Étape 3 : déploiement des prerequis
Introduction
Les serveurs étant tous déployés et prêts à l’emploi, il est temps d’appliquer la configuration nécessaire à l’hébergement du cluster Kubernetes.
La logique retenue est d’exploiter Ansible pour paramétrer sur chaque serveur les prérequis nécessaires à l’installation et au bon fonctionnement de K8S.
L’avantage de cette méthode est de pouvoir facilement rejouer des déploiements et suivre au fil du temps l’évolution de son cluster en modifiant uniquement des variables Ansible.
Organisation Ansible
La poursuite de cette étape nécessite d’avoir une instance Ansible configurée et prête à l’emploi. Pour rappel, les VMs déployées s’appuient sur un template dont on n’a spécifiquement préparé la couche SSH pour être pilotée par Ansible.
De mon côté, Ansible est installé sur mon poste de travail Windows à travers la couche WSL. L’outil a été paramétré pour tenir compte dans son inventaire d’une connexion au vCenter afin de relever les VMs disponibles et de créer, à la volée, des groupes basés sur les tags des VMs. Ces tags ayant été dans l’étape précédente, déployés en même temps que les VMs grâce à OpenTofu (Terraform).
L’exercice va donc être de créer un rôle Ansible role_k8s_deploy, lancé par un playbook playbook_deploy_k8s.yaml.
Fonction des tags rattachés aux VMs, les actions décrites dans le rôle Ansible vont s’appliquer soit à l’ensemble des serveurs, soit aux control plane, soit aux workers, soit aux load balancer. N’hésitez pas à faire un tour dans la définition de l’architecture pour être au clair sur le périmètre de chacune des VMs.
Ansible s’appuie sur une arborescence de fichiers bien spécifique, avec des noms de dossiers à respecter qui vont chacun contenir des éléments particuliers. Il est bien entendu possible d’adapter cette arborescence et d’exploiter l’ensemble selon différentes stratégies.
Voici une description de ce qui va être utilisé pour cet article.
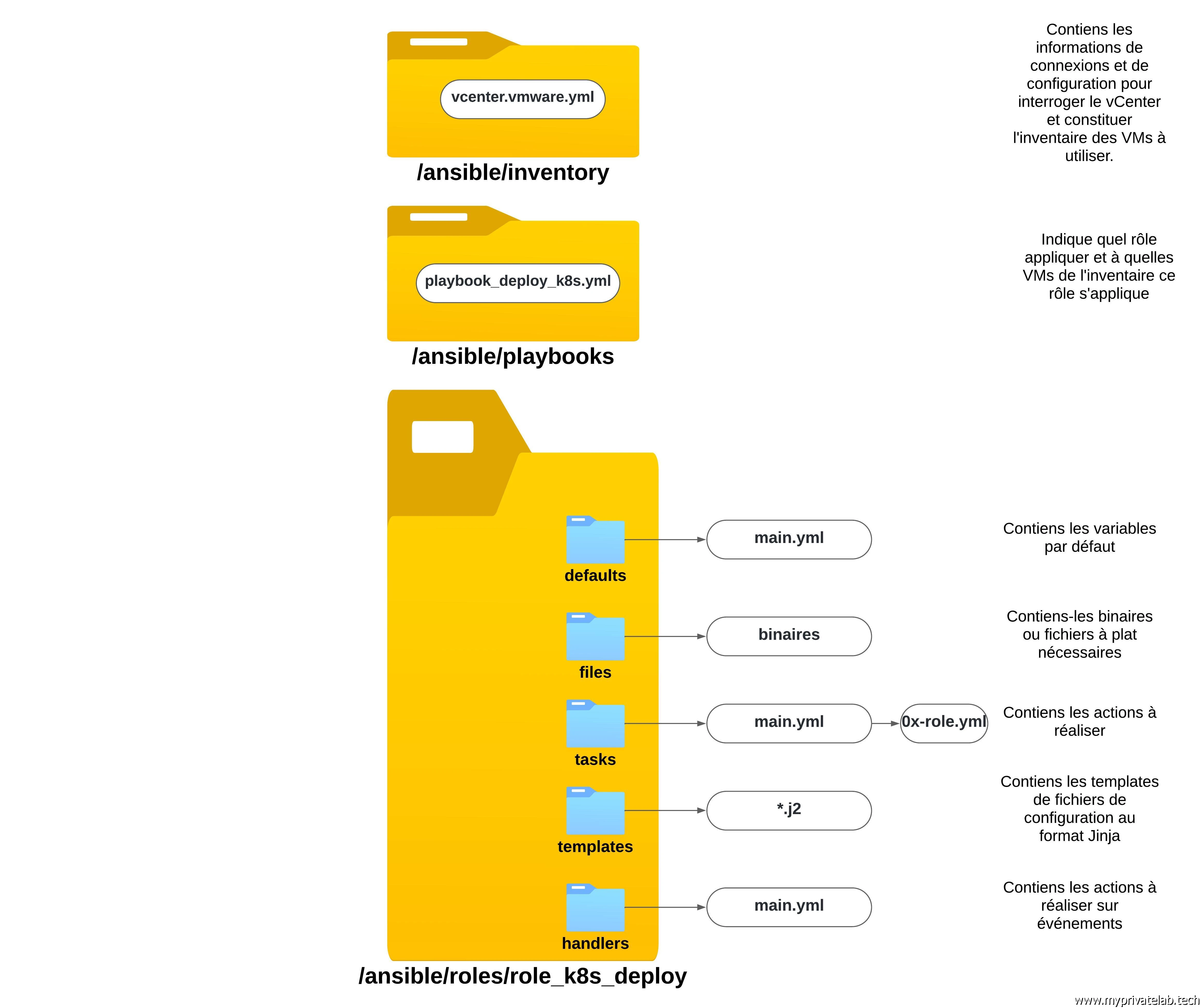
Cliquez sur l'image pour l'agrandir.
Inventaire Ansible
Le contenu du fichier d’inventaire est décrit dans l’article correspondant.
Playbook Ansible
Le contenu du playbook playbook_deploy_k8s.yml est très basique.
#Deploie le role "role_k8s_deploy" sur tous les serveurs appartenant au groupe "TAG_COOLCORP_APPS_K8S"
---
- name: Deploy K8S Cluster
hosts: TAG_COOLCORP_APPS_K8S
roles:
- role_k8s_deploy
Il va permettre d’appliquer le rôle role_k8s_deploy à toutes les VMs du groupe TAG_COOLCORP_APP_K8S, autrement dit toutes les VMs disposant de ce tag, soit toutes les VMs déployées précédemment avec OpenTofu (Terraform).
Pour lancer le déploiement, il suffit d’appeler le playbook via la commande:
ansible-playbook playbooks/playbook_deploy_k8s.yml --ask-vault-pass
Pour rappel, l’inventaire disposant des accès au vCenter, le fichier est chiffré et nécessite le passage d’un mot de passe demandé par l’option --ask-vault-pass
La commande va permettre de démarrer l’exécution des commandes à destination des serveurs.
Gestion des variables
En premier lieu, Ansible va charger les variables présentes dans le fichier main.yml du dossier defaults.
Comme vous le constatez, chacune des variables est nommée var_quelquechose. L’idée est de rester dans une bonne pratique qui facilite la lecture et l’interprétation de l’information, mais chacun peut exploiter la norme de nommage de son choix.
Le contenu du fichier est segmenté en section:
Variables système
Variables globales, propres à l’ensemble des serveurs, comme le nom du serveur ntp à utiliser, la définition des tags…
#####Variables systeme
var_lan_tag: TAG-COOLCORP-NETWORK-LAN
var_web_tag: TAG-COOLCORP-NETWORK-WEB
var_ntp_server: ntp.ofivalmo.fr
var_domain: "coolcorp.priv coolcorp.fr"
#variable user
var_admin_user: bvivi57
Variables packages
Ces variables définissent la liste des paquets à installer sur tel ou tel serveur fonction du rôle qu’il va avoir. On y’défini aussi les packages présents par défaut dans le système qu’il faut retirer pour éviter tout conflit.
######Variables Packages
#Liste des paquets à déployer sur les control planee
var_k8s_packages_master:
- kubeadm-{{ var_kub_version }}
- nfs-utils
- tdnf-plugin-repogpgcheck
- wget
- tar
- kubectl-{{ var_kub_version }}
- kubelet-{{ var_kub_version }}
- apparmor-parser
- jq
- cri-tools
- git
- linux
#Liste des paquets à déployer sur les nodes
var_k8s_packages_worker:
- kubeadm-{{ var_kub_version }}
- nfs-utils
- tdnf-plugin-repogpgcheck
- wget
- tar
- kubelet-{{ var_kub_version }}
- apparmor-parser
- cri-tools
- linux
#Liste des paquets à supprimer
var_remove_packages:
- docker
- containerd
À noter que certaines variables font appel elles-mêmes à d'autres variables comme la version de kubernetes définie plus loin dans le fichier.
Variables K8S
La dernière section est la plus importante et la plus lourde, puis qu’elle définit toutes les variables propres à K8S et aux composants annexes.
###############Variable Kubernetes
#Variables utilisées pour construire le fichier de configuration de kubeadm basé sur le template kubeadm.conf.j2 du dossier templates
var_api_version: v1beta3
var_kub_version : "1.29.4"
var_kub_name: kub
var_pod_subnet: "10.11.0.0/16"
var_service_subnet: "10.12.0.0/16"
var_vip_kub_endpoint: kub.coolcorp.priv
var_vip_kub_vip: "192.168.10.91"
var_vip_kub_vip_dmz: "192.168.5.91"
#Variables pour définir les roles
var_tag_master: TAG-COOLCORP-ROLE-MASTER
var_tag_worker: TAG-COOLCORP-ROLE-WORKER
#Variables définissant les ports à ouvrir
#- ports "system" pour kubernetes
var_kubelet_port: 10250
var_kube_api_port: 6443
var_etcd_port: 2379
var_etcd_member_port: 2380
var_node_service_port: "30000:32767"
#- ports "réseau" pour le fonctionnement du CNI Cilium
var_cilium_udp_vxlan_port: 8472
var_cilium_tcp_healt_port: 4240
var_cilium_tcp_obser_port: 4222
var_cilium_tcp_relay_port: 4245
var_cilium_tcp_hubblepeer_port: 4244
#Configuration de Cilium
var_cilium_subnet: "10.13.0.0/16"
var_cilium_cli: "https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz"
#Lien vers la récupération du binaire containerd
var_containerd_binary: https://github.com/containerd/containerd/releases/download/v1.7.16/containerd-1.7.16-linux-amd64.tar.gz
#informations pour la connexion au vcenter pour l'addon VMware Kubernetes
var_vcenter: vcenter.coolcorp.priv
var_vcenter_user: [email protected]
var_vcenter_password: "mot_de_passe_qui_ne_devrait_pas_être_visible"
var_vcenter_datacenter : "Paris"
#Configuration de l'ingress controler "Traefik"
var_namespace_traefik_prd_lan: prd-traefik-lan
var_namespace_traefik_prd_dmz: prd-traefik-dmz
var_version_traefik: "2.10.4"
var_traefik_lan_service_account: svc-prd-traefik
var_traefik_dmz_service_account: svc-prd-traefik-dmz
var_url_traefik_lan: traefik-lan.coolcorp.priv
var_url_traefik_dmz: traefik-dmz.coolcorp.priv
La sous partie kubeadm, va permettre de définir le contenu du fichier de configuration que l’on va passer à kubeadm lors du déploiement du cluster. Pour cela, le fichier est templetisé sous le format jinja, nommé kubeadm.conf.j2 et présent dans le dossier templates.
Voici son contenu:
---
apiVersion: kubeadm.k8s.io/{{ var_api_version }}
kind: ClusterConfiguration
kubernetesVersion: {{ var_kub_version }}
networking:
podSubnet: "{{ var_pod_subnet }}"
serviceSubnet: "{{ var_service_subnet }}"
controlPlaneEndpoint: "{{ var_vip_kub_endpoint }}:6443"
clusterName: "{{ var_kub_name }}"
controllerManager:
extraArgs:
cloud-provider: external
apiServer:
certSANs:
- {{ var_vip_kub_vip }}
- {{ var_vip_kub_endpoint }}
Lors de l’exécution de Ansible, le fichier sera copié à la destination voulue en prenant les valeurs définies dans les variables du main.yml. Les détails de ces valeurs et les explications associées seront donnés dans un article futur, mais c’est à ce niveau par exemple qu’on va définir quelle version de Kubernetes on souhaite déployer. À l’heure d’écrire cet article K8S est disponible en version 1.30.1 mais je préfère rester sur la dernière release de la branche 1.29 à savoir 1.29.5. On n’aura de toute façon l’occasion de décrire une opération d’update.
D’autres variables sont disponibles, notamment pour préparer la configuration de la couche réseau avec le déploiement de Cilium, la configuration de Traefik pour exposer ses applications, ainsi que quelques paramètres de bases pour les add on vmware.
À noter que pour ces derniers, un mot de passe est présent en clair…ce qui n’est pas bien du tout. Idéalement il faudrait procéder de la même manière que pour le fichier d’inventaire et chiffrer son contenu avec la fonction vault intégrée à Ansible. On va dire que j’ai été fainéant…mais dans une vraie production, il ne faut jamais laisser d’informations d’identifications en clair dans une configuration Ansible.
Gestion des actions
Une fois les variables chargées, Ansible va poursuivre l’exécution des actions décrites dans le dossier tasks, en commençant toujours par le contenu du fichier main.yml
En l’occurrence, l’usage du main.yml est ici uniquement destiné à faire appel aux autres fichiers yaml présents au sein du même dossier.
---
#Ajout du repo Kubernetes pour la récupération des paquets officiels (installation vanilla)
- name: "Repository Configuration"
import_tasks: 01-repos.yml
tags:
- role_k8s_deploy.repos
#Lancement de l'installation des prerequis
- name: "Prerequis"
import_tasks: 02-prerequis.yml
tags:
- role_k8s_deploy.prerequis
#Configuration des flux réseau avec ouverture des ports
- name: "iptables configuration"
import_tasks: 03-iptables.yml
tags:
- role_k8s_deploy.iptables
#Installation du runtime de conteneur "containerd"
- name: "containerd installation"
import_tasks: 04-containerd.yml
tags:
- role_k8s_deploy.containerd
#Création des fichiers de configuration pour le déploiement de Kubernetes
- name: "K8S configuration"
import_tasks: 05-configure-k8s.yml
tags:
- role_k8s_deploy.configure-k8s
#Configuration et installation des loadbalancer
- name: "HAproxy configuration"
import_tasks: 06-configure-haproxy.yml
tags:
- role_k8s_deploy.haproxy
#Création de la configuration traefik
- name: "Traefik config"
import_tasks: 08-configure-traefik.yml
tags:
- role_k8s_deploy.traefik
Ceci afin d’éviter d’avoir un seul fichier contenant toutes les taches à réaliser. Pour une meilleure compréhension et une maintenabilité plus simple, il est conseillé de découper son déploiement en sous-taches, chacune étant décrite dans des fichiers spécifiques.
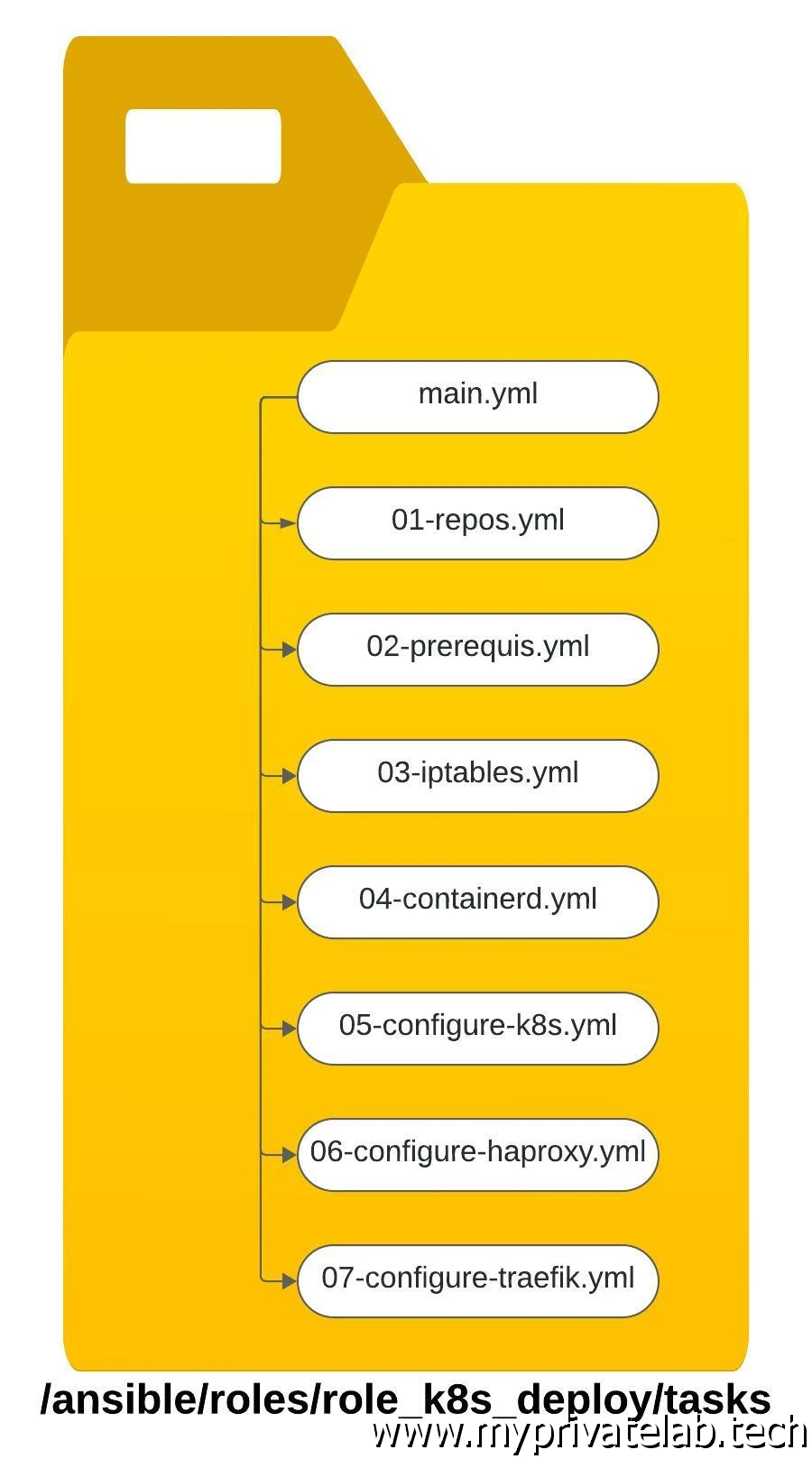
Cliquez sur l'image pour l'agrandir.
À noter également l’importance d’associer des tags à chaque action. L’avantage est ainsi de pouvoir exploiter Ansible en précisant un tag spécifique pour ne rejouer qu’une partie seulement des commandes.
Cela peut s’avérer très pratique lorsque vous mettez à jour votre déploiement qui n’impacte qu’une partie seulement de l’installation. Inutile de rejouer tout le rôle.
Prenez l’habitude de choisir une nomenclature de vos tags et de vos fichiers yaml. Dans mon cas, je préfixe les yaml par un numéro pour simplifier la lecture de l’ordre des actions. De même mes tags font toujours appel au nom de la racine, puis portent une extension supplémentaire à fur à mesure qu’on descend dans l’arborescence.
Si on entre dans le détail, voici le contenu des fichiers:
01-repos.yml
---
#extraction de la version majeure à partir de la variable var_kub_version. La valeur sera positionnée dans une nouvelle variable "var_kub_major_version"
- name: Extract Major Version Kub
become: yes
set_fact:
var_kub_major_version: "v{{ var_kub_version.split('.')[0:2] | join('.') }}"
tags: role_k8s_deploy.repos.setversion
#Deploiement du fichier repos kubernetes.repo dans /etc/yum.repos.d/ via le template kubernetes.repo.j2"
- name: "install kubernetes repo"
become: yes
template:
src: kubernetes.repo.j2
dest: "/etc/yum.repos.d/kubernetes.repo"
tags: role_k8s_deploy.repos.deploy
Ce fichier va permettre d’ajouter les repos Kubernetes comme source d’installation sur les VMs photonOS.
Cela correspond à l’ajout d’un fichier kubernetes.repo dans /etc/yum.repos.d/kubernetes.repo
Le fichier est construit celon le template kubernetes.repo.j2 présent dans le dossier templates dont voici le contenu:
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/{{ var_kub_major_version }}/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/{{ var_kub_major_version }}/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
À chaque release majeure de Kubernetes, un nouveau repo est mis à disposition, c’est pourquoi avant de générer le fichier, une tache Ansible va récupérer dans la variable indiquée dans le main.yml uniquement la version majeure. Cette version va permettre de construire le fichier de repo fonction du template kubernetes.repo.j2 trouvé dans le dossier templates.
02-prerequis.yml
Ce fichier va déployer un certain nombre de paramètres afin de s’assurer d’avoir des OS compatibles avec les prérequis Kubernetes.
---
#Désactivation de la SWARP sur tous les serveurs
- name: Disable swap (if configured).
become: yes
command: swapoff -a
tags: role_k8s_deploy.prerequis.swap
#Message de debug pour connaitre sur quel type de serveur s'exécute les actions
- debug:
msg: "{{ tags }}"
#installation des packages sur les control plane (liste des paquets défini dans "main.yml" du dossier "defaults")
- name: Install basic packages for master
become: yes
tdnf:
update_cache: yes
name: "{{ var_k8s_packages_master }}"
state: present
when: "'TAG-COOLCORP-ROLE-MASTER' in tags"
tags: role_k8s_deploy.prerequis.packages_master
#installation des packages sur les workers (liste des paquets défini dans "main.yml" du dossier "defaults")
- name: Install basic packages for worker
become: yes
tdnf:
update_cache: yes
name: "{{ var_k8s_packages_worker }}"
state: present
when: "'TAG-COOLCORP-ROLE-WORKER' in tags"
tags: role_k8s_deploy.prerequis.packages_worker
#suppression des paquets inutiles ou conflictuels (liste des paquets défini dans "main.yml" du dossier "defaults")
- name: remove non necessary packages
become: yes
tdnf:
update_cache: yes
name: "{{ var_remove_packages }}"
state: absent
tags: role_k8s_deploy.prerequis.remove-package
#copie du binaire helm depuis le dossier "files" vers /usr/local/bin/ mais uniquement sur les control plane
- name: install helm
become: yes
copy:
src: helm
dest: /usr/local/bin/helm
owner: "{{ var_admin_user}}"
mode: u=rwx,g=rx,o=r
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-NETWORK-WEB' in tags"
tags: role_k8s_deploy.prerequis.helm
#reboot des machines
- name: Unconditionally reboot the machine with all defaults
become: yes
reboot:
tags: role_k8s_deploy.prerequis.reboot
La première étape va consister à désactiver la swap. À ce jour, Kubernetes ne supporte pas l’usage de la SWAP, même si sa prise en compte est en bêta depuis la version 1.28. Il reste au moment de l’écriture de cet article conseillé de désactiver la swap. Celle-ci peut interférer négativement dans la gestion des ressources et la prédictibilité proposées par K8S pour l’orchestration des conteneurs.
Dans l’exemple cité ici, c’est directement l’instruction swapoff -a qui est appelée via le module command de Ansible. Ce module est à utiliser avec parcimonie, car il ne permet pas en l’état de rendre l’action idempotent, c’est-à-dire reproductible sans modification. L’un des nombreux intérêts d’Ansible est de pouvoir s’assurer que la configuration d’un asset correspond à un état spécifique. Cet état est décrit dans le fichier yaml, et normalement Ansible ne procède à une modification que si celle-ci est nécessaire.
Pour cela il s’appuie sur des modules qui sont capables pour telle ou telle fonctionnalité de savoir si la configuration est déjà en place ou si elle doit être modifiée. Le module command lui ne fait que lancer des instructions, par défaut ces dernières seront toujours exécutées et Ansible considéra qu’il a modifié quelque chose… Même si ce quelque chose était déjà configuré correctement.
Par exemple ici, à chaque relance du playbook, Ansible considèrera qu’il doit désactiver la swap. Ce n’est pas gênant dans ce cas, car retaper la commande même si la swap est déjà non utilisé ne provoque pas d’erreur, mais ce n’est pas toujours possible…de plus la sortie de Ansible sera trompeuse, car laissera penser que des modifications auront été faites.
Pour éviter cela on peut ajouter des conditions d’exécution pour le module command ou utiliser un script, en interrogeant par exemple d’abord le statut de quelque chose, et fonction de la valeur retournée alors la commande sera lancée ou non. Je n’ai pas été jusque-là dans mon usage, mais sachez que ça reste une bonne pratique de faire ainsi lorsqu’on n’a pas à disposition un module permettant de traiter notre besoin.
En l’occurrence, il existe un module pour gérer la swap et qui permet de ne pas passer par une simple commande, mais ce module n’est pas compatible avec PhotonOS.
Ensuite, on installe les packages de base. Dans ce cas, et grâce au tag présent sur les VMs, il est possible de faire la distinction entre le périmètre des serveurs. Ainsi certains packages ne sont déployés que sur les control plane, d’autre que sur les worker et d’autres sur uniquement sur les loadbalancer. Vous retrouvez la liste de ces packages dans le fichier de variable main.yaml du répertoire defaults.
À noter que le package « linux », correspondant au kernel de base dans PhotonOS, est installé sur tous les nodes. Cela supprimera l’usage du kernel optimisé pour ESXi si il était sélectionné à l'installation (voir cet article). C’est nécessaire au bon fonctionnement de Cilium (la couche réseau choisie).
Pour chaque package, cela reviendrait à passer sur chaque serveur et taper tdnf install nom_package.
On supprime aussi les packages inutiles.
On installe ensuite les binaires tiers nécessaires. En l’occurrence, seulement helm. Helm est un gestionnaire de package pour Kubernetes, il permet de simplifier le déploiement de certaines applications. En lieu est place de devoir manipuler tous les objets nécessaires, avec un ou plusieurs fichiers yaml, Helm permet d’installer un logiciel à l’image d’un simple package d’OS via la commande helm install. Nous aurons à l’utiliser plus tard. Il suffit de récupérer la version Linux sur le site de l’éditeur et de le placer dans le dossier files de l’arborescence du role Ansible pour qu’il puisse être utilisé par la suite.
Enfin, on reboot les serveurs pour s’assurer que tous les prérequis soient chargés pour la suite.
03-iptables.yml
Vient le tour de l’ouverture des flux réseau. En effet, les nœuds du cluster auront des besoins de dialoguer entre eux et également pour certains d’être accessible de l’extérieur sur certains ports, comme les control plane par exemple, qui devront exposer l’API K8S.
Tout cela se fait très facilement grâce au module iptables de Ansible.
---
#Ouverture du post SSH
- name: Open SSH port
become: yes
iptables:
chain: INPUT
destination_port: 22
protocol: tcp
jump: ACCEPT
tags: role_k8s_deploy.iptables_ssh
#Usage du mode nft de iptable
- name: iptables get binary
become: yes
#command: update-alternatives --set iptables /usr/sbin/iptables-legacy
command: update-alternatives --set iptables /usr/sbin/iptables-nft
register: iptables_alternatives
#Autoriser ICMP
- name: Autorise ICMP
become: yes
iptables:
chain: INPUT
protocol: icmp
jump: ACCEPT
tags: role_k8s_deploy.iptables_ping
#Ouverture du port de l'agent Kubelet
- name: Open iptable port for kubelet port
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_kubelet_port }}"
protocol: tcp
jump: ACCEPT
tags: role_k8s_deploy.iptables_kubelet
#Ouverture du port UDP pour l'usage de VXLAN par Cilium
- name: Open iptable UDP vxlan port for cilium
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_cilium_udp_vxlan_port }}"
protocol: udp
jump: ACCEPT
tags: role_k8s_deploy.iptables_cilium_vxlan-udp
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Ouverture du port TCP pour les health check réalisés par Cilium
- name: Open iptable TCP health port for cilium
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_cilium_tcp_healt_port }}"
protocol: tcp
jump: ACCEPT
tags: role_k8s_deploy.iptables_cilium_health-tcp
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Ouverture du port TCP suplementaire pour Cilium
- name: Open iptable TCP obser port for cilium
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_cilium_tcp_obser_port }}"
protocol: tcp
jump: ACCEPT
tags: role_k8s_deploy.iptables_cilium_obser-tcp
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Ouverture du port TCP suplementaire pour Cilium
- name: Open iptable TCP obser port for cilium
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_cilium_tcp_relay_port }}"
protocol: tcp
jump: ACCEPT
tags: role_k8s_deploy.iptables_cilium_obser-tcp
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Ouverture du port TCP suplementaire pour Cilium
- name: Open iptable TCP hubble-peer port for cilium
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_cilium_tcp_hubblepeer_port }}"
protocol: tcp
jump: ACCEPT
tags: role_k8s_deploy.iptables_hubblepeer-tcp
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Ouverture du port TCP de l' API Serveur pour les control plane
- name: Open iptable kub API port
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_kube_api_port }}"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-HAPROXY' in tags"
tags: role_k8s_deploy.iptables_kube-api-port
#Ouverture du port etcd pour les control plane
- name: Open iptable etcd API port
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_etcd_port }}"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-MASTER' in tags"
tags: role_k8s_deploy.iptables_kube-api-port
#Ouverture du port etcd pour les control plane
- name: Open iptable etcd API port member
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_etcd_member_port }}"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-MASTER' in tags"
tags: role_k8s_deploy.iptables_kube-api-port
#Ouverture du port 80 pour les control planee et les nlb
- name: Open iptable 80
become: yes
iptables:
chain: INPUT
destination_port: "80"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-HAPROXY' in tags"
tags: role_k8s_deploy.iptables.http
#Ouverture du port 443 pour les control plane et les nlb
- name: Open iptable 443
become: yes
iptables:
chain: INPUT
destination_port: "443"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-HAPROXY' in tags"
tags: role_k8s_deploy.iptables.https
#Ouverture du port 443 pour les worker en dmz
- name: Open iptable 443
become: yes
iptables:
chain: INPUT
destination_port: "443"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-WORKER' in tags and 'TAG-COOLCORP-NETWORK-WEB' in tags"
tags: role_k8s_deploy.iptables.dmz-https
#Ouverture du port 80 pour les worker en dmz
- name: Open iptable 80
become: yes
iptables:
chain: INPUT
destination_port: "80"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-WORKER' in tags and 'TAG-COOLCORP-NETWORK-WEB' in tags"
tags: role_k8s_deploy.iptables.dmz-http
#ouverture des ports de service node
- name: Open node service port
become: yes
iptables:
chain: INPUT
destination_port: "{{ var_node_service_port }}"
protocol: tcp
jump: ACCEPT
when: "'TAG-COOLCORP-ROLE-WORKER' in tags"
tags: role_k8s_deploy.iptables_nodeservice
#Sauvegarde de la conf iptable
- name: save iptables
become: yes
shell: iptables-save > /etc/systemd/scripts/ip4save
register: iptables_alternatives
tags: role_k8s_deploy.iptables.backup
#reboot
- name: Unconditionally reboot the machine with all defaults
become: yes
reboot:
tags: role_k8s_deploy.prerequis.reboot
Pour chaque flux, il suffit de préciser le protocole, la chaine d’application (INPUT/OUTPUT/FORWARD) et l’action attendue.
La tache de fin consiste à sauvegarder la configuration de iptables pour s'assurer qu'elle soit remise en oeuvre à chaque reboot des serveurs. La aussi c'est le module shell qui est utilisé, et comme pour le module command, on pourrait proposer mieux en terme de rejouabilité du playbook.
A noter également l'usage du module command pour lancer l'exécution de update-alternatives --set iptables /usr/sbin/iptables-nft.
nft pour Netfilter Tables est un autre moteur de filtrage et de manipulation des paquets du noyau linux, plus moderne et flexible que le moteur traditionnel iptables.
Ce point est important car il est en lien avec le driver réseau retenu pour Kubernetes (ici Cilium). Il se peut que fonction de la version du driver et du type, il faille basculer d'un mode à un autre.
Voici un résumé des flux à ouvrir:
| Flux | Source | Destination | Port | Rôle |
|---|---|---|---|---|
| SSH | any | Tous les serveurs | TCP 22 | Accès SSH |
| ICMP | any | any | ICMP | Autoriser le ping |
| Kubelet | Tous les serveurs | Tous les serveurs | TCP 10250 | Communication sur les agents Kubelet |
| VXLAN | Tous les serveurs | Tous les serveurs | UDP 8472 | Protocole de communication réseau pour Cilium |
| CILIUM HEALT | Tous les serveurs | Tous les serveurs | TCP 4240 | Nécessaire pour Cilium |
| CILIUM OBSER | Tous les serveurs | Tous les serveurs | TCP 4222 | Nécessaire pour Cilium |
| API | any | Serveurs control plane Serveurs Load Balancing |
TCP 6443 | Accès à l’API KUB |
| ETCD | Serveurs control plane | Serveurs control plane | TCP 2379 | Réplication ETCD |
| ETCD | Serveurs control plane | Serveurs control plane | TCP 2380 | Réplication ETCD |
| NODE PORT | any | Tous les serveurs | TCP 30000 :32767 | Ports pour les services de type Node ports |
| TRAEFIK | any | Tous les serveurs destinés à recevoir une instance traefik Serveur Load Balancing |
TCP 80 TCP 443 |
Exposition des applications |
Tous ces ports sont définis dans le fichier de variable. À noter que cette matrice est à adapter fonction de vos besoins et de vos contraintes.
L’une des bonnes pratiques par exemple est de limiter les accès à l’API. Cette dernière est sensible puisqu’elle permet le pilotage du cluster, elle ne devrait être donc exposée qu’aux composants nécessaires (déploiement et monitoring).
Même chose pour les accès SSH, ici je ne filtre pas d'avantage, mais sur une production il est bien sure certains que l'accès a la couche OS doit etre extremement controlée, en privilegiant l'usage de bastion par exemple.
Vous pouvez aussi vous reposer sur d’autres composants de sécurité pour filtrer les flux en dehors de l’OS. Dans tous les cas il est très important de bien poser votre matrice en amont du projet et de vous restreindre à ouvrir uniquement ce qui est nécessaire.
Dans l’architecture déployée, il y’a des nodes en DMZ, ces derniers doivent communiquer à minima avec les control plane, et fonction des « add on » utilisés pourront nécessiter des ouvertures de flux supplémentaires comme c’est le cas ici avec l’usage de Cilium.
Nous aurons l’occasion d’en reparler, mais les kubelet sont les agents K8S présent sur chaque nœud dont le rôle est de démarrer les conteneurs de bases du cluster et de remonter le statut de l’hôte. Il est important que ces agents puissent dialoguer entre eux, surtout des nodes vers les control plane.
Cliquez sur l'image pour l'agrandir.
04-containerd.yml
J’ai déjà au l’occasion d’en parler lors de la présentation de l’architecture Kubernetes à déployer, mais pour fonctionner K8S a besoin d’un runtime de conteneur au standard OCI (Open Container Initiative) et compatible avec CRI (Container Runtime Interface).
En l’occurrence c’est containerd qui sera choisi ici. Même s’il est présent par défaut dans photonOS, il est préféré dans cet exemple de récupérer directement les binaires sur le site officiel. Il y’a une très forte dépendance entre la version de Kubernetes et la version de containerd. Il est capital de respecter la matrice de compatibilité . Comme Kubernete est ici déployé en version vanilla et donc indépendante du repo par défaut de l’OS, il est préférable de faire de même avec containerd, cela pour ne jamais se retrouver bloquer sur un conflit de version.
---
#Récupération des binaire containerd et décompression de ces dernier dans /usr
- name: Download and extract containerd
become: yes
ansible.builtin.unarchive:
src: "{{ var_containerd_binary }}"
dest: /usr
remote_src: yes
tags: role_k8s_deploy.containerd.containerd
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Création du fichier de service pour gérer le démarrage et l'arret de containerd : utilisation du template containerd.service.j2
- name: "Configure containerd service"
become: yes
template:
src: containerd.service.j2
dest: "/usr/lib/systemd/system/containerd.service"
register: containerd_service_file
tags: role_k8s_deploy.containerd.contrainerd-service
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#forcer le refresh de la config systemd pour prendre en compte le fichier de service créé précedemment
- name: container reread config
become: yes
ansible.builtin.systemd:
daemon_reexec: yes
when: containerd_service_file is changed
#Activer et démarrer le service containerd
- name: enable containerd service
become: yes
systemd:
name: containerd
state: started
enabled: True
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Ajouter le module br_netfilter au chargement de containerd
- name: "configure br_netfilter module"
become: yes
template:
src: containerd.conf.j2
dest: "/etc/modules-load.d/containerd.conf"
tags: role_k8s_deploy.containerd.conf-br_netfilter
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#S'assurer que le module br_netfiler soit chargé
- name: Add the br_netfilter module
become: yes
community.general.modprobe:
name: br_netfilter
state: present
tags: role_k8s_deploy.containerd.add-br_netfilter
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Tweak du kernel pour les besoins K8S
- name: "configure sysctl"
become: yes
template:
src: 99-kubernetes-cri.conf.j2
dest: "/etc/sysctl.d/99-kubernetes-cri.conf"
register: sysctl_file
tags: role_k8s_deploy.containerd.sysctl
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Forcer le rechargement de la conf associé au kernel
- name: read sysctlconf
become: yes
shell: sysctl --system
when: sysctl_file is changed
tags: role_k8s_deploy.containerd.read-sysctl
#Generer la conf par default de containerd
- name: "configure containerd"
become: yes
ansible.builtin.shell:
cmd: containerd config default > /etc/containerd/config.toml
register: containerd_config_file
tags: srv_k8s.containerd.conf-containerd-config
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
#Activer le support des crgroup dans la config containerd
- name: "Activate cgroup"
become: yes
replace:
path: /etc/containerd/config.toml
regexp: 'SystemdCgroup\s*=\s*false'
replace: 'SystemdCgroup = true'
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
tags: srv_k8s.containerd.conf-containerd-config
#Redemarrer containerd
- name: enable containerd service
become: yes
systemd:
name: containerd
state: restarted
when: containerd_config_file is changed
#Activer les agents kubelet
- name: enable kubelet service
become: yes
systemd:
name: kubelet
state: started
enabled: True
when: "'TAG-COOLCORP-ROLE-MASTER' in tags or 'TAG-COOLCORP-ROLE-WORKER' in tags"
Le fichier de service va être généré à partir du template containerd.service.j2 présent dans le dossier templates afin que systemctl puisse lancer containerd.
Voici le contenu du template:
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target
[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/bin/containerd
Restart=always
RestartSec=5
KillMode=process
Delegate=yes
OOMScoreAdjust=-999
LimitNOFILE=1048576
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
[Install]
WantedBy=multi-user.target
Ce n’est pas suffisant en soi, car d’autres paramètres sont nécessaires, comme l’activation de certains modules du kernel, notamment br_netfilter.
Un fichier de conf spécifique containerd.conf créé à partir du template containerd.conf.j2 du dossier templates est généré et placé dans /etc/modules-load.d/
Le contenu est très basique puisqu'il y'a juste ceci:
br_netfilter
Les attribues du kernel doivent être modifié également. Habituellement on utilise l’outil sysctl, mais on va exploiter un template 99-kubernetes-cri.conf.j2 définissant les valeurs souhaitées. Le fichier généré 99-kubernetes-cri.conf est ensuite lu par sysctl (ici c’est le module Ansible shell qui est utilisé…même remarque que pour le module command).
Le contenu du fichier 99-kubernetes-cri.conf placé dans /etc/sysctl.d/ est très simple et n'a pour role que d'activer les fonctions de routage du kernel.
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net/bridge/bridge-nf-call-arptables = 1
La configuration de containerd doit également être dans un premier temps générée avec la conf par défaut via la commande containerd config default > /etc/containerd/config.toml puis complétée avec l’activation de l’usage des cgroups.
Les cgroups pour control groups est une fonctionnalité du kernel Linux qui permet de limiter, d’isoler et de surveiller l’utilisation de ressources (CPU, mémoire, disque, réseau) par des processus. C’est une fonction clef pour la conteneurisation, notamment pour Kubernetes, qui va à travers containerd, gérer l’attribution des ressources aux différents conteneurs exécutés sur le cluster.
Le module replace utilisé par ansible, va s'assurer que la valeur SystemdCgroup soit égale à true dans le fichier de configuration /etc/containerd/config.toml généré précedemment.
Une fois fini, il est possible de démarrer containerd, mais également les fameux agents kubelet. Même si le cluster n’est pas encore déployé, les agents sont déjà en place.
Conclusion
Tous les nodes sont maintenant prêts et disposent de tous les prérequis pour se voir intégrer dans un cluster Kubernetes.
Mais avant cela il sera nécessaire de poursuivre le playbook Ansible avec les taches de préparation des fichiers de configuration du cluster, notamment kubeadm. Ce point sera traité ultérieurement.
L’article n’a pas vocation à être un tutoriel détaillé de Ansible mais j’espère qu’il donne un bon aperçu de l’usage de ce dernier pour s’assurer d’avoir tous les composants nécessaires aux déploiements d’un cluster K8S, tout en conservant une agilité sur le choix des versions et des composants à installer.
À noter que les fichiers décrits sont améliorables et optimisables, l’usage d’ Ansible s’inscrit dans une amélioration continue et il est toujours possible de retravailler ses playbooks.
Pour poursuivre le cookbook avec l'étape suivante c'est par ici