Backup et restauration K8S avec Velero
Introduction
Le passage à la conteneurisation a quelque peu modifié certaines tâches d’administration.
Prévu initialement pour manipuler de la donnée éphémère, la sauvegarde d’un conteneur, en dehors de sa configuration, n’a pas toujours été une priorité.
Mais aujourd’hui avec l’usage des volumes mappés au sein des conteneurs, il devient nécessaire de se préoccuper du backup des données hébergées au sein de ces derniers.
Plusieurs stratégies sont possibles, à commencer par des sauvegardes applicatives. Si par exemple, vous exécuter un conteneur de base de données, rien ne vous empêche d’y exécuter des commandes classiques de dump afin de générer des sauvegardes des bases sur un espaces externe au conteneur, comme sur un partage réseau.
Il est également possible, comme dans le monde de la VM, d’aller exploiter des solutions de sauvegardes spécialisées qui vont s’occuper de backuper l’intégralité de vos conteneurs en y incluant les volumes persistants.
Ce que je conseille, c’est de mixer les deux dans la mesure du possible.
Vous pouvez bénéficier d’une sauvegarde directement liée à votre application, au plus proche des données. L’inconvénient est d’être plus complexe à manipuler quand vous n’êtes pas un spécialiste de l’application en question.
Puis vous pouvez avoir une sauvegarde « plus packagée », intégrée à une solution centralisée et transverse à vos applications. La délégation de MCO (maintien en condition opérationnelle) est plus simple à réaliser. Mais dans ce cas vous amenez des dépendances supplémentaires et un coût de mise en œuvre plus complexe.
Dans cet article, nous allons parler d’une sauvegarde (et d’une restauration) basée sur une solution spécialisée.
Velero
Quand on parle de Kubernetes et du besoin de sauvegarder ses applications, y compris ses objets de type Persistent Volumes (pv) basés sur différents CSI (Container Storage Interface), on retrouve souvent le produit Velero.
Cliquez sur l'image pour l'agrandir.
Velero est open source et conçu pour la sauvegarde, la restauration et la migration des ressources Kubernetes.
Il a été créé à l’origine par la société Heption dont les fondateurs ne sont autres que des membres de l’équipe de création d’origine de Kubernetes (Joe Beda et Craig McLuckie).
En 2018, c’est VMware (maintenant Broadcom… snif) qui s’est porté acquéreur de la solution. Velero est cependant toujours aujourd’hui open source et reste la référence en termes de solutions de sauvegarde pour Kubernetes.
D’ailleurs beaucoup d’autres plateformes qui intègrent des fonctions de sauvegarde K8S sont en faite basées sur Velero. C’est le cas de OpenShift par exemple. L’une des alternatives les plus en vogue de Velero, reste Kasten, rachetée par le leader de la sauvegarde Veeam en 2020. Mais dans ce cas on parle d’une solution commerciale (et a priori assez coûteuse) qui connait de bons retours.
Avant de démarrer, il est important de noter que Velero reste dans la mouvance modulaire de Kubernetes.
Son usage et son exploitation dépendent beaucoup de la configuration de votre cluster K8S.
Velero fournit une base, puis peut être étendu pour prendre en charge des fonctions spécifiques et/ou des drivers CSI (Container Storage Interface) particuliers.
Il y’a donc tous un ensemble de prérequis à rassembler. Dans mon article, je vais me baser sur mon cluster dont j’ai décris l’installation à travers mon cookbook que je vous invite à parcourir. Il est conseillé de prendre plus particulièrement connaissance de la partie traitant du CSI Vmware, puis également de la notion de volume persistant évoqué dans cet article.
Velero est prévu pour stocker ses images de sauvegardes en dehors de votre cluster.
Il peut pour cela retenir plusieurs cibles de stockage, mais l’un des exemple et usage le plus courant est un bucket S3.
Dans mon cas, je suis utilisateur de Minio, une solution permettant de fournir un stockage S3 compatible en interne. La combinaison de Velero avec Minio est d’ailleurs un classique. N’hésitez pas à parcourir mon article sur la mise en place et le fonctionnement de Minio.
Objectifs
Comme à mon habitude, je vais d’abord commencer par résumer l’objectif technique de cet article.
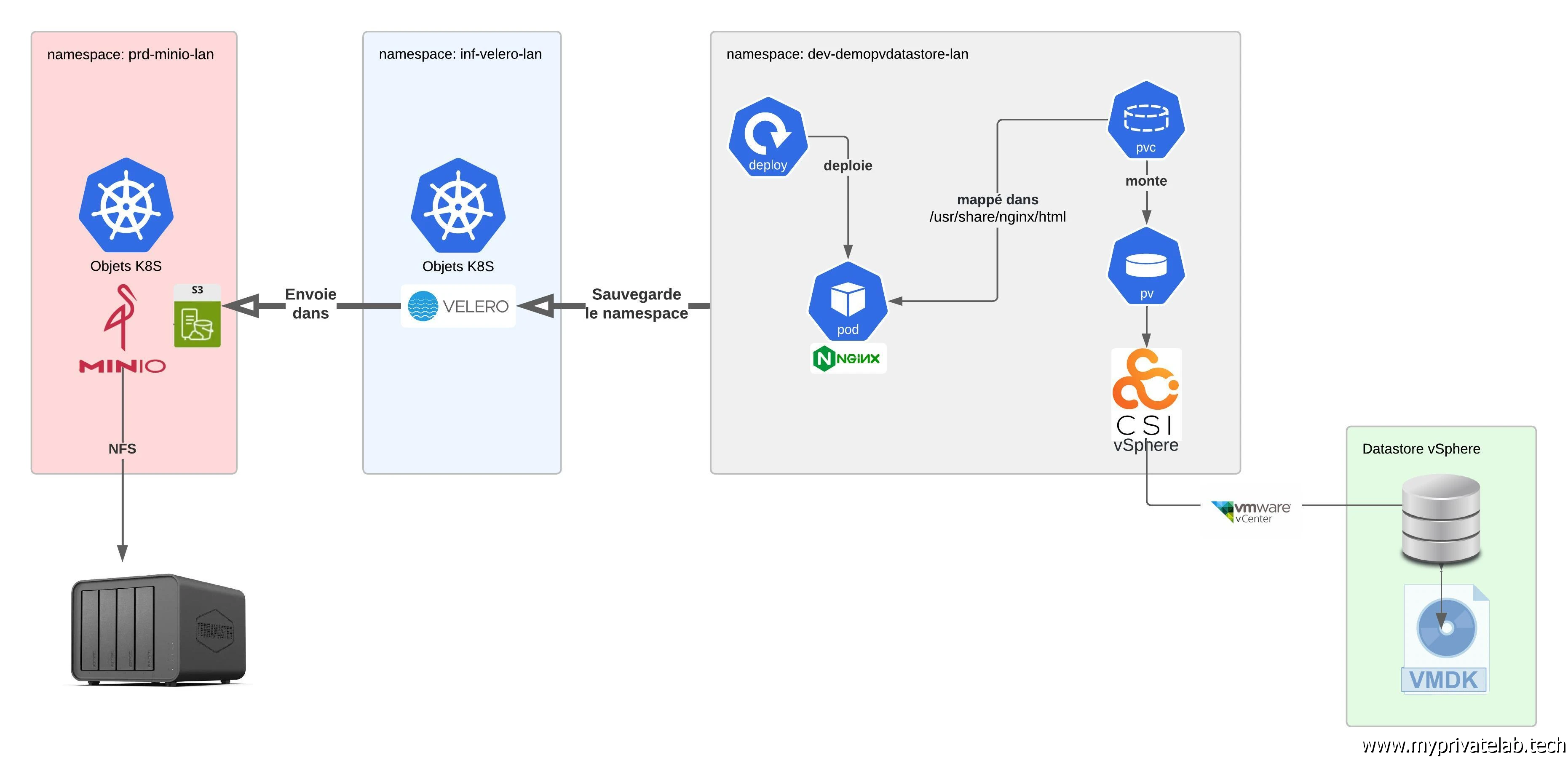
Le but est de déployer Velero dans un namespace dédié.
Puis, j’y ajouterais les dépendances nécessaires pour la prise en compte du driver CSI vSphere ainsi que l’activation des snapshots.
L’objectif sera de sauvegarder un autre namespace exécutant un serveur NGINX rattaché à un volume persistant de type block et basé sur le CSI vSphere.
L’image de sauvegarde devra inclure toute les objets K8S du namespaces et les données présentes sur le volume persistant.
Elle sera hébergée sur un bucket S3 présenté par mon instance Minio.
Une fois sauvegardé, on détruira le namespace de tests, puis on procédera à sa restauration pour s’assurer du bon fonctionnement de la configuration.
Cliquez sur l'image pour l'agrandir.
Principes
Maintenant qu’on sait où l’on veut aller, il est encore nécessaire d’avoir en tête le principe de fonctionnement de Velero pour ce cas d’usage. Je vous invite à bien vous imprégniez des points suivants pour mieux comprendre ce qui va suivre.
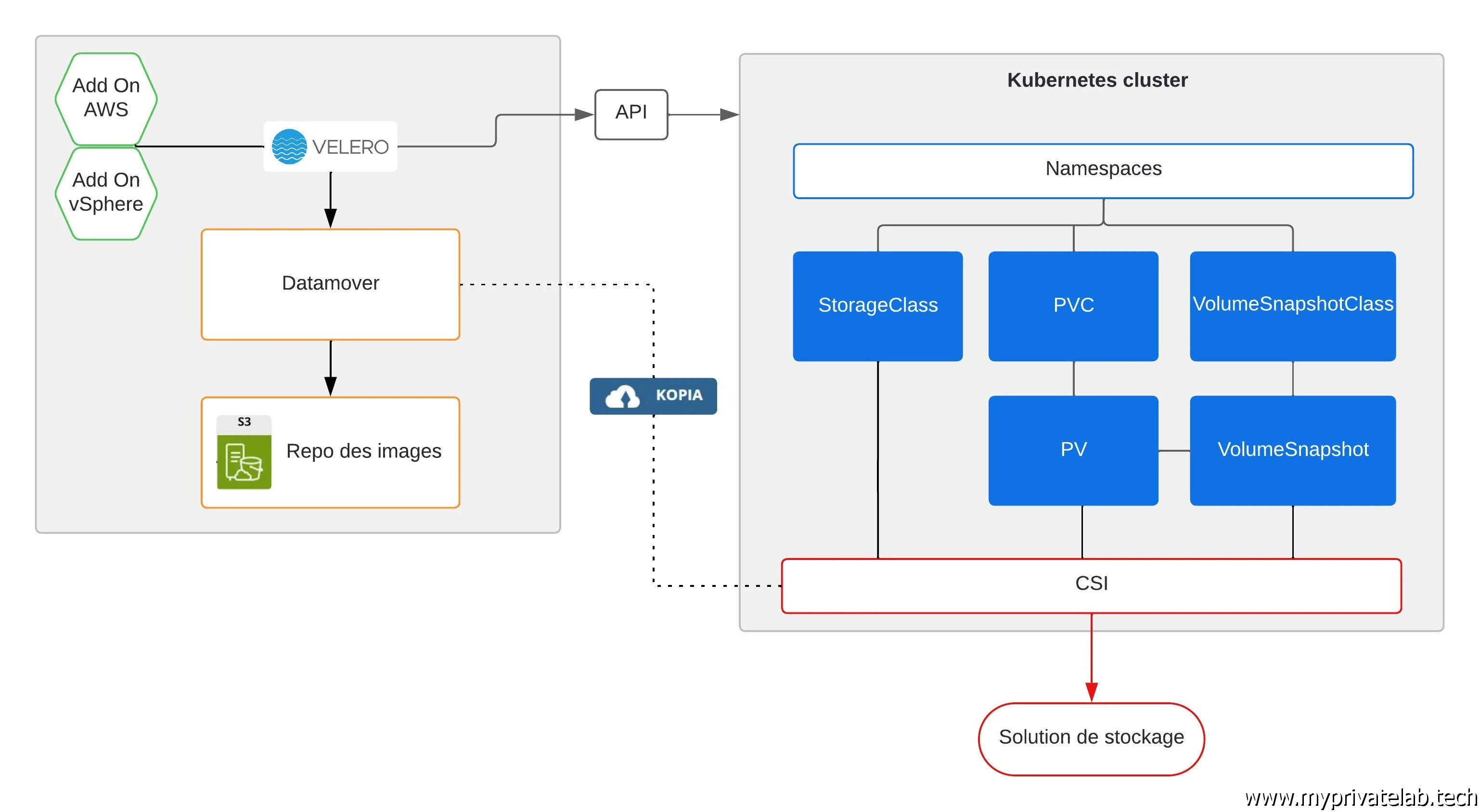
La logique de sauvegarde est:
- Velero et ses dépendances s’exécutent dans un namespace, il dispose des accès à l’intégralité du cluster et d’un accès au bucket S3 via un secret qui contient les informations d’authentification.
- Au déclenchement du backup, Velero scanne les objets contenus dans le namespace à sauvegarder, si les bonnes options sont précisées, il y inclut les PV.
- La configuration de chaque objet identifié est sauvegardée et exportée dans le bucket.
- Fonction du CSI utilisé, Velero va exploiter l’addon prévu pour:
- Généré un snapshot du volume: va donner lieu à un objet snapshot
- Monter ce snapshot pour y lire les données et les copier dans le Bucket via une solution de DataMover (ici Kopia): va donner lieu à objet datauploads
- Une fois les données copiées, le snapshot est libéré.
La logique de restauration est:
- Velero et ses dépendances s’exécutent dans un namespace, il dispose des accès à l’intégralité du cluster et d’un accès au bucket S3 via un secret qui contient les informations d’authentification.
- Au déclenchement de la restauration, Velero se base sur la configuration et la liste des objets présents au sein du bucket associé à l’image de sauvegarde utilisée pour recréer les objets en question sur le cluster.
- Une fois le ou les volumes persistent d’origine recréés, Velero positionne un pv temporaire contenant les données copiées du snapshot pris lors de la phase de backup.
- Velero copie les données de ce volume temporaire vers le volume persistent cible: : va donner lieu à un objet datadownloads
Toujours dans cette logique objet de Kubernetes, Velero implique la manipulation de nombreux nouveaux objets. Velero lui-même va venir étendre l’API par défaut de K8S.
Pour se donner une idée, voici un listing des principaux nouveaux objets liés à Velero, aux prerequis et addon nécessaires, impliqués dans les opérations de sauvegarde/restauration.
| Objets | Branche API |
|---|---|
| backuprepositories | velero.io/v1 |
| backups | velero.io/v1 |
| backupstoragelocations | velero.io/v1 |
| datadownloads | velero.io/v2alpha1 |
| datauploads | velero.io/v2alpha1 |
| deletebackuprequests | velero.io/v1 |
| downloadrequests | velero.io/v1 |
| podvolumebackups | velero.io/v1 |
| podvolumerestores | velero.io/v1 |
| restores | velero.io/v1 |
| schedules | velero.io/v1 |
| serverstatusrequests | velero.io/v1 |
| volumesnapshotlocations | velero.io/v1 |
| volumesnapshotclasses | snapshot.storage.k8s.io/v1 |
| volumesnapshotcontents | snapshot.storage.k8s.io/v1 |
| volumesnapshots | snapshot.storage.k8s.io/v1 |
| backuprepositories | backupdriver.cnsdp.vmware.com/v1alpha1 |
| backuprepositoryclaims | backupdriver.cnsdp.vmware.com/v1alpha1 |
| clonefromsnapshots | backupdriver.cnsdp.vmware.com/v1alpha1 |
| deletesnapshots | backupdriver.cnsdp.vmware.com/v1alpha1 |
| snapshots | backupdriver.cnsdp.vmware.com/v1alpha1 |
On peut aussi illustrer l'intéraction entres les principaux objets de bases et les composants d'une architecture Velero.
Cliquez sur l'image pour l'agrandir.
Deploiement de la solution
Définition du bucket de destination avec Minio
La première étape va consister à créer un bucket S3 dédié à la sauvegarde sous Minio. Je ne vais pas rentrer dans le détail de cette partie, car vous pouvez retrouver une description de l’usage de Minio dans mon article dédié.
Dans mon cas, j’ai un simple partage NFS dédié à Minio sur mon NAS. Minio expose ce dernier à travers une logique S3.
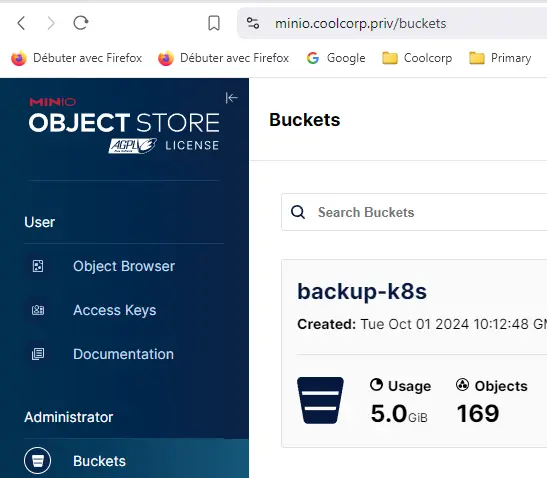
On crée un bucket, ainsi qu’un compte de service dédié associé à une politique d’accès. Cette dernière doit être configurée correctement pour permettre à Velero de lire et d’écrire toutes les données issues de la sauvegarde.
Dans l’exemple, le bucket s’appelle backup-k8s.
Cliquez sur l'image pour l'agrandir.
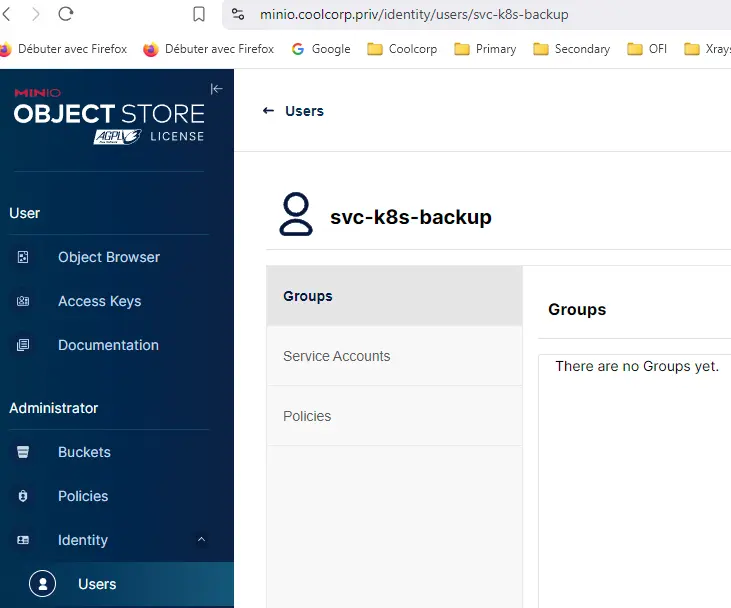
On utilise un compte svc-k8s-backup.
Cliquez sur l'image pour l'agrandir.
Le compte est rattaché à une police pol-backup-k8s
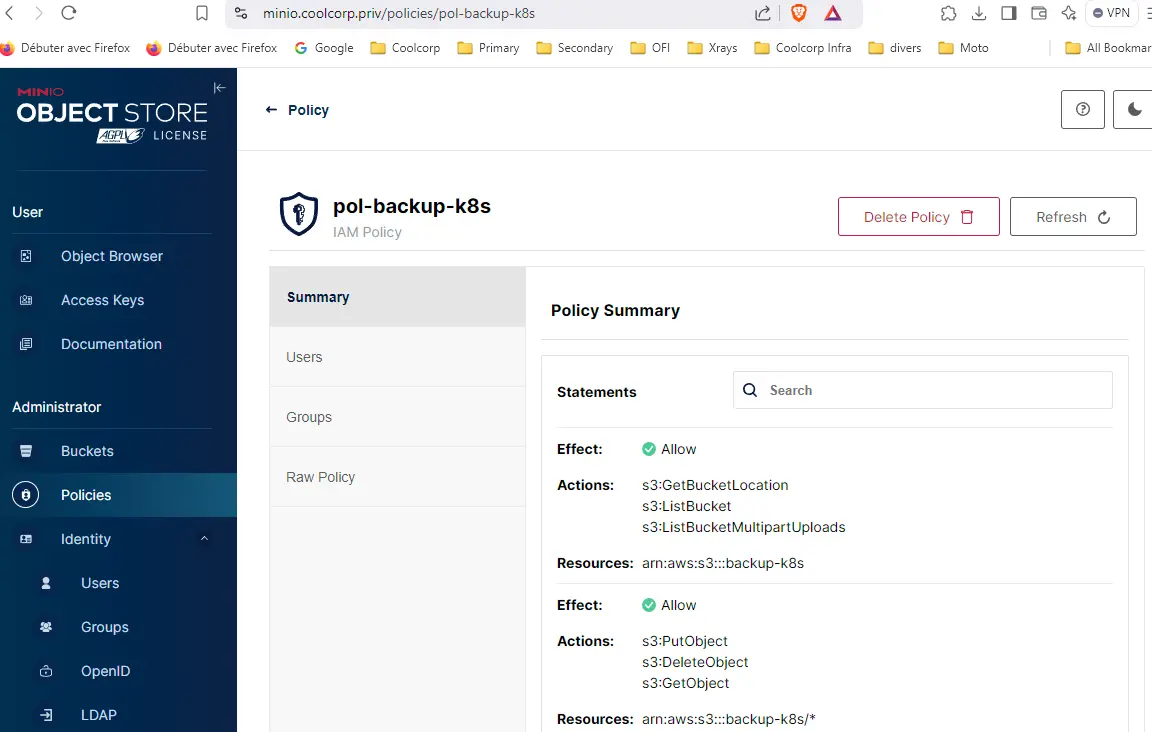
Cliquez sur l'image pour l'agrandir.
Voici le détail de la policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket",
"s3:ListBucketMultipartUploads"
],
"Resource": [
"arn:aws:s3:::backup-k8s"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:DeleteObject",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::backup-k8s/*"
]
}
]
}
L’élément important pour la suite est la récupération des informations d’authentification rattachées à ce compte. Pour cela on créer une clef d’accès composée d’un ID et d’un password que l’on va devoir mettre de côté et renseigner dans un fichier credential-velero.
Cliquez sur l'image pour l'agrandir.
Ce fichier doit avoir le formalisme suivant:
[default]
aws_access_key_id = id_issu_de_minio
aws_secret_access_key = secret_associe_a_id
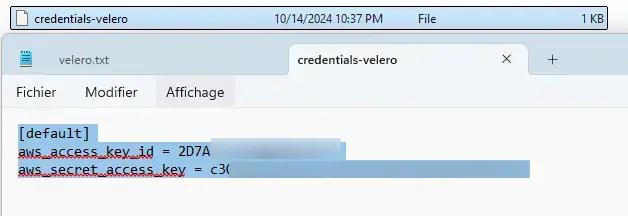
Cliquez sur l'image pour l'agrandir.
Bien entendu, c’est un fichier critique donc l’accès doit être protégé. Il va nous servir uniquement à l’installation de Velero puis pourra être supprimé par la suite (mais je vous conseille de le conserver dans un emplacement sécurisé au cas où).
Activation de la prise en compte de snapshots sur le cluster
Un autre prérequis va être d’activer la prise en charge des snapshots auprès de notre driver CSI. Dans mon cas c’est celui de vSphere. Il faut savoir qu’un CSI fournit ou supporte un ensemble de fonctionnalités propres à l’éditeur de ce dernier. Toutes les fonctionnalités ne sont pas forcement activées lors du déploiement.
Dans mon cookbook, au sein de la partie qui parle du déploiement du CSI vSphere, j’utilise la configuration par défaut, et cette dernière ne prend pas en charge les snapshots de volumes.
On va donc commencer par ajouter la configuration manquante. Cette partie peut varier d’un CSI à un autre, à vous de vérifier que:
- Velero supporte votre CSI
- Que votre CSI est configuré avec les prérequis nécessaires à son exploitation par Velero
Du côté du CSI vSphere, il va falloir récupérer un script sh fourni par VMware qui va s’occuper de pousser les dépendances manquantes pour l’usage des snaphots.
Ce script évolue au fur à mesure des versions du CSI, il faut donc l’inclure dans vos opérations d’update.
Au moment de cet article, c’est la version 3.3.1 du driver CSI qui est disponible, le script est donc récupérable à cette URL.
Il faut télécharger ce script sur le premier control plane de votre cluster,
wget https://raw.githubusercontent.com/kubernetes-sigs/vsphere-csi-driver/refs/heads/master/manifests/vanilla/deploy-csi-snapshot-components.sh

Cliquez sur l'image pour l'agrandir.
Puis en root, le rendre exécutable pour enfin le lancer avec cotre compte standart (le même avec lequel vous faites vos opération kubectl). Bien entendu il faut au préalable que votre CSI vSphere soit déployé.
Cliquez sur l'image pour l'agrandir.
Tout un ensemble d’actions va être réalisé par le script, et si tout va bien il devrait sortir sans erreur.
Si vous utilisez un autre CSI, renseignez vous sur sa prise en charge des snapshots et la maniere des les exploiter sur un cluster K8S.
Maintenant que les composants manquants sont déployés, il va falloir poursuivre par quelques étapes de configuration supplémentaire.
Un snapshot, peu importe le CSI, sous k8S est un objet. Il est associé à un autre objet qui est une VolumeSnapshotClass , un peu comme un persistent volume (pv) peut être rattaché à une classe de storage.
Il faut donc créer cette Objet VolumeSnapshotClass qui va exploiter le CSI vSPhere et les nouveaux éléments qu’on vient d’installer.
Le YAML volumesnapshotclass-csi-vsphere.yaml associé à cet objet est le suivant:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: volumesnapshotclass-csi-vsphere
driver: csi.vsphere.vmware.com
deletionPolicy: Delete
On le déploie ensuite avec la commande kubectl apply -f volumesnapshotclass-csi-vsphere.yaml.
Cet objet est transverse aux namespaces (comme les StorageClass) et on peut maintenant vérifier qu’il est bien présent sur le cluster avec la commande kubectl get volumesnapshotclass.

Cliquez sur l'image pour l'agrandir.
Mon cluster dispose d’une StorageClass (sc) associée au CSI vSphere. Elle est présentée au niveau de mon cookbook dans cet article.
Il faut que je mette à jour sa description pour y ajouter le support des snapshots par Velero. Cela se fait simplement en éditant le yaml qui m’a servi à la déployer et d’y ajouter le label velero.io/csi-volumesnapshot-class: "true".
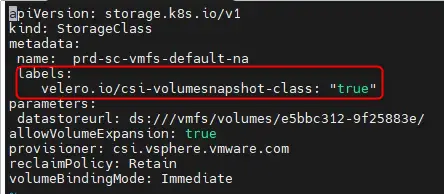
Cliquez sur l'image pour l'agrandir.
Je réapplique mon yaml pour mettre à jour la sc avec la commande kubectl apply -f 01-sc-datastore.yaml.
Préparation du namespace
On arrive presque à la fin des prérequis. Il nous reste à créer le namespace dédié à Velero.
Dans mon exemple, et pour respecter ma norme de nommage, le namespace va être appelé inf-velero-lan.
On le créé avec la commande kubectl create ns inf-velero-lan.
Dans ce namespace, je vais devoir héberger un secret contenant les identifications d’accès à mon vCenter, car l’addon Velero dédié à vSphere va devoir générer des snapshots de volumes et donc avoir accès au vCenter.
Ce secret va s’appuyer sur le même fichier de configuration csi-vsphere.conf utilisé lors du déploiement du CSI vSphere présenté dans cette partie de mon cookbook K8S.
Le fichier csi-vsphere.conf dispose du contenu suivant:
[Global]
cluster-id = "id_du_cluster_k8s"
[VirtualCenter "fqdn.votre.vcenter"]
insecure-flag = "true"
user = "compte_de_service_ayant_acces_au_vcenter"
password = "password_di_compte"
port = "443"
datacenters = "datacenter_vmware"
(plus de détails disponibles dans la partie dédiée au CSI Vsphere).
Les valeurs dépendent de la configuration vSphere.
On crée notre secret dans le namespace dédié à Velero avec la commande
kubectl -n inf-velero-lan create secret generic velero-vsphere-config-secret --from-file=csi-vsphere.conf
Il reste un objet configMap à créer. Un configMap permet de stocker la configuration d’un composant ou d’une application pour ensuite exposer cette configuration au sein d’un pod. C’est un peu comme un secret, mais sans être offusqué en base64 et donc avec un contenu jugé moins critiques en termes de confidentialité.
Ce configmap va être utilisé par les pods qui vont être déployés lors de l’installation de l’addon vSphere pour Velero.
Le contenu du fichier YAML associé velero-vsphere-plugin-config.yaml est le suivant:
apiVersion: v1
kind: ConfigMap
metadata:
name: velero-vsphere-plugin-config
namespace: inf-velero-lan
data:
cluster_flavor: VANILLA
vsphere_secret_name: velero-vsphere-config-secret
vsphere_secret_namespace: inf-velero-lan
Il fait appel au secret velero-vsphere-config-secret qu’on a créé précédemment.
On le déploie avec la commande kubectl apply -f velero-vsphere-plugin-config.yaml

Cliquez sur l'image pour l'agrandir.
On a enfin tous les prérequis nécessaires au déploiement de Velero.
Installation de Velero
Il y’a différente manière d’installer Velero. Dans cet exemple, je vous propose de passer par le binaire directement. On n’est dans un fonctionnement comme kubectl. Tout le pilotage de Velero, peut se faire à partir d’un simple exécutable sur votre poste. Cet exécutable va s’appuyer sur le même fichier de configuration que kubectl, présent dans votre profil utilisateur. Cela implique que vous devez avoir les droits nécessaires sur le cluster. En l’occurrence un droit assez élevé proche du cluster admin, car vous devez déployer beaucoup d’éléments.
Il suffit de récupérer le binaire sur le repo officiel propre à votre poste client. Dans mon cas c’est un exe pour Windows.
Je vous conseille de modifier votre path, pour pouvoir l’appeler n’importe où.
On lance l’installation de velero avec la commande:
velero install --provider aws --plugins velero/velero-plugin-for-aws:v1.10.1 --bucket backup-k8s --secret-file ./credentials-velero --backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://svc-minio-default.prd-minio-lan.svc.cluster.local:9000,publicUrl=https://minioapi.coolcorp.priv --features=EnableCSI --snapshot-location-config region=minio --namespace inf-velero-lan --use-node-agent --cacert .\CA-COOLCORP.crt
Elle est plutôt longue. Voici une explication détaillée des paramètres que l’on passe au binaire Velero.
- --provider aws: indique qu’on va se baser sur un repo de sauvegarde typée AWS (S3)
- --plugins velero/velero-plugin-for-aws:v1.10.1: indique la version du plug-in qu’on va utiliser pour le repo de sauvegarde. N’hésitez pas à contrôler la version via cette URL.
- --bucket backup-k8s: le nom du bucket S3 cible, en l’occurrence dans mon cas celui que j’ai créé dans Minio.
- --secret-file ./credentials-velero: on exploite le fichier créé en amont, contenant les accès au bucket, pour fournir à Velero les identifiants nécessaires à la lecture/écriture sur le bucket.
- --backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://svc-minio-default.prd-minio-lan.svc.cluster.local:9000,publicUrl=https://minioapi.coolcorp.priv:les différentes URL rattaché au bucket. Il est important de noter qu’on n’exploite deux url. L’une interne au cluster K8S (svc-minio-default.prd-minio-lan.svc.cluster.local:9000) et donc rattaché au service déployé lors de l’installation de Minio, puis une URL publique (https://minioapi.coolcorp.priv) visible à l’extérieur du cluster. N’hésitez pas à passer par mon articlesur Minio pour mieux comprendre ces deux urls.
- --features=EnableCSI: activation de la prise en charge du standard CSI
- --snapshot-location-config region=minio: indique la région AWS ou stocké le snapshot. En l’occurrence, étant donné qu’on « simule » AWS avec Minio, on se contente de mettre « minio ».
- --namespace inf-velero-lan: le namespace d’installation de Velero (sinon par défaut, Velero s’installe dans le namespace velero)
- --use-node-agent: on n’indique à Velero qu’il pourra utiliser les agents déployés sur les nodes, c’est en lien avec le déplacement des données du pv.
- --cacert .\CA-COOLCORP.crt: on indique le certificat de la CA rattachée à l’URL publique de Minio. Dans mon cas j’exploite ma propre PKI Windows. C’est donc simplement le certificat public de ma PKI qui a servi à générer le certificat propre à mon URL Minio, géré par Traefik, que je fournis en paramètre.
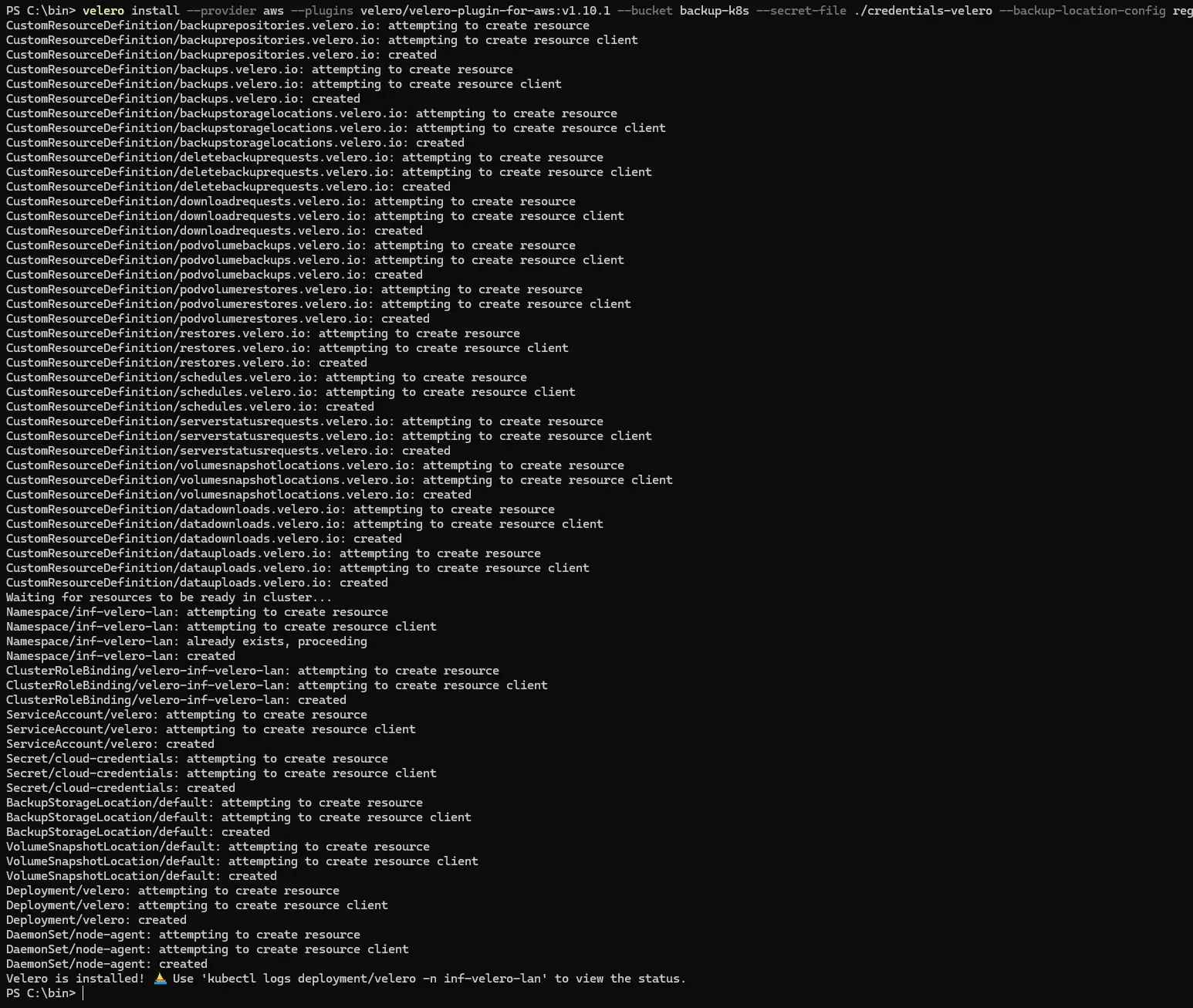
Cliquez sur l'image pour l'agrandir.
Dans la foulée de l’installation de Velero, on y ajoute le plug-in vsphere.
On utilise pour cela la commande:
velero plugin add vsphereveleroplugin/velero-plugin-for-vsphere:v1.5.4 -n inf-velero-lan
On peut valider le message d’avertissement.
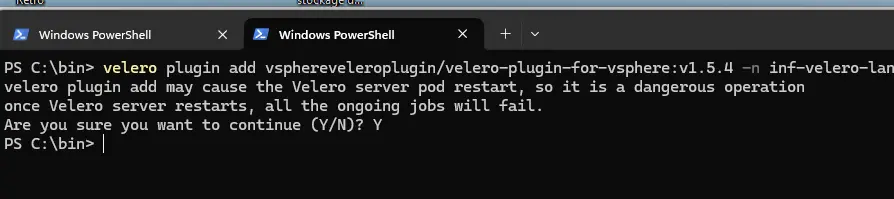
Cliquez sur l'image pour l'agrandir.
Comme pour le plug-in AWS, vérifiez la version du plug-in vSphere via cette URL.
À partir de là il va falloir attendre plusieurs minutes, le temps que tous les composants s’initialisent.
On peut vérifier avec la commande:
kubectl get pod -n inf-velero-lan
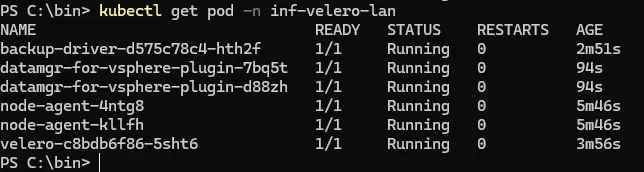
Cliquez sur l'image pour l'agrandir.
Vous devriez finir par avoir une sortie à l’identique de la capture. On n’y trouve le pod propre à Velero, mais également les pods liés au plug-in vSphere qui s’appuie sur le configmap et le secret qu’on a mis en place dans les prérequis.
Test de la solution
Test de sauvegarde
Pour tester la sauvegarde, je vais utiliser sun namespace démo dev-demopvdatastore-lan que j’avais déjà employé pour valider l’installation du CSI vSphere.
Je ne vais pas revenir en détail sur les différents YAML qui composent la démonstration. Il s’agit simplement d’exécuter un serveur NGINX au sein d’un pod dans lequel est mappé un volume persistant dans le chemin /usr/share/nginx/html du conteneur.
Le pod est en exécution, je peux le vérifier avec la commande: kubectl get pod -n dev-demopvdatastore-lan

Cliquez sur l'image pour l'agrandir.
Je me positionne dans le contexte du conteneur du pod, via la commande kubectl exec -it nom_du_pod -n dev-demopvdatastore-lan bash
En tapant df -h, on peut voir qu’un disque de 5Go est mappé à /usr/share/nginx/html. Ce disque correspond à mon pv.
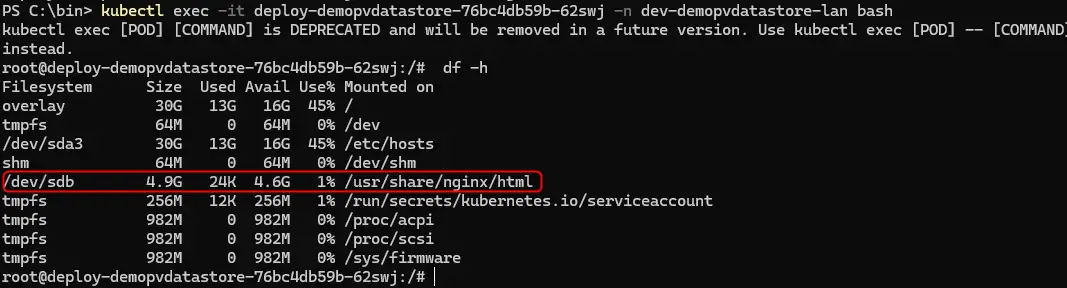
Cliquez sur l'image pour l'agrandir.
Je vais y inscrire une donnée, avec la commande touch, ce qui me permet d’avoir un fichier toto au sein du volume.

Cliquez sur l'image pour l'agrandir.
Le volume est bien un pv reposant sur le CSI vSphere, je peux en avoir l’information via la commande: kubectl get pv
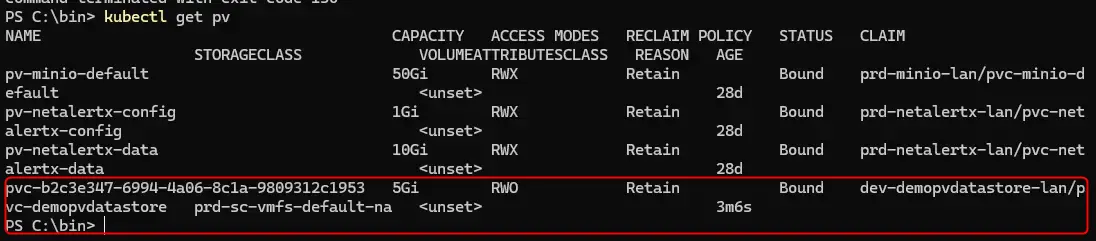
Cliquez sur l'image pour l'agrandir.
On peut lancer la sauvegarde de tout le namespace de démonstration via la commande:.
velero backup create backup-test-01 --include-namespaces dev-demopvdatastore-lan --namespace inf-velero-lan --snapshot-volumes --snapshot-move-data
Une fois encore la commande est un peu longue, mais simple à comprendre.
- velero backup create backup-test-01: on demande à Velero de créer une image de backup backup-test-01
- --include-namespaces dev-demopvdatastore-lan: on indique à Velero que les objets à sauvegarder sont dans le namespaces dev-demopvdatastore-lan
- --namespace inf-velero-lan: namespace ou se trouve Velero
- --snapshot-volumes: on demande à snapshoter les volumes
- --snapshot-move-data: on demande à déplacer les données des snapshots. Cette option est importante, car sans elle, Velero va simplement faire un snapshot des volumes, mais ces derniers resteront à la source. Les donnes contenues ne seront pas sauvegardées en dehors de vSphere. La restauration ne fonctionnera que si le snapshot est toujours disponible donc en considérant l’infra de départ toujours opérationnelle. Si on faisait face à un disaster recovery total, on ne pourrait pas restaurer la data. L’option en question permet de déplacer le contenu dans le bucket S3. C'est à ce niveau qu'on utilise Kopia. Je ne suis pas capable d'en dire plus sur cet usage, mais en gros Kopia est utilisé par Velero pour sauvegarder le contenu du snapshot vers le bucket S3 en combinaison avec l'addon vSphere

Cliquez sur l'image pour l'agrandir.
On peut contrôler régulièrement l’état d’avancement du backup avec la commande velero backup describe backup-test-01 -n inf-velero-lan --details.
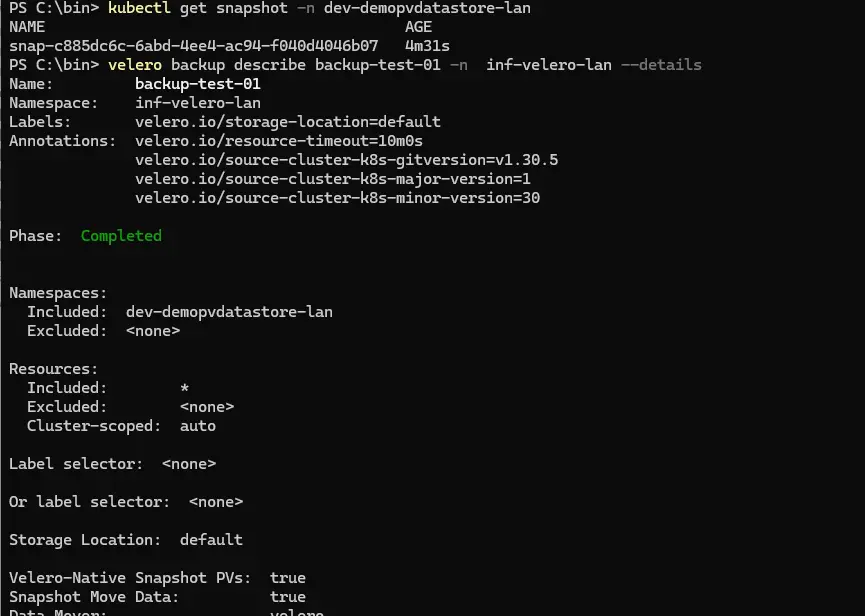
Cliquez sur l'image pour l'agrandir.
Si on regarde du côté du vCenter, on observe les opérations de snapshots.
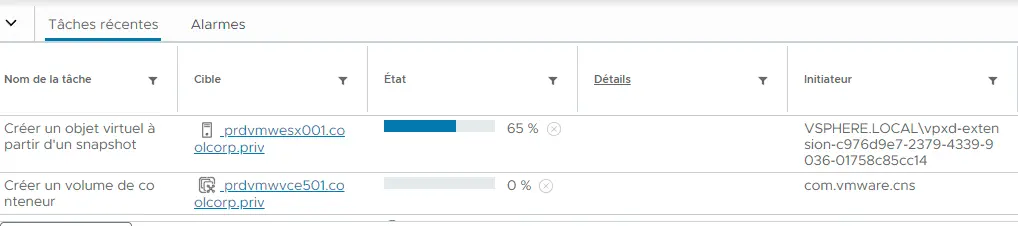
Cliquez sur l'image pour l'agrandir.
Snapshot qu’on peut lister avec la commande: kubectl get snapshot -n dev-demopvdatastore-lan (le snapshot est lié au namespace du pvc à sauvegarder)

Cliquez sur l'image pour l'agrandir.
Le snapshot est rattaché à un pv temporaire.
Si on se tourne du côté de Minio, on voit apparaitre des objets dans le Bucket.
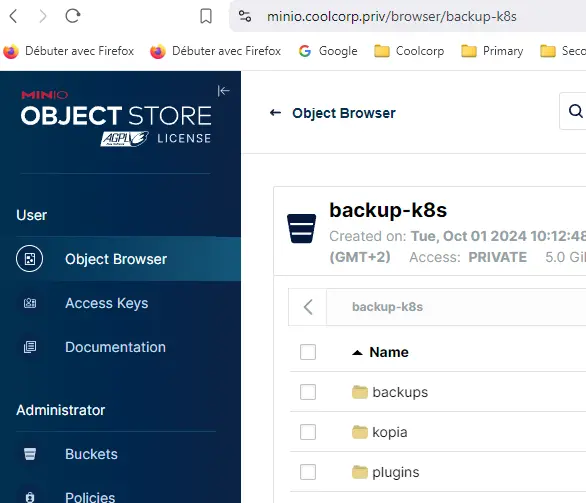
Cliquez sur l'image pour l'agrandir.
Il faut se méfier du statut du backup, parfois Velero indique que l’opération est terminée, mais en réalité, les données sont toujours en cours de déplacement, notamment du côté de l’addon vSphere qui continu de les copier.
Pour être certains de la fin de l’opération, il faut contrôler les logs des pod dédiés au déplacement des données issu du plug-in vSphere. Le pv temporaire associé rattaché au snapshot devrait aussi disparaitre.
En fin d'opération on peut lister les images de sauvegarde disponibles avec la commande velero get backup -n inf-velero-lan.
On doit y retrouver notre image avec la rétention par défault de 30 jours (ce parametre est bien entendu customisable au lancement du backup).

Cliquez sur l'image pour l'agrandir.
Une fois que tout est terminé, on peut détruire le namespace de démo et tout ce qui s’y rattache, incluant le pv.
J’exécute les commandes de suppression.
kubectl delete -f D:\Doc\GIT\gitlab.com\kub.coolcorp.priv\namespaces\dev-demopvdatastore-lan
kubectl delete ns dev-demopvdatastore-lan
kubectl delete pv nom_du_pv
À la fin le namespace dev-demopvdatastore-lan, ses objets et le pv n’existent plus sur le cluster.
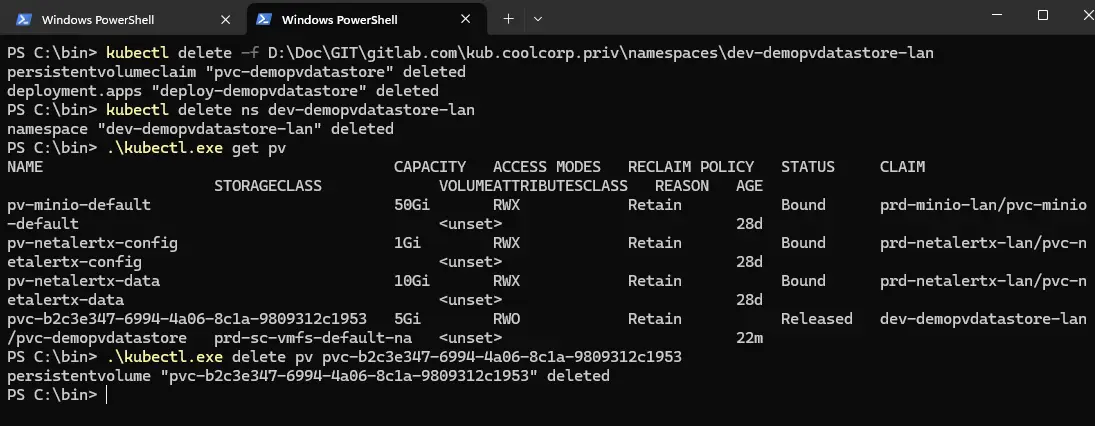
Cliquez sur l'image pour l'agrandir.
Test de restauration
On peut évaluer maintenant la restauration.
Si on liste les backups avec la commande velero get backup -n inf-velero-lan, on peut retrouver notre image de sauvegarde backup-test-01.
On va la retenir pour lancer la commande de restauration:
velero restore create --from-backup backup-test-01 --namespace inf-velero-lan

Cliquez sur l'image pour l'agrandir.
Pour le coup, les instructions sont simples à comprendre
On peut suivre le déroulé de la restauration avec la commande velero restore describe backup-test-01-id-restauration(donné en sortie de lancement de restauration) -n inf-velero-lan --details
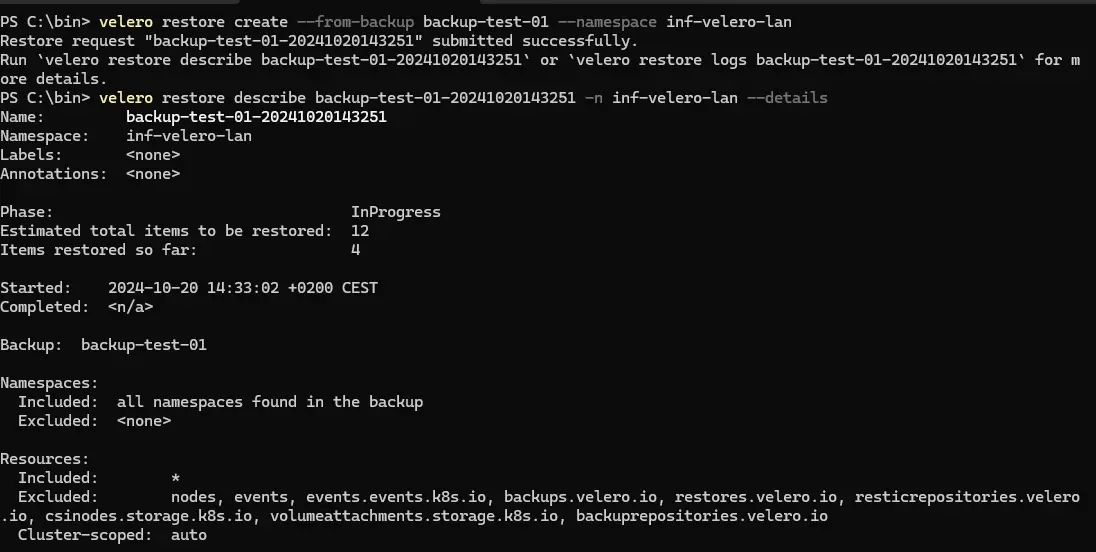
Cliquez sur l'image pour l'agrandir.
Si on liste les namepaces, on va vite revoir notre namespace de démo, signe que la restauration est en cours.
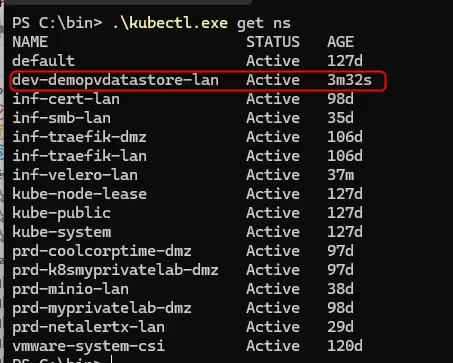
Cliquez sur l'image pour l'agrandir.
Au bout d’un certain temps, l’opération se termine. Dans mon cas je n’arrive pas à avoir un succès en sortie de commande d’informations. J’ai sans doute quelque chose à peaufiner, mais si je vérifie le statut de mon pod NGINX, celui-ci est bien à nouveau UP.

Cliquez sur l'image pour l'agrandir.
On peut rentrer dans son contexte, et venir vérifier le contenu du dossier /usr/share/nginx/html.
Le fichier toto est bien présent et montre que la donnée est restaurée.

Cliquez sur l'image pour l'agrandir.
L’opération a donc pu aller au bout et je retrouve mon application au complet avec sa donnée persistante.
N’ayant pas précisé d’option lors de la sauvegarde, l’image va demeurer 30 jours avant d’être purgée. Cette rétention est bien entendu configurable dans Velero.
Je vous invite à lire la documentation du produit pour avoir plus d’informations sur la création d’une politique de sauvegarde, incluant la planification des jobs. On peut définir une sauvegarde qui protège plusieurs namespaces, ou créer une politique par namespaces, par objets spécifiques…libre à chacun d’organiser son plan de sauvegarde par rapport à ses contraintes.
Conclusion
Au moment de l’écriture de cet article, Velero est l’outil privilégié pour la sauvegarde d’environnement Kubernetes. Pleinement inscrit dans la logique modulaire et extensible de K8S, il en reprend le fonctionnement par objet et…aussi sa complexité.
Le plus compliqué avec Velero, n’est pas son usage, mais de s’assurer d’avoir tous les prérequis avec les dépendances associées, configurées et fonctionnelles pour prendre en compte toutes les spécificités du cluster source.
C’est pourquoi il est important de comprendre la mécanique de fonctionnement et les imbrications entre composants.
Soyez très prudent sur l’interprétation des succès de sauvegarde. De manière générale, une sauvegarde n’a aucune valeur, si on n’a pas la certitude de pouvoir la restaurer. Cela implique de régulièrement tester vos backups, et ce conseil n’est pas propre à Kubernetes.
N’hésitez pas à croiser vos stratégies de protections. Avoir une image de sauvegarde Velero ne vous empêche pas d’avoir un dump applicatif en complément.
Protéger également vos images de sauvegarde, privilégier toujours une infrastructure de backup indépendante et isolée de votre infrastructure à protéger.
Dans l’exemple, Velero est installé sur le cluster qui contient les ressources à sauvegarder, ce n’est pas un souci si les images sont sorties sur un compostant tierces et sécurisé, par exemple dans mon cas un NAS.
Il sera toujours possible de faire relire le contenu des images de sauvegarde par une nouvelle instance de Velero.
Là où ma mini architecture présente une faiblesse, c’est que mon NAS est sur le même réseau local que mon poste de travail, ce qui implique qu’une attaque sur mon PC, naturellement plus exposé, pourrait avoir une répercussion sur mes images de sauvegardes (le fameux cryptolocker…).
Dans le cadre de mon mini lab, conçu avant tout pour des fins pédagogiques, ce n’est pas vraiment un problème, mais dans une vraie production, il devrait être interdit d’avoir un réseau de sauvegarde identique au réseau de base.
Pour en revenir à Velero, n’hésitez pas à l’implémenter, mais il faut assumer la charge de MCO qui en découle et le suivi nécessaire de son versionning (incluant toutes les dépendances tierces). C’est un outil performant et efficace, mais qui n’est pas au niveau d’un Veeam Backup, par exemple, en termes de simplicité d'usage et d'installation.
Je n’ai pas vraiment trouvé pour l’instant de GUI qui pourrait aider (si vous avez des propositions, je suis preneur). Des solutions d’intégration SaaS comme CloudCasa sont disponibles sous condition d’un cluster compatible (et de cout supplémentaire).
De manière générale, ne sous-estimez jamais les besoins de sauvegarde…et de restauration...mais restez cohérent dans votre politique en proposant quelque chose de techniquement maintenable. Ne promettez pas des sauvegardes que vous ne pourrez, vous, ou vos homologues futurs jamais restaurer
Déployez Velero et pensez à sauvegarder votre base etcd.
Vous aurez déjà une bonne structure pour protéger les applications hébergées sur votre cluster K8S.