Upgrade d'une plateforme K8S: Etape 02 - commandes et actions
Introduction
Après avoir parlé de la théorie, il est temps de passer à la pratique. Si vous n’avez pas pris connaissance de l’article précédent décrivant la logique de mise à jour d’une plateforme Kubernetes Vanilla, je vous invite à le faire avant de démarrer la lecture de celui-ci.
En effet, il est très important de préparer son opération d’upgrade et d’avoir identifié en avance l’ordre et la logique des taches à réaliser. Il faut avoir retenu toutes les versions cibles vers lesquelles aller et s’être assuré des matrices de compatibilité, avant, pendant et après la mise à jour.
Assurez-vous d’avoir toutes les sauvegardes nécessaires, à commencer par la base etcd ainsi que les données de vos applications hébergées sur le cluster. Sachez surtout les restaurer !
Avant de démarrer, je tiens à préciser que les commandes et méthodes décrites ici sont propres à la mise à jour de mon cluster Kubernetes personnel, dont j’explique toute la mise en œuvre à travers un cookbook dédié.
Il est fort possible que la manière de procéder change d’un cluster à un autre, tout dépend des composants additionnels retenus et de la configuration avancée de chacun. Néanmoins, je vous propose une approche modulaire, directement issue de mon article précédent. Vous devriez normalement pouvoir vous en inspirer pour traiter vos propres architectures.
Si vous êtes utilisateurs d’une distribution Kubernetes, comme OpenShift, je vous invite plutôt à vous rapprocher de l’éditeur de votre solution. L’avantage des distributions K8S c’est qu’elles simplifient les opérations de mise à jour et intègrent la plupart du temps une automatisation des tâches d’upgrade.
Il en va de même pour les solutions managées du cloud. Vous pouvez cependant retrouver dans cet article la description de certains composants que vous auriez pu ajouter à votre configuration de base (traefik, cert-manager....).
Dans mon exemple, je vais partir d’une version 1.29.4 de K8S à la version 1.xx.x en y intégrant toutes les briques additionnelles que j’ai pu ajouter. Il est possible qu’au fur à mesure des évolutions de Kubernetes, la procédure d’upgrade puisse changer. Dans ce cas, j’essayerais de mettre à niveau l’article.
En l’état je vais utiliser principalement kubeadm, puisque que c’est avec lui que j’ai déployé mon cluster. Si vous avez mis en place un cluster K8S vanilla sans kubeadm (déjà bravo) alors vous devez suivre une autre procédure.
Je ne reviendrais pas sur le détail des matrices de compatibilité. Tous ces éléments vous sont expliqués dans l’article dédié.
Controle du cluster
La première chose à faire est de s’assurer que le cluster à mettre à jour est pleinement fonctionnel. Vérifiez la statue des nodes avec la commande kubectl get node et faite une liste du maximum de vos objets K8S, à commencer par les pods dans chaque namespace.
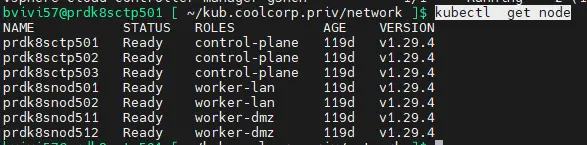
Cliquez sur l'image pour l'agrandir.
Par exemple si vous disposez des droits suffisants, vous pouvez utiliser la command kubectl get all -A
Faites un focus sur le namespace kube-system avec la commande kubectl get pod -n kube-system
Il est nécessaire d’avoir un cluster de départ sain et sans erreur avant de démarrer les opérations de mise à jour.
Mise à jour des CSI (CPI inclus)
Traitement du CPI/CSI vSphere
Le premier composant à mettre à niveau est le driver CSI (Container Storage Interface) vSphere. Comme celui-ci s’appuie sur le driver CPI(Cloud Provider Interface) du même éditeur, il faut également appliquer son update. Pour ceux qui ne seraient pas familiers avec le CPI/CSI, vous trouverez plus d’explication à ce niveau.
Il faut récupérer la dernière version du fichier vsphere-cloud-controller-manager.yaml associé au déploiement du driver CPI dans le repos du projet.
Ce dernier, comme lors de son installation sur le cluster, doit être customisé pour y intégrer les éléments de connexion au vCenter.
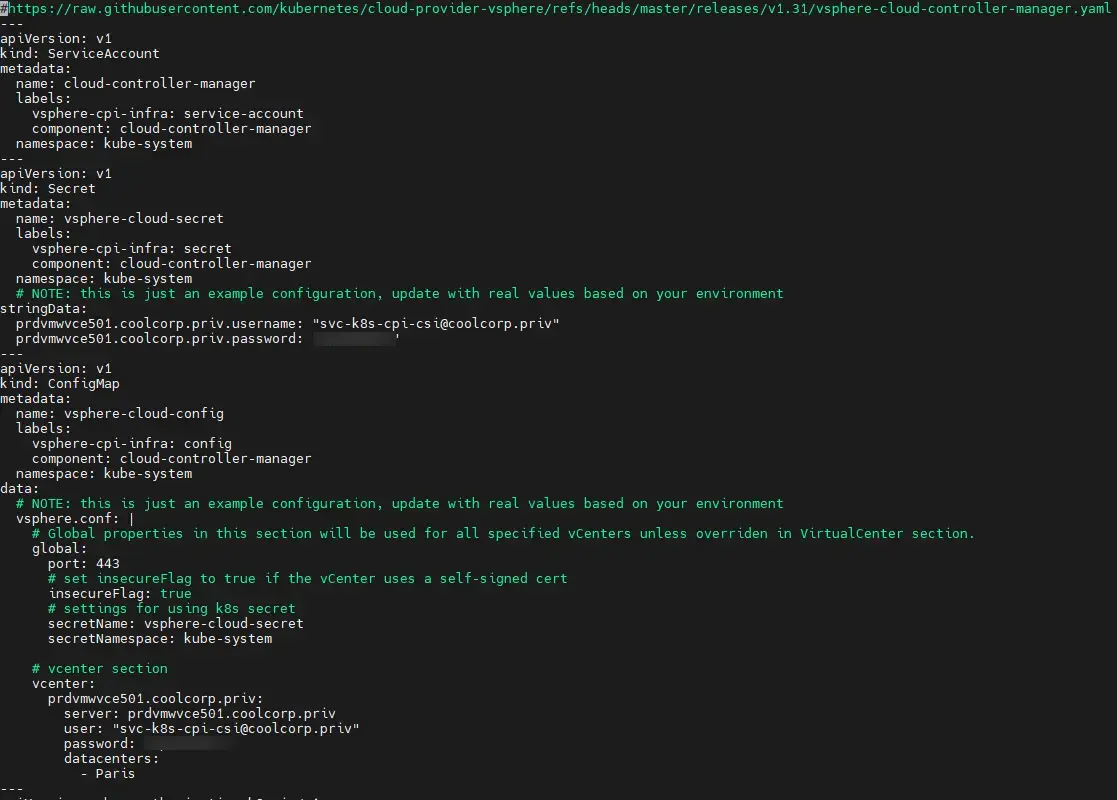
Cliquez sur l'image pour l'agrandir.
Il ne faut donc pas oublier de changer les éléments du fichier. Étant donné que j’utilise Ansible pour déployer mes prérequis lors de la mise en place d’un nouveau cluster, je n’oublie pas de mettre à jour le template Jinja que j’utilise avec cette nouvelle version du yaml.
Puis on peut appliquer la mise à jour avec la commande kubectl apply -f vsphere-cloud-controller-manager.yaml

Cliquez sur l'image pour l'agrandir.
On vérifie que les pods vsphere-cloud-controller-manager associés redémarrent correctement avec la commande kubectl get pod -n kube-system -o wide. On doit trouver un pod par control plane.

Cliquez sur l'image pour l'agrandir.
On poursuit avec le yaml associé au CSI, vsphere-csi-driver.yaml , qu’on peut également récupérer dans le repos du projet.
L’avantage est que celui-ci n’a pas à être modifié avant son exécution. (Pour ceux qui souhaite avoir le détail de son installation d'origine, la procédure est décrite ici). On peut dans la foulé l’appliquer via la commande kubectl apply -f vsphere-csi-driver.yaml
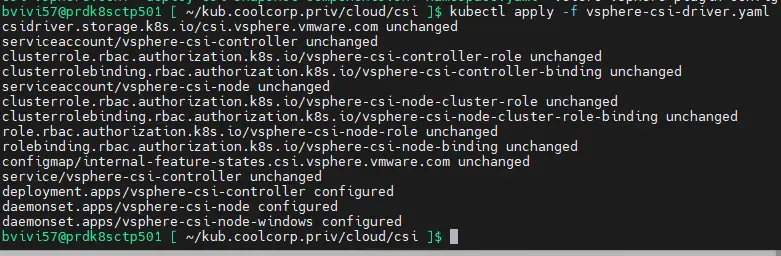
Cliquez sur l'image pour l'agrandir.
On s’assure que tout s’est passé correctement avec la commande kubectl get pod -n vmware-system-csi
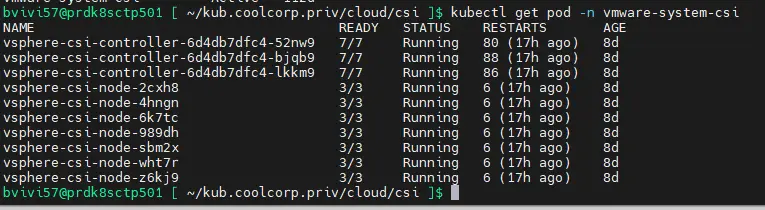
Cliquez sur l'image pour l'agrandir.
NB : concernant le CPI et le CSI, au moment de l’écriture de cet article, VMware a eu la bonne idée de modifier l’hébergement de certaines images appelées dans les yamls fraichement récupéré. Mais sans modifier la nouvelle URL des repos des conteneurs.
En effet, les drivers CSI, peu importe leurs éditeurs, sont amenés à être centralisés dans la registry global registry.k8s.io, ce qui n’était pas encore le cas pour vSphere.
Ce n’est pas sans conséquence puisque les images n’arrivent plus à être récupérées et les pods restent en erreur. J’ignore ce qu’il en sera au moment où vous lirez cet article, mais il m’a été nécessaire de modifier manuellement les urls dans les yaml récupérés. Si vous le souhaitez, ils sont disponibles dans mon repos github à cet emplacement (v1.31 pour le CPI(compléter les accès au vCenter), v3.3.1 pour le CSI .).
Autre petite astuce, si vous souhaitez minimiser le risque de voir un pod ne plus démarrer parce que le ou les images qu’il utilise ne sont plus disponibles, vous pouvez jouer sur l’option imagePullPolicy: associé au conteneur du pod.
Dans le cas du CSI, l’option est always, ce qui implique que même si l’image est disponible en cache localement sur le node, K8S souhaitera absolument la récupérer en ligne.
En modifiant l’option à IfNotPresent: alors, l’image sera récupérée en ligne uniquement si elle n’est pas trouvée en cache. Cela peu limiter l’incidence d’avoir une image indisponible en ligne, mais vous expose aussi à tourner avec une image locale qui n’est pas à jour et différente de celle du repos. À vous de voir.
En complément du CSI, si vous avez activé la prise en charge des snaphots, comme j’ai pu l’expliquer ici, il vous faudra également passer par le script deploy-csi-snapshot-components.sh récupéré dans le repo et le lancer à nouveau pour être certains qu’a ce niveau également, il n y ai pas de mise à jour à faire.
Une fois le CSI vSphere à jour (avec sa dépendance CPI) , on peut passer aux autres CSI du cluster.En l’occurrence NFS et SMB.
Traitement du CSI SMB et NFS
La logique est la même dans les deux cas. Comme j’ai pu le décrire dans l’article dédié au sujet, je suis passé par helm pour déployer ces derniers.
Il suffit donc de mettre à jour les repos helm avec la commande helm repo update
Puis d’appeler l’instruction helm upgrade accompagné des paramètres d’installation d’origine, en précisant la version cible du driver CSI consultable au niveau du repo
helm repo update
helm upgrade csi-driver-nfs csi-driver-nfs/csi-driver-nfs --namespace kube-system --version vNew
Même instruction pour le CSI SMB avec la version disponible dans le repo associé.
helm repo update
helm upgrade csi-driver-smb csi-driver-smb/csi-driver-smb --namespace kube-system --version vNew
Mise à jour du CNI
On peut maintenant passer au driver CNI (Container Network Interface). J’utilise Cilium. Vous pouvez avoir le détail de son installation ici.
Comme pour le CSI NFS et SMB, j’ai utilisé helm. On appelle donc la commande helm upgrade, avec les instructions d’installation de départ (et le fichier de config d’origine ) en précisant la version cible (les version sont consultables dans le repo du projet).
helm upgrade --version vNew --namespace=kube-system cilium cilium/cilium --values=./cilium-values.yaml --set hubble.relay.enabled=true --set hubble.ui.enabled=true
Il se peut que des erreurs apparaissent lors du premier essais...nous le verrons plus tard avec Traefik, mais parfois d'une version à une autres la syntaxe des fichiers de configuration exploité par Helm peut varier.
C'est le cas dans mon exemple, ou désormais il est imposé de faire figurer la notion de kubeProxyReplacement.
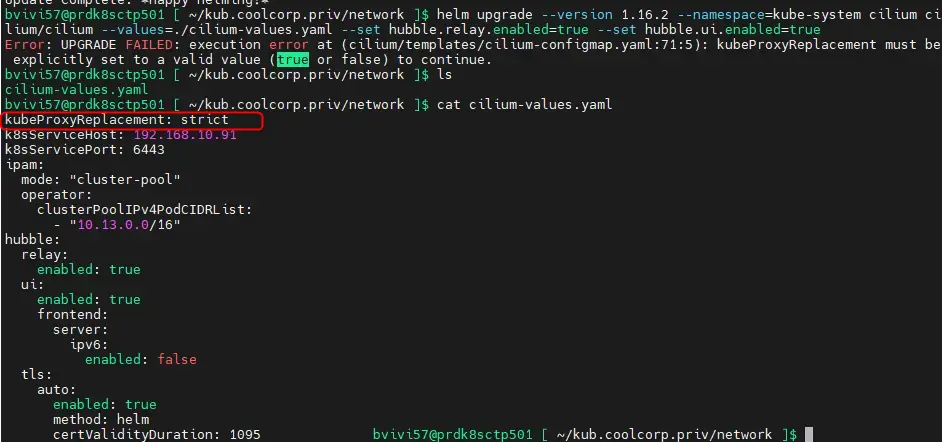
Cliquez sur l'image pour l'agrandir.
Il faut alors procéder à la correction du fichier passé en parametre et relancer la commande pour arriver à un résultat correcte.
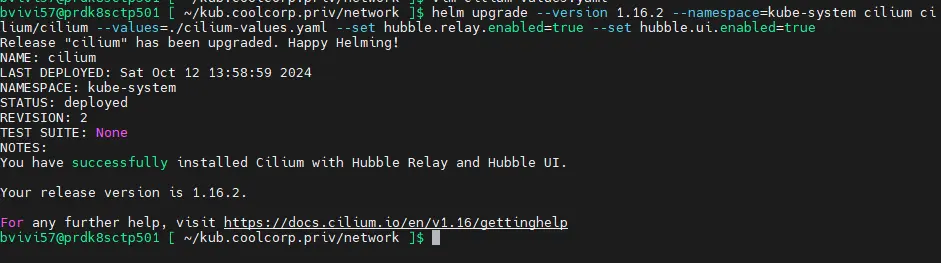
Cliquez sur l'image pour l'agrandir.
On vérifie que le CNI est opérationnel en s’assurant bien que les pod DNS internes au conteneur soient up kubectl get pod -n kube-system
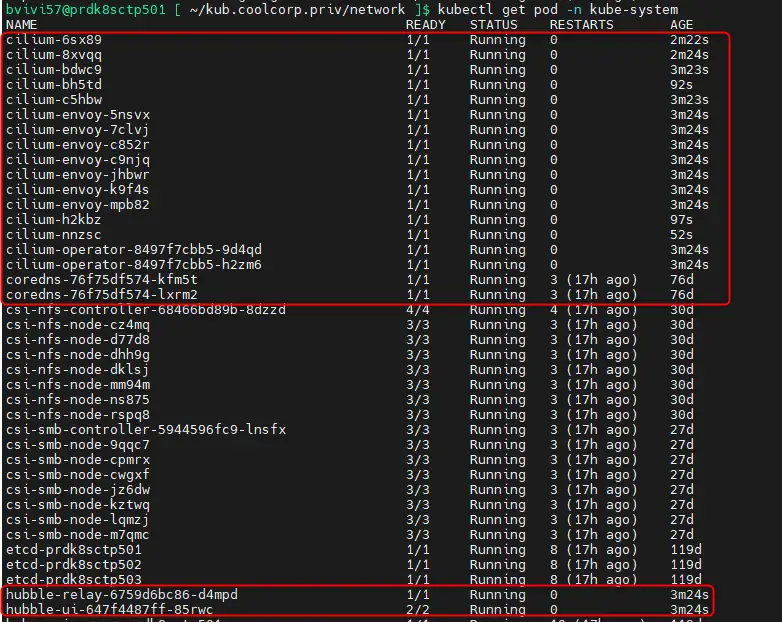
Cliquez sur l'image pour l'agrandir.
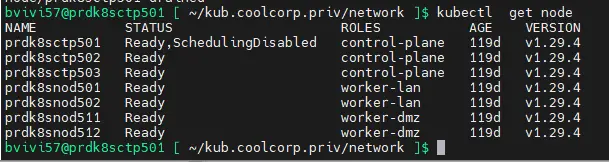
On s’assure également que les nodes sont tous en statue ready kubectl get node
Cliquez sur l'image pour l'agrandir.
Traitement des nodes
On peut passer maintenant à la mise à jour du runtime de container, de l’OS et de Kubernetes lui-même.
Pour cela on va devoir opérer node par node, en mettant en maintenance le serveur sur lequel on opère.
On commence par le premier control plane. Pour mettre en maintenance un nœud kubernetes, on n’utilise la commande kubectl drain suivi du nom du node.
Par contre, sans attributs complémentaires, il est fort possible que K8S n’accepte pas votre demande. En effet, l’orchestrateur cherche à appliquer toutes les contraintes qu’on pourrait lui avoir demandées dans l’exécution des pods.
Or pour mettre en maintenance un node, il faut que chaque pod soit évacué sur un autre node. Ce qui n’est pas toujours le cas fonction des labels, des taints et des ressources du cluster.
Il faut donc compléter la commande avec les arguments suivant:
kubectl drain --ignore-daemonsets --delete-emptydir-data nodename --force --disable-eviction
Si on tape la commande kubectl get node on devrait maintenant avoir notre premier control plane dans un statut SchedulingDisabled.
Cliquez sur l'image pour l'agrandir.
Mise à jour du runtime de container
On va commencer par le runtime de conteneur, soit dans mon cas containerd. Son installation a été réalisée via Ansible, directement à partir des binaires issus du site officiel et non du repos de l’OS. (Le détail de l'installation et des fichiers Ansible sont consultables ici)
Pour mon exemple, cela va donc consister à mettre à jour ma variable ansible précisant la version de containerd à récupérer et à relancer spécifiquement les taches d’installation via le tag ansible, en limitant le déploiement au node actuellement en maintenance.

Cliquez sur l'image pour l'agrandir.
Je ne vais pas revenir en détail sur ce point, vous pouvez trouver toutes les informations nécessaires à ce niveau.
Concrètement cela passe par la commande:
ansible-playbook playbooks/playbook_deploy_k8s.yml --ask-vault-pass -t role_k8s_deploy.containerd -l nodename
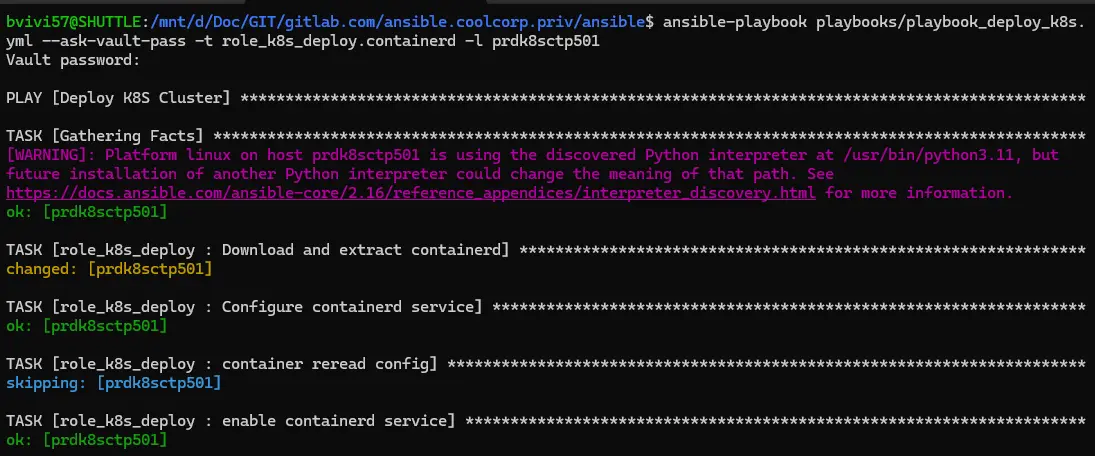
Cliquez sur l'image pour l'agrandir.
C’est l’avantage d’avoir exploité Ansible au départ de l’installation du cluster. Cela facilite un certain nombre d’opérations d’upgrade par la suite. On peut facilement suivre l’évolution du cluster à travers la mise sous git des fichiers Ansible.
Pour contrôler que le moteur de conteneur est à jour, on peut se connecter en root sur le node et tapez les commandes suivantes:
systemctl status containerd
containerd -version
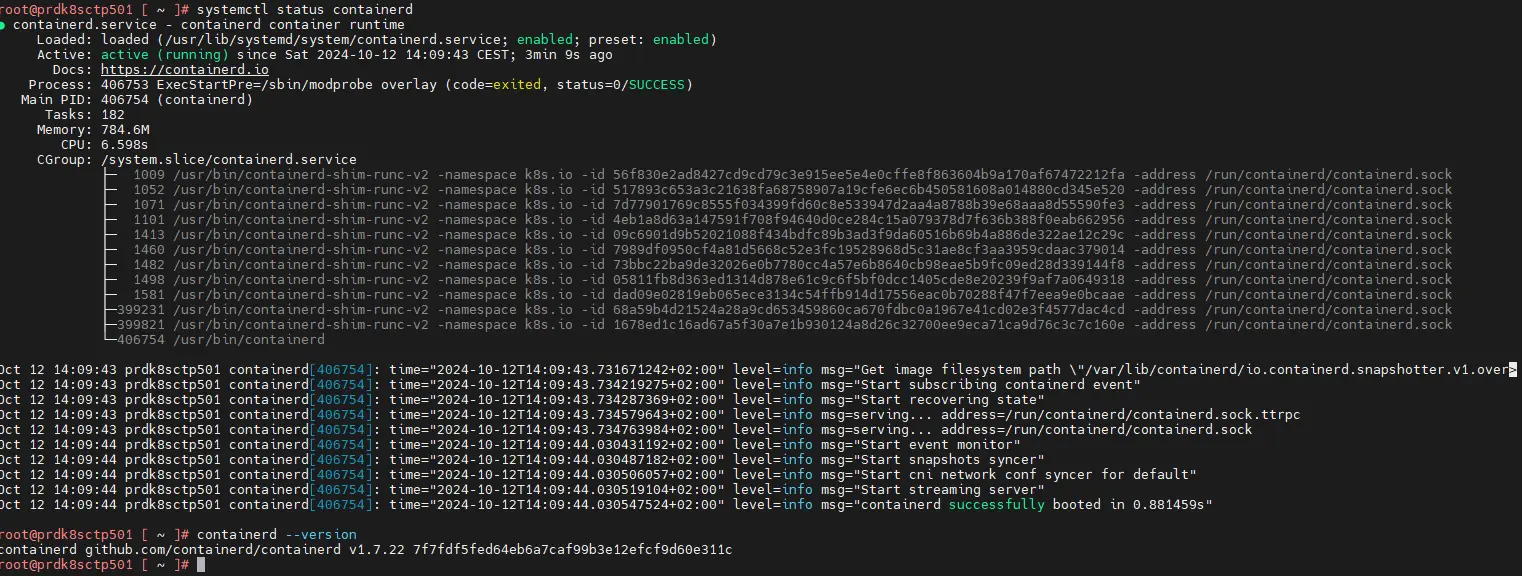
Cliquez sur l'image pour l'agrandir.
À noter également qu’à partir de la version 1.31, Kubernetes exige le support des cgroup en V2 au niveau du runtime. On peut donc en profiter pour vérifier si c’est bien le cas, histoire d’être prêt pour plus tard via la commande:
mount | grep cgroup

Cliquez sur l'image pour l'agrandir.
Mise à jour de l'OS
C’est au tour de l’OS en lui-même d’être mis à jour. L’updade du système dépend de la famille d’OS que vous utilisez. Dans mon cas, c’est particulier puisque mon cluster est basé sur PhotonOS, c’est le gestionnaire tdnf qui est employé.
De plus, je n’ai pas utilisé les repos par défaut de l’OS pour déployer Kubernetes. Il faut donc que je m’assure de ne pas installer de packages de base pour certains composants et d’exclure tous les applicatifs que j’ai pu déployer en dehors des repos par défaut (comme containerd précédemment upgradé).
Pour cela la commande est la suivante:
tdnf -y update --exclude="kubeadm,kubectl,kubelet,kubernetes-cni,containerd"
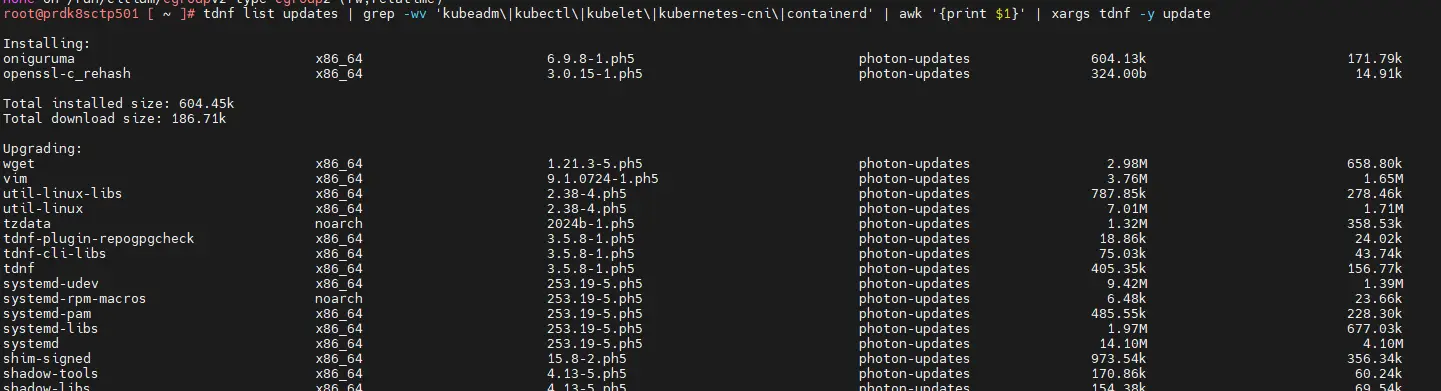
Cliquez sur l'image pour l'agrandir.
Par précaution, en fin d’update je redémarre l’OS.
Mise à des composants Kubernetes
On peut maintenant se concentrer sur Kubernetes lui-même.
À chaque release majeur de K8S, par exemple ici de 1.29 à 1.30, les repos par défaut du projet sont mis à jour.
Comme ce sont ces repos qu’on n’utilise, et qui avaient été ajoutés à ceux de l’OS lors de la préparation du système , il va falloir les modifier pour qu’ils correspondent à la version cible de K8S.
Là aussi, on passe par Ansible, puisque c’est ainsi qu’ils avaient été déployés au départ. Il suffit simplement de mettre la variable Ansible à jour, puisque le repos à été templétisé.

Cliquez sur l'image pour l'agrandir.
En repoussant uniquement les taches propres à la configuration du repos sur le node en maintenance, on obtient un repos à jour.
yml --ask-vault-pass -t role_k8s_deploy. repos -l nodenameansible-playbook playbooks/playbook_deploy_k8s.
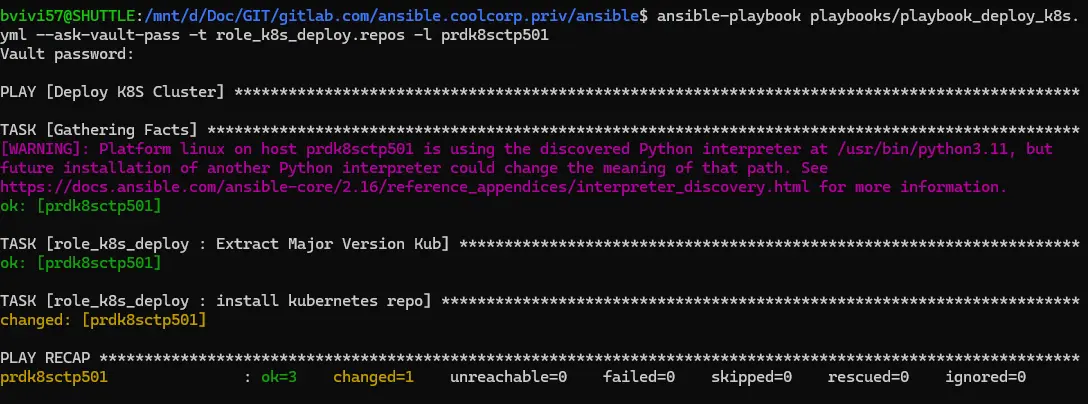
Cliquez sur l'image pour l'agrandir.
Si vous ne passez par ansible, c’est à vous de procéder à cette opération directement.
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.30/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.30/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
Il est désormais possible de mettre à jour les briques de bases du cluster. Cette opération est commune à tout cluster Vanilla déployé avec kubeadm.
kubeadm, justement, est le premier composant à mettre à jour. Pour cela on se met en root sur le node en maintenance puis on upgrade le binaire associé.
tdnf update kubeadm-1.xx.x (le gestionnaire de paquet est a adapté fonction de l’OS)

Cliquez sur l'image pour l'agrandir.
Il faut toujours préciser la version. Vous n’êtes jamais à l’abri qu’une version différente soit sélectionnée par votre gestionnaire. Au moins en précisant la version, vous vous assurez d’aller là ou vous voulez aller.
Une fois kubeadm à jour, toujours en root, vous pouvez appeler la commande d’upgrade:
kubeadm upgrade apply 1.xx.x

Cliquez sur l'image pour l'agrandir.
Tout devrait se faire tout seul, kubeadm détecte votre version de K8S et va procéder à la récupération des images k8s correspondant à sa version et redéployer l’ensemble.
Cela peut prendre un certain temps sur les control plane.
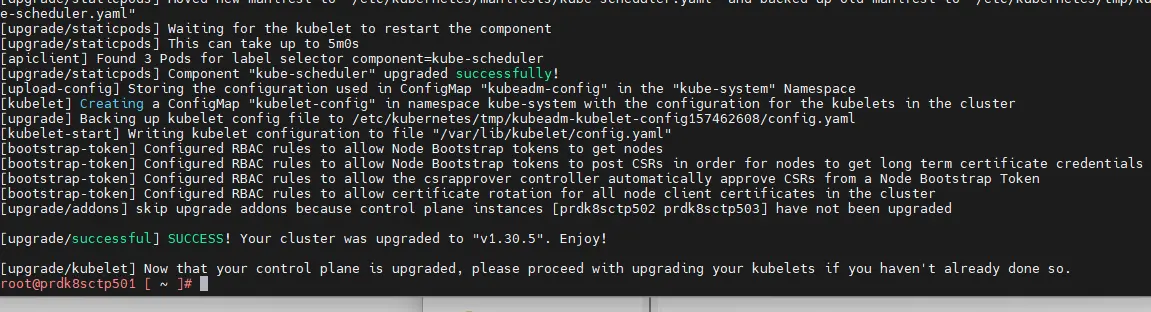
Cliquez sur l'image pour l'agrandir.
Attention si vous avez personnalisé les fichiers yaml par défaut des composants K8S récupérés par kubeadm lors de l’initialisation du cluster, il y’a de fortes chances que ces modifications soient oubliées. Il vous faudra les réappliquer par la suite.
Une fois qu’on a récupéré la main, on peut mettre à jour le reste des binaires Kuberneres, à savoir l’agent kubelet, et kubectl, toujours en précisant la version.
tdnf update kubelet-1.xx.x
tdnf update kubectl-1.xx.x
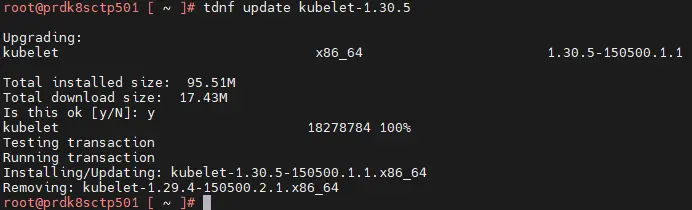
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Pour l’agent kubelet, il faut penser à le redémarrer, en ayant pris soin au préalable de recharger systemd.
systemctl daemon-reload
systemctl restart kubelet
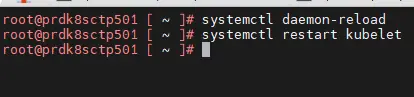
Cliquez sur l'image pour l'agrandir.
À partir de cette étape, on peut revenir à notre utilisateur standard, et sortir le node du mode maintenant avec la commande:
kubectl uncordon nodedname

Cliquez sur l'image pour l'agrandir.
Si on contrôle l’état des nodes avec la commande kubectl get node non seulement notre node est à nouveau dans un statut "ready", mais on peut voir que désormais sa version est 1.xx.x
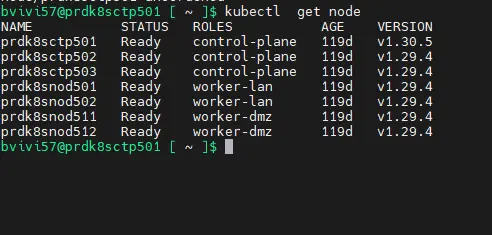
Cliquez sur l'image pour l'agrandir.
Pour éviter de rester dans une situation ou les nodes ne sont pas à la même release, il faut enchainer avec les autres serveurs.
Les taches sont exactement les mêmes que pour le premier control plane:
- On met en maintenance le node:
kubectl drain --ignore-daemonsets --delete-emptydir-data nodename --force --disable-eviction - On met à jour containerd:
ansible-playbook playbooks/playbook_deploy_k8s.yml --ask-vault-pass -t role_k8s_deploy.containerd -l nodename - On met à jour l’OS:
tdnf -y update --exclude="kubeadm,kubectl,kubelet,kubernetes-cni,containerd" - On redémarre le node
- On met à jour les repos:
ansible-playbook playbooks/playbook_deploy_k8s.yml --ask-vault-pass -t role_k8s_deploy.repos -l nodename - On met à jour kubeadm:
tdnf update kubeadm-1.xx.x - On lance l’upgrade de K8S:
kubeadm upgrade nodepetite variante à ce niveau pour les autres nodes, il n’est plus nécessaire de préciser la version à mettre à jour. - On met à jour l’agent kubelet en le redémarrant:
tdnf update kubelet-1.xx.xsystemctl daemon-reloadsystemctl restart kubelet- On met à jour kubectl (control plane uniquement)
tdnf update kubectl-1.xx.x - On sort le node du mode maintenance:
kubectl uncordon nodename
Il faut procéder d’abord par tous les control plane, puis ensuite sur les worker. À noter que pour les worker, la mise à jour de kubectl n’est pas nécessaire. Vous observez également que la mise à jour des worker est beaucoup plus rapide.
En fin d’opération, on devrait avoir tous nos nodes à la cible. kubectl get node
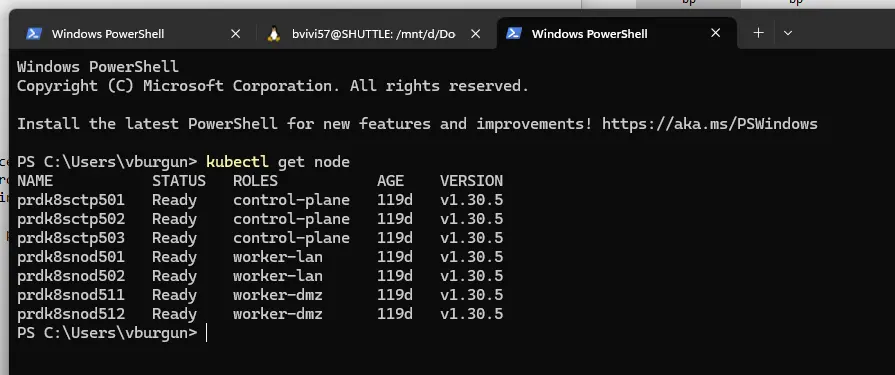
Cliquez sur l'image pour l'agrandir.
Il ne faut bien sûr par oublier d’upgrader kubectl sur son poste de travail, afin que lui aussi corresponde à la nouvelle release. Pour cela il faut récupérer le binaire correspondant à l’OS de son poste client.
Cliquez sur l'image pour l'agrandir.
Mise à jour des addons
Arrivé à cette étape, le cluster est enfin à jour, avec tous les composants système inclus.
On pourrait s’arrêter là, mais on va terminer par les deux solutions additionnelles déployées sur le cluster.
Mise à jour de Traefik
On démarre par Traefik, son usage et son installation sont détaillés ici.
Sa mise à jour est relativement simple, puisque là aussi on passe par helm.
Dans mon cas, lors de l’installation, je suis passé par un fichier de configuration spécifique. Ce fichier a été templétiser pour être généré par Ansible et exploite une variable indiquant la version cible de Traefik.
Dans un premier temps, il me faut donc mettre à jour cette variable et redéployer mon fichier de conf via l’instruction ansible:
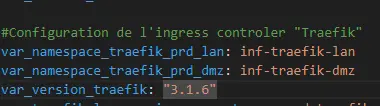
Cliquez sur l'image pour l'agrandir.
ansible-playbook playbooks/playbook_deploy_k8s.yml --ask-vault-pass -t role_k8s_deploy.traefik

Cliquez sur l'image pour l'agrandir.
N’hésitez pas à lire mon article dédié sur Traefik pour mieux comprendre ce passage.
Une fois le fichier à jour, je peux l’appeler en complément des instructions helm de l’époque, mais avec le mot clef upgrade
Par contre attention, Traefik a la fâcheuse tendance à modifier quelquefois sa logique au fur à mesure des versions.
helm est censé simplifier les updates, mais dans ce cas, et comme je m’appuie sur un fichier de configuration spécifique, je me suis aperçu qu’un mot clef de ce fichier, a savoir, image n’est désormais plus interprété par ma version cible de traefik .

Cliquez sur l'image pour l'agrandir.
Il m’a fallu repasser par la case template, pour tenir compte de cette modification et à nouveau redéployer mon fichier de configuration avec ansible pour enfin rappeler la commande helm upgrade, d'abord pour mettre à jour mon instance trafik du lan.
helm upgrade traefik-lan traefik/traefik -f traefik-config-lan.yaml -n inf-traefik-lan --set nodeSelector.traefik-lan=yes --set tolerations[0].key=node-role.kubernetes.io/control-plane --set tolerations[0].operator=Exists --set tolerations[0].effect=NoSchedule
Puis pour mettre mon instance trafik à jour en DMZ
helm upgrade traefik-dmz traefik/traefik -f traefik-config-dmz.yaml -n inf-traefik-dmz --set nodeSelector.traefik-dmz=yes --set tolerations[0].key=node-role.kubernetes.io/worker-dmz --set tolerations[0].operator=Exists --set tolerations[0].effect=NoSchedule

Cliquez sur l'image pour l'agrandir.
(N'hésitez pas à revoir mon architecture kubernetes pour mieux comprendre ce point).
Cette fois-ci Traefik s’est bien mis à jour.
On peut vérifier le statut des pods kubectl get pod -n inf-traefik-lan -o wide / kubectl get pod -n inf-traefik-dmz -o wide, ainsi que l'URL d’administration pour voir apparaitre la nouvelle version.

Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
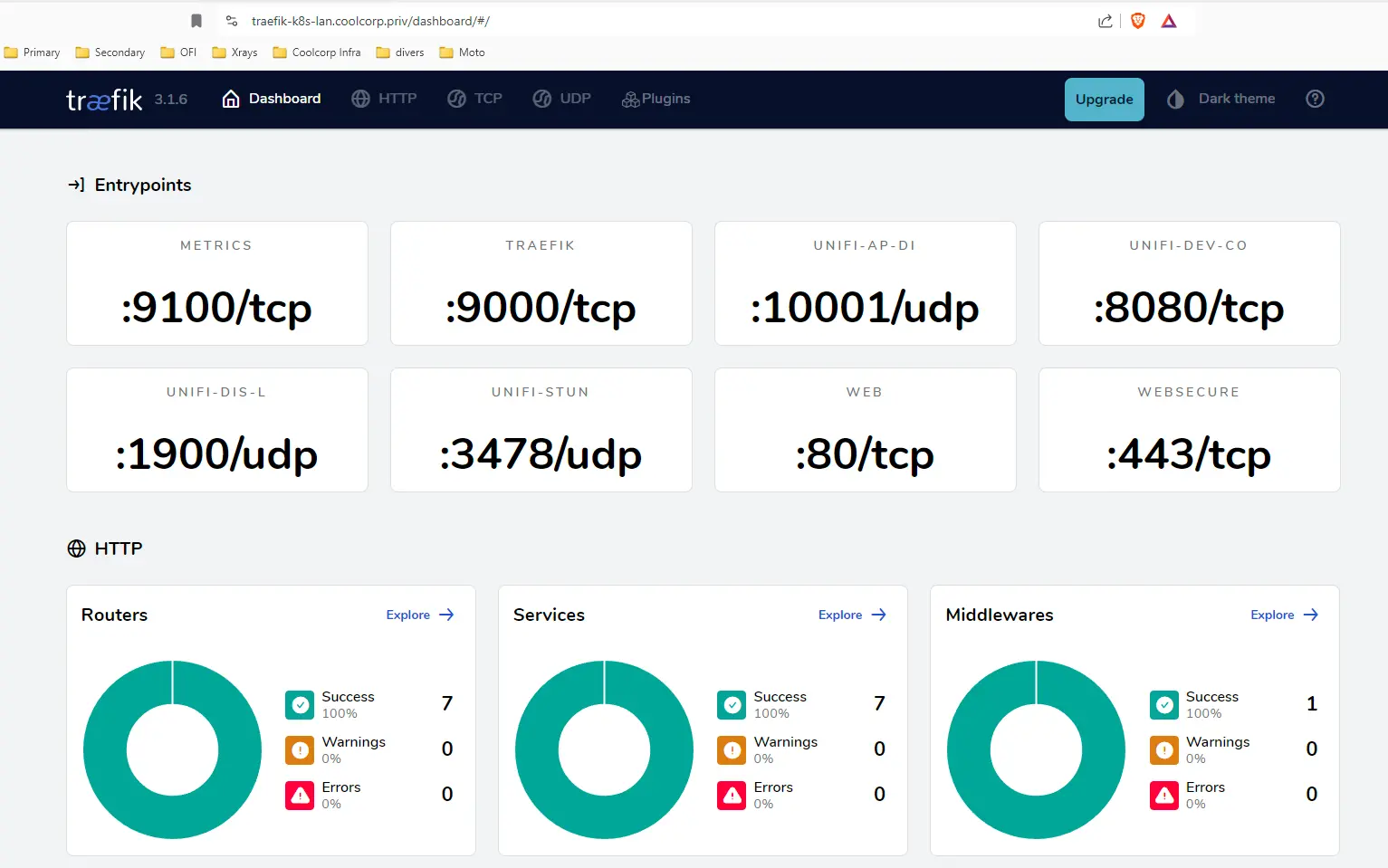
Cliquez sur l'image pour l'agrandir.
Cette mise à jour démontre un point important: attention aux changements fonctionnels des addons et objets customisés.
En dehors du contrôle des matrices de compatibilités, il faut bien que vous étudiez les impacts des mises à jour telle que Traefik (comme pour Cilium). L’éditeur peut très bien décider de modifier non seulement ses attributs d’installation, mais également la définition des objets customisés qu’il ajoute à l’API Kubernetes.
Traefik a déjà réalisé ce type de modification, et vous pouvez vous retrouver avec une installation fonctionnelle, mais avec des objets orphelins que traefik, dans sa nouvelle version, ne sait plus traiter.
Il faut à ce moment passer par le redéploiement de tous les objets impactés que vous auriez écrit suivant l’ancienne définition livrée avec la version précédente de traefik.
Fort heureusement, lorsque l’éditeur fait ce choix, il laisse le plus souvent une période de transition ou l’ancienne et la nouvelle définition des objets sont prises en compte durant un certain nombre de releases…mais au bout d’un moment cette rétrocompatibilité s’arrête et il faut que vous procédiez aux modifications de vos objets…penser y donc le plus tôt possible et analyser bien les release nodes.
Mise à jour de Cert-Manager
C'est au tour de cert-manager.
C’est parmis le plus simple, puisque là aussi on passe par helm et sans fichier de configuration custom. N’hésitez pas à lire l’article associé sur son déploiement.
Sa mise à jour passe donc par la commande helm upgrade précisée des options d’origine et de la version cible à déployer (voir le repo du projet pour sélectionner la version).
helm upgrade cert-manager jetstack/cert-manager --namespace inf-cert-lan --version vx.xx.x --set crds.enabled=true
Cliquez sur l'image pour l'agrandir.
On peut s’assurer que tout est OK via la commande:
kubectl get pod -n inf-cert-lan -o wide

Cliquez sur l'image pour l'agrandir.
Conclusion
Le cluster, ses composants et ses addons sont désormais à jour. Cet article a pour vocation de mettre en avant la complexité potentielle, mais maitrisable, que peut amener la mise à jour d’un cluster vanilla K8S.
Tant que vous êtes organisé et que vous conservez un rythme d’update régulier (au moins 2x par an), on reste sur des opérations qui restent réalisables dans une mission de maintien en condition opérationnelle.
Bien entendu avec des infrastructures conséquentes, disposant de plusieurs clusters et de nombreux nodes, il devient vital d’automatiser et d’industrialiser davantage toutes les opérations que j’ai pu décrire ici.
Même de mon côté avec mon petit cluster, je gagnerai à aller chercher davantage d’automatisation. Je n’exploite aux finales que très peu Ansible. On trouve de nombreux exemples sur Internet de personne ayant été beaucoup plus loin pour mettre à jour un cluster à partir d’outil comme Ansible.
Dans tous les cas, savoir décomposer son update et maitriser la mise à jour de tous les composants vous fait gagner en maturité et en compétence à chaque itération.
Vous êtes à même de mieux comprendre ce qui se passe au sein de votre cluster. Vous maitrisez petit à petit le rôle de chaque composant et si par la suite des incidents se produisent vous êtes plus à même de les comprendre et de les résoudre.
Il est indéniable que des distributions comme OpenShift, ou que l’usage de clusters managés dans le cloud simplifient énormément les opérations d’update. Mais vous n’êtes pas non plus à l’abri d’un problème, et dans ce cas vous dépendez exclusivement du support de l’éditeur. De plus, vous pouvez être soumis à la pression des updates, notamment dans le cloud, ou vous n’avez le plus souvent pas le choix du calendrier des mises à jour.
À l’image des chasseurs (😊) il n’y a pas de bonnes ou de mauvaises solutions. Il est même tout à fait envisageable d'avoir différents types de clusters K8S. Certains vanilla onprem, et d’autres, managés dans le cloud. Ou plusieurs clusters OpenShift hébergée dans différents écosystèmes, public ou privée.
C’est à vous de retenir la solution qui vous convient le mieux et qui répond à vos exigences et aux compétences de vos équipes. Mais n’écartez pas forcément un cluster Vanilla par peur des upgrades…si vous construisez une architecture cohérente et comprise de vos admin/ops/dev (Kubernetes ne doit pas etre la chasse gardée d'une équipe), il n’y a aucune raison que vos opérations de mise à jour ne puissent pas se terminer finalement par un simple lancement d’un playbook Ansible ou de l’exécution une pipeline Jenkins.