Intégration d'un GPU dans une plateforme Kubernetes avec cas d'usage IA
Introduction
Après la hype du minage de cryptomonnaie de 2021, les GPU (Graphical Processor Unit) associés aux cartes graphiques connaissent désormais une autre raison de se vendre par palette de mille: l’IA.
Si à l’origine, les GPU étaient prévus pour donner vie aux univers 3D de nos jeux vidéo, ils sont employés à bien d’autres usages aujourd’hui.
Leur architecture optimisée pour des calculs massivement parallèles s’avère être particulièrement efficace pour traiter des opérations matricielles et vectorielles.
Or ce type de manipulations mathématiques est utilisé dans certains algorithmes d’IA, notamment les fameux LLM (large language model) qui font le succès des ChatGPT like actuels.
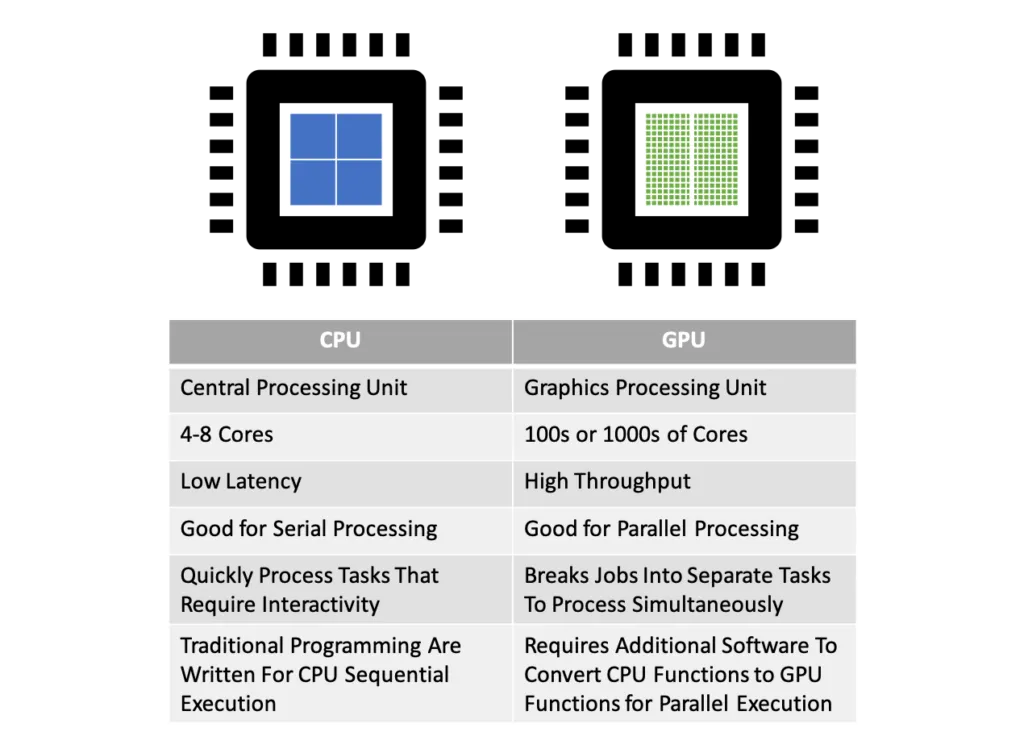
Les GPU sont bien supérieurs à nos CPU (Central Processor Unit) quand il s’agit d’opérer un même type de calcul simple, mais simultanément sur un grand jeu de données de même type.
Cliquez sur l'image pour l'agrandir.
Cela tombe très bien, car pour les modèles LLM, on a ce type de besoin et cela se fait en deux phases:
- Phase d’entrainement: la plus consommatrice, très gourmande en calcul ou l’algorithme va concevoir un modèle à partir d’une quantité énorme de données.
- Phase de consultation ou d’inférence: basé sur le modèle créé dans la phase précédente, l’objectif est de générer des prédictions (ou des réponses) sur sollicitation de l’utilisateur.
Pour la première phase, ça peut être complexe de concevoir un modèle avec du matériel traditionnel.
Tout va dépendre du type de données utilisées et de l’objectif du modèle, mais pour des cas comme ChatGPT qui se veut être un modèle généraliste, la puissance de calcul nécessaire est énorme.
Ce sont des milliers de GPU qui vont être sollicités, et pas n’importe lesquels. Tous les GPU n’ont pas les mêmes performances, et dans le cadre de modèles comme chatGPT, la phase d’entrainement sollicite des GPU spécialisés très haut de gamme optimisés pour l’IA…avec des prix d’acquisition très élevés et une forte consommation énergétique.
Pour la seconde phase, il devient possible de rendre la chose plus accessible. La puissance nécessaire va être liée aux modèles utilisés, mais également aux nombres de sollicitations auxquelles il devra répondre. Bien entendu pour ChatGPT on reste sur des proportions industrielles, puisque ce sont des millions d’utilisateurs à travers le monde qui infèrent le modèle en permanence.
Dans le cas d’un usage déconnecté, où le modèle est présent localement avec peu de personnes le sollicitant en parallèle, il devient possible d’exploiter du matériel beaucoup plus raisonnable.
J’ai décrit dans un article précédent l’usage des produits open sources Ollama et OpenWebUI pour bénéficier d’un chatGPT like privatif, capable d’exploiter différents modèles préentrainés et disponibles gratuitement.

Cliquez sur l'image pour l'agrandir.
Le résultat s’est montré positif à travers un déploiement sous Kubernetes sur un nœud physique. Seulement la performance n’est pas formidable, car mon serveur exploite uniquement un CPU et dispose d’une configuration très modeste.
J’ai décidé de passer à la vitesse supérieure et de profiter de ce cas d’usage pour détailler l’installation et la prise en charge d’un GPU par Kubernetes.
Depuis la version 1.26 de K8S il est possible d’exposer le ou les GPUs de son serveur aux pods exécutés sur le cluster.
Mais comme à son habitude, l’intégration de GPU par Kubernetes est réalisée de façon modulaire et fait appel à des composants tiers.
Principe d'usage d'un GPU sous K8S

Cliquez sur l'image pour l'agrandir.
Pour exploiter un GPU dans un pod il est nécessaire de répondre aux critères suivants:
- Disposer d’une version de Kubernetes supérieure ou égale à la 1.26. Idéalement préférer une release au moins égale à la v1.29, car beaucoup d’améliorations ont été apportées. Si vous ne savez pas comment upgrader K8S, n’hésitez pas à faire un tour ici.
- Disposer d’une carte graphique compatible. Cette liste évolue en permanence, mais oubliez les GPU intégrés au CPU. Il est nécessaire d’avoir un GPU dédié et surtout disposant d’une quantité de VRAM ( (Video RAM) la mémoire présente sur la carte et dédiée au GPU) au moins égale à 8Go si vous souhaitez vous essayez au LLM. Les constructeurs supportés sont AMD, INTEL et NVIDIA. Ce dernier étant largement leader sur le marché au moment de cet article, c’est un modèle de la marque au caméléon que je vous conseillerais, au moins de la génération RTX 2x. Mais les autres constructeurs cités fonctionnent également.
- Déployez le driver de votre carte graphique sur l’OS hébergeant le node K8S.
- Déployez le driver de votre carte graphique lié au runtime que vous utilisez pour faire tourner vos conteneurs. Si vous souhaitez en savoir davantage sur la notion de runtime, vous pouvez faire un tour ici.
- Déployez l’opérateur Kubernetes associé à votre carte graphique.
Pour résumer, il faut que votre carte graphique soit reconnue par votre système (votre OS), puis par votre moteur de conteneur afin que celui-ci puisse exposer votre GPU dès lors que l’opérateur (cette notion est détaillée plus loins dans l'article) déployé sur Kubernetes sera en mesure d’autoriser sa déclaration et sa détection dans les pods.
Votre GPU ou vos GPU seront traités au sein de Kubernetes comme une simple ressource, identique au CPU et à la mémoire qu’il vous sera possible d'assigner à vos pods.
Environnement de test
Dans mon cas, mon setup est le suivant:
Un serveur physique nommé prdk8sctp001, déployé sous Rocky Linux 9.5 disposant d’un CPU Ryzen AMD Ryzen 9 7900X, 96 GO de RAM et d’une carte Graphique NVIDIA 3060 avec 12 GO de VRAM.

Cliquez sur l'image pour l'agrandir.
Ce serveur constitue une plateforme Kubernetes unique et distincte de mon cluster classique à plusieurs nodes dont je décris l’installation ici.
Cela me permet de tester une configuration spécifique de K8S sans impacter mon cluster principal.
La version de K8S est la v1.31.3.

Cliquez sur l'image pour l'agrandir.
Ce serveur me sert à la fois de control plane et de worker node. Cela m’oblige parfois à jouer de la toleration suivante pour autoriser les composants à s’exécuter sur le serveur.
spec:
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
Par défaut, Kubernetes place un taint sur un control-plane pour éviter l’exécution des conteneurs applicatifs sur celui-ci, car dans un contexte de production le control plane est réservé à l’administration et aux contrôles du cluster.

Cliquez sur l'image pour l'agrandir.
Maintenant, pour des environnements de tests, il n’est pas rare d’avoir qu’un seul serveur devant jouer plusieurs rôles.
Dans ce cas, je ne vous conseille pas de lever le taint sur le control plane, mais plutôt d’exploiter la toleration vu juste au-dessus pour autoriser explicitement vos assets à s’exécuter sur le control plane.
Concernant la couche CNI (Container Network Interface), je reste sur Cilium. Je ne rentrerais pas dans le détail, vous trouverez davantage d’informations ici. J’ai simplement dû adapter son déploiement à une configuration mono node.
Pour ceux qui sont interessés par l'installation de Cilium sur une plateforme K8S ne disposant que d'un seul serveur servant de control plane et de worker, voici le fichier de configuration cilium-values.yaml helm employé:
kubeProxyReplacement: true
k8sServiceHost: 192.168.10.160
k8sServicePort: 6443
ipam:
mode: "cluster-pool"
operator:
clusterPoolIPv4PodCIDRList:
- "10.13.0.0/16"
hubble:
relay:
enabled: true
ui:
enabled: true
frontend:
server:
ipv6:
enabled: false
tls:
auto:
enabled: true
method: helm
certValidityDuration: 1095
operator:
replicas: 1
L'installation via helm passe par la commande suivantes:
helm install --version X.XX.X \
--namespace=kube-system cilium cilium/cilium \
--values=./cilium-values.yaml \
--set hubble.relay.tolerations[0].key="node-role.kubernetes.io/control-plane" \
--set hubble.relay.tolerations[0].operator="Exists" \
--set hubble.relay.tolerations[0].effect="NoSchedule" \
--set hubble.relay.tolerations[1].key="node-role.kubernetes.io/master" \
--set hubble.relay.tolerations[1].operator="Exists" \
--set hubble.relay.tolerations[1].effect="NoSchedule" \
--set hubble.ui.tolerations[0].key="node-role.kubernetes.io/control-plane" \
--set hubble.ui.tolerations[0].operator="Exists" \
--set hubble.ui.tolerations[0].effect="NoSchedule" \
--set hubble.ui.tolerations[1].key="node-role.kubernetes.io/master" \
--set hubble.ui.tolerations[1].operator="Exists" \
--set hubble.ui.tolerations[1].effect="NoSchedule"
C'est hors sujet, mais ça peut toujours servir.
Pour le CSI (Container Storage Interface), n’étant pas sur une plateforme virtuelle vSphere comme pour mon cluster principal, je n’ai rien utilisé d’autre que le CSI NFS. La aussi, je vous invite à vous renseigner ici.
Par contre, j’ai créé trois Storage Class (sc) locales pour tirer parti des disques SSD que j’ai positionnés sur le serveur, soit un SSD NVME et deux SSD sata, chacun étant associé à une classe de storage.
Je détaille l’usage d’une sc locale dans l’article ou j’ajoute un node physique à mon cluster de production dans le cas du premier test de Ollama. N’hésitez pas à le parcourir.
Mise en pratique
Maintenant que le décor est planté, on peut se lancer dans les hostilités. Étant donné que je travaille avec une carte graphique NVIDIA, le déploiement sera forcement associé à l’écosystème de la marque.
Pour ceux qui disposeraient d’un GPU d’un autre constructeur, vous pourrez vous inspirer de la logique globale de l’article, mais il faudra suivre les instructions propres à votre modèle de carte graphique proposé par votre fabricant.
Installation du driver sur l'OS
Pour démarrer, on installe le driver NVIDIA sur Rocky Linux 9. Vous pouvez agir en root directement ou passer par la commande sudo, mais il vous faut les droit associés. On commence par activer les repos EPEL (Extra Packages for Enterprise Linux).
Il suffit de passer les commandes suivantes:
dnf config-manager --set-enabled crb

Cliquez sur l'image pour l'agrandir.
dnf install \
https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm \
https://dl.fedoraproject.org/pub/epel/epel-next-release-latest-9.noarch.rpm

Cliquez sur l'image pour l'agrandir.
Ensuite on va également ajouter les repos de NVIDIA. On utilise la commande suivante:
dnf config-manager --add-repo http://developer.download.nvidia.com/compute/cuda/repos/rhel9/$(uname -i)/cuda-rhel9.repo

Cliquez sur l'image pour l'agrandir.
Il est nécessaire de compiler certaines sources, il faut donc récupérer toutes les dépendances associées à la compilation. Vous pouvez utiliser les commandes suivantes:
dnf install kernel-headers-$(uname -r) kernel-devel-$(uname -r) tar bzip2 make automake gcc gcc-c++ pciutils elfutils-libelf-devel libglvnd-opengl libglvnd-glx libglvnd-devel acpid pkgconfig dkms
Cliquez sur l'image pour l'agrandir.
Enfin, on peut installer le driver NVIDIA avec la commande:
dnf module install nvidia-driver:latest-dkms
Cliquez sur l'image pour l'agrandir.
Une fois l’opération terminée, il faut redémarrer le serveur.
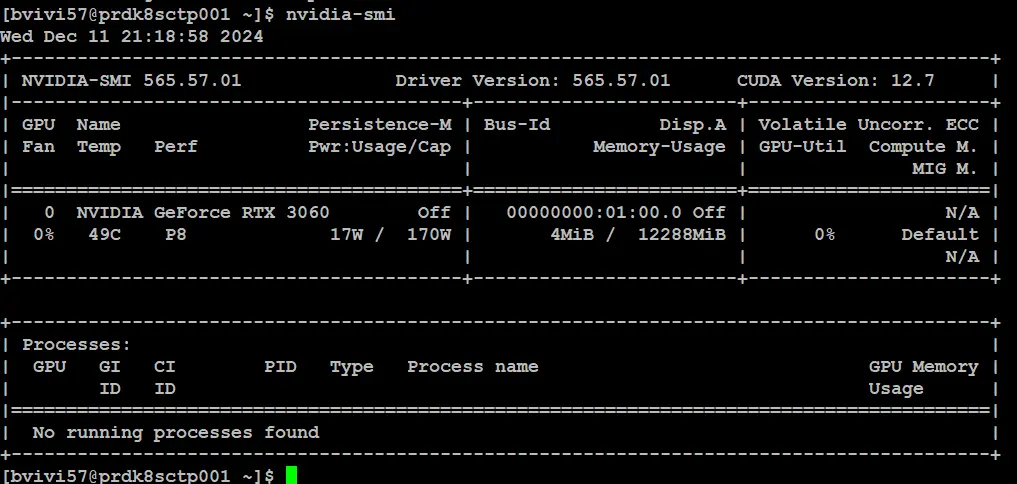
Si tout est OK, vous devriez maintenant pouvoir faire appel à l’instruction nvidia-smi. Celle-ci vous donne des informations sur le statut du GPU et sur sa consommation instantanée.
Cliquez sur l'image pour l'agrandir.
La carte étant reconnue par l’OS, on peut poursuivre par l’intégration au runtime de container.
Paramétrage de containerd
Comme pour mon cluster principal, j’utilise containerd. Attention, en l’état, on ne peut pas utiliser la branche 2 car non compatible avec NVIDIA au moment de l’écriture de l’article, j’ai donc déployé la version 1.7.24. Pour plus d’informations sur containerd, n’hésitez pas à faire un tour par là.
NVIDIA fournit un guide plutôt complet pour l’intégration de ses composants dans un cluster K8S.
On va donc suivre ce dernier et commencer par l’ajout d’un repos supplémentaire.
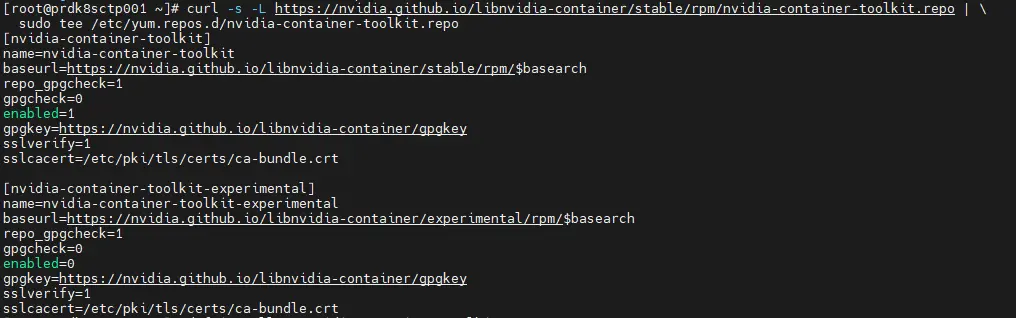
Ce repos va permettre d’installer la dépendance nvidia-container-toolkit via les commandes:
curl -s -L https://nvidia.github.io/libnvidia-container/stable/rpm/nvidia-container-toolkit.repo | \
sudo tee /etc/yum.repos.d/nvidia-container-toolkit.repo
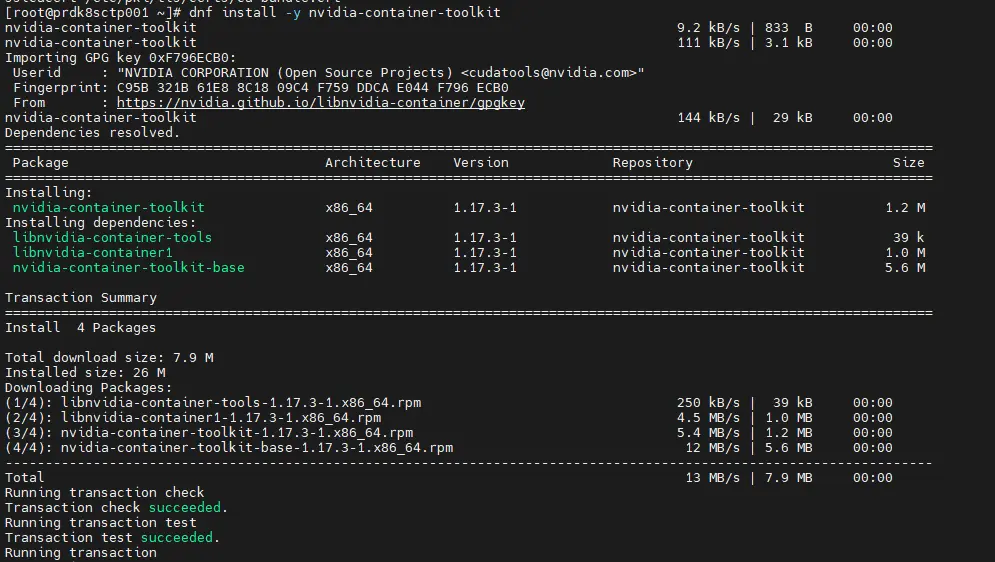
dnf install -y nvidia-container-toolkit
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Une fois installé on peut exécuter l’instruction nvidia-ctk runtime configure --runtime=containerd (toujours en root ).

Cliquez sur l'image pour l'agrandir.
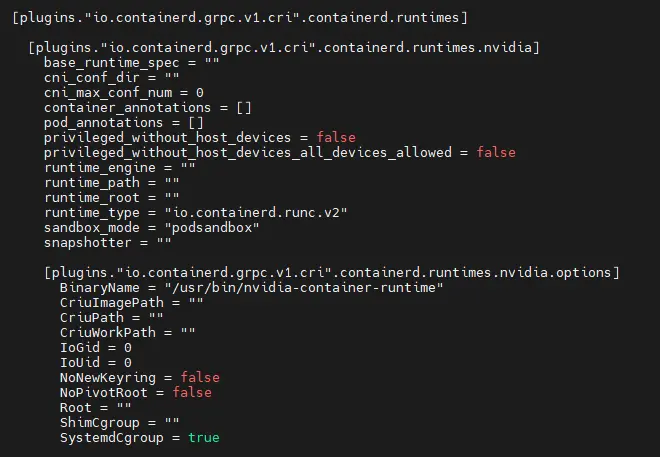
Celle-ci va modifier la configuration de containerd pour y inclure les paramètres propres aux supports des cartes NVIDIA.
On peut d’ailleurs les identifier dans le fichier de conf /etc/containerd/config.toml.
Cliquez sur l'image pour l'agrandir.
Pour qu’elle soit prise en compte, il faut redémarrer le service containerd (systemctl restart containerd).
Installation de l'opérateur NVIDIA pour Kubernetes
C’est autour de l’opérateur gpu-operateur d’être déployé sur le cluster. Un opérateur combine des Custom Ressource Definition (crd), soit des extensions de l’API par défaut de K8S, et un contrôleur chargé de gérer les ressources qui vont être générées à partir de ces Custom Ressource Definition.
Cela automatise la gestion de nouveaux objets qui viennent étendre les capacités du cluster.
Côté NVIDIA, vous pourrez aussi entendre parler du Device Plugin For Kubernetes. C’est la base minimale nécessaire à la prise en comptes des GPU NVIDIA par K8S, mais il est conseillé de passer par l’opérateur qui va intégrer le déploiement du Device Plugin et faciliter la configuration de l’ensemble.
Pour installer l’opérateur gpu-operateur, on peut utiliser helm (pour rappel helm est un gestionnaire de package pour K8S, j'en parle dans cet article).
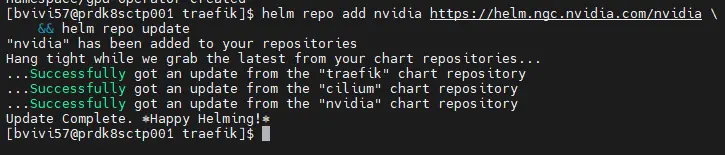
On ajoute le repos helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
Cliquez sur l'image pour l'agrandir.
On créé le namespace destiné à accueillir le contrôleur et les autres pods associés:
kubectl create ns gpu-operator

Cliquez sur l'image pour l'agrandir.
Puis on lance la commande de déploiement.
helm install --wait --generate-name \
-n gpu-operator \
nvidia/gpu-operator \
--version=v24.9.1 \
--values=./gpu-values.yaml
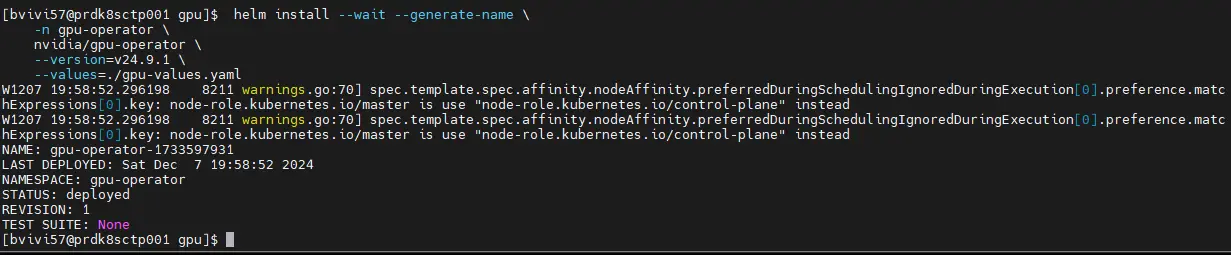
Cliquez sur l'image pour l'agrandir.
Vous remarquerez que j’ai fourni un fichier de valeur gpu-values.yaml en plus des paramètres de bases.
Le contenu est le suivant:
daemonsets:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: "node-role.kubernetes.io/control-plane"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
node-feature-discovery:
gc:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: "node-role.kubernetes.io/control-plane"
operator: "Equal"
value: ""
effect: "NoSchedule"
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
Il est nécessaire au faite que je n’utilise qu’un seul node pour ce cluster K8S un peu particulier. Il me faut, comme évoquer en début d’article, autoriser l’exécution de pods sur le control-plane.
Tests et déploiement d'une application
Test basique
Arrivé à ce stade, on peut vérifier le déploiement via la commande kubectl get pod -n gpu-operator.
Reste maintenant à savoir si cela fonctionne.
Pour ça, nvidia fourni un petit pod de tests cuda-vectoradd chargé d’exécuter une commande sur le GPU.
Voici le yaml cuda-vectoradd.yaml associé:
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1
Par rapport à ce que fournit NVIDIA, j’ai simplement ajouté la toleration pour l’exécution sur un control-plane.
Autrement, le plus intéressant est le champs:
resources:
limits:
nvidia.com/gpu: 1
C’est ici qu’on mappe le GPU au pod (dans le cas d’un GPU AMD la syntaxe est pratiquement la même amd.com/gpu: 1).
Cela indique qu’on autorise le pod à solliciter 1 GPU (en l’occurrence je n’en ai pas plus pour la démo).
On exécute le pod avec la commande kubectl apply -f cuda-vectoradd.yaml.

Cliquez sur l'image pour l'agrandir.
Le pod se termine très vite, mais on peut lire ses logs via la commande kubectl logs cuda-vectoradd (la démo de fait dans le namespace par défault).
Bonne nouvelle, le test est un succès.
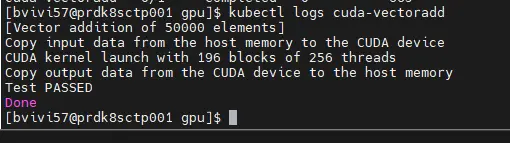
Cliquez sur l'image pour l'agrandir.
Mais voyons si on ne peut pas faire davantage d’essais.
Test avancé
Pour ça, je vais partir sur l’outil gpu-burn. C’est un simple benchmark qui permet de solliciter son GPU sous Linux.
En intégrant sa récupération, sa compilation et son exécution dans un pod, on devrait pouvoir observer une charge sur la carte graphique.
Voici le contenu du fichier demo-gpu.yaml que j’utilise (merci ChatGPT):
apiVersion: v1
kind: Pod
metadata:
name: gpu-burn
spec:
restartPolicy: OnFailure
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: gpu-burn
image: "nvidia/cuda:11.7.1-devel-ubuntu20.04" # Image CUDA de développement
command: ["/bin/bash", "-c"]
args:
- |
# Mettre à jour le système et installer git, make et gcc
apt-get update && apt-get install -y git make gcc && \
# Cloner gpu-burn et compiler
git clone https://github.com/wilicc/gpu-burn.git && \
cd gpu-burn && make && \
# Exécuter gpu-burn pendant 60 secondes
./gpu_burn 60 && \
echo "GPU burn test completed successfully" && sleep 3600
resources:
limits:
nvidia.com/gpu: 1 # Alloue une GPU NVIDIA
Comme pour le test de NVIDIA, j’utilise l’instruction nvidia.com/gpu: 1.
Le pod de NVIDIA étant terminé, il est à nouveau possible de monter le GPU dans ce nouveau pod (kubectl apply -f demo-gpu.yaml).
La dernière instruction présente dans les args du pod lance gpu-burn pour 60s.

Cliquez sur l'image pour l'agrandir.
C’est suffisant pour qu’une fois le pod lancé on puisse utiliser la commande nvidia-smi et se rendre compte qu’effectivement le GPU est en cours de sollicitation par GPU Burn.
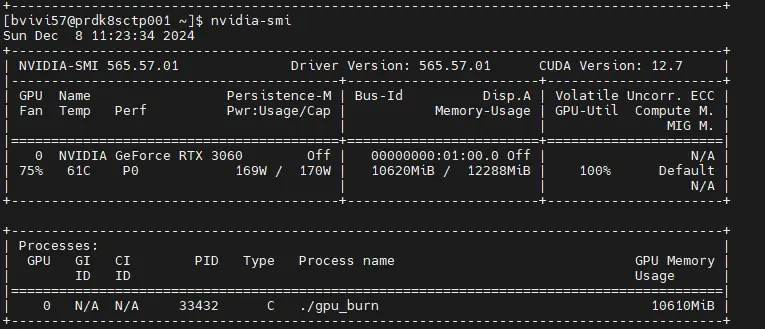
Cliquez sur l'image pour l'agrandir.
Si on veut en savoir plus, on peut déployer l’outil nvtop, (dispo dans les repos EPEL: dnf install nvtop).
Ce petit outil vous permet de voir en live l’usage de vos GPU.
Quand on l’exécute alors que le pod gpu-burn est toujours actif, on voit vient que le GPU NVIDIA est sollicité.
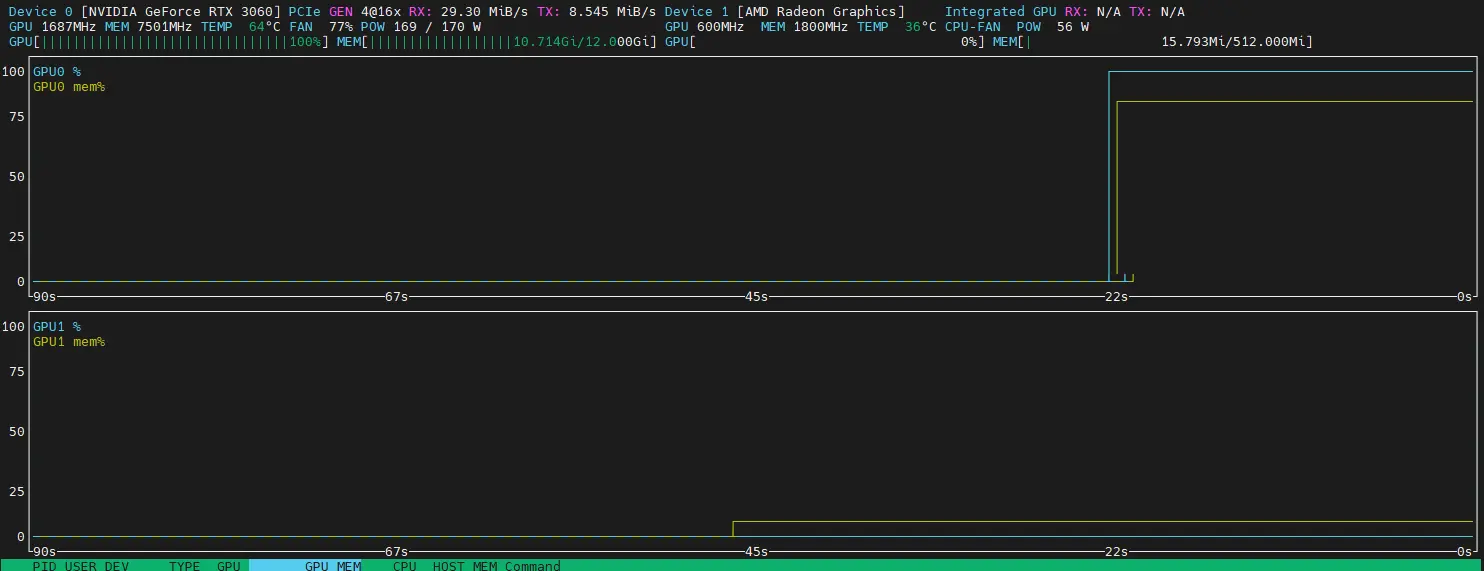
Cliquez sur l'image pour l'agrandir.
Déploiment Ollama et OpenWebUI
Il est maintenant tant de réaliser le test final, avec Ollama et OpenWebUI.
Je ne vais pas redétailler le déploiement de ces deux outils, tout vous est présenté et expliqué ici.
Je vais reprendre exactement les mêmes playbook que ceux utilisés pour ma première expérimentation sur un serveur physique de récupération et ne disposant d’aucun GPU. Seul le namespace va changer et quelques paramètres associés au stockage.
Je vous liste néanmoins les yamls utilisés.
Déploiement du PV dédié à ollama. Il faut de la perf, donc j’utilise mon disque NVME et sa classe de stockage local sc-local-storage-prddtsnme001:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-ollama-default
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
capacity:
storage: 250Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: sc-local-storage-prddtsnme001
local:
path: /mnt/datastores/prddtsnme001/localpv/prd-mygptgpu-lan/pv-ollama-default
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- prdk8sctp001
On poursuit avec le pvc:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-ollama-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
accessModes:
- ReadWriteOnce
storageClassName: sc-local-storage-prddtsnme001
resources:
requests:
storage: 250Gi
Puis le deployment de ollama:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-ollama-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
replicas: 1
selector:
matchLabels:
environment: prd
network: lan
application: mygpt
tier: ollama
template:
metadata:
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ollama
image: ollama/ollama:0.5.1
resources:
limits:
nvidia.com/gpu: 1
ports:
- containerPort: 11434
volumeMounts:
- name: pv-ollama-default
mountPath: "/root"
volumes:
- name: pv-ollama-default
persistentVolumeClaim:
claimName: pvc-ollama-default
Là, on n’oublie pas la toleration pour autoriser l’exécution sur le control-plane et surtout la déclaration de l’usage du GPU.
On enchaine avec le service pour exposer ollama au sein du cluster.
---
kind: Service
apiVersion: v1
metadata:
name: svc-ollama-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: ollama
spec:
ports:
- name: ollama
port: 11434
protocol: TCP
targetPort: 11434
selector:
environment: prd
network: lan
application: mygpt
tier: ollama
Puis on déclare le PV pour OpenWebUI. Dans ce cas, un simple volume NFS via le CSI associé suffit.
---
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: nfs.csi.k8s.io
name: pv-openwebui-default
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
capacity:
storage: 30Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
driver: nfs.csi.k8s.io
volumeHandle: /Volume1/nfsshare/rubikub.coolcorp.priv/namespaces/prd-mygptgpu-lan/openwebui
volumeAttributes:
server: 192.168.10.152
share: /Volume1/nfsshare/rubikub.coolcorp.priv/namespaces/prd-mygptgpu-lan/openwebui
Ce PV est utilisé par le PVC qui suit.
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-openwebui-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 30Gi
volumeName: pv-openwebui-default
On enchaine avec le deployment OpenWebUI avec toujours la toleration qui va bien. Pas besoin de GPU ici puisqu'il s'agit de l'interface web.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-openwebui-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
replicas: 1
selector:
matchLabels:
environment: prd
network: lan
application: mygpt
tier: openwebui
template:
metadata:
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: open-webui
image: ghcr.io/open-webui/open-webui:main
ports:
- containerPort: 8080
volumeMounts:
- name: pv-openwebui-default
mountPath: "/app/backend/data"
env:
- name: OLLAMA_BASE_URL
value: "http://svc-ollama-default:11434"
volumes:
- name: pv-openwebui-default
persistentVolumeClaim:
claimName: pvc-openwebui-default
On expose en interne openWebUI avec le service suivant:
---
kind: Service
apiVersion: v1
metadata:
name: svc-openwebui-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
spec:
ports:
- name: openwebui
port: 8080
protocol: TCP
targetPort: 8080
selector:
environment: prd
network: lan
application: mygpt
tier: openwebui
Service qu’on va ouvrir à l’extérieur via l’ingress et l’usage de traefik qui va accueillir les connexions sur l’URL https://mygptgpu.coolcorp.priv/ (avec un joli certificat qu’on n’aura pris soin de mettre dans un secret).
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ing-openwebui-default
namespace: prd-mygptgpu-lan
labels:
environment: prd
network: lan
application: mygpt
tier: openwebui
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: web,websecure
ingressClassName: traefik-lan
traefik.ingress.kubernetes.io/router.tls: "true"
spec:
ingressClassName: traefik-lan
tls:
- hosts:
- mygptgpu.coolcorp.priv
secretName: secret-certificate-mygptgpu
rules:
- host: mygptgpu.coolcorp.priv
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-openwebui-default
port:
number: 8080
Je ne vais pas plus loin dans le détail, encore une fois n’hésitez pas à parcourir mon premier article sur le sujet.
Premier article qui m’avait permis de faire tourner Ollama et OpenWebUI sur un serveur sans GPU que je peux toujours solliciter par l’URL https://mygpu.coolcorp.priv.
Je vais pouvoir donc comparer les deux instances.
Pour ça il me faut récupérer le même modèle LLM.
Je vais choisir llama3.2.
C’est un modèle qui repose sur 3 milliards de paramètres. Plus ce nombre est élevé, plus normalement le modèle est puissant…mais plus il nécessite de ressources à la fois pour l’entrainement et pour la consultation.
Pour l’inférence, la quantité de VRAM de la carte graphique est un élément très important. Le modèle à besoin de stocker ses paramètres au sein de cette dernière. La RAM traditionnelle est trop lente pour ça.
Le nombre de paramètres à exploser au fur à mesure de l’évolution des LLM. A titre d’exemple, le premier modèle GPT-1 utilisé 117 millions de paramètres, GPT-3 175 milliards…et GPT-4 on parle de trillions.
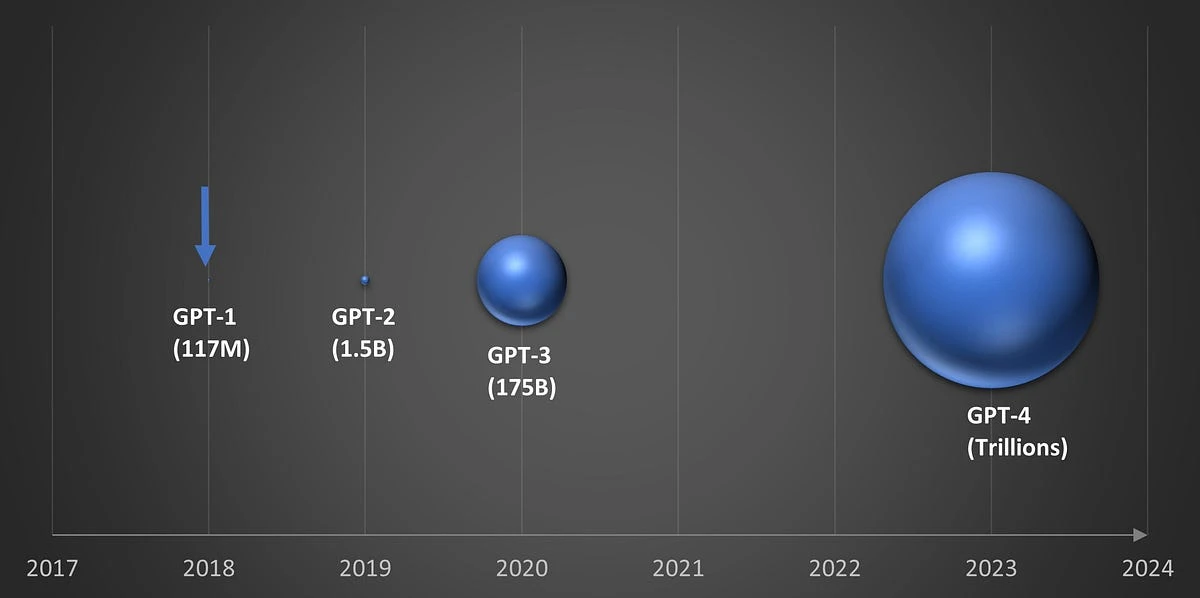
Cliquez sur l'image pour l'agrandir.
Plus on retient un modèle au nombre de paramètres important, plus la quantité de VRAM doit augmenter pour avoir un temps de réponse correcte lors de la phase d’inférence. Cela détermine le nombre de tokens simultanés (de mots) traitables lors de la consultation du modèle.
Il existe des abaques traitant de la quantité de VRAM nécessaire en rapport au modèle LLM retenu.
N'hésitez pas à consulter ce site https://unfoldai pour davantage de détails et savoir comment est calculé le besoin en VRAM en rapport au modèle choisi.
Fort heureusement, l’efficacité d’un modèle ne suit pas une ligne de droite proportionnelle au nombre de paramètres.
Certes, plus on n’a de paramètres, plus le modèle est puissant, mais au fur à mesure qu’on n’augmente ces derniers, le gain est de plus en plus faible…c’est d’ailleurs une des limites actuelles de l’IA générative.
On s’aperçoit que si au départ l’augmentation des paramètres permettait des améliorations énormes dans les modèles LLM, on commence à perdre en efficience au fur à mesure de l’augmentation des paramètres.
D’ailleurs certains modèles, ne cherchent pas forcement a être les meilleurs et pouvoir répondre à tous, mais cherche plutôt a être les plus optimisés possibles, pouvant traiter les demandes les plus courantes, mais avec une emprunte numérique plus faible.
C’est ce qui a fait par exemple le succès des modèles de MistralAI qui s’est fait connaitre en proposant des modèles avec un nombre de paramètres plus faible, mais pour autant tout aussi performant pour une majorité de cas que des modèles plus lourds.
Dans mon serveur, je dispose d’une carte graphique avec 12 GO de VRAM, je peux donc viser d’après les références trouvées un modèle de 3 milliards de paramètres comme celui de Facebook llama3.2 (disponible aussi avec 1 milliard de paramètres).
Je me rends donc sur chacune de mes instances Ollama, rentrant dans le contexte d’exécution des conteneurs (kubectl exec -it nom_du_pod -n nom_namespace -- bash).

Cliquez sur l'image pour l'agrandir.
Dans les deux cas, je passe la commande ollama pull llama3.2 pour récupérer le modèle (plus d’informations ici).

Cliquez sur l'image pour l'agrandir.
De cette manière le modèle est sélectionnable dans l’interface de OpenWebUI.
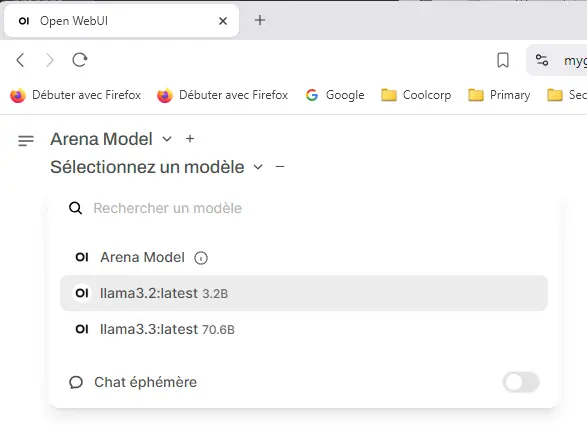
Cliquez sur l'image pour l'agrandir.
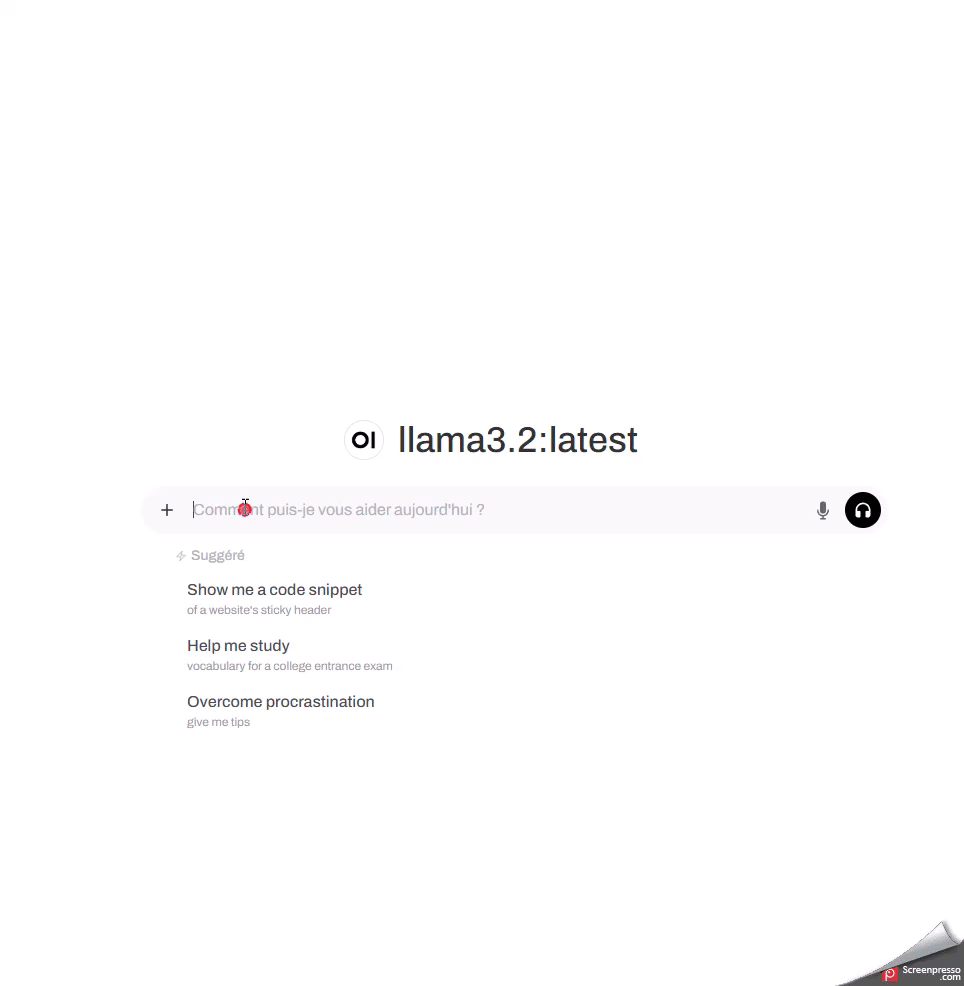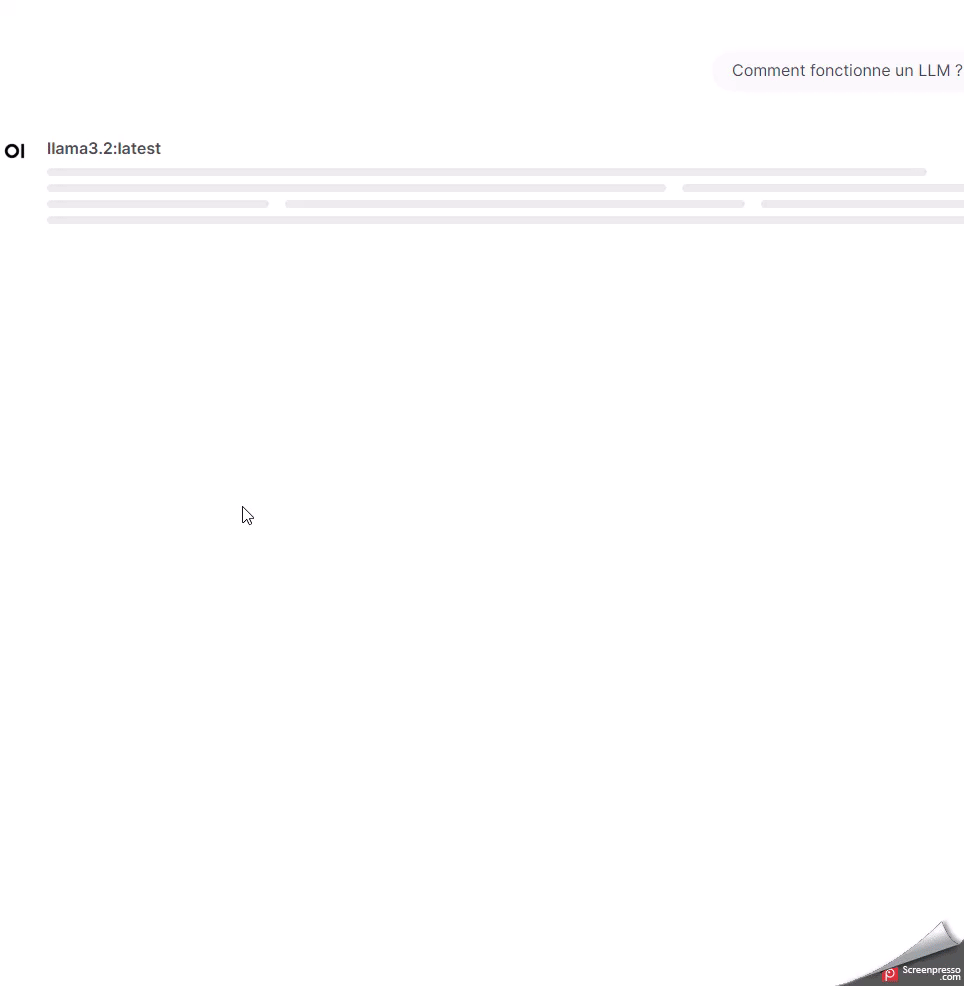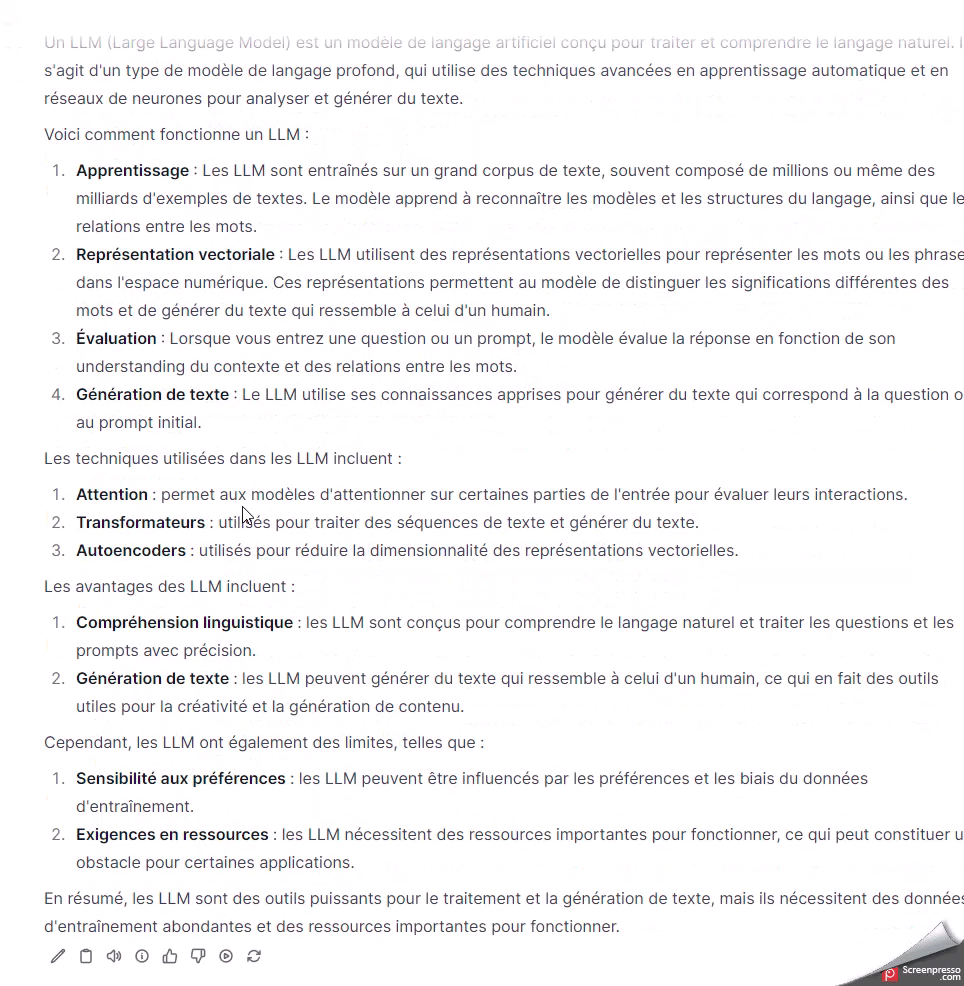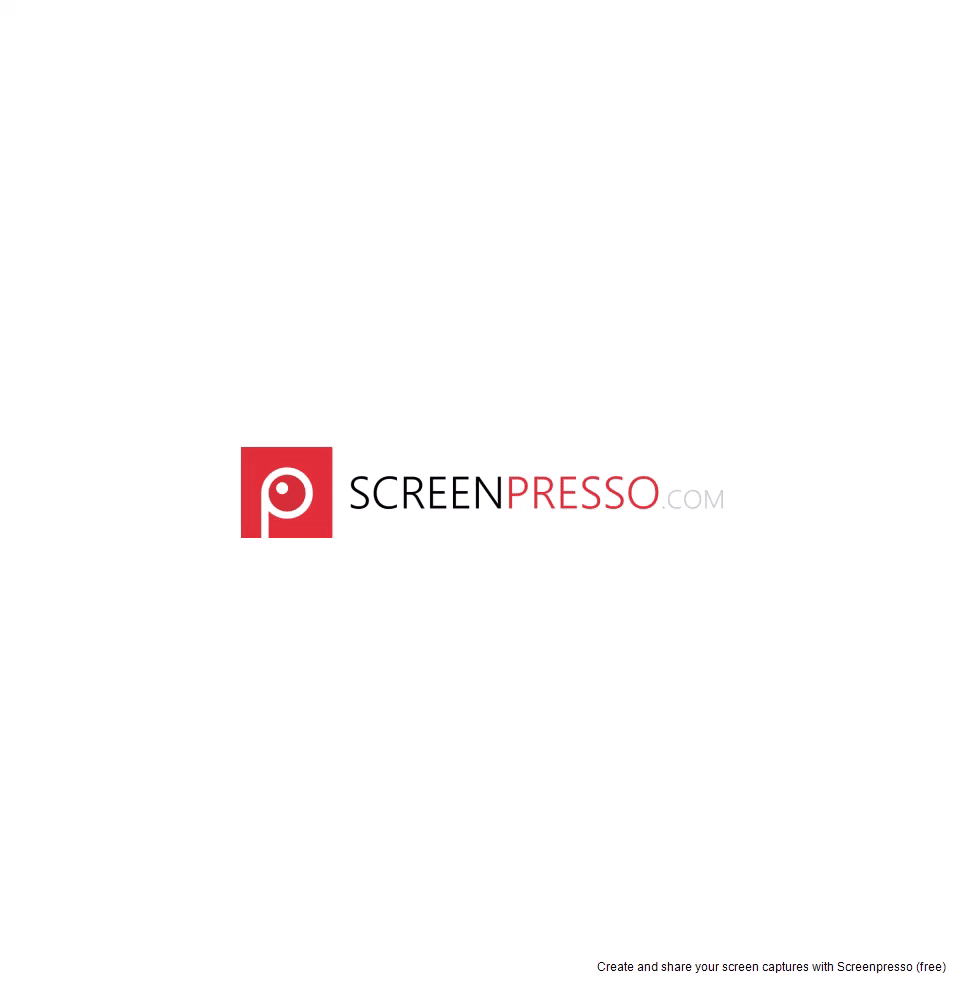
Je vais pouvoir poser la même question sur l’instance avec et sans GPU.
La différence est nette. L’instance avec GPU répond nettement plus vite aux sollicitations du modèle.
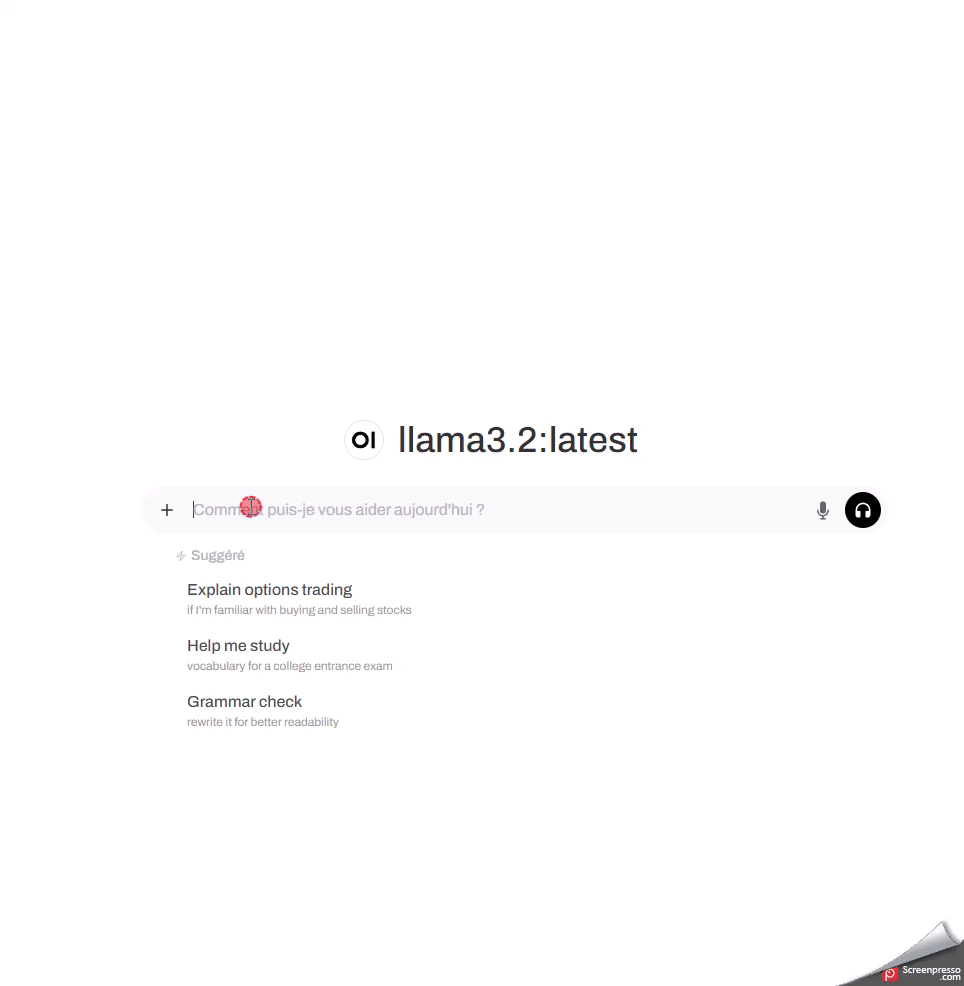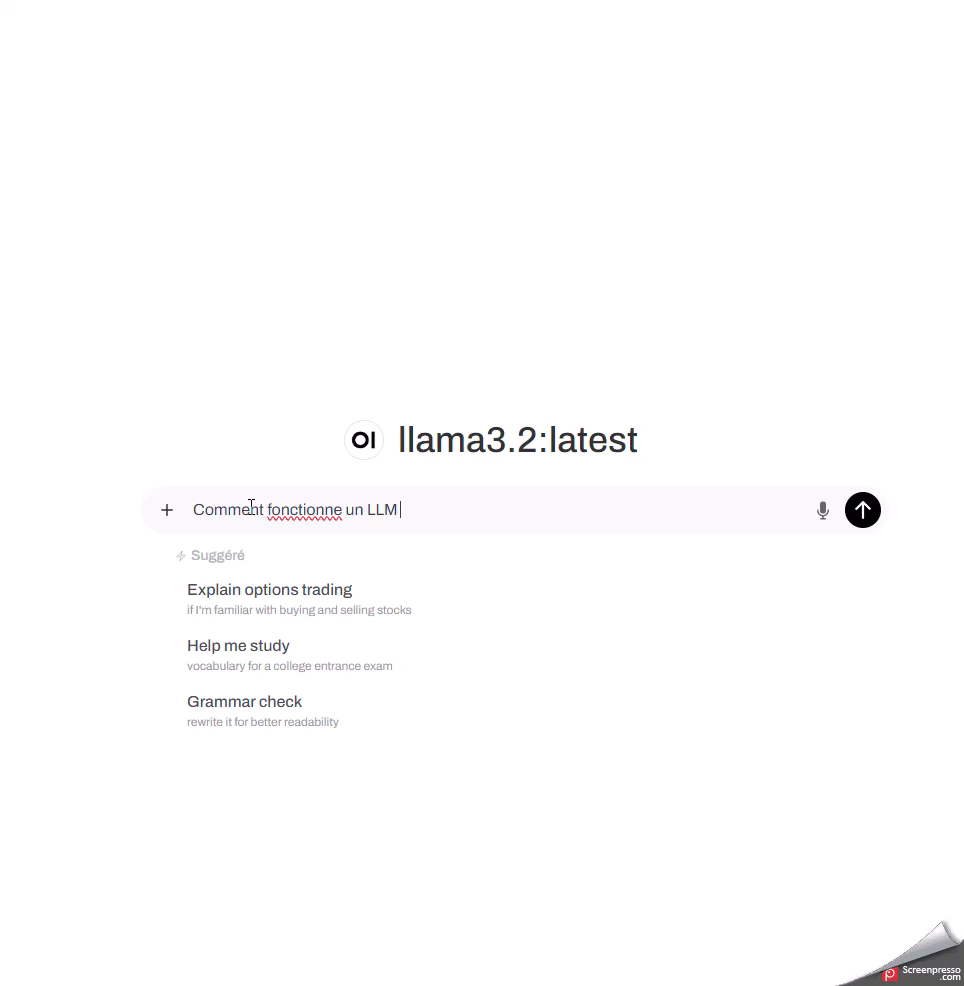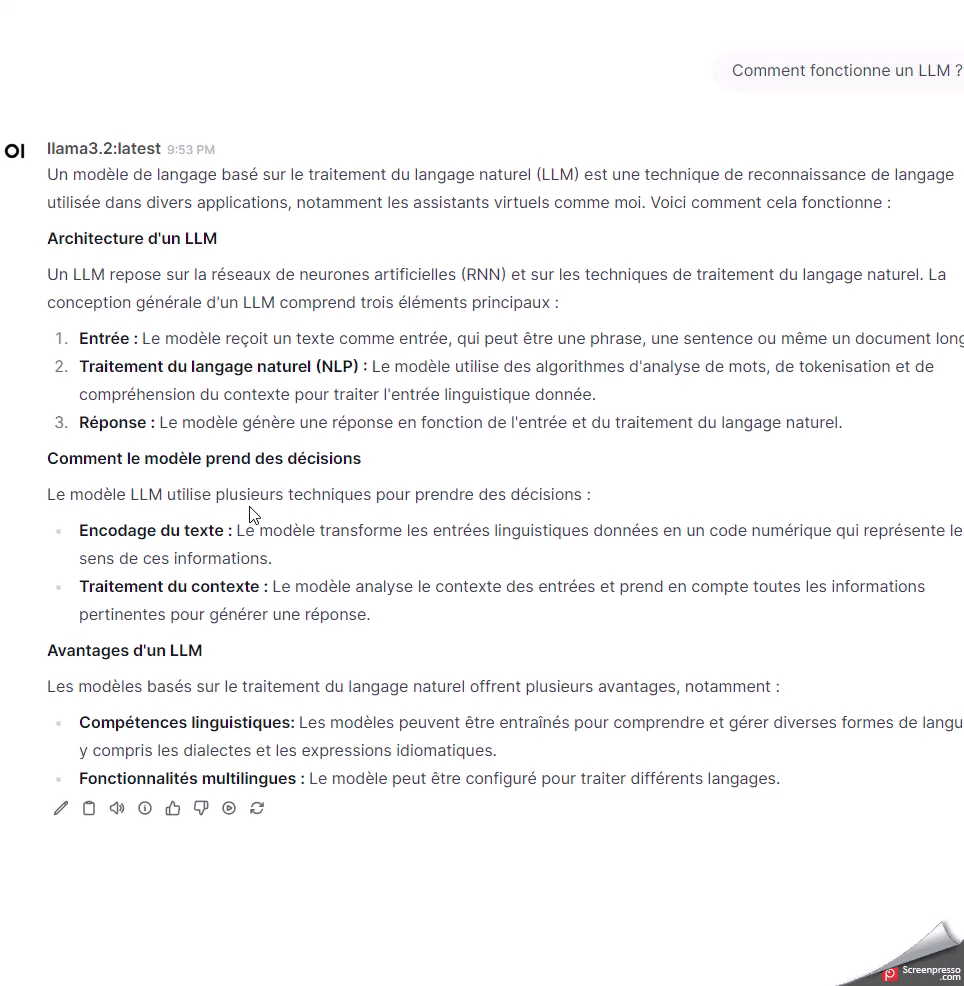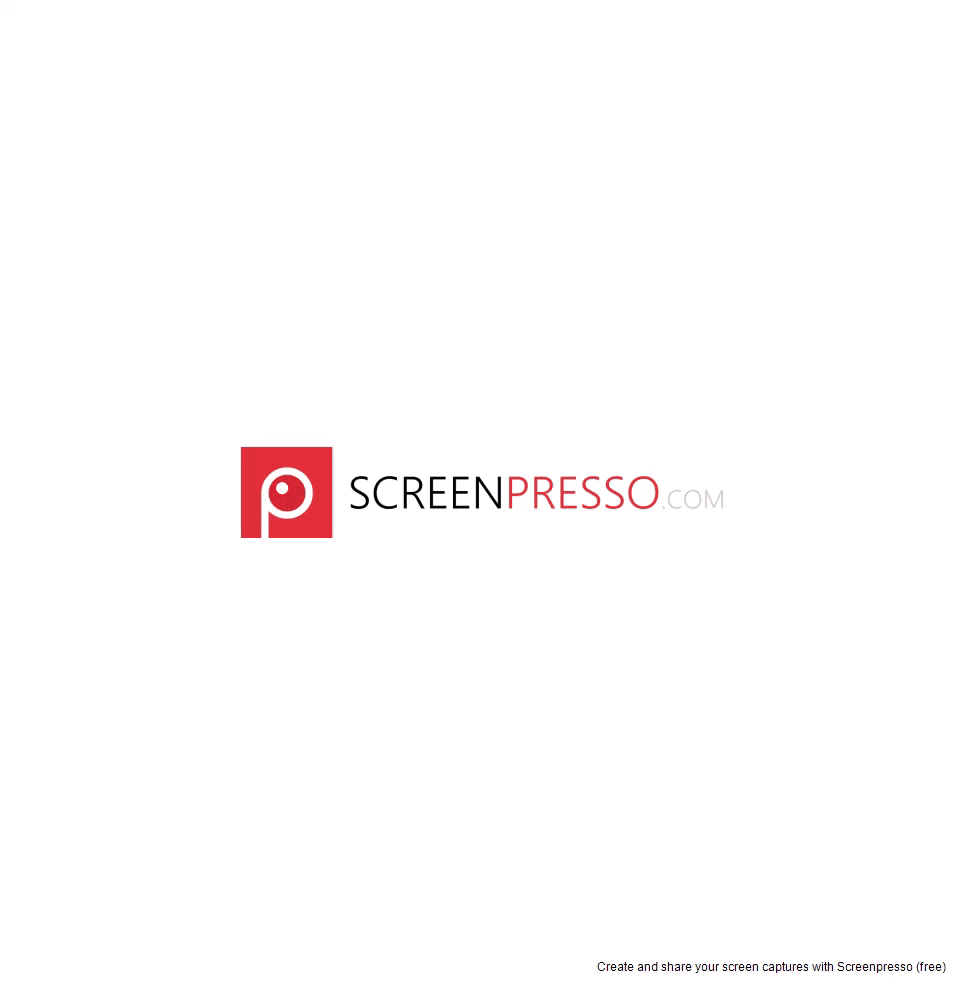
Cliquez sur l'image pour l'agrandir.
Lorsqu’on regarde les ressources consommées durant les tests, on voit que sur le serveur disposant de l’instance sans GPU, le CPU donne tout ce qu’il a alors que sur l’instance avec GPU, le CPU est moins sollicité à l’inverse du GPU qui est bien employé.
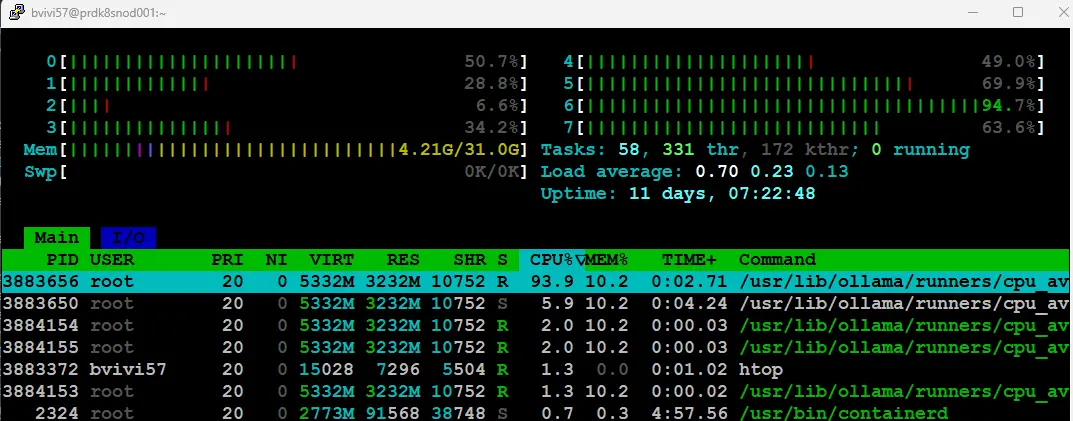
Cliquez sur l'image pour l'agrandir.
On peut d’ailleurs voir la sollicitation du GPU avec les mêmes outils que pour nos tests précédents.
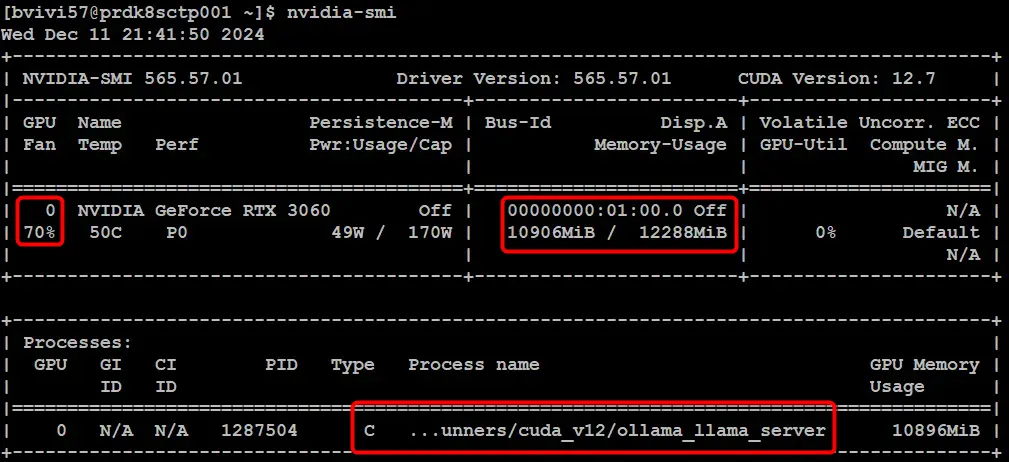
Cliquez sur l'image pour l'agrandir.
Si je désactive l’usage du GPU sur mon serveur prdk8sctp001, en supprimant dans le pod à la référence nvidia.com/gpu: 1.
Lorsque je relance le pod et que je sollicite à nouveau le modèle, on n’arrive à une dégradation des performances, certes moins que sur mon instance dépourvue de GPU, car je dispose d’un CPU plus récent sur ce nouveau serveur physique, mais on perd la fluidité observée lors des premières sollicitations avec GPU.
Cliquez sur l'image pour l'agrandir.
Si je m’essaye à un autre modèle, comme llama3.3, la par contre, même avec le GPU d’actif dans le pod, les performances sont catastrophiques.
Cliquez sur l'image pour l'agrandir.
La faute aux 70 milliards de paramètres de ce modèle bien trop important pour la VRAM et la puissance de ma pauvre NVIDIA 3060.
Point important également, ne disposant que d’un seul GPU (le GPU intégré au CPU n’est pas exploitable), dès lors que celui est associé à un pod, il n’est plus disponible pour d’autres. C’est aujourd’hui un problème, car même si l’application hébergée au sein du pod n’a pas besoin des ressources du GPU à un instant T, celui-ci est comme même perdu pour le reste des pods.
Il existe cependant la notion de MIG (Multi Instance GPU) qui permet de partitionner un GPU en "sous GPU" déclarable dans plusieurs pods. Mais cette fonction est réservé à des cartes profesionnelles comme la NVIDIA A100 qui supporte 7 "sous GPU" permettant de paralléliser l’usage d’un carte entre plusieurs pods.
Conclusion
Grâce à son approche modulaire et sa constante évolution, Kubernetes a su s’adapter aux demandes du marché pour intégrer la gestion des GPU dans son service d’orchestration. Les principaux constructeurs de cartes graphiques ont pu proposer leurs extensions et rendre compatibles leurs cartes avec Kubernetes.
Le revers de la médaille c’est qu’une fois de plus, pour arriver à un résultat il faut passer par l’installation de plusieurs composants qu’il vous faudra maintenir dans le temps et mettre à jour régulièrement.
Cette complexité sera forcement réduite dans l’usage d’un service managé, ou certaines offres inclus de base l’ajout de GPU, mais il vous faudra tout de même jouer de la CLI dans certains cas.
Je n’ai montré ici qu’un exemple pour l’usage de LLM (et suivre la mode du moment…) mais le GPU peut permettre beaucoup d’autres choses.
Pour le contexte du LLM, on note clairement l’avantage de ce dernier sur un CPU…sous conditions d’avoir le hardware proportionnellement adapté à la lourdeur du modèle retenue.
Dans les mois à venir, on risque de voir d’autres composants faire leur entrée, comme les fameux NPU pour Neural Process Unit déja en oeuvre dans certaines configuration. Ces processeurs dédiés devraient permettre des performances au niveau de l’inférence extrêmement intéressante pour des coûts énergiques bien plus faibles qu’un GPU du fait de leur spécialisation.
Comme pour les GPU, les NPU pourront être exploités par K8S grâce au Device Plugins qui sert finalement de base pour l'intégration de tous nouveaux composants materiels au sein d'un cluster.
Tout dépendra des constructeurs de ces puces qui devront fournir des opérateurs dédiés et permettre le support de leur produit dans Kubernetes.
À noter que l’intégration devra d’abord se faire au niveau du runtime de conteneurs, puis que Kubernetes reste un orchestrateur.
Cela risque d’être fort intéressant à voir se développer et va s’accompagner de son lot de défis, notamment du côté de la supervision, de l’observabilité et de la gestion des ressources. Il fallait déjà suivre sa mémoire, son CPU, son disque et sa bande passante réseau…il faudra ajouter aux dashboards de monitoring des graphiques GPU et NPU 😊.