Observabilité: Intégration dans Splunk via OpenTelemetry
Introduction
Les architectures conteneurisées associées aux microservices ont augmenté fortement la complexité de supervision et de suivi applicatif.
En augmentant le nombre d’asset et en faisant passer la donnée (ou la requete user) par de nombreuses fonctions qui, une fois combinées, donnent le service souhaité, on rend difficile l’identification d’une brique défectueuse.
Supervision VS Observabilité.....non Supervision & Observabilité
On utilise traditionnellement pour ce faire cette bonne vieille supervision. L’objectif est de surveiller l’état d’un système à l’aide d’indicateurs prédéfinis. Tout repose sur des seuils associés à des métriques clefs.
Mais en cas de problème, ce n’est pas forcément suffisant. Si la supervision permet d’agir sur bon nombre d’incidents, elle n’aide pas toujours à identifier une anomalie fonctionnelle. Savoir qu’un CPU tourne à 99% est une chose… savoir pourquoi en est une autre.
On va donc évoluer vers l'observabilité. On parle de la capacité d’un système à fournir suffisamment d’informations internes pour permettre de comprendre ce qui se passe, surtout face à un souci. Pour cela on va s’appuyer sur la supervision déjà évoquée et ses métriques associées, mais également sur des logs ainsi que sur des traces.
| Critère | Supervision | Observabilité |
|---|---|---|
| Finalité | Surveiller des problèmes connus | Comprendre des problèmes inconnus |
| Nature | Réactive | Proactive et analytique |
| Dépendance aux seuils | Forte (seuils, règles, alertes) | Faible (exploration dynamique) |
| Outils | Historiques, centrés sur l’infra | Modernes, centrés sur les apps et flux |
| Utilisation | Alerting, dashboards simples | Debug, root cause analysis, corrélation |
| Données | Agrégées et simples Riches | Corrélées et explorables |
Si on résume grossièrement, la supervision prévient quand ça va mal, l’observabilité permet de comprendre pourquoi ça va mal. Ce deuxième point devient très important quand on parle d’identifier un problème présent sur une application composée de multiples conteneurs qui échangent entre eux, à travers de nombreux nœuds du réseau.
L’application monolithique a l’avantage de réduire le périmètre de recherche… même si là aussi l’observabilité peut être un précieux allié.
Log et Trace: pareil ?
Il convient aussi de différencier la log de la trace.
La log est un message textuel horodaté émis par une application ou un système qui décrit un événement ponctuel ou un état.
La trace représente le parcours complet d’une requête (ou transactions) à travers plusieurs services ou composants
| Caractéristique | Log | Trace |
|---|---|---|
| Objectif principal | Décrire un événement ou une action | Suivre le chemin d'une requête |
| Format | Texte | Structure hiérarchique (spans) |
| Corrélation | Souvent isolé | Corrélé |
| Contexte | Local | Global |
| Temporalité | Horodaté individuellement | Ordonné avec des durées |
| Analyse | Recherche de messages | Analyse de performances, bottlenecks |
Introduction à Splunk Enterprise
Cliquez sur l'image pour l'agrandir.
Comme d’habitude dans l’IT, il n’existe pas une seule réponse possible pour traiter ces enjeux. Vous pouvez choisir d’utiliser différents outils spécialisés. Certains sont plutôt orientés vers la supervision, d’autres vers l’observabilité. Des éditeurs proposent également des suites complètes pouvant supporter tous les besoins.
Personnellement, j’aime bien combiner les outils et chercher le meilleur dans chacun. Je n’ai cependant pas envie de tomber dans le syndrome de la « caisse à outils » où l’on finit par collectionner toutes les dernières tendances du moment sans bien les maitriser.
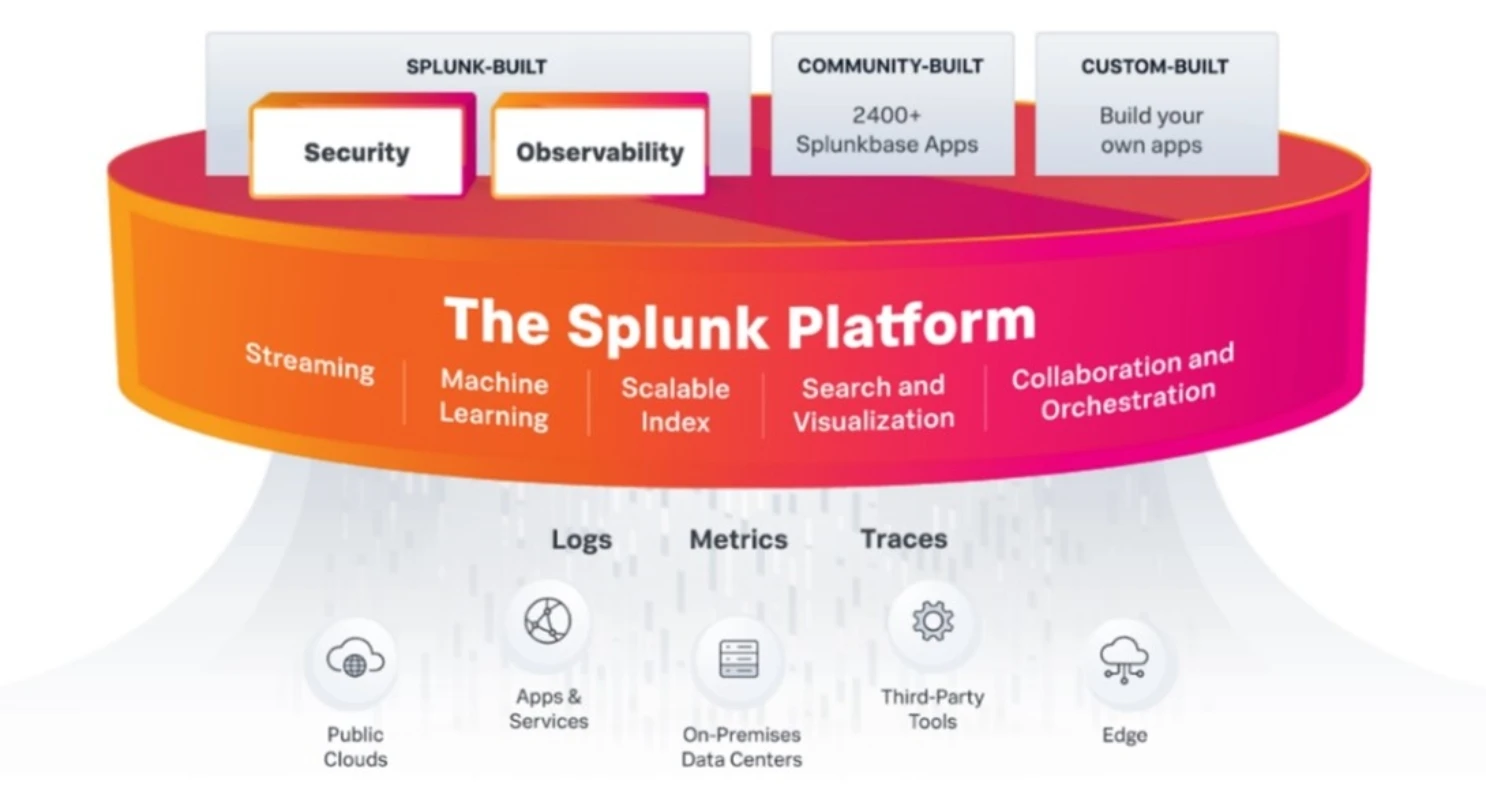
Dans la liste des applicatifs avec lesquels je travaille, on retrouve Splunk Enterprise de l'éditeur du même nom. À l’origine imaginé comme un puits de logs dans lequel il est possible de déverser toute donnée structurée, Splunk est devenu un écosystème complet extensible par de nombreuses fonctionnalités tierces, gratuites ou payantes.
Splunk fonctionne grâce à un moteur interne qui stocke des données dans des index, pour ensuite extraire des champs à utiliser dans des requêtes à l’aide d’un langage inspiré de SQL (le SPL : Splunk Search Processing Language).
Il devient possible de corréler les informations, en combinant l’interrogation de plusieurs index via une uniformisation des noms de champs. Par exemple, on peut commencer par identifier une IP source issue d’un log de firewall, puis la retrouver dans les logs d’un serveur web afin de suivre son activité et d’identifier facilement les données auxquelles elle a eu accès.
On peut utiliser le SPL pour regrouper le tout au sein de Dashboard et réaliser des calculs statistiques, comme par exemple, extraire les temps de passage d’une requête du firewall au site web. On obtient alors une métrique de performances qui peut nous aider à identifier un problème de communication au sein du système.
On est proche d’un outil bien connu de l’open source, comme ELK (Elastic Stack). La différence notable entre les deux produits est que la majorité de l’extraction des champs et de leurs opérations se font sous Splunk après l’indexation. Cela sous-entend que la donnée est toujours « brute » sans modification spécifique (hors exception) et que c’est au requêtage des données que les champs sont extraits et manipulés.
Cela implique qu’il devient possible de facilement modifier le découpage et le nommage des champs sans avoir à réindexer la donnée.
Afin de faciliter justement cette manipulation des champs, Splunk dispose d’un « store » où il va être possible de récupérer des technical add-on automatisant le découpage et l’extraction des champs fonction de la source.
En plus de ces technical add-on on retrouve dans le store ce qu'on appelle des apps. Ce sont des extensions à Splunk, incluant des dashboard déjà réalisés, des découpages de champs préconfigurés rendant ainsi beaucoup plus simple le suivi des événements autour d’un produit spécifique.
Certaines apps sont gratuites, d’autres sont payantes. Elles peuvent être proposées par Splunk, par des partenaires, par d'autres éditeurs, par des équipementiers ou par la communauté. Il devient ainsi très simple d'intégrer et d'exploiter ses logs dès lors qu'on utilise des solutions et/ou du matériel connus.
S’ajoutent deux apps majeures directement développées par Splunk qui sont:
- Splunk Enterprise Security: c’est la solution SIEM de l’éditeur (Security Information and Event Management). Elle permet la collecte, la corrélation, l’analyse et l’alerting autour des évènements de sécurité dans un système d’information. C’est devenu l’application phare.
- Splunk Observability Cloud: c’est la suite d’observabilité qui va combiner métrique et logs issus des infrastructures/applications onprem et cloud d’un système d’information.
Il reste néanmoins important de comprendre que, peu importe l’app, toutes fonctionnent sur le moteur et la couche Splunk Base qu’il est possible d’utiliser seul afin d’y construire ses propres dashboards et de créer ses propres extractions de champs, jusqu'à développer ses propres applications.
Cliquez sur l'image pour l'agrandir.
Splunk n’est malheureusement pas une solution gratuite. L’éditeur est d’ailleurs même réputé pour avoir une tarification élevée, sachant qu’il est possible d’installer l’outil et les apps onprem, ou de souscrire à une offre SaaS managée. Plusieurs modes de licences existent, comme par exemple, un paiement pour une quantité journalière de données indexées.
Il reste néanmoins possible d’installer Splunk Enterprise et de l’utiliser gratuitement sous conditions d’une limite d’indexation par jour de 500MB.
C’est déjà intéressant pour se former à l’outil, se donner une idée de ses capacités, voire même de le conserver ainsi pour une petite infrastructure.
C’est d’ailleurs grâce à cette offre gratuite que je peux réaliser cet article.
Le but ici n’est pas de rentrer dans le détail du fonctionnement de Splunk, mais plutôt d’illustrer la théorie par la pratique. Je souhaite aussi vous donner un aperçu de ce qu’il est possible de faire autour d’une plateforme Kubernetes.On va déployer Splunk sur une VM Rocky Linux 9.6 puis l’utiliser pour récolter et analyser tous les logs issus de mon cluster Kubernetes.
Introduction à OpenTelemetry

Cliquez sur l'image pour l'agrandir.
Cela va être aussi l’occasion d’évoquer un "outil" qui ne cesse de faire parler de lui OpenTelemetry.
Splunk a beau être une solution payante, l’éditeur est très engagé dans certains produits OpenSource et s’appuie d’ailleurs en partie sur ces derniers pour concevoir son offre.
OpenTelemetry est un standard open source qui permet de collecter, structurer et exporter des données d’observabilités, soit comme évoquées en début d’article: les métriques, les logs et les traces distribuées.
Splunk est un participant important au projet et s’investit dans son développement et son usage.
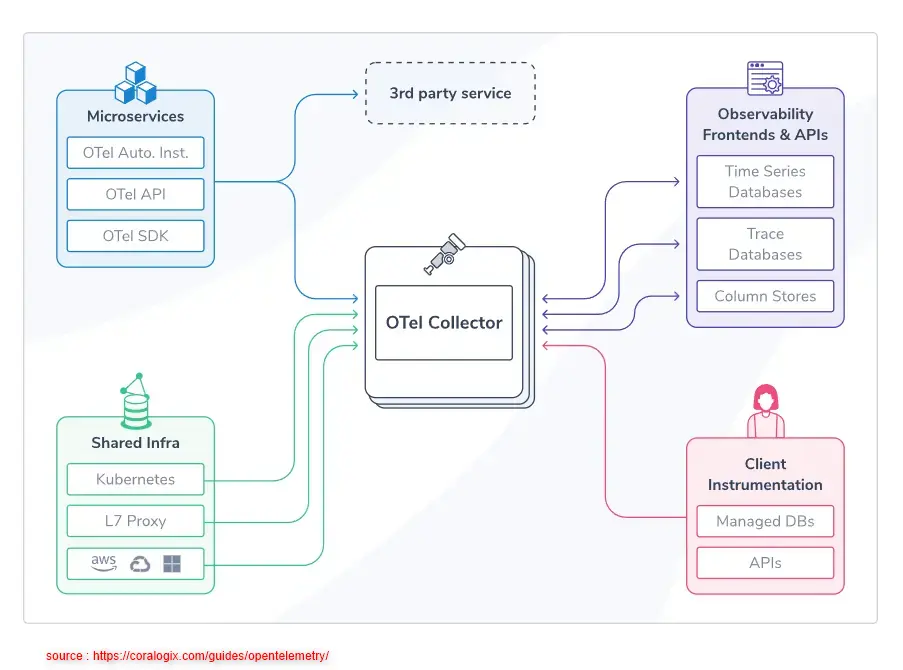
OpenTelemetry s’articule autour des composants clefs suivants:
| Composant | Rôle |
|---|---|
| SDKs clients | Intégrés dans le code (Python, Java, Go, etc..) pour capturer traces/métriques/logs |
| Collector (agent) | Processus qui reçoit les données, les traite, et les envoie vers un backend |
| Exporters | Adaptateurs vers les backends (Splunk, Prometheus, OTLP, Jaeger, etc...) |
| Instrumentations | Librairies prêtes à l’emploi pour frameworks (Django, Flask, Spring, etc.) |
| Protocole | OTLP (OpenTelemetry Protocol), un protocole performant et standardisé |
Cliquez sur l'image pour l'agrandir.
L’avantage d’un standard comme Open Telemetry est de pouvoir se fier à un seul agent de collecte de données, quel que soit le traitement final, à condition que ce dernier soit compatible avec OpenTelemetry.
On bénéficie aussi d’un dictionnaire commun autour des items à collecter.
OpenTelemetry permet donc la supervision/l’observabilité des applications avec un seul langage et protocole tout en gardant la liberté du backend.
Pour l’intégration de Kubernetes dans Splunk, nous allons donc déployer des agents OpenTelemetry prépackagés sur chaque nœud.
Il s’agira d’utiliser un agent fourni par Splunk, mais qui reste basé sur le standard OpenTelemetry.
Déploiement
Installation de Splunk Enterprise
Usage du package RPM
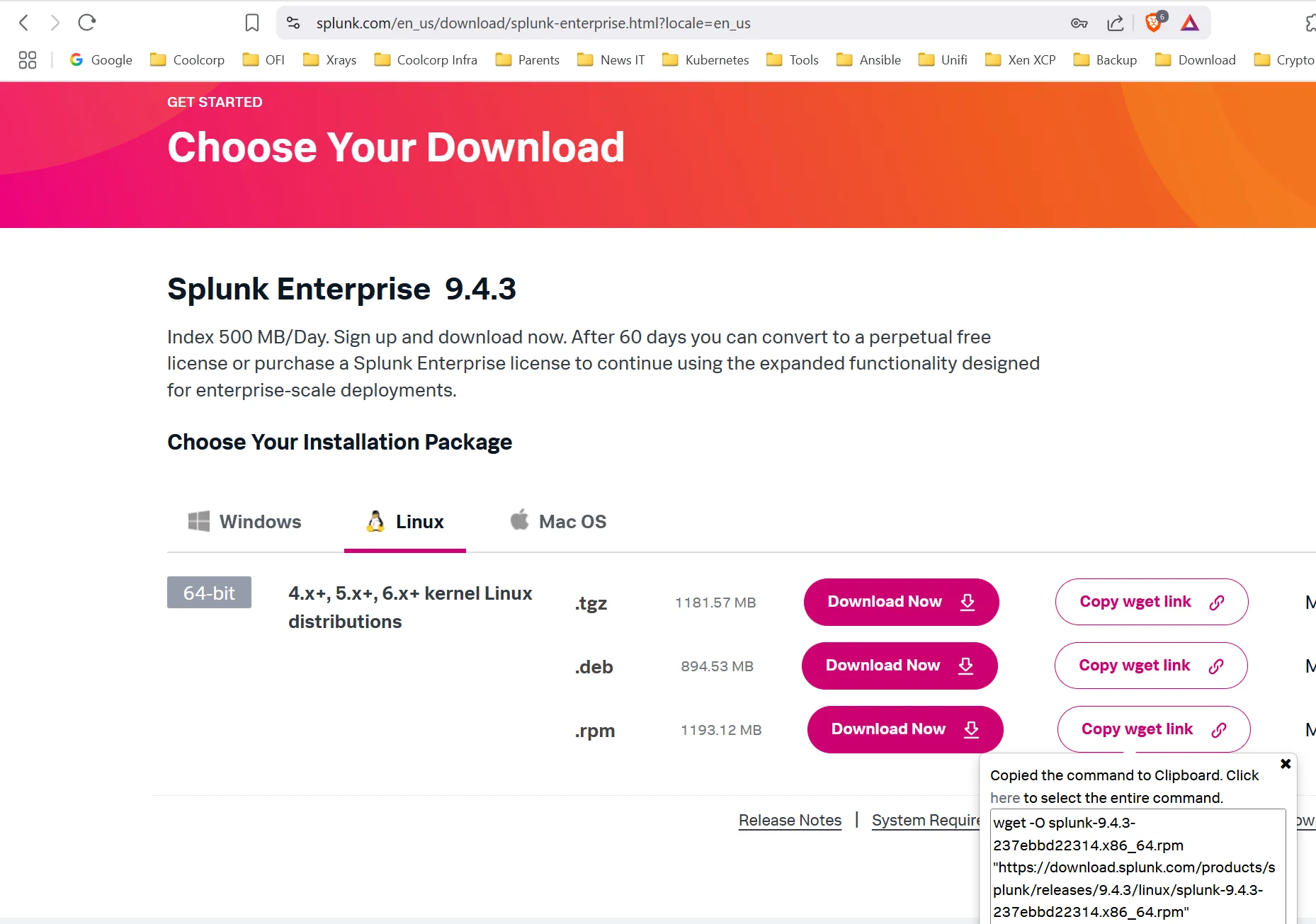
Pour récupérer les binaires Splunk, il suffit de se créer un compte gratuitement sur le site de l’éditeur. Il n’est pas nécessaire d’avoir une adresse email pro.
Une fois le compte créé et connecté sur le site, on peut télécharger Splunk Base (Splunk Enterprise) sous différents formats.
Pour le besoin de cet article, on choisit le package rpm.
On peut récupérer directement la commande wget pour récupérer ce dernier sur le serveur cible destiné à accueillir la solution.
Cliquez sur l'image pour l'agrandir.
wget -O splunk-9.4.3-237ebbd22314.x86_64.rpm "https://download.splunk.com/products/splunk/releases/9.4.3/linux/splunk-9.4.3-237ebbd22

Cliquez sur l'image pour l'agrandir.
La version est à adapter
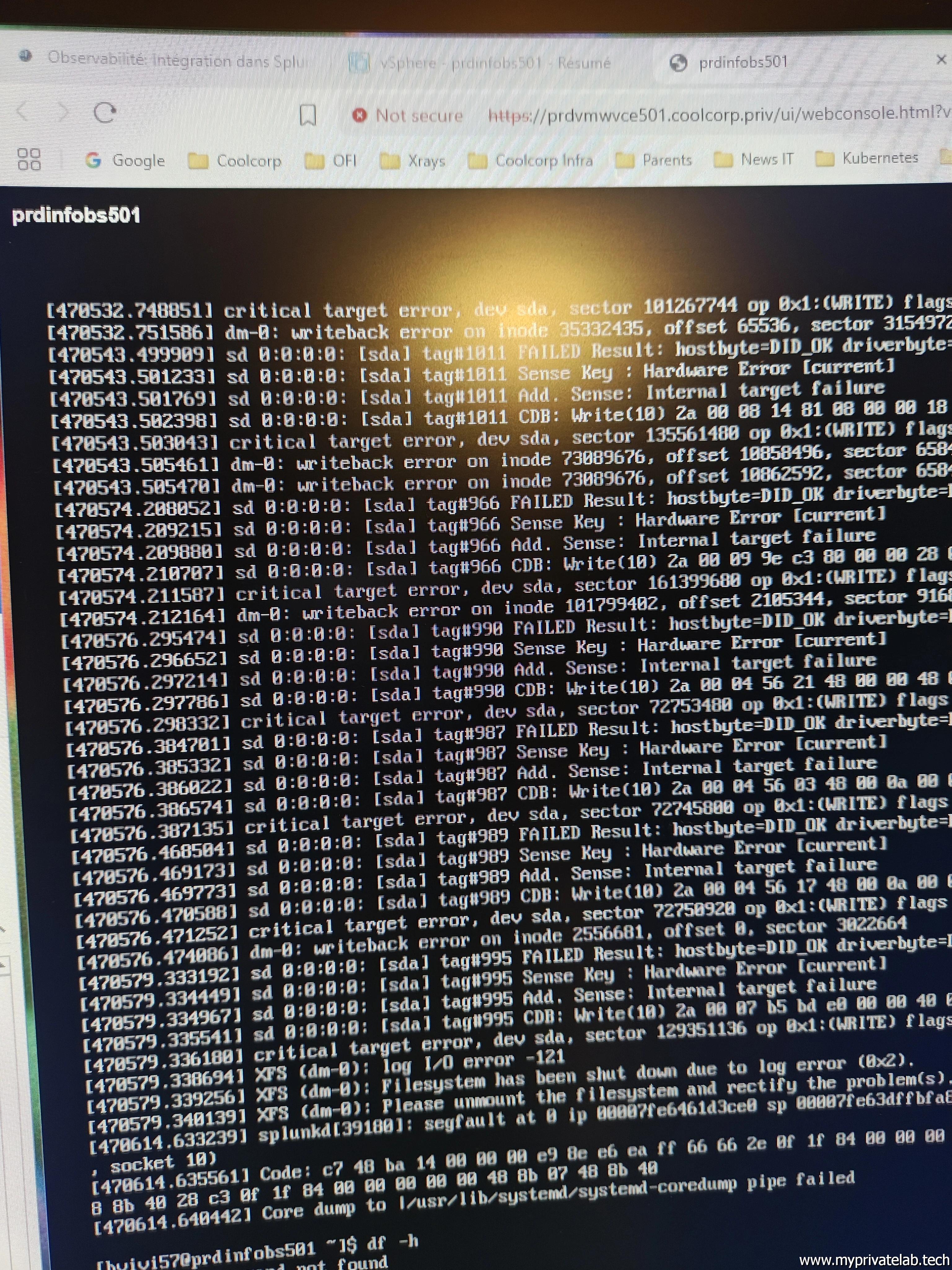
On est sur une VM RocyLinux 9.6 avec 8 vCPU, 16Go de mémoire et 120Go de disque (SSD obligatoire). Splunk est potentiellement un consommateur de ressource. Attention, fonction de la volumétrie de vos logs, vos SSDs peuvent rapidement souffrir.
Pour la petite anecdote, j'écris souvent mes articles en plusieurs fois avant d'arriver au résultat complet, laissant passer quelques jours parfois entre deux séances d'écriture. 48H ont suffi pour rendre HS ma VM en raison d'erreur disque... Heureusement, j'avais pu identifier avant plantage et grâce à Splunk... qu'un de mes pods était responsable d'un très gros envoi de logs. J'ai donc stoppé ce pod, pu remettre en place ma VM (merci gparted) et poursuivre mon tutoriel..
Cliquez sur l'image pour l'agrandir.
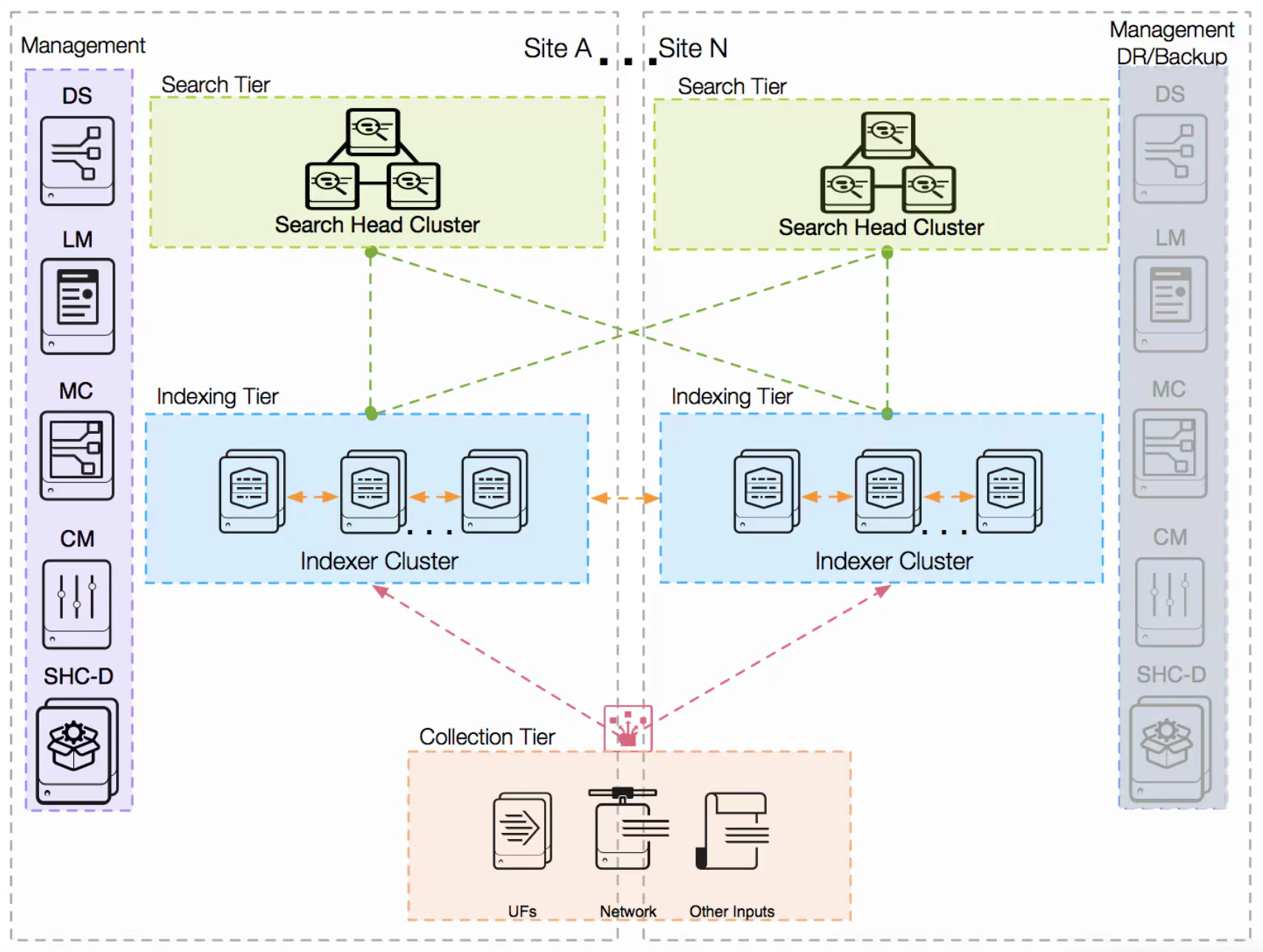
Habituellement, pour une installation en production, on va décomposer Splunk Enterprise sur différents serveurs en activant, pour certains, uniquement un nombre limité de fonctions.
On va retrouver, par exemple des Indexeurs, chargés uniquement de recevoir la donnée. Il est possible d’avoir des pool d’indexeur qui pourront dupliquer la donnée si nécessaire ou se répartir la charge. On installera également des Search Head, dédié cette fois-ci à l’interrogation des données et à la construction des dashboard.
Il est possible de réserver des Search Head à des usages ou des équipes spécifiques, Splunk autorisant une gestion des droits granulaire à plusieurs niveaux. D’autres sous composants peuvent être déployés, mais il est important de comprendre que la majorité de ces derniers se déploie toujours à partir du meme binaire. On joue ensuite sur la configuration de la couche installée, pour activer/désactiver telle ou telle fonction.
Cliquez sur l'image pour l'agrandir.
Dans notre cas, on va laisser tout activé pour exploiter une installation « tout en un » où indexeur et search head sont sur le même serveur.
Avant de lancer l’installation, il est conseillé de créer un user dédié:
useradd splunk

Cliquez sur l'image pour l'agrandir.
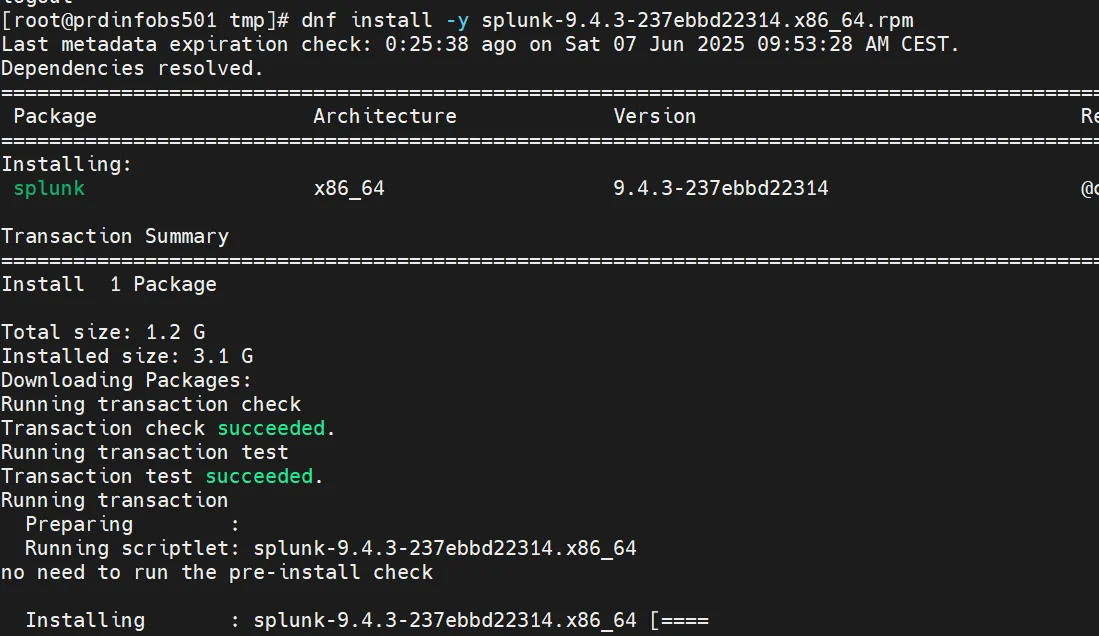
Une fois le package sur le serveur, on peut lancer l’installation avec la commande:
dnf install -y splunk-9.4.3-237ebbd22314.x86_64.rpm
Cliquez sur l'image pour l'agrandir.
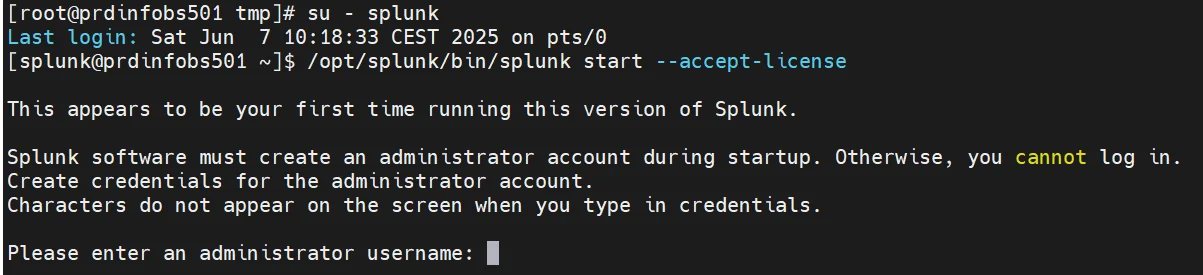
On passe ensuite dans le contexte de l’utilisateur splunk pour lancer une première fois l’instance:
su - splunk

Cliquez sur l'image pour l'agrandir.
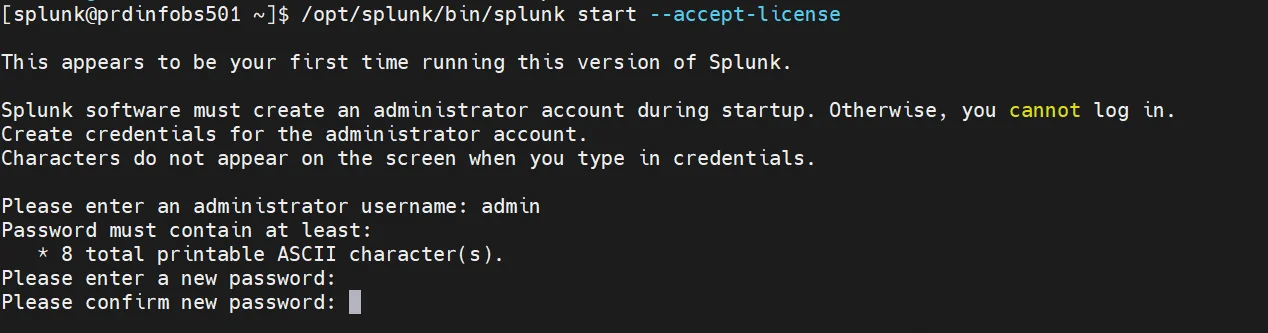
/opt/splunk/bin/splunk start --accept-license
Cliquez sur l'image pour l'agrandir.
Il nous est demandé de renseigner l’utilisateur et le mot de passe du compte admin.
Cliquez sur l'image pour l'agrandir.
Une fois l’instance démarrée, on peut la couper dans la foulée.
/opt/splunk/bin/splunk stop
Cliquez sur l'image pour l'agrandir.
On revient à l’utilisateur root. On active la prise en charge de Splunk par systemd pour obtenir un démarrage automatique de l’instance. Il est important de noter qu’on souhaite utiliser un utilisateur dédié pour l’application afin d’éviter que l’instance démarre avec le compte root.
/opt/splunk/bin/splunk enable boot-start -user splunk -systemd-managed 1

Cliquez sur l'image pour l'agrandir.
Après avoir configuré le démarrage automatique, on lance l’instance et on s’assure que tout fonctionne correctement.
systemctl enable Splunkd
systemctl start Splunkd
systemctl status Splunkd
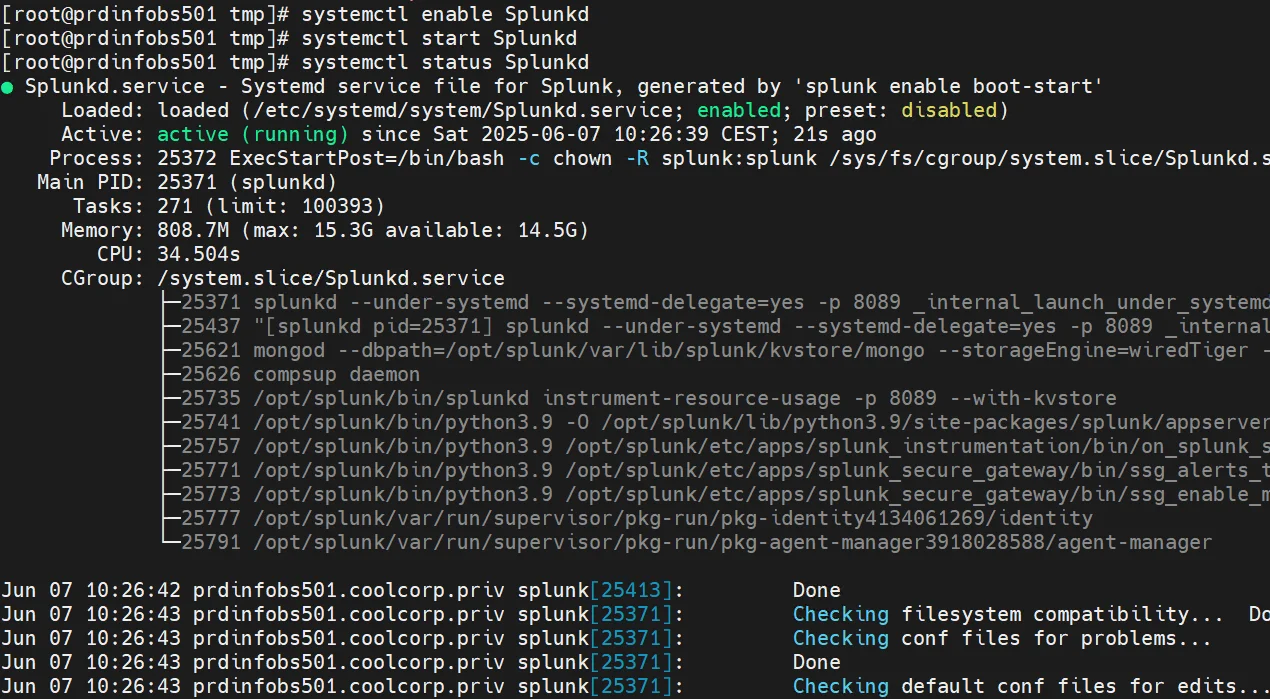
Cliquez sur l'image pour l'agrandir.
À ce stade, Splunk Enterprise est démarré et prêt à être utilisé.
Création du certificat
Mais, avant d’accéder à l’interface, on va quand même exploiter un certificat pour utiliser correctement HTTPS.
Je ne vais pas rentrer dans le détail. Il s’agit de générer son csr et sa clef privée avec openssl. Dans mon exemple, mon serveur s’appelle prdinfobs501.coolcorp.priv et je souhaite utiliser l’URL HTTPS://log.coolcorp.priv. Voici la commande associée pour mon cas:
openssl req -new -nodes -sha256 -keyout log.coolcorp.priv.key -out log.coolcorp.priv.csr -newkey rsa:4096 -subj "/C=FR/ST=Ile-de-France/L=Paris/O=COOLCORP/OU=Infrastructure/CN=log.coolcorp.priv" -reqexts SAN -config <(printf "[req]\ndistinguished_name = req_distinguished_name\n[req_distinguished_name]\n[SAN]\nsubjectAltName=DNS:log.coolcorp.priv,DNS:prdinfobs501.coolcorp.priv")
Cliquez sur l'image pour l'agrandir.
J’utilise le csr (Certificate Signing Request) obtenu pour générer mon certificat via ma PKI interne (une CA Windows). À chacun d’adapter selon sa situation (vous pouvez aussi vous contenter de HTTP…)
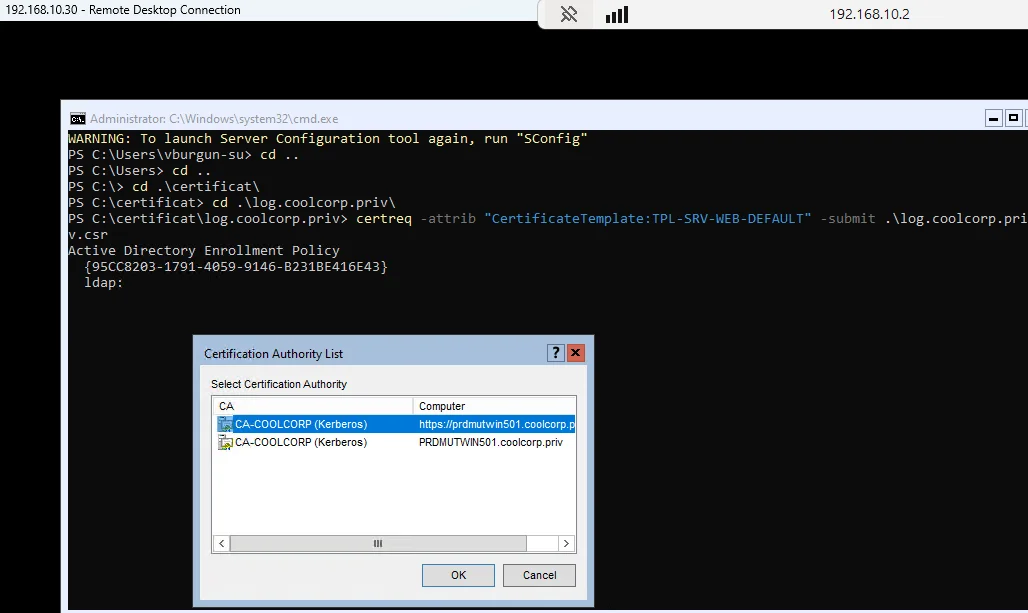
Cliquez sur l'image pour l'agrandir.
Je copie ma clef et mon certificat sur le serveur dans le dossier /opt/splunk/etc/auth/certs
(je créer le dossier au besoin)
cd /opt/splunk/etc/auth/
mkdir certs

Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Je modifie le fichier de configuration /opt/splunk/etc/system/local/web.conf pour activer la prise en charge HTTPS et indiquer la clef et le certificat à utiliser.
vi /opt/splunk/etc/system/local/web.conf
[settings]
enableSplunkWebSSL = true
privKeyPath = /opt/splunk/etc/auth/certs/log.coolcorp.priv.key
serverCert = /opt/splunk/etc/auth/certs/log.coolcorp.priv.cer
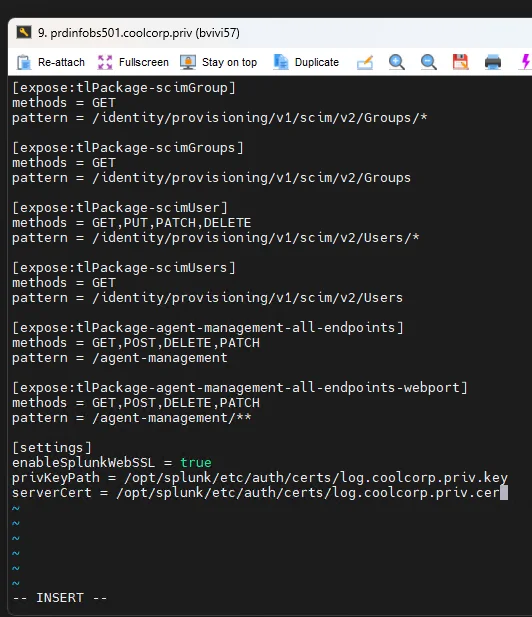
Cliquez sur l'image pour l'agrandir.
Je redémarre splunk
systemctl restart Splunkd
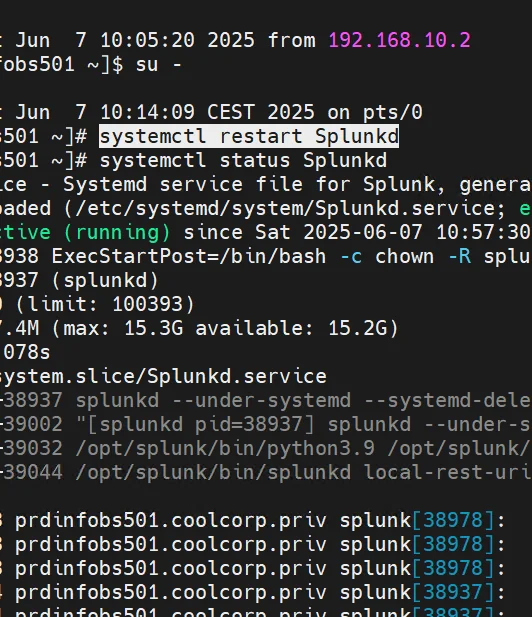
Cliquez sur l'image pour l'agrandir.
Le serveur web de Splunk écoute par défaut sur le port 8000. Pour l’autoriser, j’exécute la commande suivante dans firewalld:
firewall-cmd—add-port=8000/tcp—permanent
firewall-cmd—reload

Cliquez sur l'image pour l'agrandir.
On peut enfin se connecter en admin à l’URL HTTPS:\\log.coolcorp.priv pour commencer à manipuler l’outil.
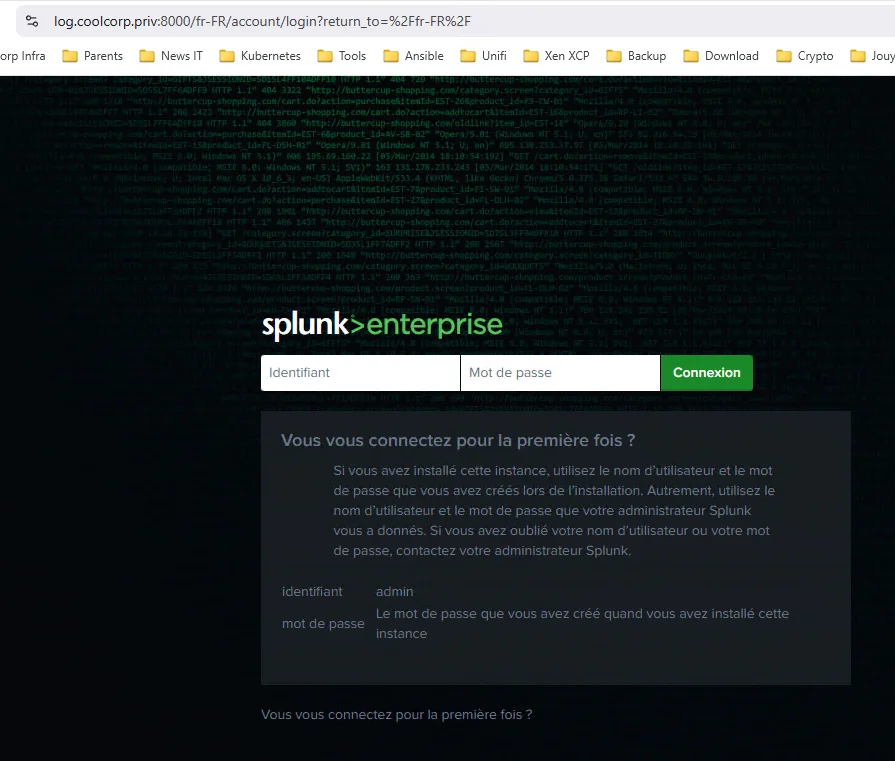
Cliquez sur l'image pour l'agrandir.
Configuration de Splunk Enterprise
À l’arrivée sur l’interface, vous disposez de peu d’apps. La plus importante se nomme Search & Reporting C’est à partir de cette dernière que vous pouvez réaliser vos recherches.
Création de l'app
Il n’est pas conseillé de rester dans le contexte de cette app, mais plutôt de créer une app dédiée à votre besoin. Dans notre exemple, je veux pouvoir explorer les logs des conteneurs exécutés sur mon cluster Kubernetes.
Je me rends donc dans le menu de gestion des applications, pour en créer une nouvelle.
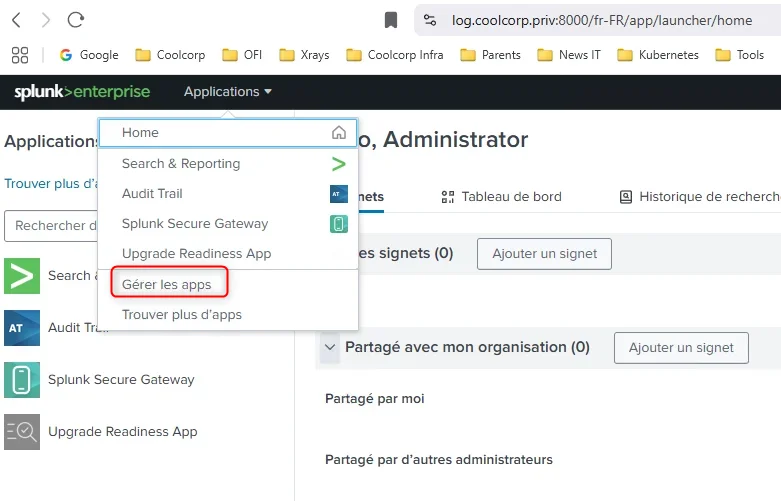
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
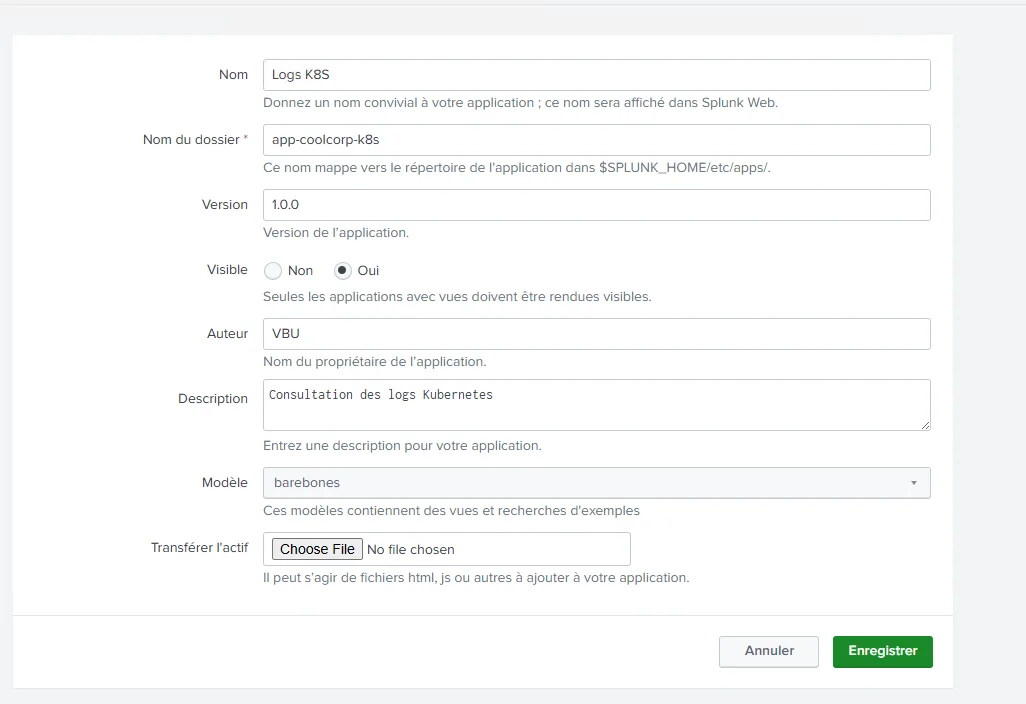
Je lui donne un nom, app-coolcorp-k8s, indique à Splunk où stocker les éléments que je pourrais être amené à créer pour mon app.
Cliquez sur l'image pour l'agrandir.
En faite, sous Splunk, une app est représentée par un dossier qui contiendra tous les éléments qui pourraient s’y rattacher, comme les tableaux de bord ou la définition des extractions de champs. Au sein de ce dossier, tout est fichiers et il devient ainsi possible de packager son app pour la diffuser et la déployer sur d’autres instances Splunk. Je n’irais pas dans ce niveau de détails aujourd’hui, retenez juste que, sous Splunk, exploiter une logique de découpage par « app » au sein de son instance est une bonne pratique.
Une fois mon app créée, je peux me rendre dans son contexte. Par défaut mon app reprend la configuration de l’app Search & Reporting. Je suis néanmoins dans mon app, et tout ce que je vais maintenant faire va y être sauvegardé et associé.
Je sais que je suis dans le contexte de mon app, via l’observation de l’URL qui fait référence à cette dernière.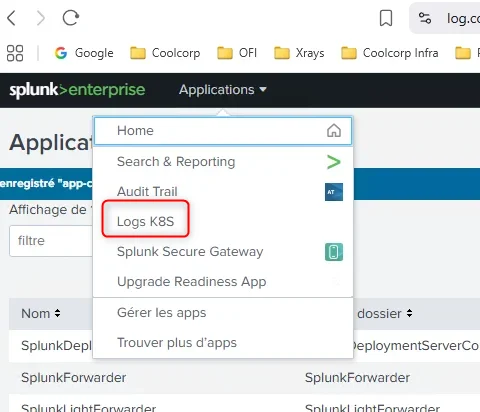
Cliquez sur l'image pour l'agrandir.
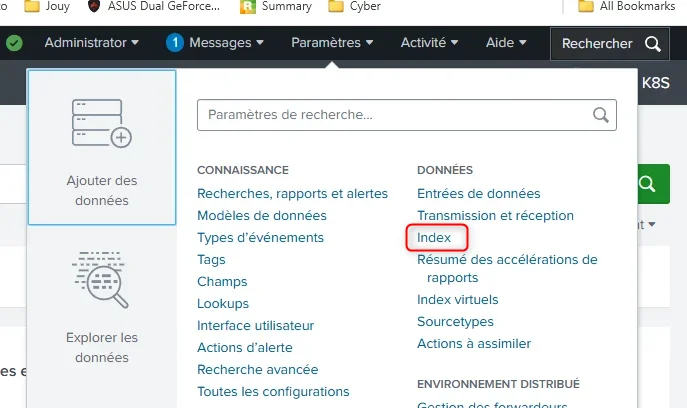
Création de l'index
Je peux maintenant créer un index. Un index est comme une base de données dédiée à l’hébergement des logs collectés. Par défaut, il existe un index main, qui, sans paramétrage explicite, est utilisé par défaut.
Cliquez sur l'image pour l'agrandir.
Là aussi, la bonne pratique veut qu’il faille éviter d’utiliser cet index. En effet, le cycle de vie de votre donnée récoltée est associé à un index. Je ne vais pas entrer dans les détails, mais il est possible de définir par index la quantité et/ou l’historique de données que vous souhaitez conserver avant que Splunk ne fasse le ménage ou déplace les données sur un support différent (archivage).

Cliquez sur l'image pour l'agrandir.
À noter aussi que, comme pour les apps, il est possible d’associer des droits spécifiques pour la consultation d’un index. Ça devient alors très intéressant de segmenter sa donnée dans plusieurs index en fonction du caractère confidentiel de cette dernière.
Pour l’exemple, je crée un index nommé idx-coolcorp-k8s dédié au stockage de mes logs K8S.
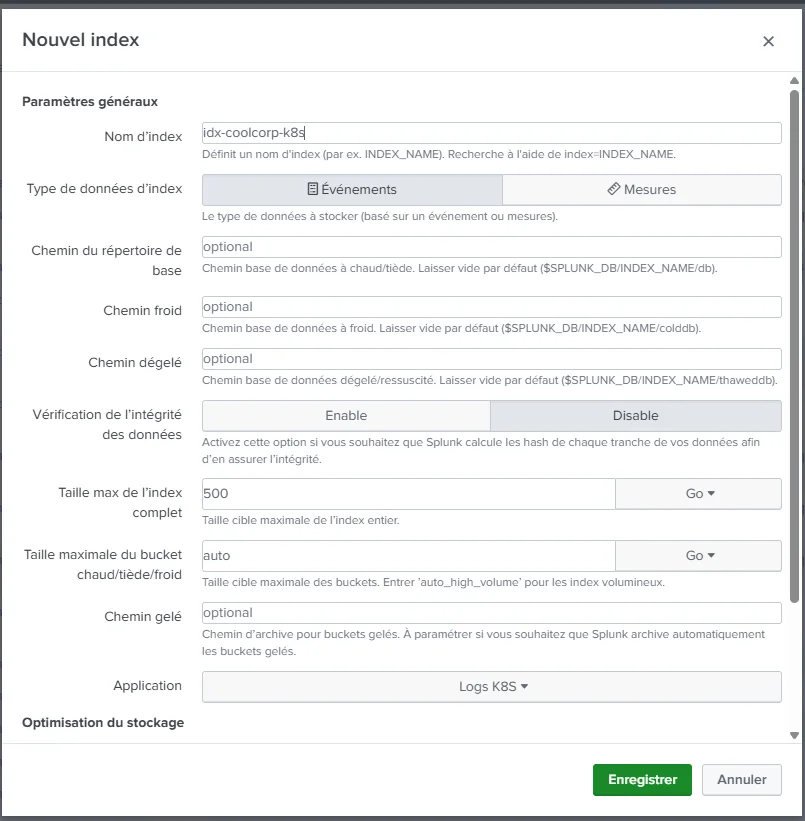
Cliquez sur l'image pour l'agrandir.
La définition de mon index est enregistrée dans le contexte de mon app.
Toujours en prenant soin de rester justement dans ce contexte, je vais définir le point d’entrée de la donnée à collecter.
Création du collector http
Splunk peut ingérer de la donnée de différentes manières. Pour Kubernetes, on va retenir l’envoi via un http collector. C’est une manière pour Splunk d’écouter sur un port dédié à cet usage et de pouvoir recevoir le flux de logs par ce biais.
On se place donc dans le menu Entrée données, puis on sélectionne collecteur d’événement http.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
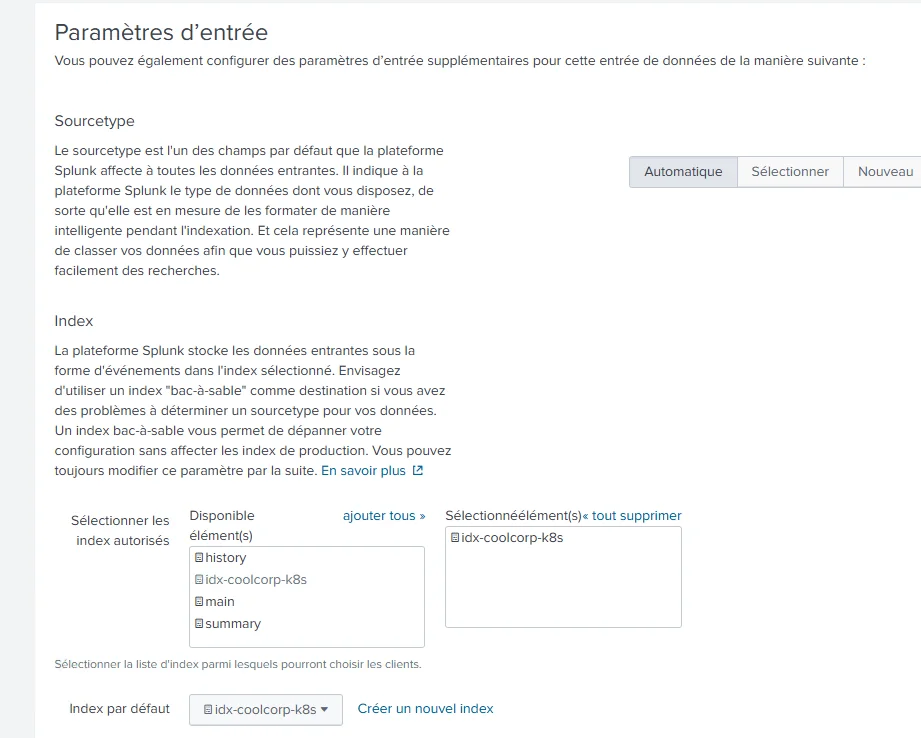
On va laisser la majorité des options par défaut, notamment le choix du sourcetype. Le sourcetype, pour Splunk, est associée à la nature de la donnée. Fonction du sourcetype, Splunk saura comment extraire et manipuler les champs qu’il reçoit. Des sourcetypes sont connus par défaut dans Splunk, mais il est possible d’étendre ces derniers et de les compléter par vos propres règles d’extraction de champs.
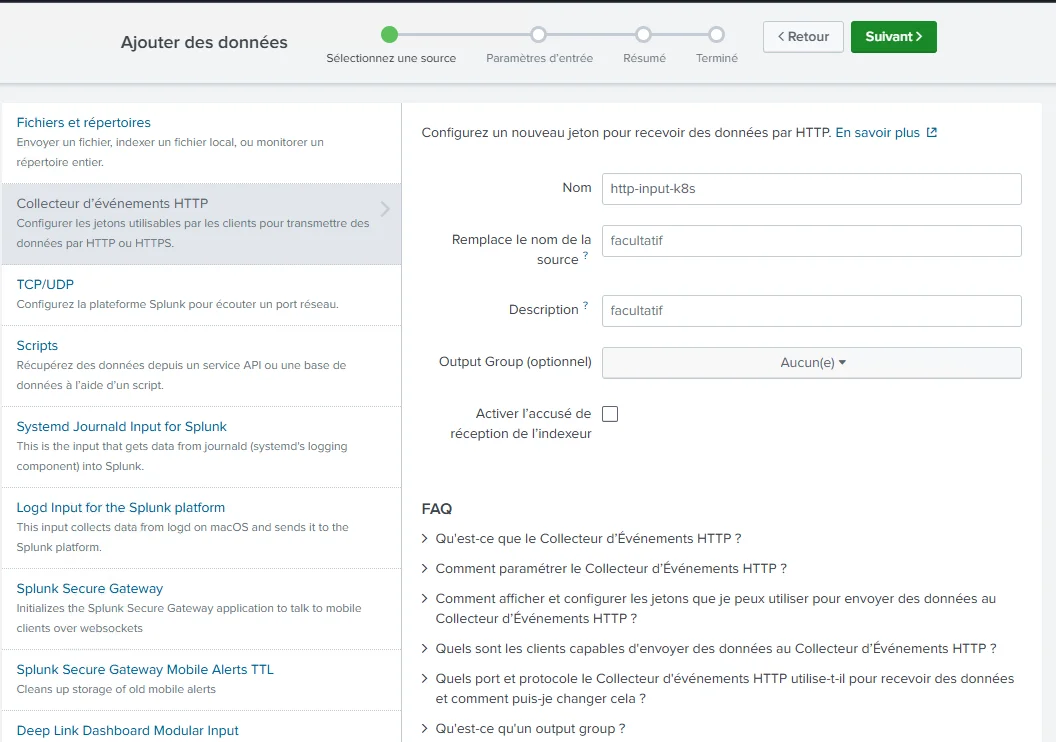
Cliquez sur l'image pour l'agrandir.
C’est d’ailleurs souvent ce qu’on va retrouver quand on déploie un technical add-on.
Dans notre exemple, on va laisser le sourcetype être détecté automatiquement.
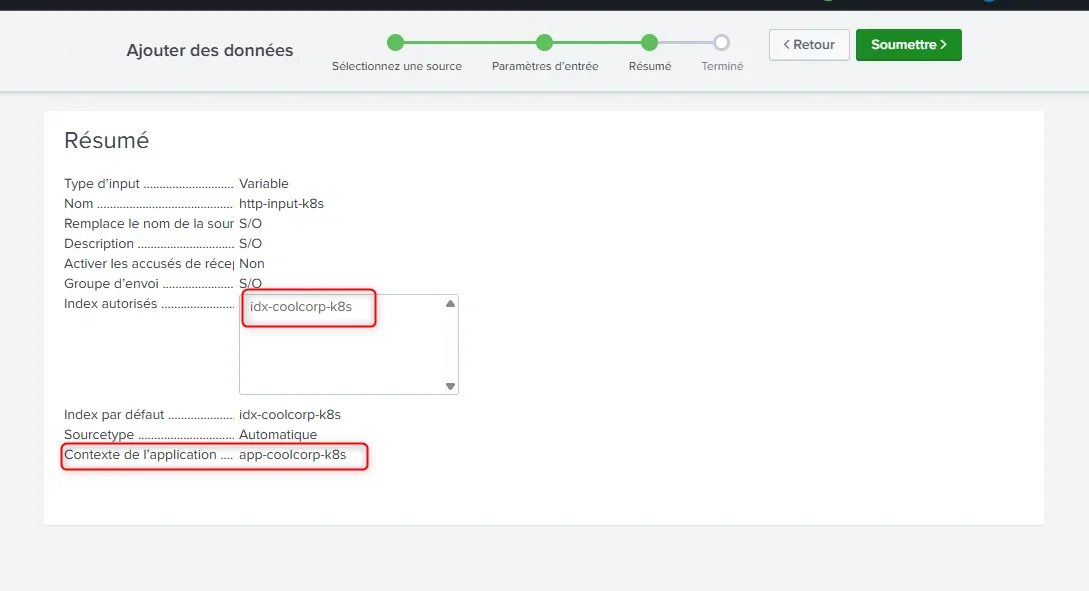
Par contre, on va forcer la donnée collectée par ce biais à être stockée dans l’index créé juste avant.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
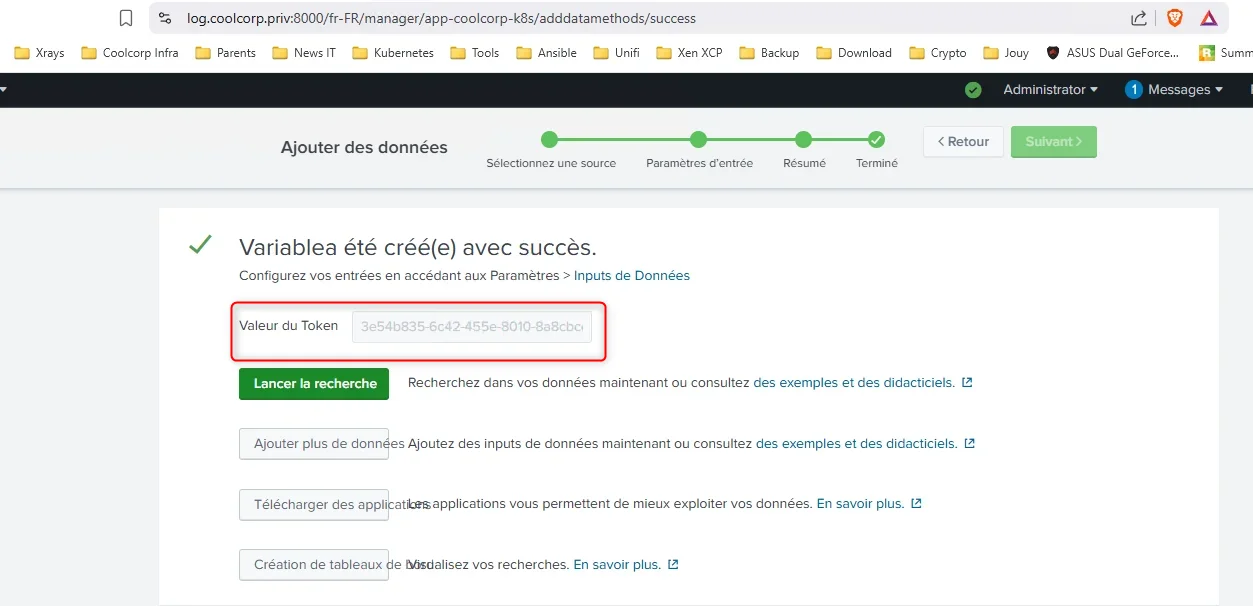
En fin de configuration, Splunk nous retourne un token. C’est ce token qu’il faudra que l’agent OpenTelemetry présente pour pouvoir être autorisé à « pousser » les logs collectés. C’est de cette manière également que la donnée pourra être identifiée et associée à l’index dédié.
Cliquez sur l'image pour l'agrandir.
Dernière chose à faire, ouvrir le port d’écoute utilisé par le collector http c’est-à-dire le 8088. Notez que le certificat créé antérieurement pour le site Web sera également utilisé pour protéger l'envoi des journaux. Il sera automatiquement réutilisé par le collecteur HTTPS.
firewall-cmd --add-port=8088/tcp --permanent
firewall-cmd --reload

Cliquez sur l'image pour l'agrandir.
Installation de l'agent OpenTelemetry
On va donc maintenant passer à l’installation de l’agent OpenTelemetry sur le cluster.
On va s’appuyer sur l’agent préparamétré et déployable via l’usage d’un chart Helm fourni par Splunk.
Tout le détail est présent sur le repo github dédié.
Cliquez sur l'image pour l'agrandir.
Pour respecter ma nomenclature et la logique retenues au sein de mon cluster, je souhaite dédier un namespace à l’agent.
N’hésitez pas à parcourir mon cookbook sur le déploiement de mon cluster principal Kubernetes pour en apprendre davantage sur mon usage des namespace.
Je commence donc par créer sur mon cluster K8S le namespace inf-sup-lan avec la commande:
kubectl create ns inf-sup-lan

Cliquez sur l'image pour l'agrandir.
Ensuite, je lance une commande à partir de l’outil Helm qui a été préalablement configuré pendant la phase de déploiement de mon cluster.
Il faut d'abord déclarer le repo du chart:
helm repo add splunk-otel-collector-chart https://signalfx.github.io/splunk-otel-collector-chart
Puis on initie le processus d’installation de l’agent OpenTelemetry préconfiguré par Splunk, en utilisant les paramètres suivants:
helm install my-splunk-otel-collector --set="splunkPlatform.endpoint=https://log.coolcorp.priv:8088/services/collector,splunkPlatform.token=le_token_du_collector,splunkPlatform.metricsIndex=k8s-metrics,splunkPlatform.index=idx-coolcorp-k8s,clusterName=kub.coolcorp.priv,splunkPlatform.insecureSkipVerify=true,logsEngine=otel" splunk-otel-collector-chart/splunk-otel-collector -n inf-sup-lan
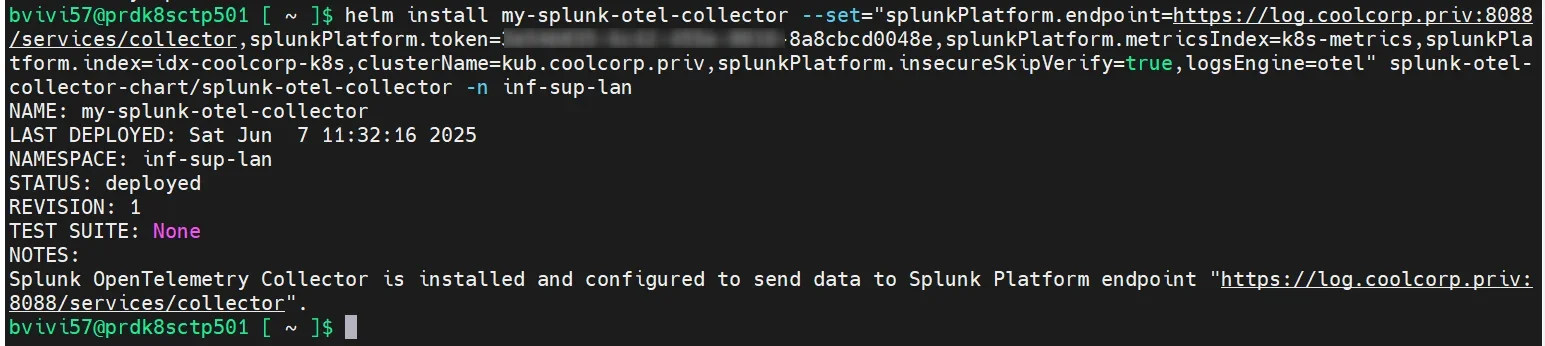
Cliquez sur l'image pour l'agrandir.
Comme vous pouvez l’observer dans la commande, j’en profite pour passer un certain nombre d’arguments. Notamment vers quels serveurs envoyer la donnée, quel index utiliser (même si celui-ci est déjà forcé côté splunk) ainsi que le token associé à mon collector http.
Rapidement on peut observer qu’un agent opentelemetry est déployé sur chaque node de mon cluster.
kubectl get pod -n inf-sup-lan -o wide
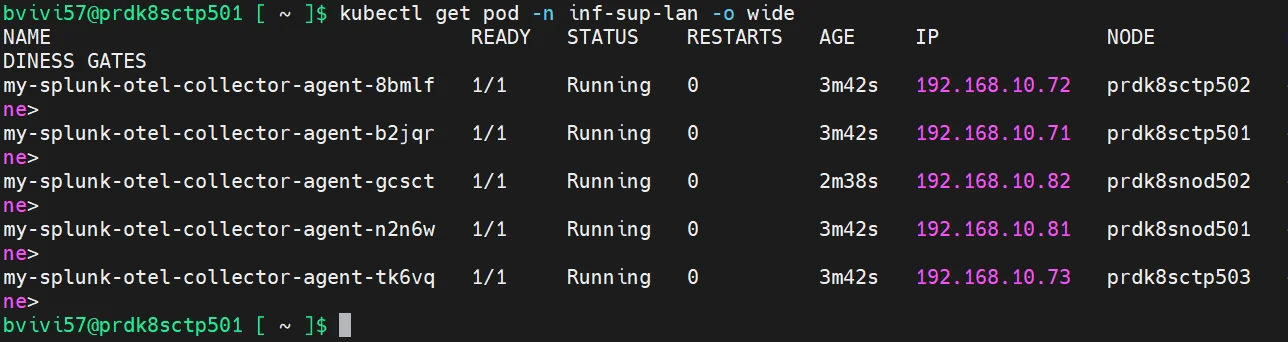
Cliquez sur l'image pour l'agrandir.
Enfin, presque…en effet, je ne vois pas d’agent sur mes nodes en DMZ. Comme cela est défini dans la présentation de mon cluster issue de mon cookbook k8S, mon cluster dispose de deux nœuds worker en DMZ. Je les ai tagués et j’y applique un « taint » via l’attribut node-role.kubernetes.io/worker-dmz.
Pour y déployer des pods, il faut que ces derniers soient « tolérant » à ces « taint » comme je l’explique ici.
Or, par défaut, les pods déployés par Helm n’ont pas ces « tolérances » activées. Je dois donc mettre à jour le déploiement des agents en incluant des tolérances pour les control plane, pour être certain d’avoir un agent par nœud du cluster.
Cela peut se faire via la commande suivante pour mettre à jour le déploiement:
helm upgrade my-splunk-otel-collector splunk-otel-collector-chart/splunk-otel-collector --reuse-values --set "tolerations[0].key=node-role.kubernetes.io/worker-dmz" --set "tolerations[0].operator=Exists" --set "tolerations[0].effect=NoSchedule" -n inf-sup-lan
helm upgrade my-splunk-otel-collector splunk-otel-collector-chart/splunk-otel-collector \
--reuse-values \
--set "tolerations[0].key=node-role.kubernetes.io/worker-dmz" \
--set "tolerations[0].operator=Exists" \
--set "tolerations[0].effect=NoSchedule" \
--set "tolerations[1].key=node-role.kubernetes.io/control-plane" \
--set "tolerations[1].operator=Exists" \
--set "tolerations[1].effect=NoSchedule" \
-n inf-sup-lan
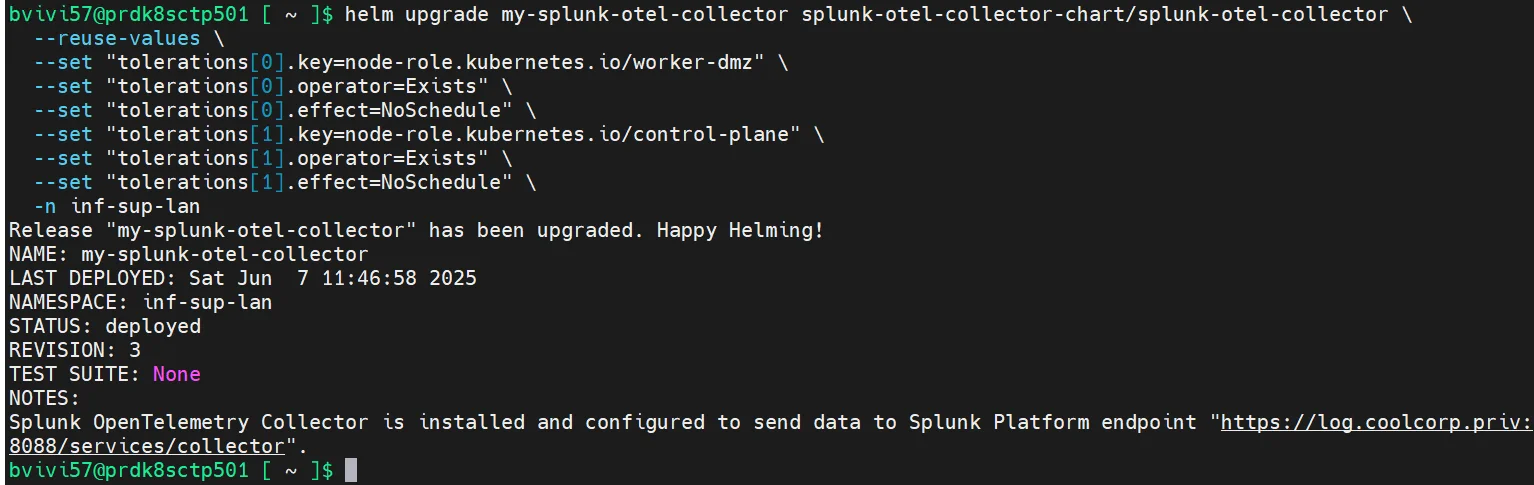
Cliquez sur l'image pour l'agrandir.
Pour ceux qui ne seraient pas à l’aise avec Helm n’hésitez pas à parcourir mon article sur le déploiement de Jenkins sous K8S dans lequel je reviens sur le fonctionnement de helm.
Après avoir mis à jour le déploiement via cette nouvelle commande helm, on peut contrôler à nouveau le statut des agents.
kubectl get pod -n inf-sup-lan -o wide
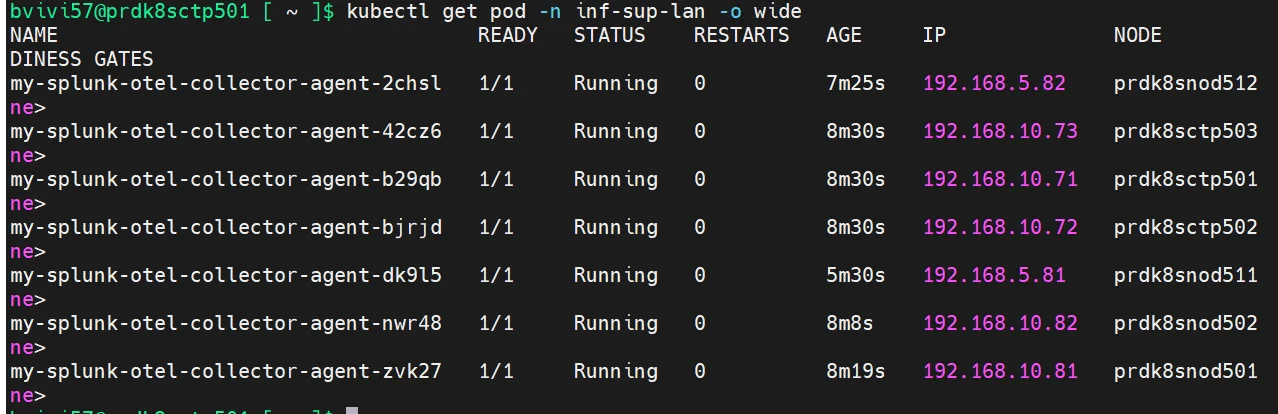
Cliquez sur l'image pour l'agrandir.
Cette fois-ci j’ai bien un agent par node. Cela va permettre à opentelemetry de relevé les logs de tous les conteneurs qui s’exécutent sur chaque serveur.
Ces logs seront ensuite redirigés vers mon instance splunk en présentant le token configuré lors de l’installation de l’agent et issu du collector http.
De cette façon le serveur Splunk va autoriser le flux et indexer son contenu dans l’index idx-coolcorp-k8s.
Manipulation des logs
On peut le vérifier en revenant dans l’interface de Splunk et en se positionnant dans le contexte de l’app app-coolcorp-k8s.
Le langage SPL s’apprend relativement rapidement, du moins ses bases. Par exemple, lire le contenu de l’index revient à simplement à taper:
index="idx-coolcorp-k8s"
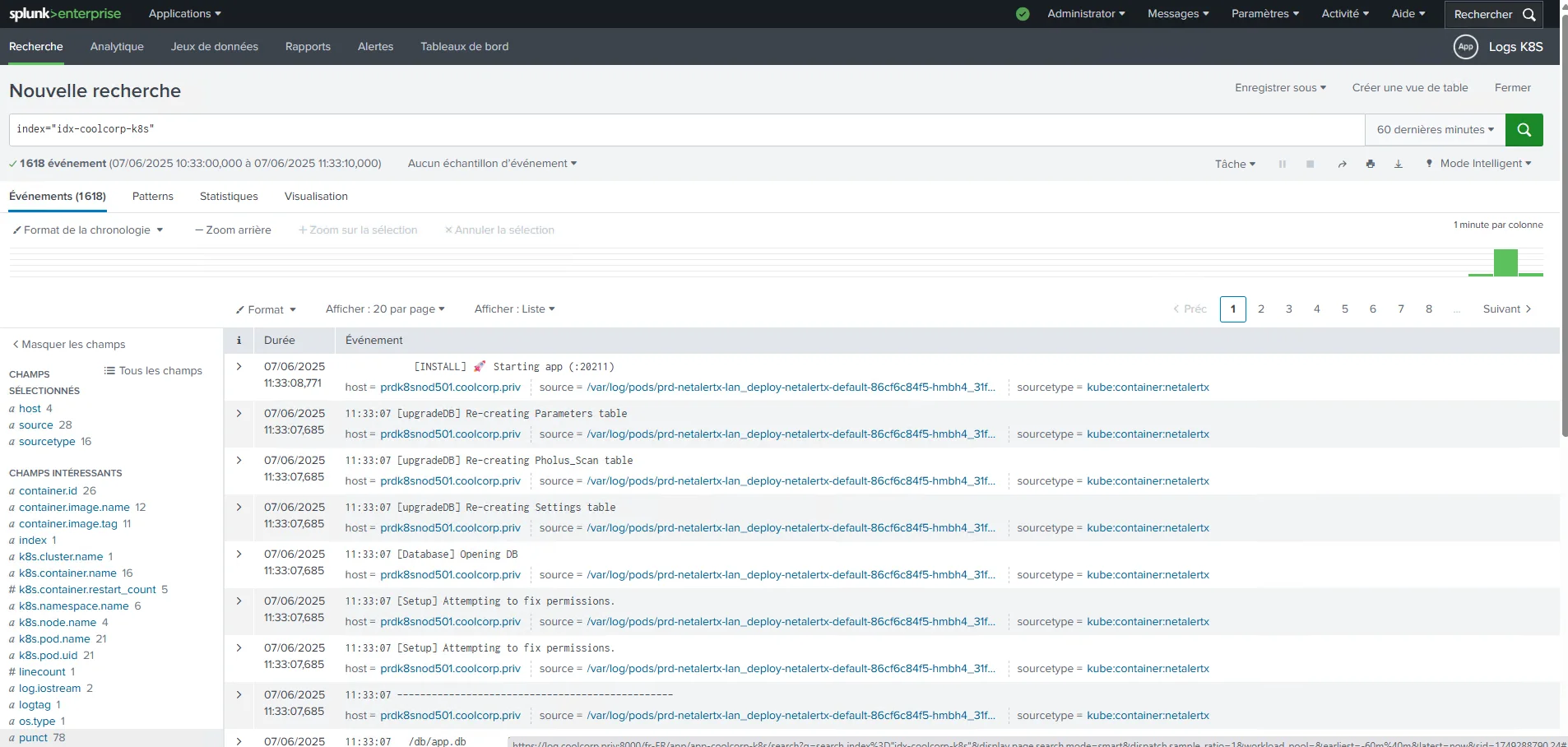
Cliquez sur l'image pour l'agrandir.
Pour être certains de voir tous les champs, on se positionne en mode verbeux. C’est le mode le plus consommateur, mais qui permet à Splunk d’extraire le maximum de champs. En situation de run classique, vous aurez tendance à utiliser le mode intelligent, qui permettra à Splunk d’extraire uniquement les champs pertinents par rapport à votre requête.
Cliquez sur l'image pour l'agrandir.
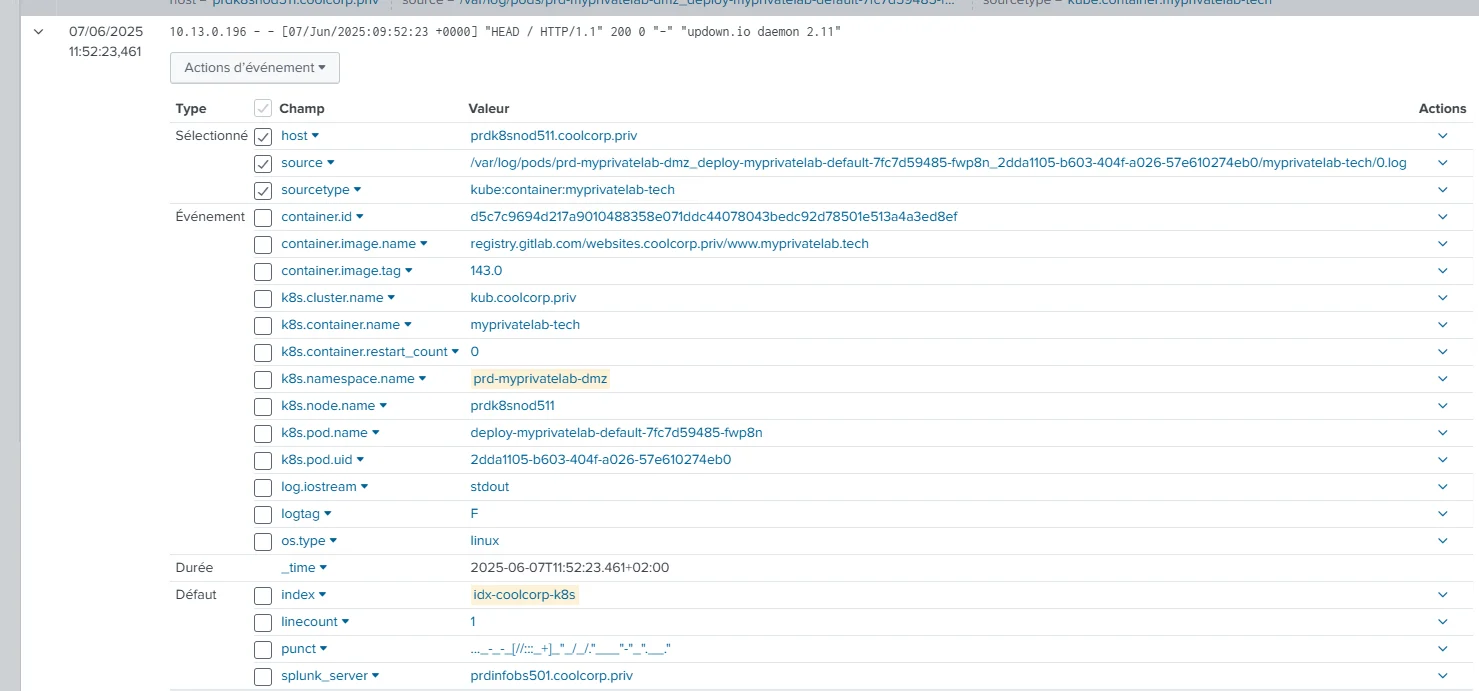
Ici, avec ce mode par défaut, on a une vue complète de tous les champs automatiquement extraits depuis les logs des conteneurs tourant sur le cluster Kubernetes.
Comme nous n’avons pas spécifié des sourcetype lors du chargement, Splunk en crée un automatiquement par conteneur, sous la forme kube:container:nom_conteneur.
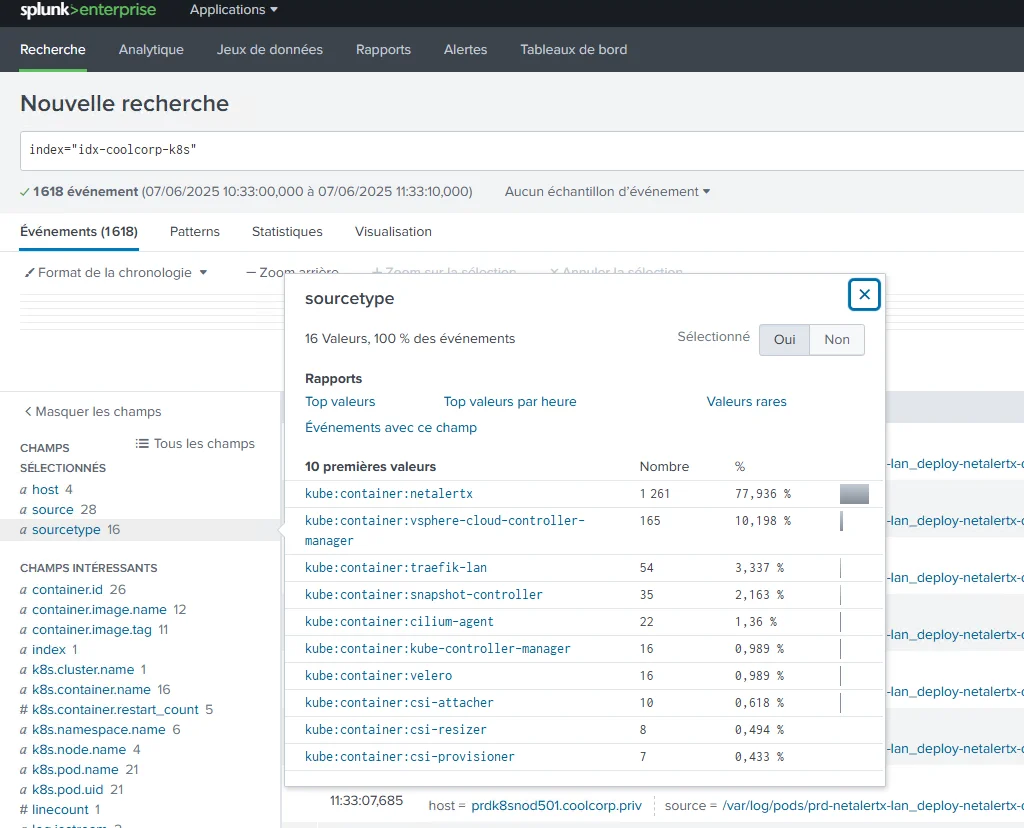
Cliquez sur l'image pour l'agrandir.
Si cette manière de faire ne vous convient pas, l’agent Splunk étant basé sur OpenTelemetry, vous pouvez jouer sur les annotations présent au sein des objets deployment Kubernetes pour surcharger ce type d’information.
Par exemple, si, pour mon site web, je modifie le fichier yaml associé de cette manière.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-myprivatelab-default
namespace: prd-myprivatelab-dmz
labels:
environment: prd
network: dmz
application: myprivatelab
tier: default
spec:
selector:
matchLabels:
environment: prd
network: dmz
application: myprivatelab
tier: default
replicas: 1
template:
metadata:
namespace: prd-myprivatelab-dmz
labels:
environment: prd
network: dmz
application: myprivatelab
tier: default
annotations:
splunk.com/sourcetype: privatelab:website
Je serais en mesure de rechercher des enregistrements associés en filtrant sur ce nouveau sourcetype que j’ai forcé en annotant l’objet K8S.
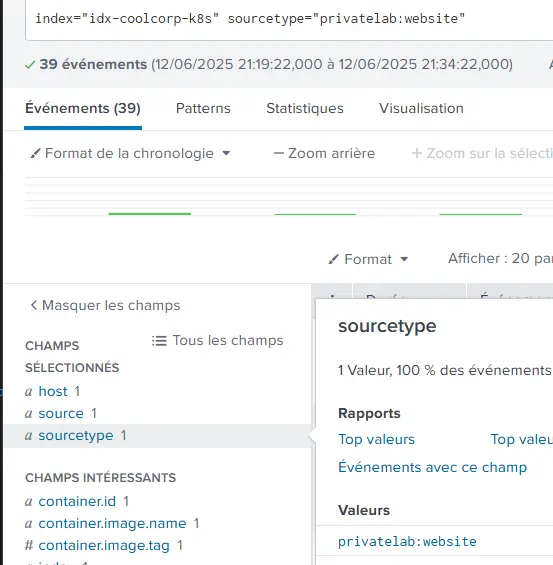
Cliquez sur l'image pour l'agrandir.
On peut d’ailleurs étendre ce principe via d’autres annotations:
template:
metadata:
annotations:
splunk.com/sourcetype: "my_custom_sourcetype"
splunk.com/index: "my_index"
splunk.com/source: "my_app"
splunk.com/ignore: "false"
Sachant qu’on peut aussi faire ces propres annotations, pour, par exemple, ajouter des champs complémentaires. L'avantage est que le découpage de champs se fait automatiquement en raison de l'usage de l'agent opentelemetry préparamétré pour émettre le flux de logs de manière à ce que Splunk puisse directement y interpréter les champs selon une configuration par défaut.
Il est important aussi de noter que la recherche et l’extraction se font sur une plage horaire donnée. Par défaut ici 24H. Mais il est possible de préciser la période de manière extrêmement précise. Plus la plage va être large, plus la quantité de données à traiter et à afficher va être importante : la requête va consommer de la ressource.
C’est pourquoi, quand on prend l’habitude de travailler avec Splunk, il faut rapidement apprendre à optimiser ses recherches pour filtrer au mieux ce qu’on veut afficher.
La date utilisée pour associer un événement ne correspond pas forcément à la date d’entrée dans le système. Si votre log contient un champ date, celui-ci peut très bien être considéré comme le champ à laquelle la donnée doit être affiché. Comprenez par là que, par exemple, si votre source provient d’un asset dont la date est erronée ou que le champ date de la log ne soit pas juste, c’est pourtant cet indicateur horaire qui pourrait être considéré par Splunk comme la date à utiliser...ce qui pourrait fausser votre sélection de plages horaires.
Mais encore une fois, le but n’est pas de faire un tutoriel avancé sous Splunk.
Dans notre cas, tous semblent correspondre. En fait, on affiche dans Splunk ce qu’on pourrait voir avec la commande kubectl log. La seule différence, c’est qu’on indexe tous les sorties de tous les conteneurs du cluster.
On peut commencer à filtrer sur des logs issus d’images particulières, de namespace spécifique ou de tous autres champs utilisable et directement détecté par Splunk.
Par exemple, si je souhaite voir les logs de mon site web, sachant que celui-ci se trouve dans un pod du namespace prd-myprivatelab-dmz, il me suffit de filtrer sur index="idx-coolcorp-k8s" "k8s.namespace.name"="prd-myprivatelab-dmz".
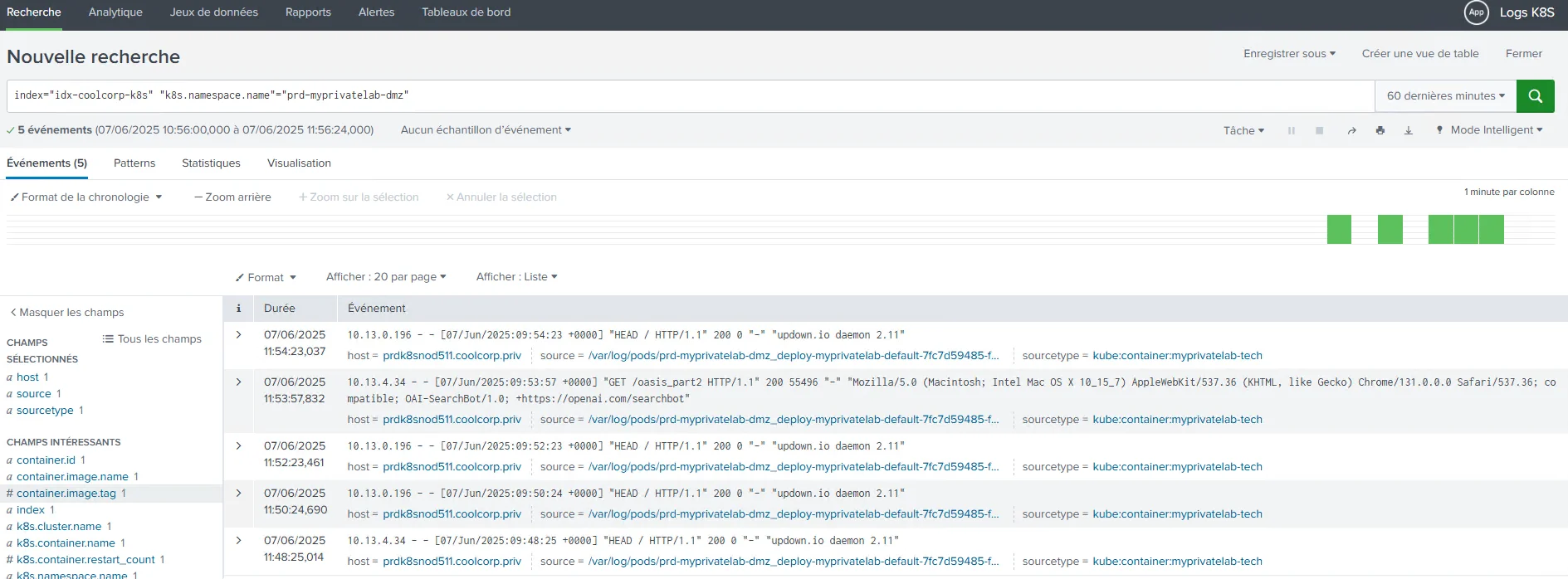
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
bien entendu on peut utiliser des regex et des filtres sur des caractères ainsi que des instructions splunk spécifiques pour obtenir un affichage plus adapté.
Par exemple, en renommant des champs et ne les présentant dans un tableau:
index="idx-coolcorp-k8s"
| sort _time | eval date=strftime(_time, "%Y-%m-%d %H:%M:%S")
| rename k8s.cluster.name as cluster k8s.node.name as node k8s.pod.name as pod k8s.container.name as container _raw as log k8s.namespace.name as namespace
| table date, cluster, node, namespace, pod, container, log
Bien que longue, la commande est relativement simple à comprendre:
- On trie les données par date
- On travaille le format de la date pour l’affichage
- On renomme les champs par défaut par des noms plus explicites
- On affiche le tout dans un tableau
Le caractère | est utilisé pour passer les résultats d’une instruction à une autre.
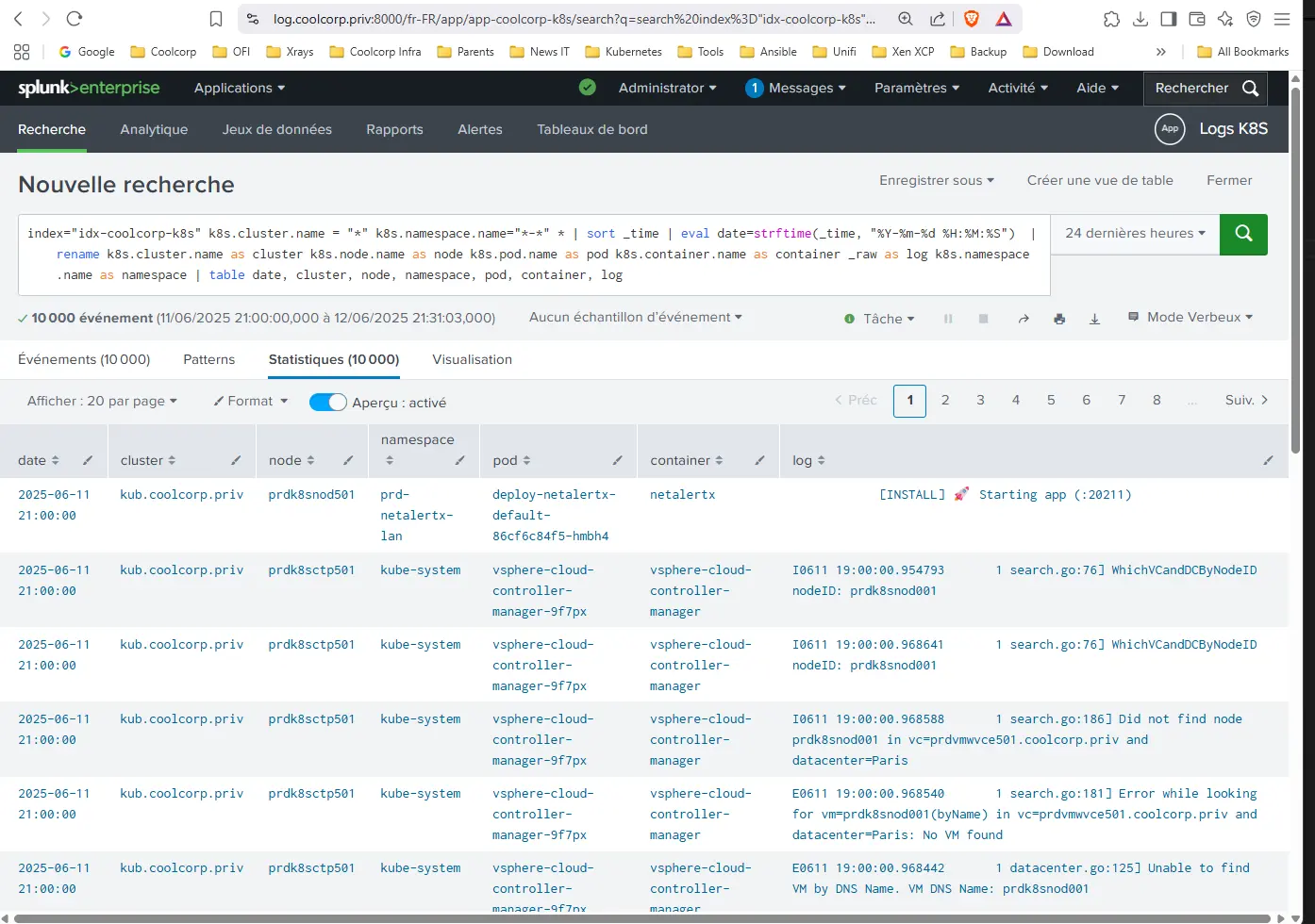
Cliquez sur l'image pour l'agrandir.
Tout cela n’est que la partie émergée de l’iceberg, le SPL permet d’aller très loin dans la manipulation des données en y intégrant la notion de suivi dans le temps, pour par exemple, obtenir l’évolution d’un évènement spécifique identifiable via la valeur d’un ou plusieurs champs (nombre d'erreurs au cours de la journée, par exemple).
Je vous laisse prendre connaissance de tout ce qu’il est possible de faire en parcourant la documentation de Splunk qui s’avère très bien faite…sans compter que maintenant les IA savent très bien vous épauler dans la construction de vos requêtes SPL.
L’objectif final est d’exploiter le résultat de ces recherches dans des dashboard, qu’on va pouvoir rendre dynamique via l’intégration de menu facilement manipulable par un utilisateur.
Par exemple il m’est possible d’enregistrer ma requête précédente pour la renvoyer vers un dashboard.
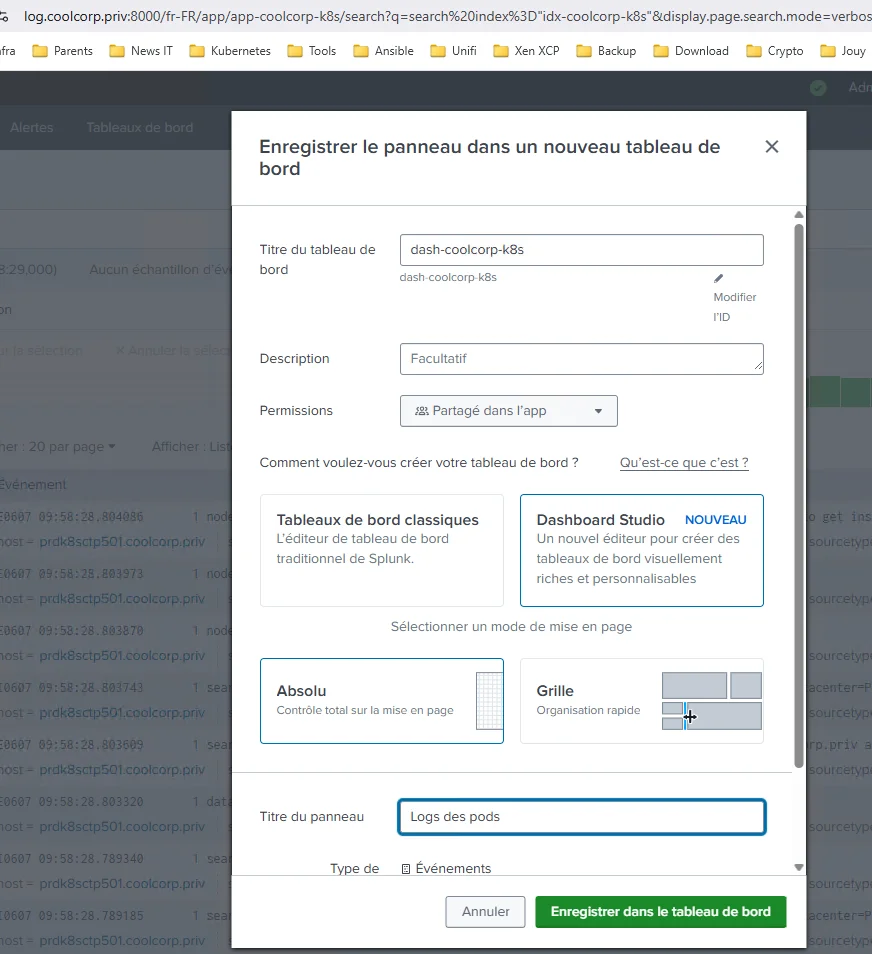
Cliquez sur l'image pour l'agrandir.
Après quelques manipulation et usage du Dashboard Studio intégré à Splunk on peut arriver à ce type de résultat.
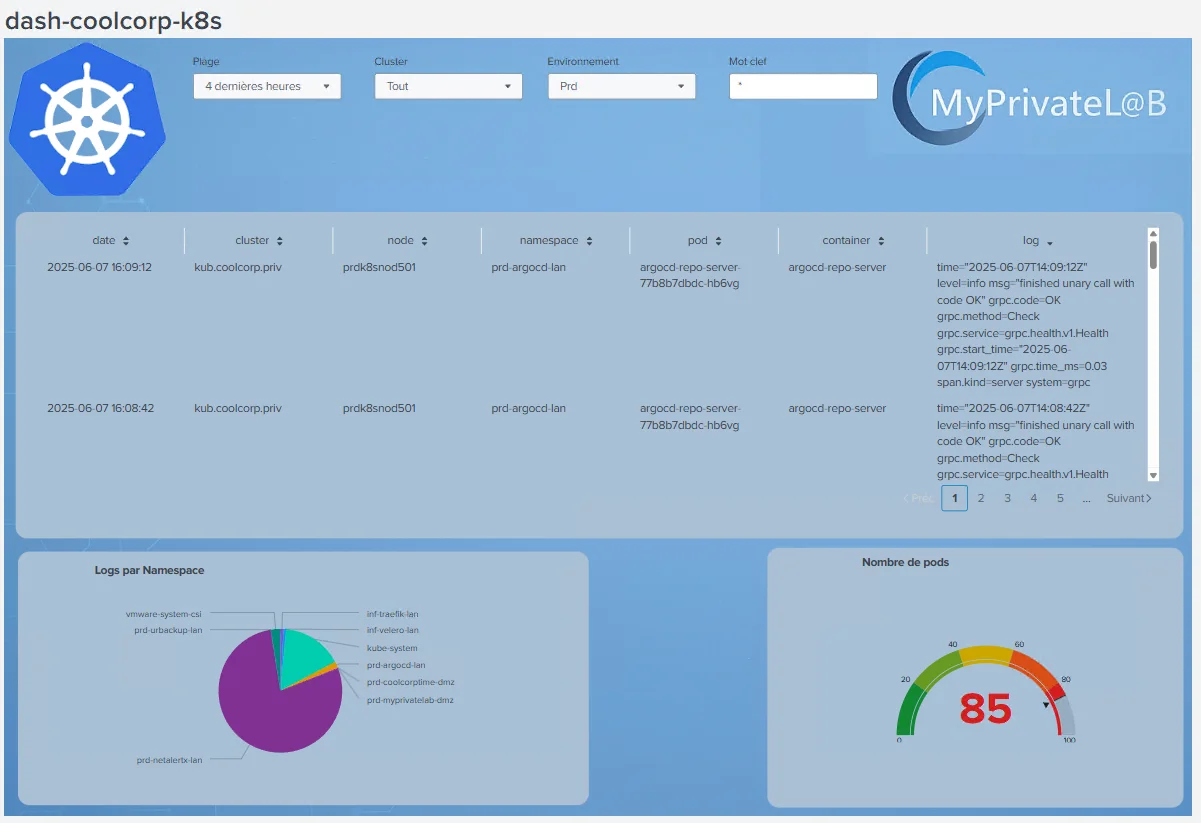
Cliquez sur l'image pour l'agrandir.
J’ai inclus dans cet exemple différents types de graphiques et quelques entrées d’input, comme le choix de l’environnement en me basant sur le trigramme qui débute chacun de mes namespaces (d’où l’importance d’avoir une nomenclature fonctionnelle).
Conclusion
J’espère que cet article et les explications associées vous ont convaincu d’investir, à minima votre temps, dans des solutions de type Splunk pour apporter une meilleure visibilité au sein de vos clusters Kubernetes.
Il ne s’agit pas seulement d’une collecte de log, mais bien de pouvoir se donner la capacité à suivre une plateforme en combinant des événements issue de différentes sources.
Dans l’article je n’ai traité que les logs de mon cluster, mais je pourrais également ajouter les logs de mes firewalls, les logs de mes proxys, de mes OS…Et travailler à tracer toute la vie d’une requête, depuis son arrivée sur mon premier firewall jusqu’à son traitement sur mon serveur web.
Splunk n’est pas le seul outil capable de vous aider dans ce type de démarches, d’autres applicatifs, dont certains gratuits, peuvent vous fournir ce type de services, comme ELK. On peut même déployer dans le cluster Kubernetes d’autres composants spécialisés, comme ceux rattachés à CNI cillium, afin d’obtenir des informations sur les échanges entre les différents pods.
À chacun de choisir ses armes, dans mon cas, mon travail m’a fait me tourner vers Splunk, que je trouve particulièrement efficaces et qui bénéficie de nombreuses addons proposant une comptabilité accrue avec les standards du marché.
Dans tous les cas, je vous invite à privilégier des solutions basées sur OpenTelemetry. Ce standard ne cesse d’être adopté et il sera vite devenu un indispensable dans les années à venir. Je n’ai pas spécifiquement détaillé son utilisation dans cet article. Je me suis contenté de déployer l’agent Splunk basé sur OpenTelemetry au sein du cluster K8S, mais cela m’a déjà permis d’évoquer le sujet. Il est fort probable que je m’investisse davantage dans OpenTelemetry par la suite.