Backup et restauration de la base etcd K8S
Introduction
Pour fonctionner, Kubernetes stocke sa configuration dans une base clef/valeur.
Historiquement et par défaut, c’est etcd qui sert cette fonction au sein d’un cluster.
etcd peut être externalisé et déployé en dehors du cluster, mais le plus souvent il fait partie intégrante des briques de bases configurées lors de l’usage de kubeadm.
Dans ce type d’installation, un conteneur etcd est déployé sur chaque control plane qui compose le cluster, permettant ainsi d’avoir une redondance des données.
À chaque opération sur le cluster, la base etcd est modifiée pour maintenir un statut des objets K8S.
En permanence, Kubernetes compare le contenu de sa base à l’état des assets qu’il contrôle. Si un écart est constaté, K8S fera alors le nécessaire pour revenir à l’état décrit dans sa base.
La base etcd devient donc un élément critique du cluster. En cas d’incohérence de cette dernière, c’est tout le statut du cluster qui peut ne plus correspondre aux attentes des administrateurs.
L’indisponibilité d’ etcd entraine de facto une impossibilité d’interagir avec le cluster et donc de piloter les assets sous-jacents.
C’est pourquoi il est fortement recommandé de sauvegarder régulièrement la base etcd et de s’assurer de pouvoir la restaurer en cas d’incident.
Je vais tâcher dans cet article d’essayer de décrire une procédure possible pour traiter cette problématique.
Néanmoins, cela reste un exercice qui peut varier d’une configuration à une autre. Il n’est pas garanti que ce qui fonctionne dans mon cas fonctionne pour vous. Mais j'espère que vous trouviez suffisamment d’éléments ici pour construire votre stratégie de sauvegarde et vous exercer à la restauration.
Principes
Si c’est relativement simple dans le cas d’un cluster disposant d’un seul control plane, cela peut être un peu plus complexe dans le cas de multiple control plane.
Chaque control plane dispose de sa version de la base et s’assure que son contenu soit en cohérence avec le contenu des autres serveurs.
Cette synchronisation est assurée par le protocole Raft. C’est un algorithme de consensus distribués qui exige qu’un minimum de serveur soit actif pour fonctionner.
Raft est basé sur une notion de leader qui prend la responsabilité de la gestion des écritures dans la base. Les autres nœuds du cluster sont des followers et reçoivent les mises à jour du leader.
Si le leader venait a être indisponible, alors les followers en élisent un nouveau entre eux, sous condition qu’ils soient suffisamment nombreux pour se mettre d’accord.
Par exemple, un cluster de trois nœuds supportera la perte d’un nœud, les deux restants représentant une majorité suffisante. Mais si un second nœud tombe, alors Raft n’est plus en mesure d’élire un leader et le nœud restant ne peux assurer les mises à jour de la base.
Restaurer de manière incorrecte une base etcd au sein d’un cluster peut provoquer une désynchronisation des nœuds et des erreurs dans le protocole Raft amenant les nœuds à ne plus pouvoir élire un leader.
C’est pourquoi il est nécessaire de respecter une procédure stricte qu’il ne faut pas hésiter à tester plusieurs fois avant de partir en production.
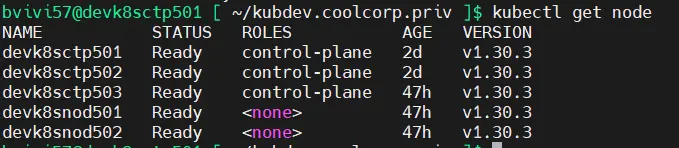
Pour illustrez mon article, je vais me baser sur un cluster de developpement que j’ai monté avec trois control plane et deux worker, répartie entre une infra VMwware et XCP-ng.
Cliquez sur l'image pour l'agrandir.
Je vais faire un backup avant de supprimer un namespace dev-demo-lan. Le but étant de restaurer le backup pour voir réapparaitre le namespace.
Sauvegarde de la base etcd
Le backup peut se faire indépendamment sur chaque control plane. Il est recommandé de faire un backup par control plane pour avoir ainsi plusieurs images de sauvegarde de la base.
En prérequis il est nécessaire d’installer le package etcd sur les control planes. etcd s’exécute en tant que conteneurs et les serveurs ne disposent pas directement des binaires etcd dont on va avoir besoin pour exécuter les commandes de sauvegarde et de restauration.
Dans mon cas, j’utilise PhotonOS, l’installation du packet est donc à adapter à votre distribution.
Pour moi la commande est tdnf install etcd

Cliquez sur l'image pour l'agrandir.
Ensuite, on s’assure d’être en root pour créer un répertoire dédié à l’hébergement des backups.
Pour rester en cohérence avec la description de l’installation de mon cluster, j'ai choisi arbitrairement /etc/kubernetes/backup.
mkdir -p /etc/kubernetes/backup

Cliquez sur l'image pour l'agrandir.
Puis sur chaque control plane, en root, je tape la commande suivante:
- Sur le control plane un:
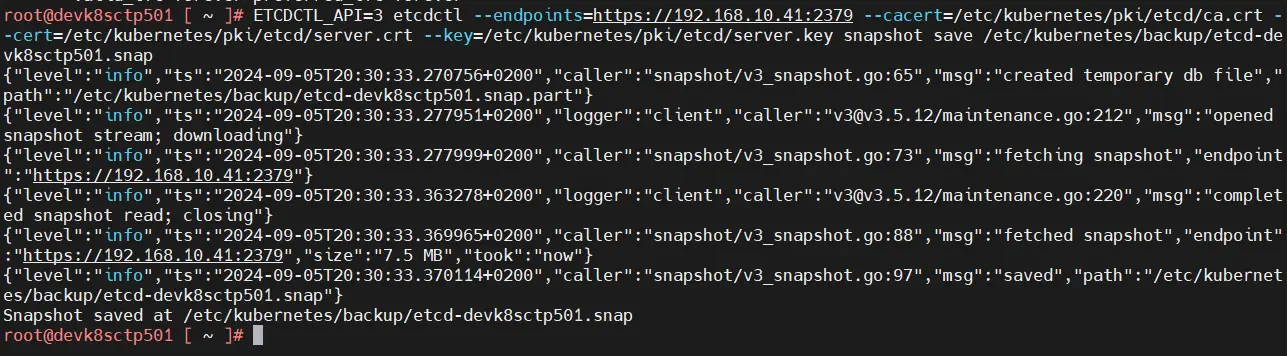
ETCDCTL_API=3 etcdctl --endpoints=https://ip_du_serveur_01:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key snapshot save /etc/kubernetes/backup/etcd-nom_serveur_01.snap - Sur le control plane deux:
ETCDCTL_API=3 etcdctl --endpoints=https://ip_du_serveur_02:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key snapshot save /etc/kubernetes/backup/etcd-nom_serveur_02.snap - Sur le control plane trois:
ETCDCTL_API=3 etcdctl --endpoints=https://ip_du_serveur_03:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key snapshot save /etc/kubernetes/backup/etcd-nom_serveur_03.snap
Cliquez sur l'image pour l'agrandir.
L’IP à utiliser est l’IP principale de votre control plane. Les autres options permettent d’indiquer le certificat et la clef privée du serveur etcd afin de pouvoir s’authentifier auprès de l’instance etcd qui tourne sous forme conteneurisée sur le node.
En effet, lors du déploiement du cluster avec kubeadm, tous ces éléments sont automatiquement générés et placés dans les chemins par défaut. Maintenant fonction de votre méthode d’installation de Kubernetes, les emplacements peuvent différer.
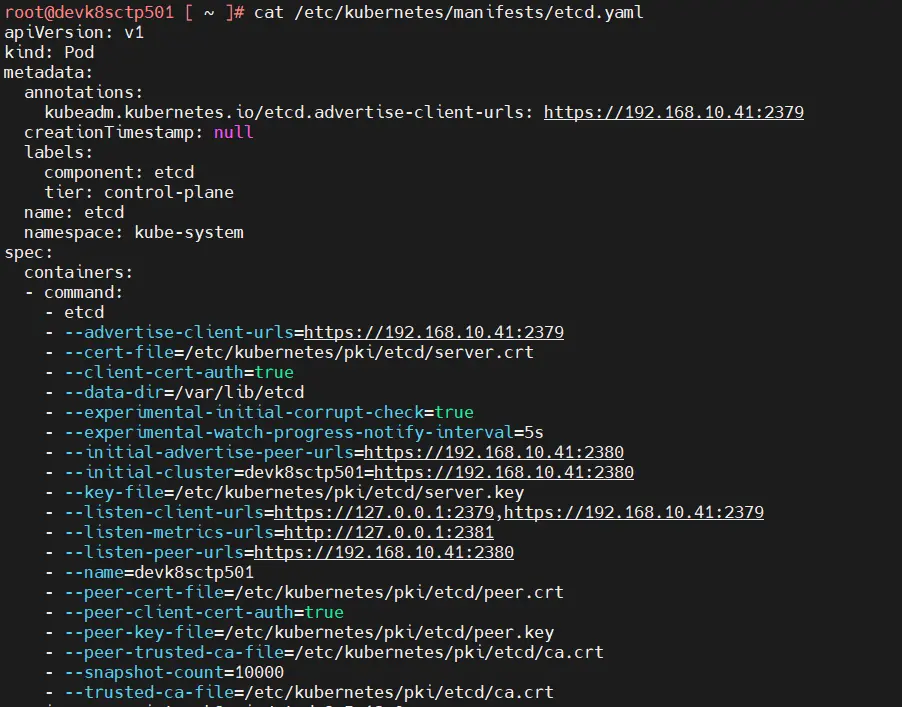
Normalement le détail de votre installation de etcd est disponible dans le manifest d’installation de etcd récupéré par kubeadm (ou autre) et consultable dans /etc/kubernetes/manifests/etcd.yaml
Cliquez sur l'image pour l'agrandir.
Vous y retrouverez les éléments à passer dans votre commande de backup.
Une fois l’opération réalisée sur chaque serveur, en prenant bien soin de changer l’IP pour chaque control plane, vous devriez avoir un backup par serveur.
Quand on parle de backup on parle en faite de snapshot, c’est ainsi que fonctionne etcd. Sauvegarder etcd, revient à faire un snapshot de la base dans un fichier.snap.
De mon coté, je supprime mon namespace de test.
kubectl delete ns dev-demo-lan
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Restauration de la base etcd
Pour restaurer la base, il va d’abord faloir retenir une image de sauvegarde et utiliser la même sur chacun des control planes.
Dans mon cas, j’ai trois masters et je vais décider d’utiliser le backup réalisé sur mon premier serveur (ici devk8sctp501).
Pour éviter toute incohérence dans la base, je vais déjà m’assurer de couper tous services associés à un control plane le temps de l’opération et ceci pour tous les nodes.
Il est important qu’aucun control plane ne soit actif durant la restauration, car dès le rétablissement de l’image de sauvegarde sur un nœud, si les autres nœuds continuent de fonctionner en parallèle, les données vont commencer à différer.
On passe donc en root sur chaque control plane et on déplace les manifests du dossier /etc/kubernetes/manifests/ dans /etc/kubernetes/backup avec la commande:
mv /etc/kubernetes/manifests/*.yaml /etc/kubernetes/backup/

Cliquez sur l'image pour l'agrandir.
En effet, pour s’assurer d’avoir les composants de base du cluster en exécutions sur le nodes, l’agent kubelet installé sur chaque serveur surveille ce répertoire et exécute tous fichiers yaml qui s’y trouve. C’est comme ça que Kubernetes « boot ».
À partir du moment où le fichier yaml est retiré de son emplacement, les pods associés sont stoppés par l’agent kubelet mettant fin aux services associés.
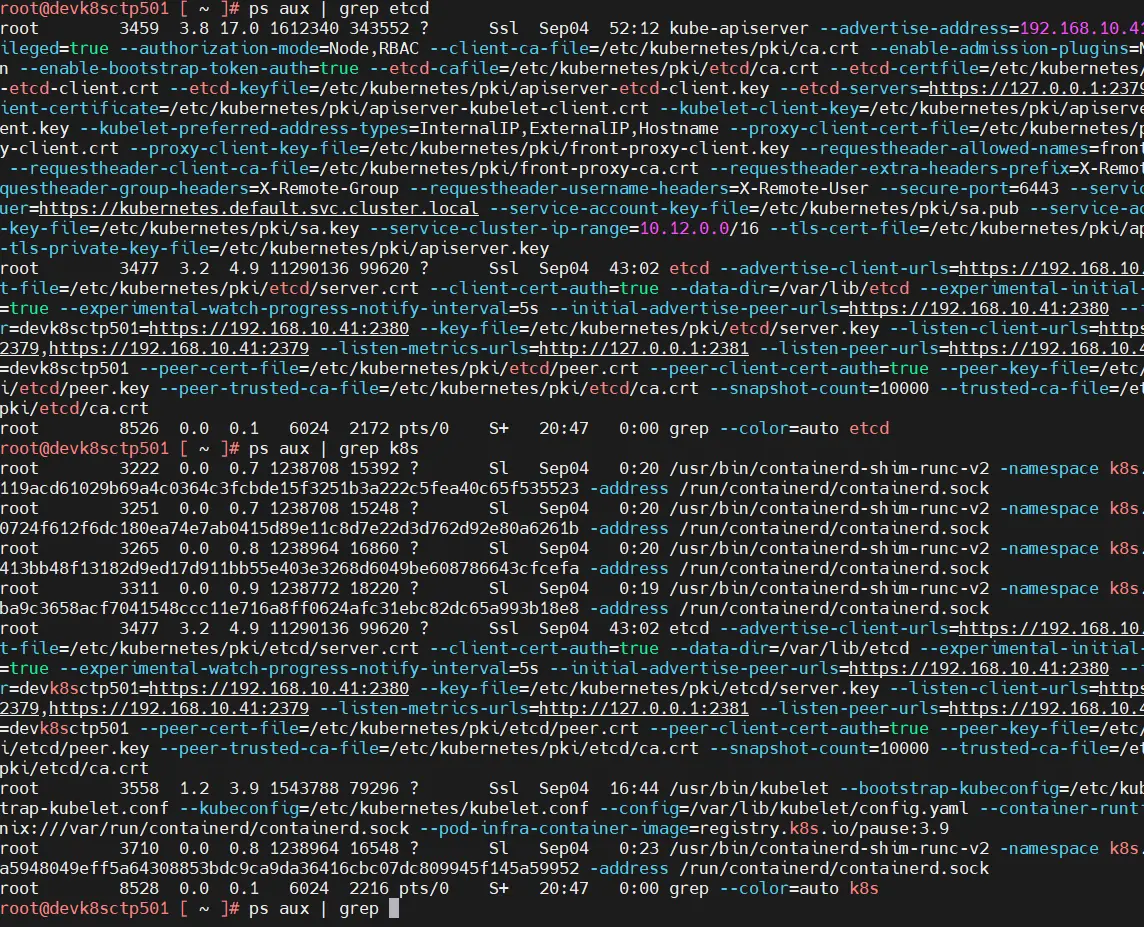
Cela peut prendre quelques minutes. Il faut surveiller l’arrêt de etcd avec la commande:
ps aux | grep etcd
Cliquez sur l'image pour l'agrandir.
Tant qu’elle retourne quelque chose cela indique que etcd est actif, une fois l’absence de process etcd sur chaque control plane, vous pouvez poursuivre les manipulations.
(En dehors de etcd, les autres manifests aussi ont été déplacés coupant le scheduler, l’api et autres briques système associées à K8S. C’est préférable le temps de l’indisponibilité de la base etcd).
Mais avant il reste à purger les datas d’origine, sans quoi le snapshot ne pourra être déployé.
Vous pouvez au choix supprimer les données ou les mettre de côté. Dans mon cas, je considère les données de base comme perdues, donc je delete :
rm -rf /var/lib/etcd/*

Cliquez sur l'image pour l'agrandir.
(Pour rappel, l’emplacement des données est visible dans le manifest associé à etcd évoqué en début d’article).
Vous pouvez faire de même sur chaque control plane.
Une fois cette opération réalisée on peut passer la commande de restauration sur le premier control plane.
ETCDCTL_API=3 etcdctl --data-dir="/var/lib/etcd/" --name=nom_server_01 --endpoints=https://ip_du_serveur_01:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --initial-advertise-peer-urls=https://ip_du_serveur_01:2380 --initial-cluster-token=etcd-cluster-0 --initial-cluster=nom_server_01=https://ip_du_serveur_01:2380,nom_server_02=https://ip_du_serveur_02:2380,nom_server_03=https://ip_du_serveur_03:2380 snapshot restore /etc/kubernetes/backup/etcd-nom_serveur_01.snap
Comme pour la commande de sauvegarde, on indique l’IP du serveur, les informations de connexion via l’usage de la clef et du certificat puis le snapshot à utiliser comme source de restauration.
Il faut également indiquer le nom et les ips des autres serveurs qui vont participer au cluster via l'option --initial-cluster.
L'option --initial-cluster-token est également importante, car c'est elle qui va permettre d'accorder tous les serveurs entre eux lors de l'initialisation de chaque note (bootstrap).
Sans ces paramètres, chaque control plane pourrait penser qu'il est seul à opérer. En effet, le snapshot ne contient pas la configuration du cluster, seulement les valeurs en base. Il faut donc indiquer lors de l'opération de restauration, que celle-ci s'accompagne d'un usage en cluster en précisant quel vont être les autres participants.
Dans les commandes il faut bien utiliser le nom court des serveurs et à l'identique dont ils apparaissaient dans la commande kubectl get node.
Il faut procéder de la même manière sur tous le control plane, mais attention, je le répète, en prenant toujours le même snapshot (et en ayant au préalable purger les données).
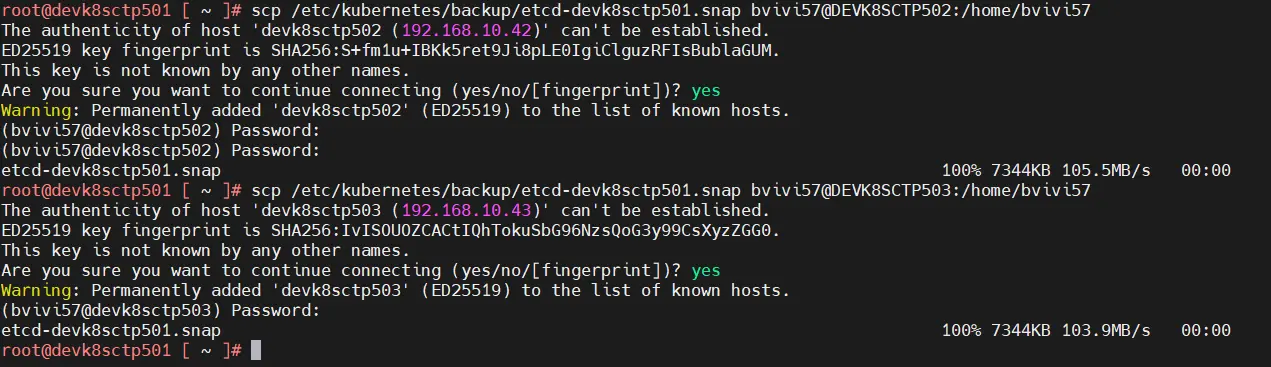
Celui-ci doit donc être copié depuis le node retenu comme source de sauvegarde sur chaque autre node via les commande:
scp /etc/kubernetes/backup/etcd-nom_serveur_01.snap user@nom_serveur_02:/home/user
scp /etc/kubernetes/backup/etcd-nom_serveur_01.snap user@nom_serveur_03:/home/user
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
En résumé, dans mon cas, avec trois control plane et le snapshot de référence disponible sur chaque serveur, mes commandes de restauration sont:
- Sur le premier serveur (devk8sctp501):
ETCDCTL_API=3 etcdctl --data-dir="/var/lib/etcd/" --name=devk8sctp501 --endpoints=https://192.168.10.41:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --initial-advertise-peer-urls=https://192.168.10.41:2380 --initial-cluster-token=etcd-cluster-0 --initial-cluster=devk8sctp501=https://192.168.10.41:2380,devk8sctp502=https://192.168.10.42:2380,devk8sctp503=https://192.168.10.43:2380 snapshot restore /etc/kubernetes/backup/etcd-devk8sctp501.snap - Sur le second serveur (devk8sctp502):
ETCDCTL_API=3 etcdctl --data-dir="/var/lib/etcd/" --name=devk8sctp502 --endpoints=https://192.168.10.42:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --initial-advertise-peer-urls=https://192.168.10.42:2380 --initial-cluster-token=etcd-cluster-0 --initial-cluster=devk8sctp501=https://192.168.10.41:2380,devk8sctp502=https://192.168.10.42:2380,devk8sctp503=https://192.168.10.43:2380 snapshot restore /etc/kubernetes/backup/etcd-devk8sctp501.snap - Sur le troisieme serveur (devk8sctp503):
ETCDCTL_API=3 etcdctl --data-dir="/var/lib/etcd/" --name=devk8sctp503 --endpoints=https://192.168.10.43:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --initial-advertise-peer-urls=https://192.168.10.43:2380 --initial-cluster-token=etcd-cluster-0 --initial-cluster=devk8sctp501=https://192.168.10.41:2380,devk8sctp502=https://192.168.10.42:2380,devk8sctp503=https://192.168.10.43:2380 snapshot restore /etc/kubernetes/backup/etcd-devk8sctp501.snap
Une fois que les instructions de restauration ont été passées sur tous les control plane, alors on peut remettre les manifests à leur emplacement d’origine en passant cette commande sur chaque node.
mv /etc/kubernetes/backup/*.yaml /etc/kubernetes/manifests/
Procéder serveur par serveur. Vous verrez avec les commandes ps aux | grep etcd et ps aux | grep k8s que progressivement les briques systèmes vont redémarrées.
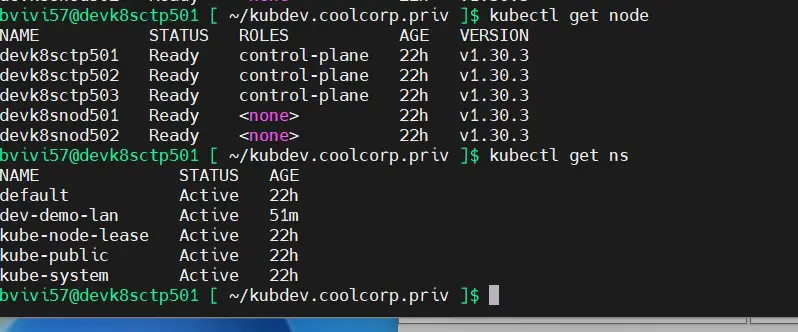
Après quelques minutes, vous devriez être en mesure de retaper des commandes type kubectl get node et à nouveau pouvoir communiquer avec votre cluster.
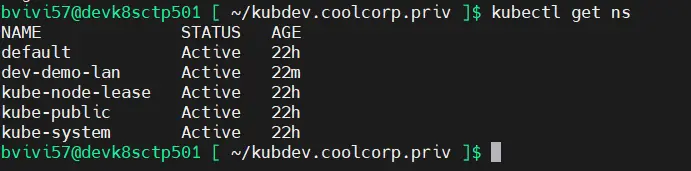
Dans mon cas, si je fais maintenant un kubectl get ns, je retrouve mon namespace dev-demo-lan supprimé précédemment.
Cela montre bien que la base a été restaurée.
Cliquez sur l'image pour l'agrandir.
Utilisation de Ansible
Comme j’ai pu l’expliquer dans cet article, j’utilise beaucoup Ansible pour automatiser certaines tâches.
Si je ne vais pas jusqu’à ansibiliser la restauration, j’ai au moins ansibilisé la sauvegarde.
Cela me permet très facilement de lancer un backup etcd et de m’assurer d’avoir toujours à disposition un snapshot de la base sous la main.
Je ne vais pas rappeler ici le fonctionnement ni l’arborescence de Ansible, mais vous pouvez lire l’article suivant dans lequel je décris la logique que j’utilise habituellement.
J’ai donc créé un rôle role_k8s_etcd_backup composé des taches suivantes:
01-prerequis.yml
Ce playbook sert uniquement à installer les binaires etcd et les répertoires que j’utilise pour stocker les snapshots.
Je créer également un dossier restore.
---
- name: Install basic packages
become: yes
tdnf:
update_cache: yes
name: "etcd"
state: present
tags: role_k8s_etcd_backup.prerequis.package
when: "'k8sctp' in inventory_hostname"
- name: Creates backup folder
become: yes
file:
path: "/etc/kubernetes/backup"
state: directory
mode: 0770
recurse: yes
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.etcd.folder
- name: Creates restore folder
become: yes
file:
path: "/etc/kubernetes/restore"
state: directory
mode: 0770
recurse: yes
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.etcd.folder
02-create-script.yml
Le deuxième playbook 02-create-script.yml me permet de copier sur chaque control plane un script de backup qui reprend les commandes expliquées précédemment.
---
- name: Récupérer l'adresse IPv4 de l'interface eth0
become: yes
shell: ip -4 addr show dev eth0 | grep inet | awk '{print $2}' | cut -d'/' -f1
register: ipv4_address_eth0
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.script.ip
- name: Afficher l'adresse IPv4 associée à eth0
debug:
msg: "L'adresse IPv4 de l'interface eth0 est {{ ipv4_address_eth0.stdout }}"
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.script.ip
- name: "Deploy etcd Backup script"
become: yes
template:
src: backup-etcd.sh.j2
dest: /etc/kubernetes/backup/backup-etcd.sh
mode: u=rwx,g=r,o=r
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.script.copy
Il s'appuie sur un template backup-etcd.sh.j2 dont voici le contenu:
#!/bin/bash
ETCDCTL_API=3 etcdctl --endpoints=https://{{ ipv4_address_eth0.stdout }}:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save /etc/kubernetes/backup/etcd-{{ inventory_hostname }}.snap
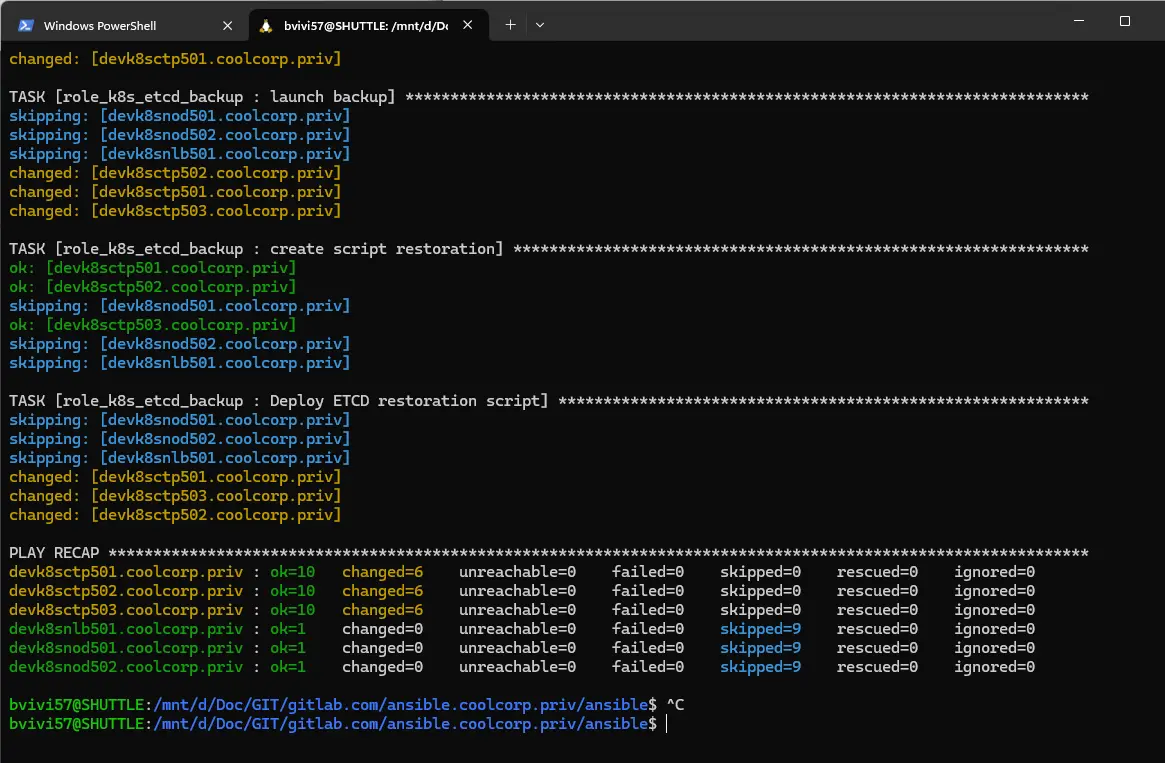
03-launch-backup.yml
Le troisième playbook 03-launch-backup.yml lance le script copié précédemment pour faire un snapshot sur chaque serveur.
---
- name: "launch backup"
become: yes
shell: sh backup-etcd.sh
args:
chdir: /etc/kubernetes/backup/
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.backup.launch
04-create-restoration-script.yml
Enfin le dernier playbook 04-create-restoration-script.yml permet de générer un script de restauration, prêt à l’emploi dans le dossier restore.
---
- name: "create script restoration"
become: yes
set_fact:
min_hostname : "{{ inventory_hostname | lower }}"
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.restore.prerequis
- name: "Deploy etcd restoration script"
become: yes
template:
src: restore-etcd.sh.j2
dest: /etc/kubernetes/backup/restore-etcd.sh
mode: u=rwx,g=r,o=r
when: "'k8sctp' in inventory_hostname"
tags: role_k8s_etcd_backup.restore.create
Il est également basé sur un template restore-etcd.sh.j2 qui reprend les commandes de etcd de restauration.
#!/bin/bash
# Vérifiez si un argument a été fourni
if [ "$#" -ne 1 ]; then
echo "Usage: $0
Vous trouverez le rôle et les fichiers associés dans mon repo github si vous le souhaitez.
Je n’ai qu’à régulièrement lancer mon rôle pour avoir un backup de ma base et disposer sur mes control planes de toutes les commandes nécessaires sous forme de scripts prêts à l’emploi.
Cliquez sur l'image pour l'agrandir.
Conclusion
S’assurer d’avoir des snapshots réguliers de sa base etcd est une bonne pratique qu’il ne faut pas négliger.
Mais s’assurer de pouvoir la restaurer est tout aussi important. Voici pourquoi il ne faut pas hésiter à s’exercer et tester régulièrement la procédure. Car il est possible que celle-ci évolue dans le temps ou fonctionne différemment au fur à mesure des versions de K8S.
À noter que durant la phase de restauration, etcd et les briques système étant indisponibles, votre cluster n’est plus opérationnel. Néanmoins, les pod actifs restent dans leur état sur les nodes de type worker. Mais plus aucune opération de scheduling ou de pilotage n’est possible.
À noter également qu’une fois la base etcd restaurée, Kubernetes va chercher à faire revenir ses assets dans l’état dans lequel ils s’y trouvent. Si entre le moment où vous avez fait le snapshot, et le moment ou vous procédez à la restauration des changements de configuration ont été faits, ceci sont perdu. Peut-être qu’une série d’actions va se déclencher pour revenir à l’état décrit dans le snapshot.
Certains composants peuvent ne pas apprécier, notamment des drivers tiers ou des addons que vous auriez pu installer en plus sur votre cluster.
Chaque cas est unique, et cet article n’a pour vocation que de vous donner des pistes pour organiser votre propre stratégie. Dans tous les cas, n’hésitez pas à régulièrement jouer vos scénarios.
Même si le faire en production est complexe, vous pouvez comme je l’ai fait moi reproduire votre infrastructure sur un cluster de dev pour vous entrainer. Essayez d’être au plus proche de votre production, l’idéal étant de le faire directement sur cette dernière à un moment ou un autre…mais mesurer bien le risque !