste.
Les commandes ci-dessous sont pour W11, mais vous pouvez exploiter d’autres OS, comme MAC ou Linux.
Il faut installer nodeJS.
powershell winget install -e --id OpenJS.NodeJS.LTS
Cliquez sur l'image pour l'agrandir.
Ensuite, on récupère l’intégration avec Python (ce qui nécessite bien entendu d’avoir Python sur son poste: la 3.10 au minimum).
pip3 install “huggingface_hub[mcp]>=0.33.0”

Cliquez sur l'image pour l'agrandir.
Avant de lancer la commande tiny-agent, on va préparer sa configuration.
Tout passe par un fichier agent.json.
Voici un exemple complet.
{
"model": "qwen3:8b",
"endpointUrl": "https://ollama.coolcorp.priv/v1",
"servers": [
{
"type": "stdio",
"config": {
"command": "npx",
"args": ["@playwright/mcp@latest"]
}
},
{
"type": "stdio",
"config": {
"command": "npx",
"args": [
"@modelcontextprotocol/server-filesystem@latest",
"D:\\"
]
}
},
{
"type": "stdio",
"config": {
"command": "npx",
"args": [
"@modelcontextprotocol/server-filesystem@latest",
"M:\\Films"
]
}
},
{
"type": "stdio",
"config": {
"command": "npx",
"args": ["mcp-server-kubernetes"]
}
}
]
}
On peut décortiquer les sections.
On commence par préciser l’URL de notre instance Ollama en indiquant le modèle LLM qu’on souhaite solliciter.
"model": "qwen3:8b",
"endpointUrl": "https://ollama.coolcorp.priv/v1",
(Si vous avez installé ollama localement il vous suffit de pointer vers http://localhost:11434/v1).
Puis, on crée une section par serveur MCP qu’on souhaite charger.
Par exemple, je vais reprendre l’intégration avec le filesystem. On peut créer plusieurs configuration par emplacement ciblé avec lequel on souhaite que son IA puisse agir (dans mon CAS D:\ et M:\Films).
{
"type": "stdio",
"config": {
"command": "npx",
"args": [
"@modelcontextprotocol/server-filesystem@latest",
"D:\\"
]
}
},
{
"type": "stdio",
"config": {
"command": "npx",
"args": [
"@modelcontextprotocol/server-filesystem@latest",
"M:\\Films"
]
}
},
J’ajoute également le module MCP playwright pour le pilotage d’un navigateur.
"type": "stdio",
"config": {
"command": "npx",
"args": ["@playwright/mcp@latest"]
}
Ne nous arrêtons pas en si bon chemin, ajoutons le module MCP pour le pilotage d’un cluster Kub 😊.
{
"type": "stdio",
"config": {
"command": "npx",
"args": ["mcp-server-kubernetes"]
}
}
Pour obtenir une liste de tous les serveurs MCP potentiels, vous pouvez faire un tour ici. C’est certes moins sexy que OneMCP, mais tout aussi puissant.
Attention, chaque module MCP peut venir avec sa configuration à positionner dans le fichier de configuration agent.json.
Une fois le paramétrage terminée, on peut exécuter l’agent en précisant l’emplacement du fichier de configuration.
tiny-agents run "C:\Applications\ia\tiny-agent
Dès le lancement, tiny-agent va lister toutes les actions possibles propres aux modules MCP.
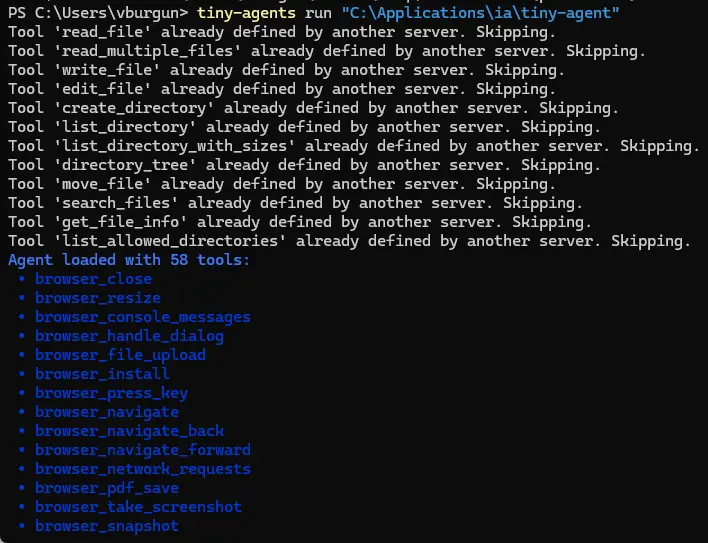
Cliquez sur l'image pour l'agrandir.
On peut donc commencer à jouer 😊.
Par exemple, on peut reprendre la création d’un fichier sur son filesystem.
Dès la requête, l’agent réfléchi, sollicitant Ollama et donc le GPU du nœud Kubernetes sur lequel tourne Ollama.
Dans mon exemple, j’ai retenu le LLM qwen3:8b. C’est un modèle open source développé par Alibaba et réputé pour son optimisation. On exploite ici la version à 8 milliards de parametres (presque le maximum utilisable pour un GPU avec 12 Go de vRAM)
On peut observer que la création de mon fichier est bien réalisée.
De même je peux interroger l’agent pour obtenir des informations sur le contenu d’un répertoire.
La preuve en est que le serveur MCP intégré à Tiny Agent est fonctionnel et que tout se passe sur mon réseau, sans aucune sollicitation de tiers.
Continuons avec, par exemple, une demande de lister mes namespaces de mon cluster K8S puisque j’ai chargé le module MCP K8S.
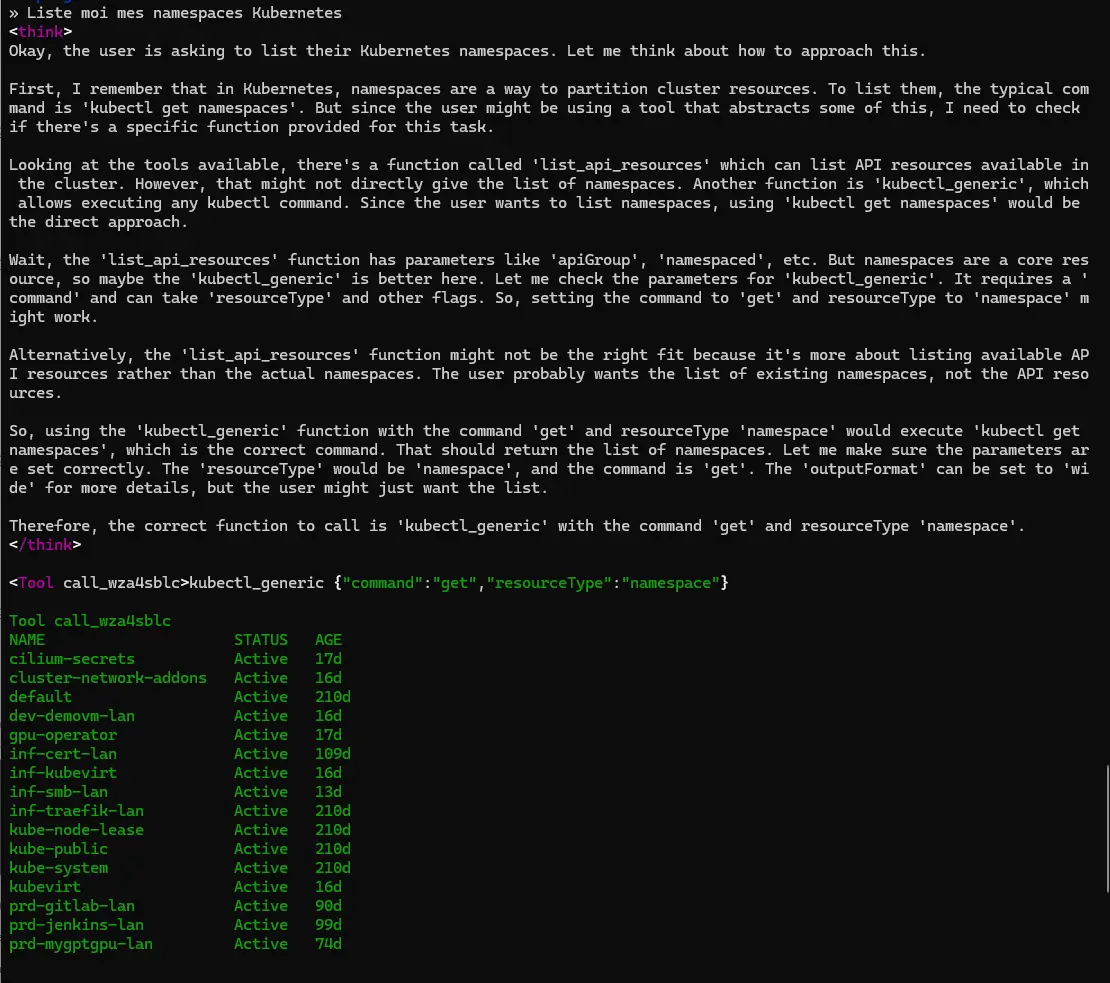
Cliquez sur l'image pour l'agrandir.
Là aussi cela fonctionne.
Si on poursuit avec la manipulation du browser, on va dire que l’expérience est moins concluante.
Alors oui, j’arrive à faire en sorte que l’agent lance mon browser et commence à y réaliser des actions, mais rapidement, l’agent IA rend la main ou se perd dans ses actions.
La raison est la puissance limitée dont je dispose dans mon lab. Le GPU sous-jacent à Ollama est un modeste Nvidia 3060TI avec 12Go de vRAM, ce qui me limite dans la taille des modèles LLMs que je peux utiliser.
J’ai essayé de modifier mon fichier de configuration agent.json pour demander à tiny agent de solliciter un modèle plus robuste à 24 milliards de paramètres. Mais dans ce cas un simple « bonjour » à travers le prompt ne réagit qu’après plusieurs minutes.
J’avais déjà essuyé ce type de problème dans mes précédents articles sur l’IA. Pour MCP, la puissance des LLMs nécessaires dépend des modules utilisés et des actions à accomplir. Il me serait par exemple impossible de refaire l’exemple du PowerPoint avec mon matériel actuel.
Conclusion
MCP est clairement un standard en pleine adoption et qui laisse présager de très belles choses pour l’IA. Il n’est pas le seul sur le marché, et d’autres protocoles, comme A2A (Agent2Agent), plus orientés vers la communication entre IA, sont en train de préparer l’écosystème des agents IA. MCP se démarque déjà par les nombreux modules disponibles.
L’expérience avec des services en lignes est déjà intéressante, l’usage en local déjà un peu plus complexe.
Mais les choses évoluent rapidement. Les outils s’améliorent, ce qui rend l’UX plus agréable. De plus, les avancées en matière de hardware vont certainement rendre l’utilisation de gros modèles LLM plus efficace, meme localement.
NVIDIA a déjà annoncé sa puce GB10 sur architecture ARM en partenariat avec Mediatek, promettant l’exécution de modèle LLMs jusqu’à 200 milliards de paramètres dans un format de mini PC.
Cliquez sur l'image pour l'agrandir.
Asus et MSI sont d’ailleurs de l’aventure avec leur propre produit basé sur la puce avec des prix d’achat démarrant à 3000$. C’est certes un prix déjà élevé, mais qui commence sérieusement à rendre accessible l’IA locale, sans parler des fameux NPU (Neural Processor Unit) intégrés au CPU moderne pour accélérer l'inférence.
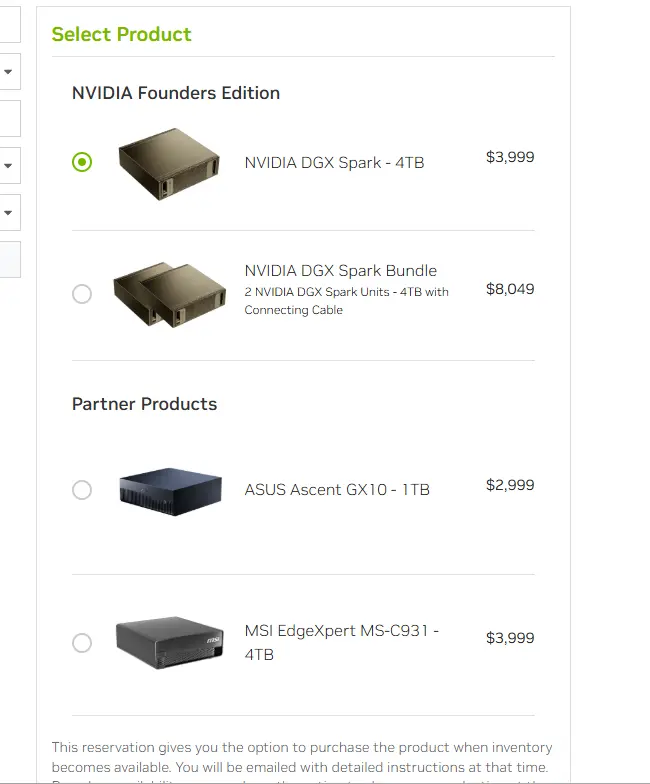
Cliquez sur l'image pour l'agrandir.
À l’avenir, il est fort possible que les entreprises, comme les particuliers, puissent bénéficier localement d’une puissance de traitement suffisamment élevé pour exploiter des agents IA exécutant des actions de tous les jours via des serveurs MCP… j’ai hâte 😊.