Définition K8S : Le Deployment
Introduction
Un Deployment est un objet de l’API kubernetes. Son « shortname » est deploy et sa description complète peut être trouvée ici .
Principes
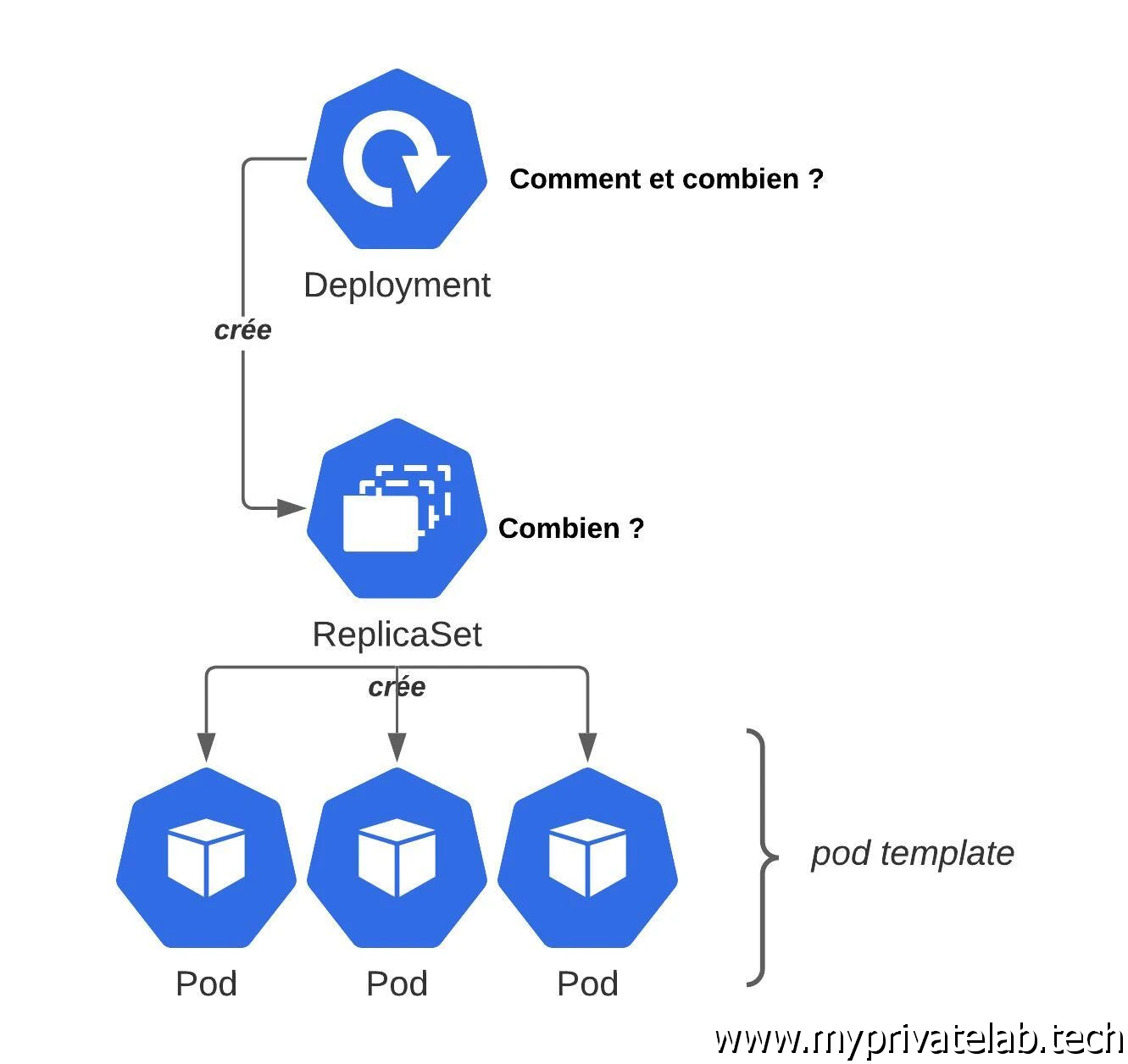
Un pod peut être exécuté en l’état et permet de déclarer un ou plusieurs conteneurs. Il reste cependant un objet basique dont on doit gérer la stratégie de déploiement.
C’est justement l’objectif de l’objet Deployment. Comme son nom l’indique, il permet de gérer la manière dont on souhaite voir son pod être déployé (mais pas que).
C’est un objet extrêmement puissant qui a pris progressivement le pas sur les ReplicaSet, qui bien que toujours présent sont de moins en moins sollicités directement, mais exploité à travers les Deployments (un Deployment venant créer des ReplicaSet).
Le Deployment se déclare dans un fichier yaml et va nécessiter une section pod template. Vous allez indiquer au Deployment quoi faire avec son pod template : combien d’instances de ce template vous voulez et comment gérer ses mises à niveau.
Voici un exemple d’un fichier de Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-demodeployment-defaut
namespace: dev-demodeployment-lan
labels:
environment: dev
network: lan
application: demodeployment
spec:
replicas: 3
strategy:
type: Recreate
selector:
matchLabels:
environment: dev
network: lan
application: demodeployment
template:
metadata:
labels:
environment: dev
network: lan
application: demodeployment
spec:
nodeSelector:
network: lan
containers:
- name: demo-nginx-deployment
image: nginx:1.27
Si l’on se penche un peu de dessus, on peut observer plusieurs choses, notamment le nombre de repliqua souhaité du pod déclaré dans la section pod template.
replicas: 3
Pour respecter ce besoin, le module contrôleur de Kubernetes va utiliser les paramètres présents dans la section selector.
selector:
matchLabels:
environment: dev
network: lan
application: demodeployment
Kubernetes se base sur la notion de label pour fonctionner. Dans notre exemple, chaque pod disposant des labels:
- environment: dev
- network: lan
- application: demodeployment
est considéré comme 1 replica.
Cela implique que le ou les labels que vous utilisez comme selector doivent se retrouver impérativement dans les metadatas du pod déclarées dans la partie template…sinon vous risquez d’avoir un problème.
Ce modèle permet également de rattacher des pods précédemment lancés à un Deployment. Imaginez que vous ayez déployé un pod directement, sans passer par un objet Deployment. Si vous décidez d’avoir plusieurs instances de ce même pod et de finalement exploiter un Deployment, dans le cas ou votre pod en cours d’exécution dispose déjà des labels nécessaires, il sera comptabilisé comme un replica existant. Si par exemple vous configurez votre Deployment avec 3 répliqua et qu’un pod existe déjà avec les bons labels, Kubernetes ne va instancier que deux nouveaux pod.
À noter que le champ Selector permet des conditions de sélection multiples qui peuvent être basées sur des logiques combinatoires (et/ou..).
Cliquez sur l'image pour l'agrandir.
Manipulations et exemple
Une fois votre déploiement rédigé il est très facile de le lancer via la simple commande:
kubectl apply -f mon-deployment.yaml

Cliquez sur l'image pour l'agrandir.
Vous pouvez lister vos déployment avec la commande:
kubectl get deployment

Cliquez sur l'image pour l'agrandir.
Dans notre exemple, si on demande la liste des pods, on retrouve bien 3 instances de notre application.

Cliquez sur l'image pour l'agrandir.
Vous pouvez également suivre le statut de vos déploiements avec la commande:
kubectl rollout status deployment mon-deployment

Cliquez sur l'image pour l'agrandir.
Gestion du cycle de vie
Un Deployment ne s’arrête pas qu’à la capacité de gérer le nombre de replica (en construisant des objets type ReplicaSet). Il vous permet également de gérer la manière dont vous allez mettre à jour vos applications.
Imaginons que vous avez déployé une application reposant sur l’usage du serveur web NGINX dans sa version 1.25 avec 3 replicas et que vous souhaitez basculer en 1.26. Il y’a alors deux possibilités:
- Utiliser une stratégie Recreate: dans ce cas vous souhaitez stopper vos 3 pods en v1.25 en même temps pour les redéployer aussi tôt en v1.26. C’est efficace, mais vous allez avoir un arrêt de service puisque tous les replica (donc vos pods) seront arrêtés en même temps.
- Utiliser une stratégie RollingUpdate: dans ce cas vous souhaitez procéder à la montée de version, pod par pod. D’abord le premier est coupé puis basculé en V1.26, une fois up, vous passez au second puis au troisième. C’est plus long, mais vous aurez toujours au moins un pod actif durant toute l’opération de mise à jour, donc aucune interruption de service. C’est d’ailleurs pour ça que si vous ne précisez rien dans votre fichier de déploiement, Kubernetes appliquera par défaut la méthode RollingUpdate.
L’objet Deployment vous permet d’agir de manière beaucoup plus fine sur la stratégie de cycle de vie de vos applications.
En ajoutant une section strategy dans votre yaml vous pouvez préciser vos attentes , par exemple ne pas utiliser la méthode RollingUpdate, mais Recreate.
spec:
replicas: 3
strategy:
type: Recreate
Ou alors conserver la méthode RollingUpdate,, mais en demandant à kubernetes de ne pas créer plus qu’un certain nombre de pod à la fois (maxsurge) ou à l’inverse d’imposer toujours un certain nombre de pod actif durant le déploiement (MaxUnavailable) (ces deux données peuvent être renseignées en % ou en nombre).
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
Tout cela n’est que la partie émergée de l’iceberg, car en combinant d’autres objets,options et addon, on peut arriver à proposer des stratégies de déploiement encore plus poussées comme le pattern Canary Relase consistant à mettre en œuvre la nouvelle version de votre application qu’à un nombre limité d’utilisateurs. Vous avez alors une montée en charge progressive pour vous donner le temps de tester la nouvelle révision de votre développement. Mais ce n’est pas le but de cet article.
Update et rollbak
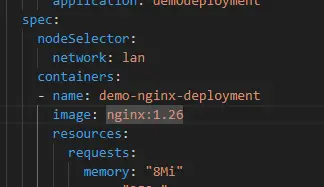
Pour passer en v1.26, on peut reprendre l’exemple du yaml en début d’article puis simplement modifier la version de l’image dans la section pod template.
Cliquez sur l'image pour l'agrandir.
Puis rappeler la commande:
kubectl apply -f mon-deployment.yaml

Cliquez sur l'image pour l'agrandir.
Le fichier ayant été modifié, vous obtenez en sortie la reponse configured, indiquant que Kubernetes a détecté le changement et a procédé à une mise à jour du deployment en redéployant les pods associés.
A l'inverse si vous tapez à nouveau la commande:
kubectl apply -f mon-deployment.yaml
Sans avoir changer d'élements, le retour sera alors unchanged.
Vous allez pouvoir suivre l’historique de vos déploiements avec la commande:
Kubectl rollout history mon-deployment

Cliquez sur l'image pour l'agrandir.
Si vous souhaitez passer maintenant en v1.27, vous pouvez procéder à la même opération en mettant à jour la version de votre image dans votre yaml, puis à nouveau appliquer le changement.
kubectl apply -f mon-deployment.yaml
Cette fois-ci vous pouvez compléter votre commande précédente avec:
Kubectl annotate deployment mon-deployment kubernetes.io/change-cause="info sur le changement"

Cliquez sur l'image pour l'agrandir.
Dans ce cas, non seulement vous retrouverez l’itération de votre changement dans l’historique de vos deployement, mais associé à un commentaire indiquant davantage d’informations sur ce changement.
Kubectl rollout history mon-deployment

Cliquez sur l'image pour l'agrandir.
Vous notez que la commande annotate ne vient préciser que le dernier déploiement.
Mais vous pouvez ainsi multiplier les changements et à chaque fois indiquer ce qui a été modifié en annotation.
Vous arriverez ainsi à tracer vos déploiements.

Cliquez sur l'image pour l'agrandir.
Allons encore un peu plus loin, imaginons qu’un incident ait lieu suite à l’une des mises à jour.
Il est urgent de revenir au plus vite à la situation précédente. Dans ce cas vous pouvez utiliser la commande:
kubectl rollout undo deployment mon-deployment

Cliquez sur l'image pour l'agrandir.
Vous reviendrez ainsi à votre “version précédente”.
Poursuivons les hypothèses, en partant du principe que vous ayez fait plusieurs updates consécutives et que vous vous êtes perdu en route. Rien n’empêche de revenir à une version spécifique de votre déployment via la commande:
kubectl rollout undo deployment mon-deployment --to-revision=1

Cliquez sur l'image pour l'agrandir.
Dans notre exemple, on pourrait à chaque fois revenir sur le fichier yaml et l’éditez pour indiquer la version de l’image du conteneur à utiliser. Dans des cas plus complexe ou vous avez plusieurs conteneurs dans votre pod, que vous avez potentiellement modifié plus de choses que simplement la version de l’image (les commandes, les ports exposés, les metadata….) ou que vous n’ayez pas « giter » votre fichier, la commande kubectl rollout, peut vous sauver la vie.
Sans compter qu’une fois revenu à votre révision, vous pouvez utiliser la commande:
kubectl get deployment mon-deployment -o yaml
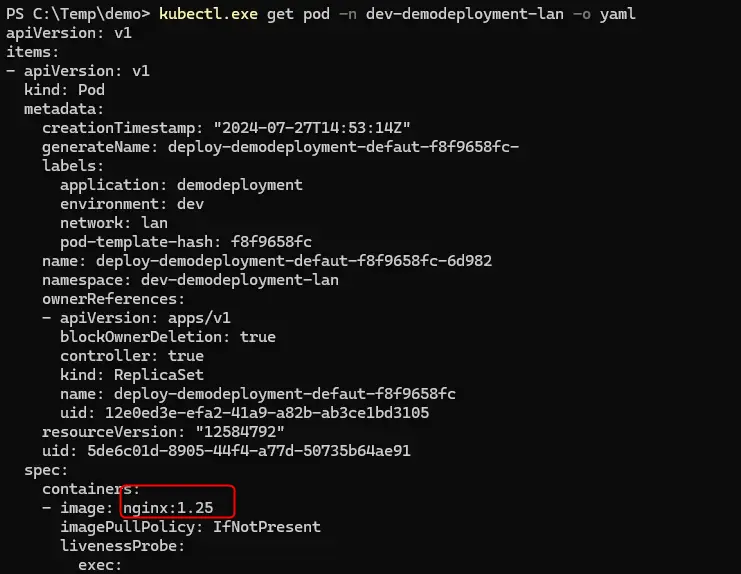
Cliquez sur l'image pour l'agrandir.
Pour réobtenir le yaml correspondant à votre déploiement actuel. Très pratique pour reconstruire son yaml si jamais celui-ci était perdu. (a noter que cette astuce fonctionne avec pratiquement tous les objets)
C’est d’ailleurs un point d’attention. Vous pouvez agir avec Kubernetes à travers des fichiers yaml ou via des commandes directement, voir meme éditer certains parametres avec la commande kubectl edit.
Lorsque vous manipulez un objet Kubernetes directement en CLI sans passez par un yaml, vous obtez pour une démarche imperative , vous donnez vos ordres instruction par instruction. A l'inverse quand vous passez par un yaml, vous obtez pour une démarche déclarative ou vous décrivez l'ensemble de l'objet.
Il est conseillé de suivre une logique déclarative mais surtout il faut éviter de mixer les deux stratégies pour un meme objet, au risque de créer un état d'incohérence sur ce dernier ou de casser les liens qu'il pourrait avoir avec d'autres objets.
Préférez garder une démarche imperative pour des cas de débug ou de test.
Si vous revenez dans l’urgence à une version de votre déploiement, mais que pour une raison ou une autre, le dernier fichier yaml utilisé ne reflète pas ce changement, si un de vos collègues se base sur celui-ci pour lancer un déploiement après vous, il est possible que vous et votre collègue n’ayez aux finales pas la même vision de la version à déployer.
C'est pouquoi dans l'exemple précédent, une fois revenu à une version donnée via la commande Kubectl rollout, l'incident étant passé, prenez le temps de remettre à jour le fichier yaml (n'oubliez pas l'option -o yaml de la commande kubectl get si nécessaire) et de repasser par un déploiement déclarative.
Conclusion
L’objet Deployment est parmi les plus puissants et intéressants de l’API kubernetes. Je vous encourage à ne jamais passer par un objet pod directement en dehors de besoin de tests ou débug, pour toujours encadrer vos pod par un Deployment.