Analyser son code avec l’IA – Part 1: Découverte d’Oasis
Introduction
CI/CD, IA, GPU, Conteneur, Cybersécurité ne sont pas uniquement des termes marketing que désormais tout bon cabinet de conseil se doit de maitriser…
Pour un ingénieur et un passionné de technologies, ce sont avant tout des outils, du matériel, des méthodes et des savoir-faire utiles à appliquer dans son travail pour répondre aux mieux aux exigences de ses missions.
Il est temps de tirer parti de plusieurs articles disponibles sur ce site et de rassembler les morceaux pour proposer une illustration complète et factuelle de ce qu’il est possible de faire aujourd’hui avec tout ce vocabulaire.
L’objectif va être de construire une pipeline Jenkins, déclenchable sur un évènement de push dans un repo Gitlab afin de récupérer le code associé pour l’analyser via différents modèles LLM (Large Language Model). Le tout s’exécutant sur un nœud Kubernetes disposant d’un GPU pour optimiser l’exécution des moteurs IA.
Le repo est hébergé dans GitLab.
Gitlab utlise un webhook pour prévenir Jenkins d'exécuter la pipeline.
Le dossier est hébergé sur un volume NFS
Jenkins exécute une commande Oasis.
Oasis sollicite Ollama pour utiliser les modèles LLM disponibles. Le GPU du serveur est utilisé.
Les rapports sont récupérables dans le dossier partagé ou par une interface web, en PDF, html ou markdown
Pour mieux appréhender les explications et les actions à venir, il est conseillé de prendre connaissance de divers articles déjà publiés.
Le CI/CD à travers l’usage de Gitlab et Jenkins va servir à automatiser les actions et simplifier les analyses:
- Article sur l’installation de Jenkins
- Article sur l’installation de GitLab
- Article sur l'intéraction entre Jenkins et Gitlab
L’IA va permettre d’identifier rapidement les failles du code et de proposer des corrections:
Le GPU va servir à rendre les temps d’analyse raisonnable et de pouvoir utiliser des modèles LLMs avancés:
L’intérêt d’utiliser des conteneurs à travers Kubernetes est de pouvoir capitaliser sur la modularité et la scalabilité de la plateforme.
Je ferais souvent référence à ces liens, car ils contiennent déjà certaines explications et différents exemples utiles pour mieux appréhender ce qui va suivre. Je vais d'ailleur souvent réutiliser des éléments associés.
En ce qui concerne la cybersécurité, je vais présenter l’outil Oasis, un scanneur de vulnérabilité de code open source conçu pour exploiter une instance Ollama.
Mais avant de se lancer dans l’aventure, voici, comme à mon habitude un schéma résumant la cible à atteindre.
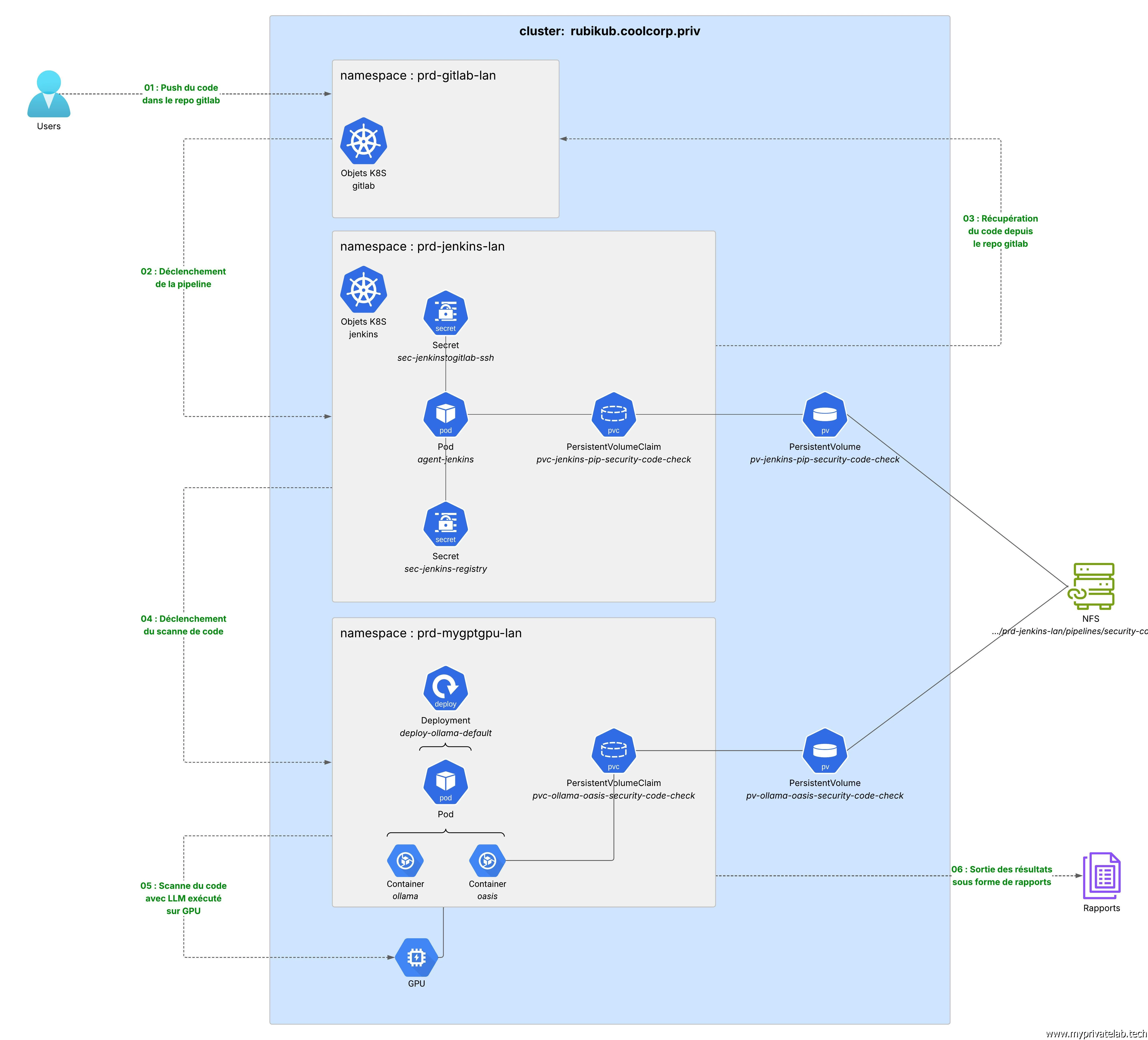
Cliquez sur l'image pour l'agrandir.
Il ne détaille pas tous les composants, mais exprime l’essentiel des objets à manipuler et les interactions entre les éléments (texte en vert).
Il s'agit pour moi de présenter une des approches possibles, reposant sur mon lab perso et reprenant certains déploiements déjà faits par le passé. Libre à chacun d’adapter, de corriger ou d’améliorer ce qui est proposé en fonction de ses propres besoins.
Oasis
Pour effectuer une analyse du code, nous utiliserons l’outil Ollama Automated Security Intelligence Scanner, également connu sous son abréviation, OASIS. C’est un logiciel open source disponible gratuitement depuis son repo GitHub.

Cliquez sur l'image pour l'agrandir.
Il s’appuie sur la plateforme open source Ollama, qui permet de faire fonctionner localement des modèles d’intelligence artificielle (LLM) tels que LLaMA 2, LLaMA 3, Mistral et Gemma, grâce à une interface de ligne de commande simple ou à une API.
J’ai déjà eu l’occasion de présenter Ollama dans cet article. Je vais d’ailleurs m’appuyer sur l’instance (et sur le serveur) que j’avais déployés dans le cadre de ce tutoriel.
Comme OpenWebUI que j’évoque également dans ma publication, Oasis va communiquer avec Ollama pour tirer parti des modèles LLM qu’il héberge.
Il va utiliser ces derniers pour analyser le code qu’on lui aura soumis afin d’identifier les problématiques de cybersécurité potentielles et générer un rapport complet sur le sujet.
Oasis peut exploiter beaucoup des moteurs d’IA qui auraient été installés sur Ollama.
Principes
Oasis va procéder en deux étapes. D’abord il va s’appuyer sur un LLM « light » pour une analyse rapide du code, puis va enchainer sur une analyse plus profonde pour cibler ce qui aurait été identifié lors de la première passe. Lors de ce second passage, Oasis va pouvoir exploiter un LLM plus avancé, mais aussi plus consommateur de ressources.
C’est là que va servir le GPU et notamment le tutoriel permettant d’utiliser une carte graphique au sein d’un cluster Kubernetes.
Oasis peut même soumettre le code à davantage de LLM pour croiser les résultats et obtenir une analyse encore plus fine.
Il va pouvoir détecter plusieurs types de vulnérabilités, comme les failles XSS, les SQL injection, l’usage de code d’exécution à distance, les problèmes d’authentifications et même l’usage de données sensible, comme un password ou un token.
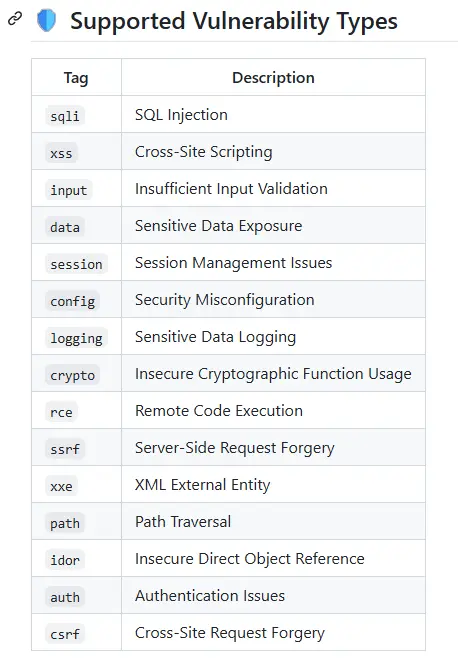
Cliquez sur l'image pour l'agrandir.
Le projet reste néanmoins très jeune à l’heure de rédaction de cet article. Sa première release date de Janvier 2025.
Oasis s’exécute sous forme d’une commande spécifique prenant différents arguments et nécessite Python pour fonctionner.
Par défaut, il n’y a pas d’installation conteneurisée disponible ; on doit donc récupérer l’application directement depuis le dépôt.
Oasis permet de générer plusieurs rapports de scans dans différents formats, tels que PDF ou HTML. En option il est possible de les exposer via un serveur web (Flask).
Création de l'image Docker
Je vais créer une image Docker de l’application pour l’exécuter sur le cluster Kubernetes sur lequel tourne Ollama.
L’écriture du Dockerfile n’est pas compliquée. Il suffit de reprendre les commandes d’installation donnée sur le GitHub.
# Utiliser une image Python officielle
FROM python:3.13.3
# Installer les dépendances nécessaires
RUN apt-get update && apt-get install -y git && rm -rf /var/lib/apt/lists/*
# Installer pipx et s'assurer qu'il est accessible
RUN python -m pip install --upgrade pip \
&& python -m pip install pipx \
&& python -m pipx ensurepath
# Définir les variables d'environnement pour pipx
ENV PIPX_HOME=/root/.local
ENV PATH="${PIPX_HOME}/bin:${PATH}"
# Cloner le dépôt et installer Oasis
WORKDIR /app
RUN git clone https://github.com/psyray/oasis.git \
&& cd oasis \
&& pipx install --editable .
# Script d'entrée pour garder le conteneur actif
CMD ["oasis", "-i", "/nfs/security_reports", "-w", "-we", "all", "-wp", "8080"]
On part d’une image Python, on y installe les dépendances nécessaires, puis on récupère le code Oasis.
Pour que le conteneur puisse tourner, il faut donner, en dernière instruction du Dockerfile, la commande à exécuter pour lancer le process qui déterminera que le conteneur est en vie.
En l’occurrence, on lance la commande oasis, en lui indiquant où générer ces reports (/nfs/security_reports) et avec l’exécution du serveur web intégré écoutant sur le port 8080.
C’est grâce à ce serveur web que le conteneur ne va pas s’arrêter. Si on se contente de la commande oasis, celle-ci est lancée et, comme rien n’est passé en source pour analyser le code, elle se terminerait aussitôt en mettant fin au conteneur. C’est un peu une astuce pour laisser le conteneur tourner, on n’aurait pu utiliser une commande fictive comme CMD ["tail", "-f", "/dev/null"] si on ne souhaitait pas utiliser le serveur web.
Ceci reste une proposition qui peut amener à des optimisations...par exemple utiliser un user dédié...à chacun de constuire l'image qui lui convient le mieux.
On peut compiler cette deniere avec la commande:
docker build -t oasis-container .
Cliquez sur l'image pour l'agrandir.
De mon coté, je la pousse ensuite sur ma registry:
docker tag oasis-container registry.gitlab.com/apps.coolcorp.priv/oasis:oasis-dck-4.0
docker push registry.gitlab.com/apps.coolcorp.priv/oasis:oasis-dck-4.0
Cliquez sur l'image pour l'agrandir.
Intégration à Ollama
La seconde étape va consister à modifier mon Deployment de Ollama pour qu’il inclue Oasis.
Il serait possible de faire tourner oasis dans un Deployment séparé, puis de lui indiquer avec un argument l’url de Ollama, mais, pour mon usage, je souhaite l’intégrer au Pod Ollama et simplifier ainsi la communication.
Attention, choisir cette stratégie implique d’avoir autant d’instances d’Oasis que d’instance de Ollama avec les deux se partageant la même plage de port. Comme je travaille avec un seul répliqua, ce n’est pas un problème. Cela permettra de mettre en évidence le concept de Pod.
Je vais donc reprendre mes yamls utilisés lors de mon tutoriel pour l’installation de Ollama et OpenWebUI.
De ce fait, je vais utiliser le Namespace prd-mygptgpu-lan déja en place.
Avant de modifier l’objet Deployment de Ollama, je vais ajouter un PV (PersistentVolume) et un PVC (PersistentVolumeClaim).
En effet, l’idée est de pouvoir cloner dans un dossier le code que je souhaite scanner depuis gitlab.
Ce dossier doit être consultable par Oasis, car, lorsque la pipeline Jenkins exécutera la commande de scanne depuis le conteneur Oasis, il sera nécessaire de spécifier un argument de chemin. Cet argument doit pointer vers le répertoire contenant le code à analyser.
On va donc utiliser un volume NFS, lui-même relié à un PV appelé par un PVC et utilisé par le pod contenant le conteneur Oasis. Si vous n’êtes pas à l’aise avec le concept de stockage sous K8S n’hésitez pas à lire mon article issu de mon cookbook Kubernetes ainsi que mon article sur le CSI (ContainerStorageInterface) NFS.
Je vais donc créer sur mon NAS un répertoire dédié au sujet.
En l’occurrence il se trouvera dans: /Volume1/nfsshare/rubikub.coolcorp.priv/namespaces/prd-jenkins-lan/pipelines/security-code-check/.
Cliquez sur l'image pour l'agrandir.
On génère un pv exploitant le CSI NFS et pointant vers ce dossier via le fichier 03-pv-ollama-oasis-security-code-check:
---
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: nfs.csi.k8s.io
name: pv-ollama-oasis-security-code-check
labels:
environment: prd
network: lan
application: ollama
tier: oasis
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
driver: nfs.csi.k8s.io
volumeHandle: /Volume1/nfsshare/rubikub.coolcorp.priv/namespaces/prd-jenkins-lan/pipelines/security-code-check/oasis
volumeAttributes:
server: 192.168.10.152
share: /Volume1/nfsshare/rubikub.coolcorp.priv/namespaces/prd-jenkins-lan/pipelines/security-code-check
Puis on génère le pvc rattaché via le fichier 04-pvc-ollama-oasis-security-code-check.yml:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-ollama-oasis-security-code-check
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: ollama
tier: oasis
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 30Gi
volumeName: pv-ollama-oasis-security-code-check
storageClassName: ""
On applique les deux objets avec la commande: kubectl apply -f nom_yaml.yaml

Cliquez sur l'image pour l'agrandir.
Il faut maintenant rajouter ce pvc ainsi que l’appel à l’image d’oasis dans mon Deployment associé à Ollama.
Je ne vais pas revenir sur tous les objets K8S utilisé pour Ollama. Je vous invite à lire mon article dédié ou à récupérer mes fichiers sur mon GitHub.
Ici, je n’ai qu’à toucher au fichier 05-deploy-ollama-default.yml (appelé 03-deploy-ollama-default.yml dans le tutoriel d’origine).
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-ollama-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
replicas: 1
selector:
matchLabels:
environment: prd
network: lan
application: mygpt
tier: ollama
template:
metadata:
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ollama
image: ollama/ollama:0.6.5
resources:
limits:
nvidia.com/gpu: 1
ports:
- containerPort: 11434
volumeMounts:
- name: pv-ollama-default
mountPath: "/root"
- name: oasis
image: registry.gitlab.com/apps.coolcorp.priv/oasis:oasis-dck-8.0
ports:
- containerPort: 8080
volumeMounts:
- name: pv-jenkins-pip-security-code-check
mountPath: "/nfs"
imagePullSecrets:
- name: sec-mygptgpu-registry
volumes:
- name: pv-ollama-default
persistentVolumeClaim:
claimName: pvc-ollama-default
- name: pv-jenkins-pip-security-code-check
persistentVolumeClaim:
claimName: pvc-ollama-oasis-security-code-check
Au niveau des spécifications, j’ai ajouté la référence à l’image Oasis (ici la v8) que nous venons de créer. Étant donné qu’elle est hébergée sur ma registry privée, il faut également que je précise le secret sec-mygptgpu-registry qui contient mes credential d’accès dans la section « imagePullSecrets:».
J’y ajoute également l’appel au pvc nouvellement créé que j’utilise comme point de montage /nfs au niveau de mon conteneur oasis.
Je précise le containerPort 8080 pour la partie serveur web.
Rien d’autre n’est nécessaire.
À titre d’information, j’attire votre attention sur l’usage de l’option nvidia.com/gpu: 1 déjà en place et associé au conteneur ollama. Pour mieux appréhender ce point, n’hésitez pas à faire un tour ici.
Le GPU reste associé à ollama. Ce n’est pas directement Oasis qui analyse le code, mais bien le ou les LLM présents sur ollama qui sont pilotés par Oasis.
Je peux ainsi mettre à jour mon Deployment Ollama (kubectl apply -f ...).
En vérifiant avec la commande: kubectl get pod -n prd-mygptgpu-lan

Cliquez sur l'image pour l'agrandir.
Tests et premiers résultats
On se connecte dans le contexte du second container, à savoir Oasis à l’aide de la commande:
kubectl exec -it deploy-ollama-default-86754968cb-6z4gl -c oasis -n prd-mygptgpu-lan -- bash
De là on peut vérifier que le volume est bien mappé ( df -h ).

Cliquez sur l'image pour l'agrandir.
Étant donné qu’on est dans le contexte du conteneur Oasis, autant tester son fonctionnement.
Pour ce faire, j’ai créé un répertoire « repo » dans mon dossier partagé NFS, qui est monté dans le conteneur. J’y ai ensuite déposé un fichier demo.py , issu d’une sortie de ChatGPT, dans lequel j’ai demandé un bout de code Python avec des failles.
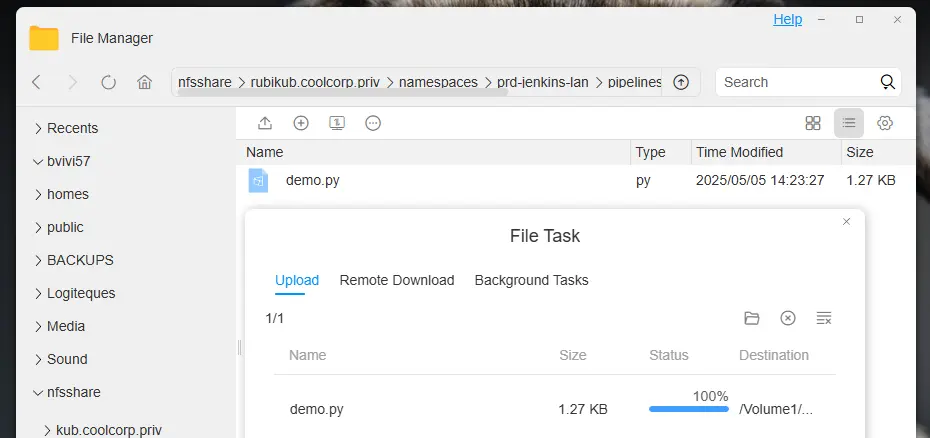
Cliquez sur l'image pour l'agrandir.
Voici son contenu:
import subprocess
import sqlite3
import requests
# ❌ 1. Donnée sensible codée en dur
API_KEY = "sk_test_51Lx0fFakeSecretHardcodedKey123456"
# ❌ 2. Mot de passe codé en dur
DB_PASSWORD = "P@ssw0rd123"
# ❌ 3. Requête SQL vulnérable à l'injection
def get_user_info(username):
conn = sqlite3.connect("users.db")
cursor = conn.cursor()
# ⚠️ Injection SQL possible ici
query = f"SELECT * FROM users WHERE username = '{username}'"
cursor.execute(query)
result = cursor.fetchall()
conn.close()
return result
# ❌ 4. Exécution de commande shell avec une entrée non filtrée
def run_ping(host):
# ⚠️ Command injection possible ici
cmd = f"ping -c 4 {host}"
subprocess.call(cmd, shell=True)
# ❌ 5. Requête HTTP sans vérification SSL
def send_data(data):
# ⚠️ Transmet potentiellement des données sensibles en clair
response = requests.post("http://insecure.example.com/api", data=data, verify=False)
return response.status_code
# Appels de test
if __name__ == "__main__":
username = input("Enter username: ")
print(get_user_info(username))
host = input("Enter host to ping: ")
run_ping(host)
send_data({"api_key": API_KEY, "data": "some sensitive info"})
Dans le contexte du conteneur Oasis tentons d’analyser ce code via la commande:
oasis -i /nfs/repo -sm gemma3:4b -m llama3:8b --clear-cache-scan --vulns all
Cela déclenche immédiatement le scan.
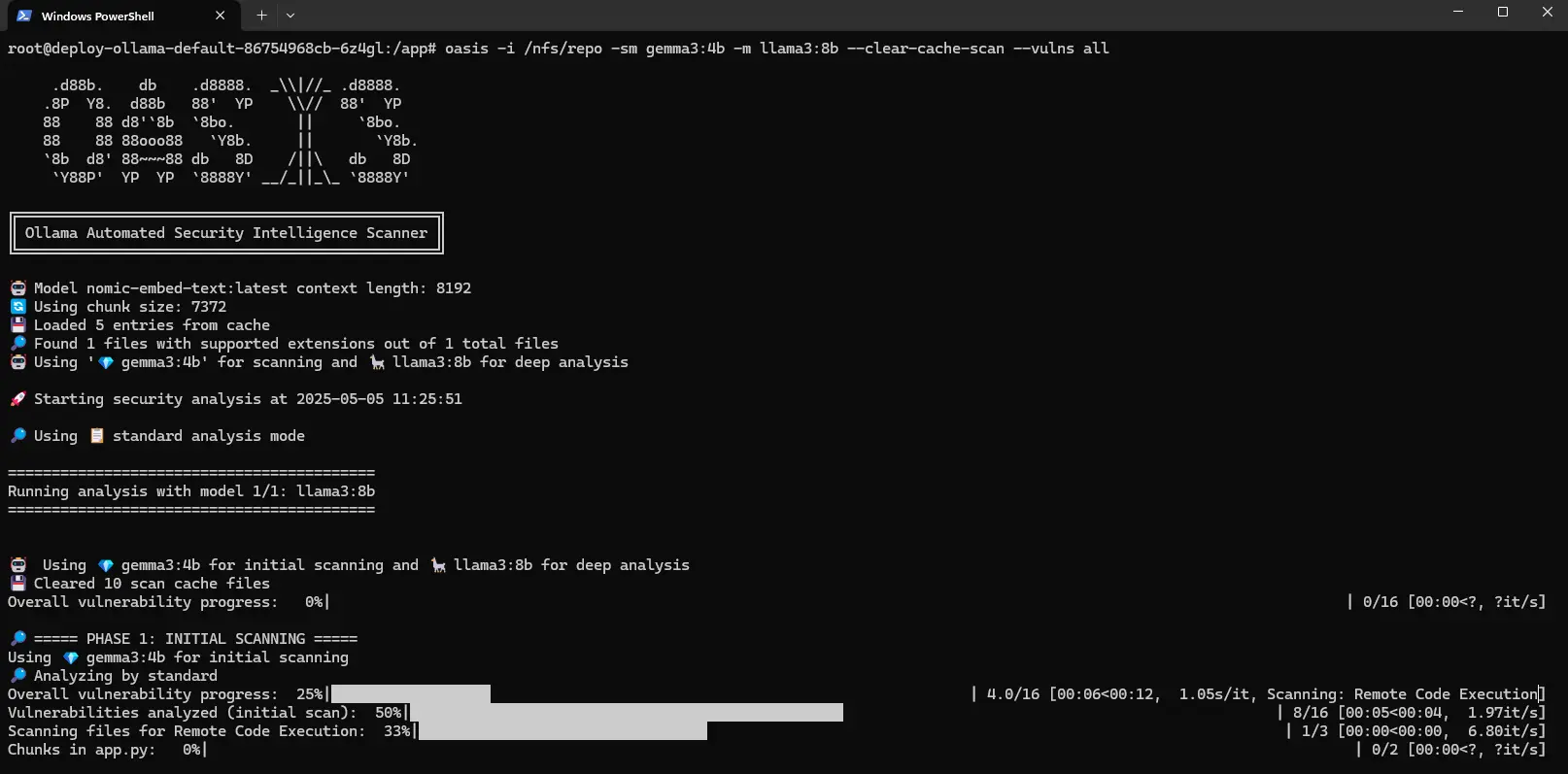
Cliquez sur l'image pour l'agrandir.
Dans la commande, on utilise d’abord le modèle LLM gemma3:4b pour réaliser l’analyse rapide (-sm), puis on passe au modèle llama3:8b pour l’analyse approfondie (-m), tout en demande à oasis d’ignorer le cache potentiel issu de scans précédents (--clear-cache-scan) et de faire une analyse de toutes les vulnérabilités (--vulns all).
Oasis partageant le même pod que Ollama, il n’y a pas besoin de préciser l'adresse de l'API de ce dernier
Pendant l’analyse, on peut observer sur le nœud K8S sur lequel le Pod Ollama est exécuté que le GPU est fortement sollicité (commande: nvtop, n’hésitez pas à relire mon article sur l’intégration du GPU sous Kubernetes).
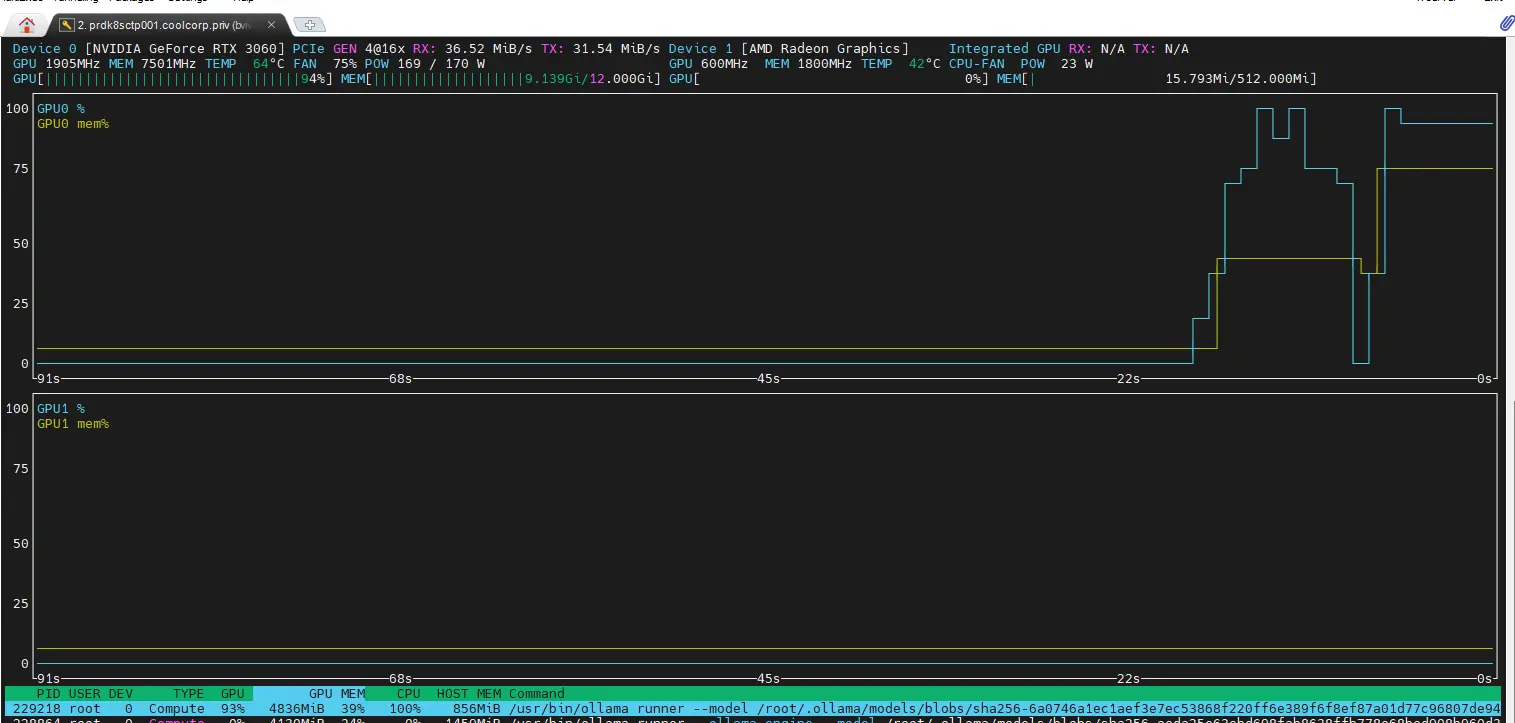
Cliquez sur l'image pour l'agrandir.
En fin de scan, Oasis nous indique qu’il a généré un ensemble de rapports.
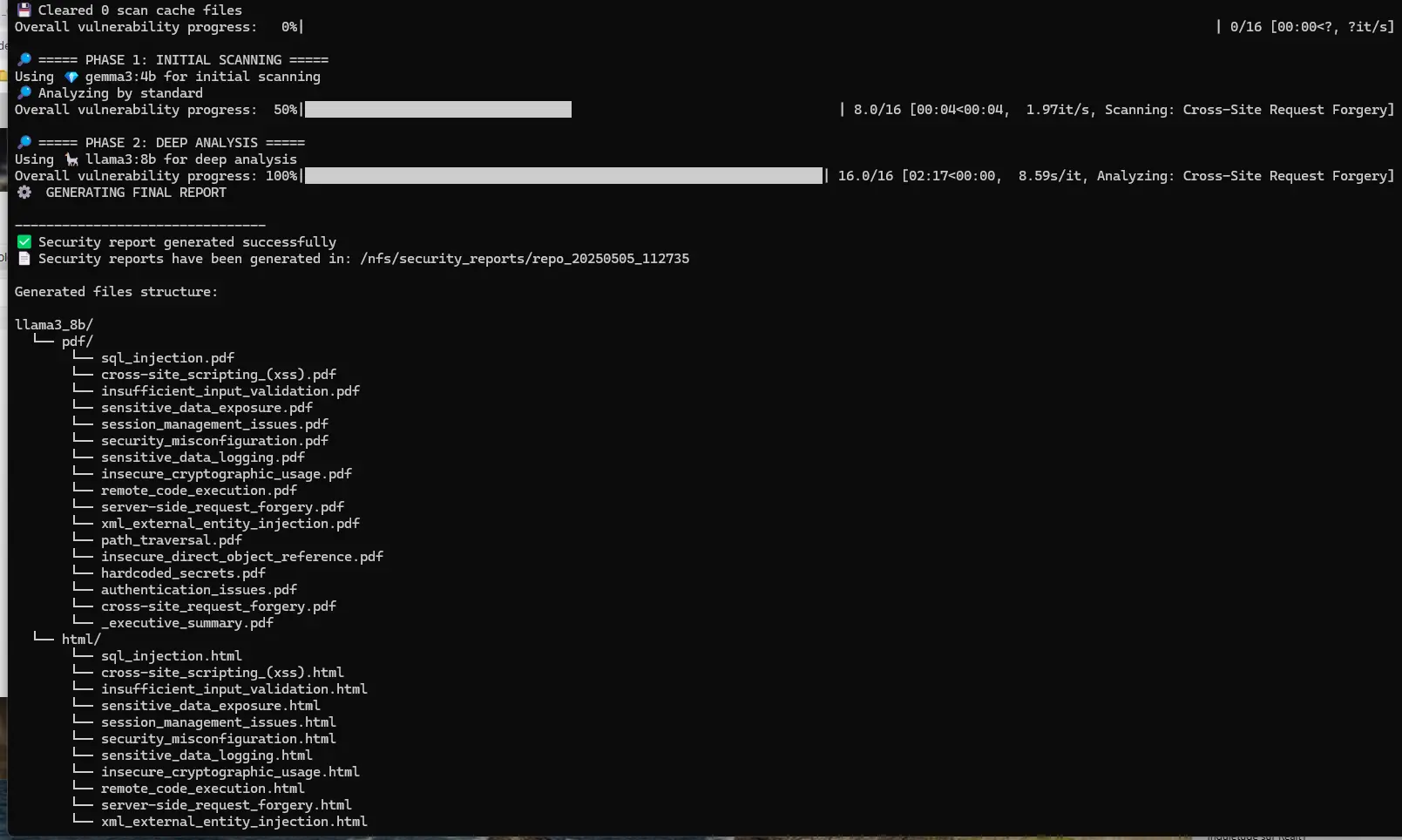
Cliquez sur l'image pour l'agrandir.
Rapports disponibles sur le volume NFS, dans un sous-dossier créé automatiquement « security_reports ».
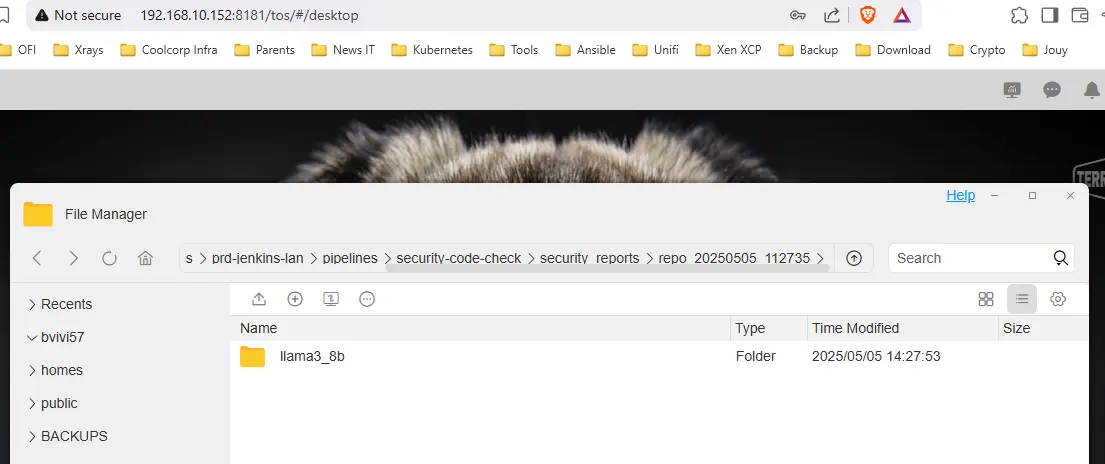
Cliquez sur l'image pour l'agrandir.
On peut naviguer à l’intérieur de l’arborescence pour, par exemple, récupérer tous les reports au format pdf.
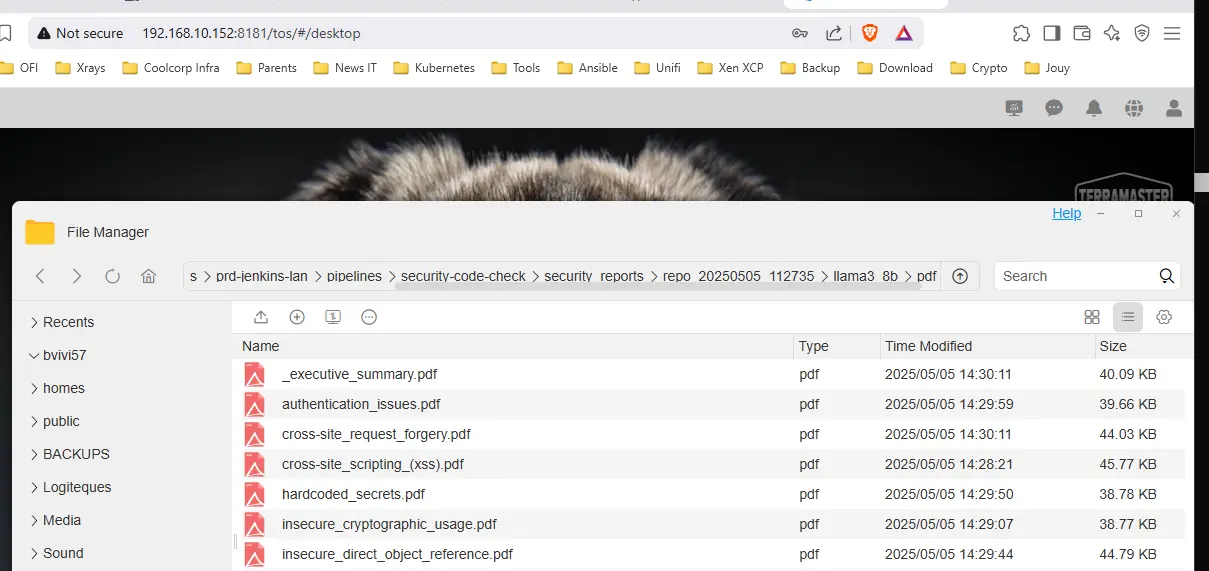
Cliquez sur l'image pour l'agrandir.
Une fois rapatrié sur son poste de travail, on peut les parcourir en commençant par _executive_summary.pdf.
On peut voir dans l’exemple que Oasis a détecté 16 failles.
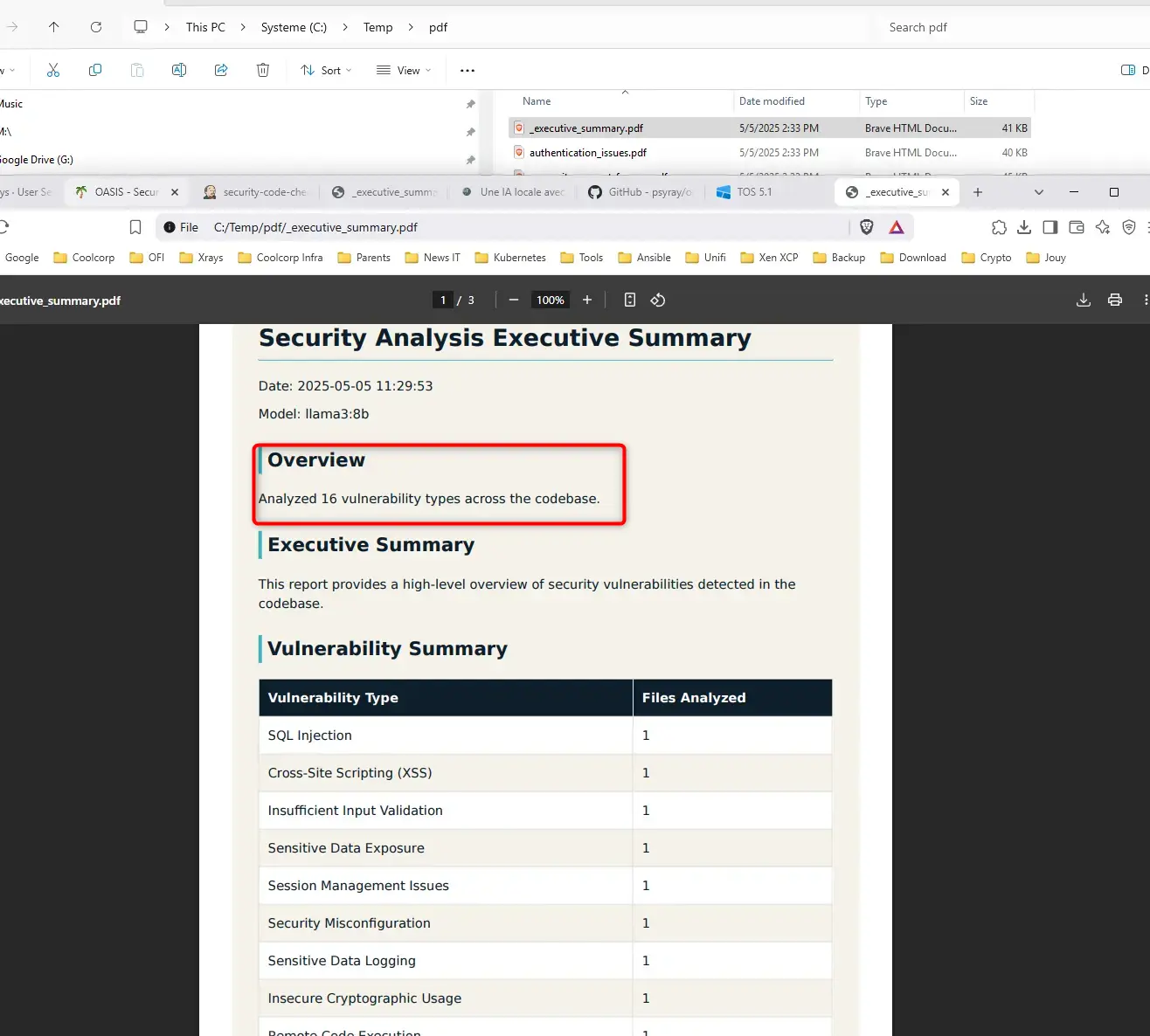
Cliquez sur l'image pour l'agrandir.
Pour chacune d’elles, il est possible d’obtenir le détail associé via l’ouverture du PDF dédié.
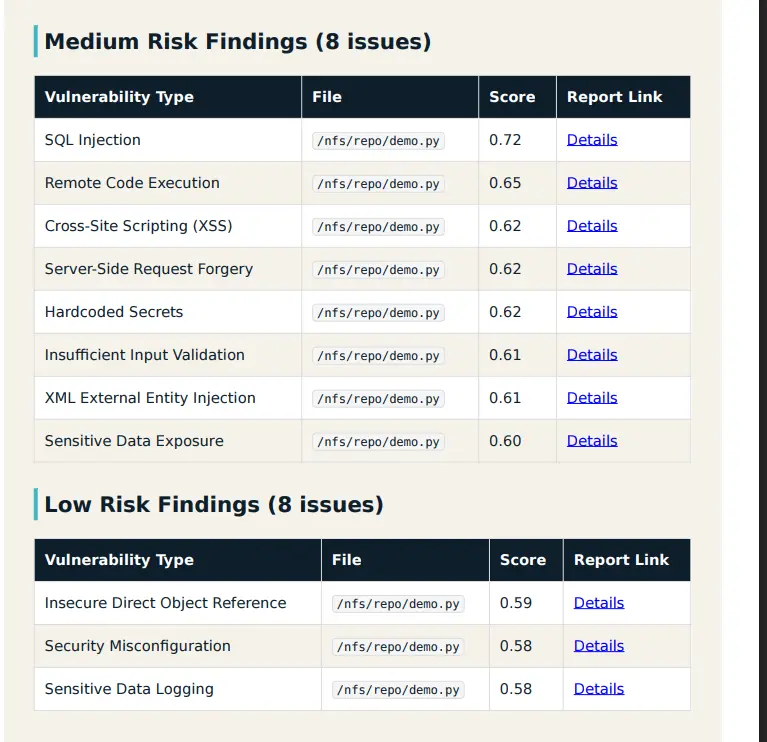
Cliquez sur l'image pour l'agrandir.
On y retrouve ensuite l’explication de la faille ainsi que des recommandations pour la corriger.
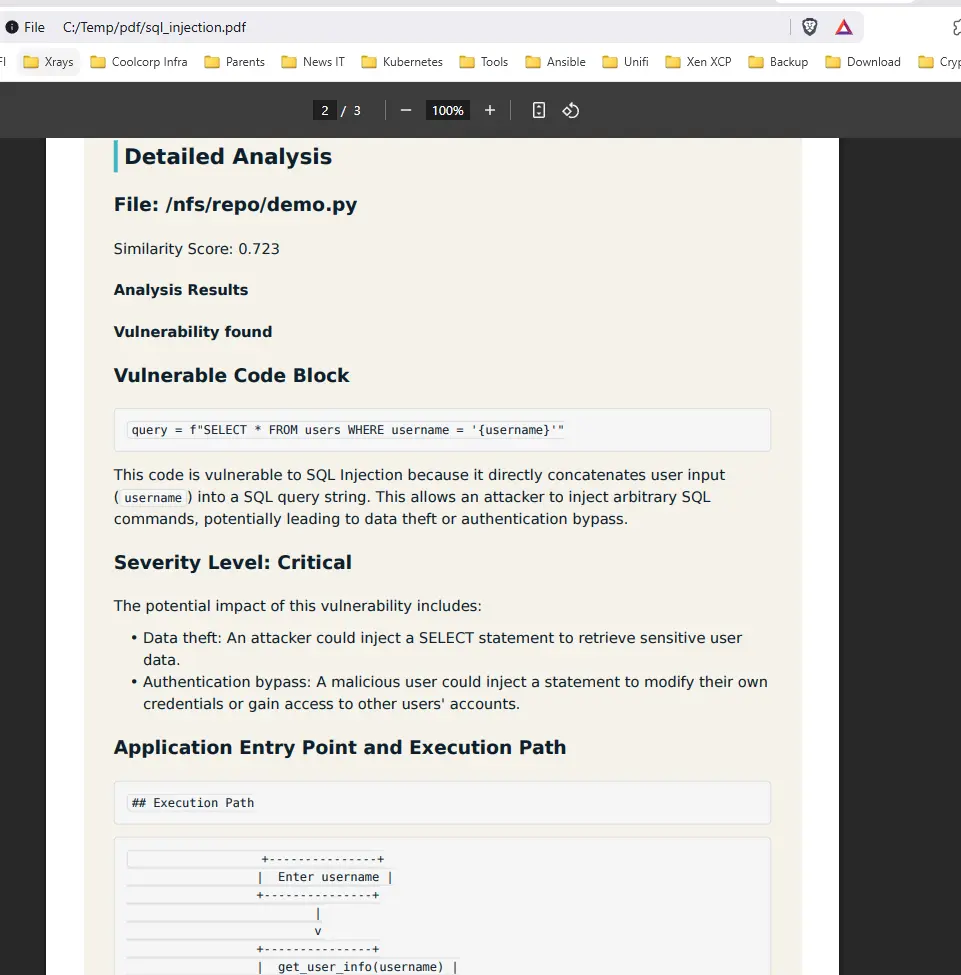
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
On dispose ainsi d’un ensemble de reports nous permettant d’avoir une vue complète de la sécurité de son code.
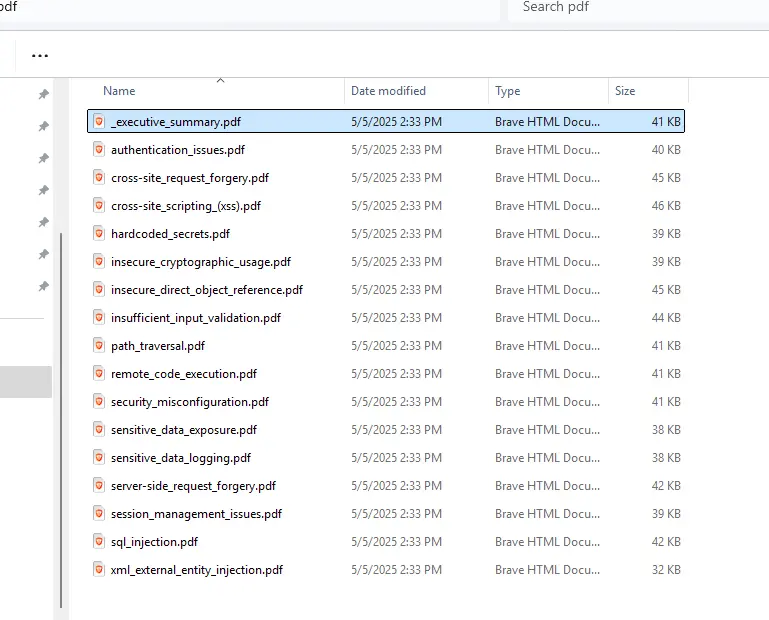
Cliquez sur l'image pour l'agrandir.
À noter que, dans l’exemple j’ai utilisé deux modèles LLMs:
- gemma3:4b - Le modèle allégé de Google issue de Gemini avec un poid de 4 milliards de parametres
- llama3:8b - Le modèle Meta (Facebook) avec un poid de 8 milliards de parametres
Ces derniers doivent être disponibles sous Ollama. Si ce n’est pas le cas, ils sont récupérés automatiquement par Oasis.
On peut d’ailleurs le vérifier en se connectant cette fois-ci non plus dans le conteneur oasis, mais dans le conteneur par défaut ollama via la commande:
kubectl exec -it deploy-ollama-default-86754968cb-6z4gl -n prd-mygptgpu-lan -- bash
Avec l’instruction ollama list, on peut obtenir l’ensemble des LLM disponible: on y retrouve bien ceux que l’on a sollicités à travers Oasis.
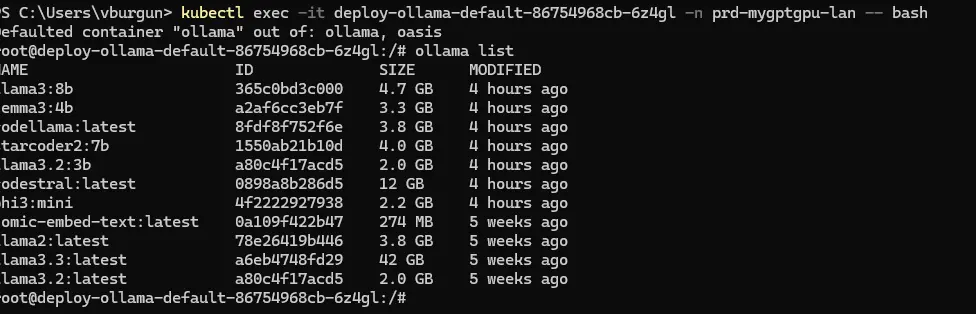
Cliquez sur l'image pour l'agrandir.
C’est d’ailleurs un point fort de la solution, puisque, fonction des besoins, des capacités hardware et du type de code on peut solliciter tel ou tel modèle. On trouve quelques recommandations directement sur le GitHub d’Oasis pour vous orienter vers le choix d’un LLM plutôt qu’un autre fonction de vos attentes.
Dans mon exemple, j’ai pris une combinaison qui permet de traiter tous types de codes avec une consommation raisonnable en ressources. C’est une analyse généraliste, peut-être pas optimisée pour un langage donné, mais qui n’utilise pas non plus des modèles très puissants qui pourraient saturer ma carte graphique (une modeste 3060 TI).
On voit déjà que les résultats sont très satisfaisants.
Interface web
Il reste le cas de l’interface web. Pour l’instant nous avons récupéré les reports depuis l’interface du NAS.
Or, notre conteneur oasis s’exécute avec l’instance web.
Pour y accéder, il faut d’abord générer classiquement un objet type Service et un objet type Ingress.
Ces principes vous sont expliqués dans mon cookbook sur Kubernetes.
Concernant le Service, je vais simplement modifier l'existant svc-ollama-default pour lui ajouter le port 8080 que nous avons déclaré dans le conteneur oasis.
Je modifie mon fichier 06-svc-ollama-default.yml (voir mon tuto sur Ollama).
---
kind: Service
apiVersion: v1
metadata:
name: svc-ollama-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
ports:
- name: ollama
port: 11434
protocol: TCP
targetPort: 11434
#Ajout de l'exposition du serveur Web d'Oasis
- name: oasis
port: 8080
protocol: TCP
targetPort: 8080
selector:
environment: prd
network: lan
application: mygpt
tier: ollama
Puis je réapplique le service (kubectl apply -f ...).

Cliquez sur l'image pour l'agrandir.
Enfin, je crée un nouvel objet ingress via le fichier 12-ing-ollama-oasis.yml.
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-ollama-oasis
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: oasis
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- oasis.coolcorp.priv
secretName: sec-oasis-cert
rules:
- host: oasis.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-ollama-default
port:
number: 8080
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: cert-oasis-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: oasis
spec:
dnsNames:
- oasis.coolcorp.priv
commonName: oasis.coolcorp.priv
secretName: sec-oasis-cert
privateKey:
algorithm: RSA
size: 4096
issuerRef:
name: clusterissuer-acme2certifier
kind: ClusterIssuer
Celui-ci permet d’exposer Oasis via l’URL https://oasis.coolcorp.priv.. J’y ajoute un certificat automatiquement généré via Cert-Manager. (Ici aussi je vous invite à lire mon article dédié à Cert-Manager ainsi que mon article sur l'obtention automatique d'un certificat à partir d'une PKI interne).

Cliquez sur l'image pour l'agrandir.
Via cette méthode (et en n’oubliant pas de créer l’enregistrement DNS associé), je peux arriver a accéder l’interface web d’Oasis.
Celle-ci me demande un password. Pour obtenir cette information, je dois consulter les journaux de démarrage du conteneur à l’aide de la commande kubectl logs deploy-ollama-default-86754968cb-6z4gl—c oasis—n prd-mygptgpu-lan
Par défaut, le password est généré aléatoirement au démarrage du serveur web. Il est possible de le fixer dans les arguments associés à oasis. Il faudrait pour cela modifier le Dockerfile et regénérer une image.
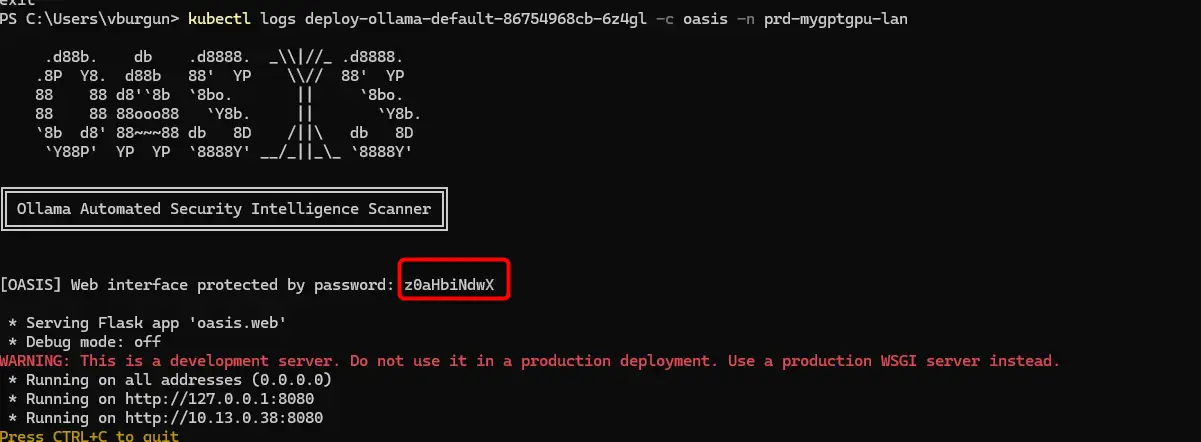
Cliquez sur l'image pour l'agrandir.
La partie web demeure un « plus », mais son utilisation n’est pas encore parfaite au moment de l’écriture de l’article. Il est d’ailleurs spécifié que son usage est réservé exclusivement au développement. Il faudrait revoir cette partie pour l’optimiser.
Néanmoins, on peut déjà avoir une idée de l’interface en testant l’accès à l’URL avec le mot de passe généré.
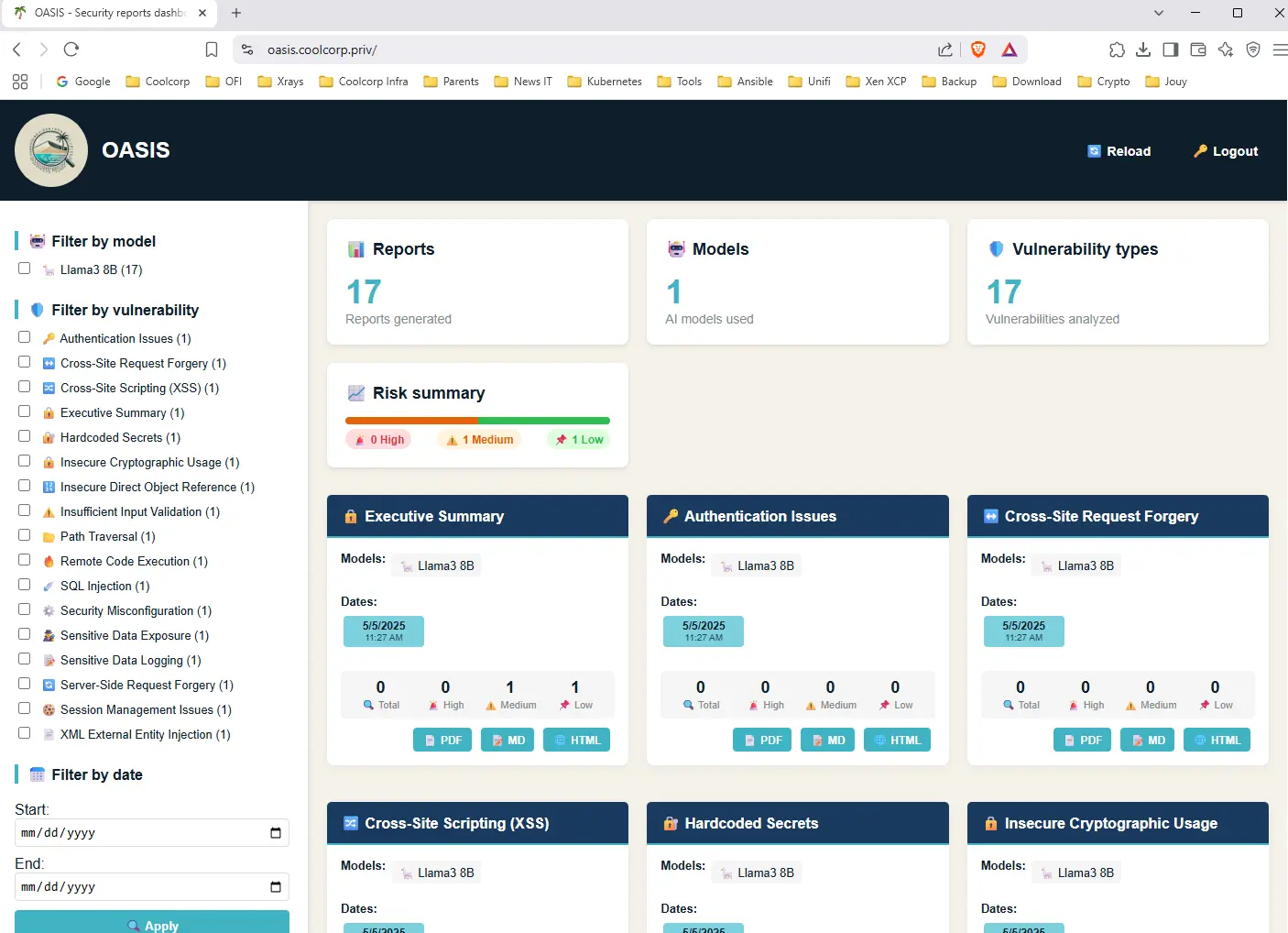
Cliquez sur l'image pour l'agrandir.
On peut récupérer directement les rapports par cette méthode avec la possibilité de filtrer par type de faille, par moteur utilisé et par date.
Cliquez sur l'image pour l'agrandir.
Conclusion
C’est la fin de cette première partie.
Celle-ci nous aura permis de mettre en place les briques de base pour intégrer Oasis à un déploiement Ollama existant.
À ce stade, on peut déjà percevoir les avantages qu’un tel type d’intégration peut amener. Encore une fois, grâce à l’écosystème open source et au talent de certains développeurs généreux, on peut obtenir un outillage extrêmement puissant.
En combinant différentes configurations, en tirant parti de son expertise et de son infrastructure existante, on peut donner un peu de concret à tous ces discours "technobullshitmarketing" où le buzz l'emporte trop souvent sur le besoin et la réalité du terrain.
Il reste maintenant à automatiser un peu tout ça pour rendre l’exploitation du scan plus simple et l’intégrer dans une chaine de CI/CD: la suite ici.