Étape 7 : Mise en place du stockage persistant (CPI/CSI)
Introduction
Maintenant que le cluster est opérationnel, il va être nécessaire de lui adjoindre des addons pour lui permettre d’assurer un certain nombre de fonctionnalités.
Parmi les besoins souvent exprimés autour de l’usage des conteneurs, on retrouve le support du stockage persistant. En effet, le conteneur a été pensé au départ pour fonctionner avec des données éphémères, s’inscrivant dans une logique micro service ou l’important est la légèreté, l’instantanéité et la multiplicité.
Mais, avec l’adoption de plus en plus forte de la conteneurisation, on n’en arrive depuis longtemps maintenant à la bascule d’application lourde impliquant souvent un besoin de persistance de la donnée.
Dans ce contexte l’arrêt et le redémarrage d’un conteneur doivent s’accompagner de la data associée.
On peut se reposer sur le partage de fichiers via des protocoles comme NFS (Network File System) ou du SMB (Server Message Block), mais ce type d’accès n’est pas toujours adaptés, notamment dans des besoins de hautes performances ou de compatibilités.
Parfois l’applicatif conteneurisé demande un accès « bloc », comme s’il s’agissait directement d’un disque mappé avec un filesystem classique.
Principe du stockage persistent sous K8S
Pour traiter des problématiques de stockage, Kubernetes propose un objet dédié appelé : PersistentVolume (pv). Manipulable directement ou précédé d’un autre objet nommé PersistanteVolumeClaim (pvc), il permet d’associer à un conteneur un espace de données capable de suivre la vie du pod auquel il est rattaché.
Si l’objet est supporté nativement, son interaction avec des systèmes de stockage tiers est dépendant du driver déployé au sein du cluster.
Pour simplifier les choses, Kubernetes propose un standard le CSI pour Container Storage Interface.
Dans les grandes lignes, le CSI permet à des acteurs extérieurs de proposer un addon autorisant un cluster Kubernetes à manipuler un système de storage pour y créér des pv.
Pour un provisionnement automatique des pv, un CSI va pouvoir également être utilisé avec troisieme objet Kubernetes appelé StorageClass (sc).
Une sc représente une « classe » de stockage soit un espace disponible pour héberger des volumes.
Une ou plusieurs classes peuvent être déclarées au sein d’un même cluster et peuvent faire appel à différents addons CSI.
On peut ainsi couvrir des besoins spécifiques, fonction des capacités proposées par les solutions associées aux drivers CSI : performance, redondances, filesystem supportés…
N’hésitez pas à parcourir cet article ou d’autres explications sont disponibles pour le CSI.
Une fois une sc disponible, on va pouvoir créer des PersistantVolumeClaim (pvc), soit des objets décrivant un besoin de stockage, à savoir:
- Une volumétrie
- Un type d’accès : lecture seule, lecture depuis de multiples sources, mais écriture accessible uniquement depuis une seule source, lecture/écriture dédiée…
Les besoins du pvc doivent correspondre aux fonctionnalités prises en charge par la sc.
Si telle est le cas, on pourra disposer d’un pv déployé automatiquement par l’appel au pvc qui lui-même pourra provisionner le besoin exprimé dans la sc.
On peut également se passer de sc et déclarer directement un pv en y déclarant les caractéristiques souhaitées.
Le volume n’est alors pas provisionné automatiquement. Même dans ce cas, le pvc peut être utilisé, et cherchera alors à trouver un pv déjà déclaré compatible avec la demande. Si un pv peut être appelé et manipulé directement, il est dans les bonnes pratiques de toujours passer par un pvc.
Cette logique permet de différentier de Comment est provisionné le volume, de Comment est consommé le volume.
Le premier cas est plutôt à charge des administrateurs, le second à charge des développeurs.
Lorsque le déploiement de l’application est écrit par le développeur, celui-ci n’a pas à se soucier de comment sera provisionné son besoin de stockage, il se contentera d’exprimer un besoin (volumétrie/type d’accès) à travers un pvc et l’attribution du volume finale (pv) sera géré automatiquement au sein du cluster fonction des classes de stockage disponible ou des volumes déjà déclarés par les administrateurs.
Voici une tentative de schématiser un peu tout ça:
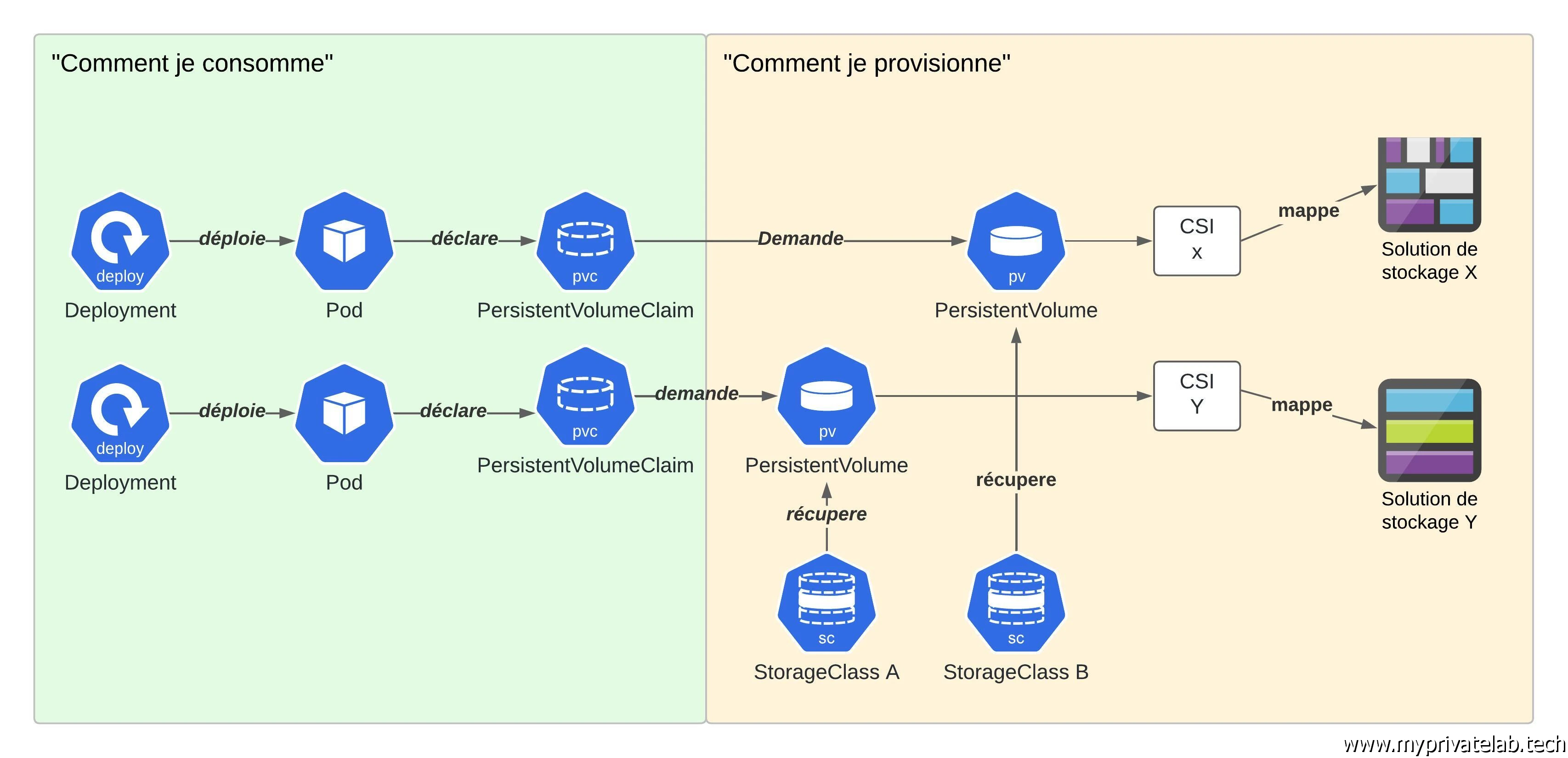
Cliquez sur l'image pour l'agrandir.
Mise en place
Dans notre situation, on va exploiter le driver CSI Vsphere permettant l’usage de datastores déclarés sur un cluster d'ESXi comme source de stockage persistent.
On va pour l’instant se connecter au premier control plane avec son utilisateur courant (ici bvivi57).
La première chose à faire est de vérifier la statue de l’ensemble des nodes via la commande:
kubectl get node
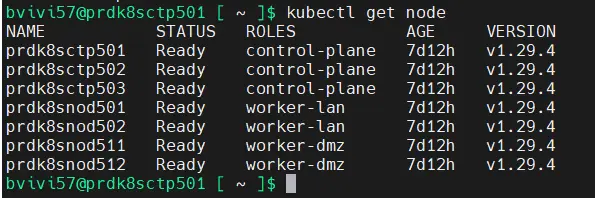
Cliquez sur l'image pour l'agrandir.
Puis on vérifie que les composants système sont tous opérationnels avec la commande:
kubectl get pod -n kube-system
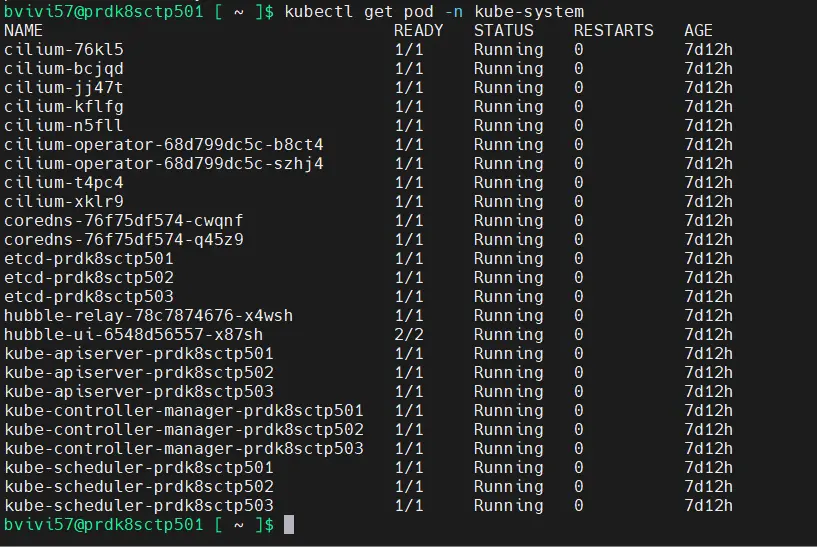
Cliquez sur l'image pour l'agrandir.
Si tout est OK, alors on peut démarrer l’installation du CSI.
Pour rappel tous les fichiers de configuration ont été préparés via le playbook Ansible.
Tout a été placé dans le dossier cloud de l’utilisateur courant.
CPI
Avant de déployer le CSI en tant que tel, il faut déployer le CPI pour Cloud Provider Interface. C’est un prérequis au CSI vSphere, car le vCenter auquel le cluster va se connecter pour opérer les volumes est vu comme un fournisseur de cloud.
Le CPI est associé au fichier vsphere-cloud-controller-manager.yaml qui se trouve dans ~/kub.coolcorp.priv/cloud/cpi sur le premier control plane.

Cliquez sur l'image pour l'agrandir.
Sa copie et sa customisation ont été réalisées par le playbook Ansible. Très peu d’information a été ajoutée.
On lui indique juste les données de connexion au vCenter ainsi que les éléments associés au cluster vSphere sur lequel s’exécute les nodes K8S. Tout le détail associé aux variables utilisées dans ce fichier est disponible dans l’article Ansible dédié.
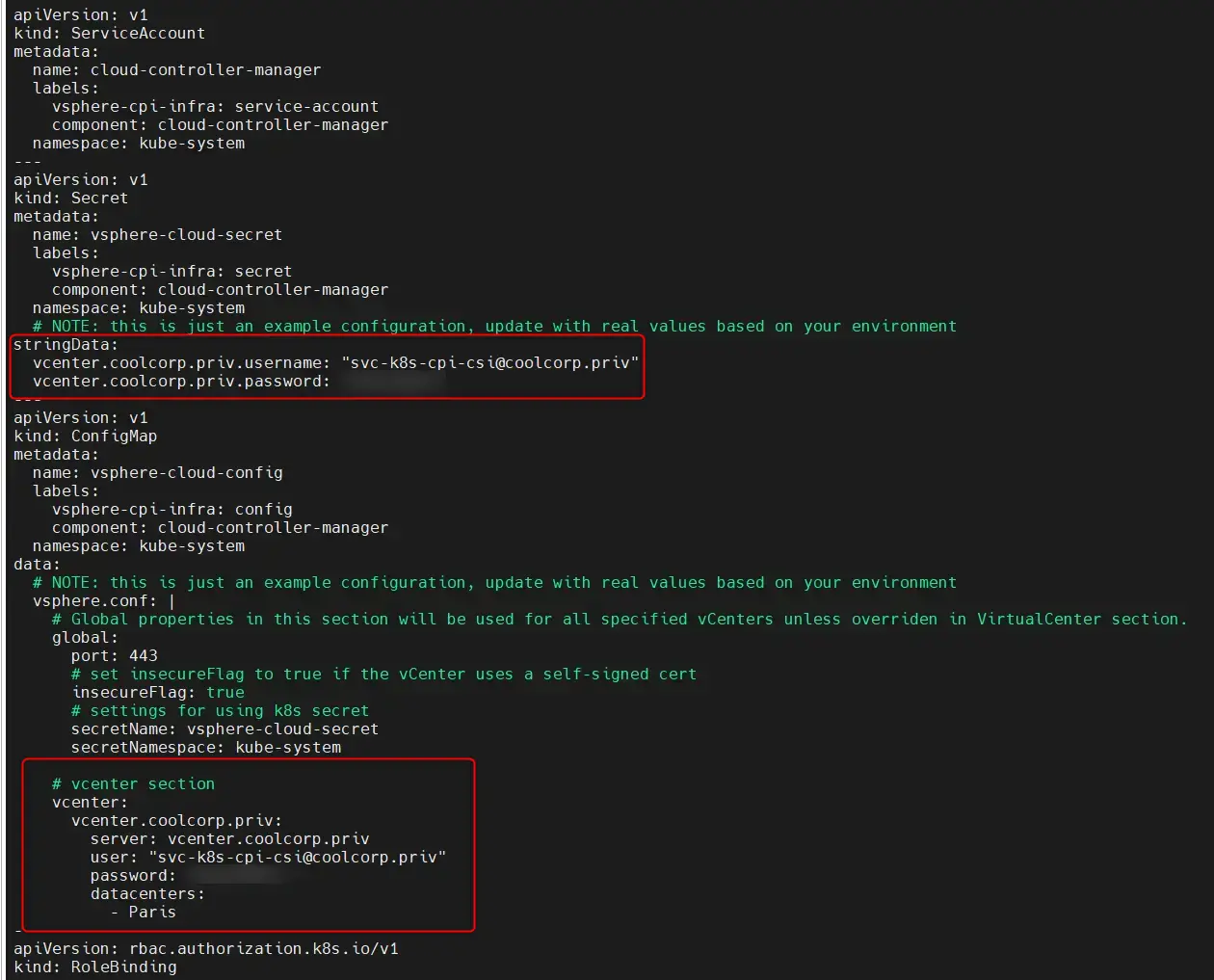
Cliquez sur l'image pour l'agrandir.
Pour ceux qui sont sensibles à la cybersécurité, ils constateront que le fichier dispose du compte de service dédié créé spécifiquement pour l’occasion, incluant login et password. C’est effectivement un fichier qui ne faudra pas conserver et ne pas hésitez à supprimer une fois l’installation réalisée.
Il suffit de taper la commande suivante pour déployer le CPI:
kubectl apply -f vsphere-cloud-controller-manager.yaml

Cliquez sur l'image pour l'agrandir.
On peut ensuite vérifier son statut via la commande:
kubectl get pod -n kube-system -o wide
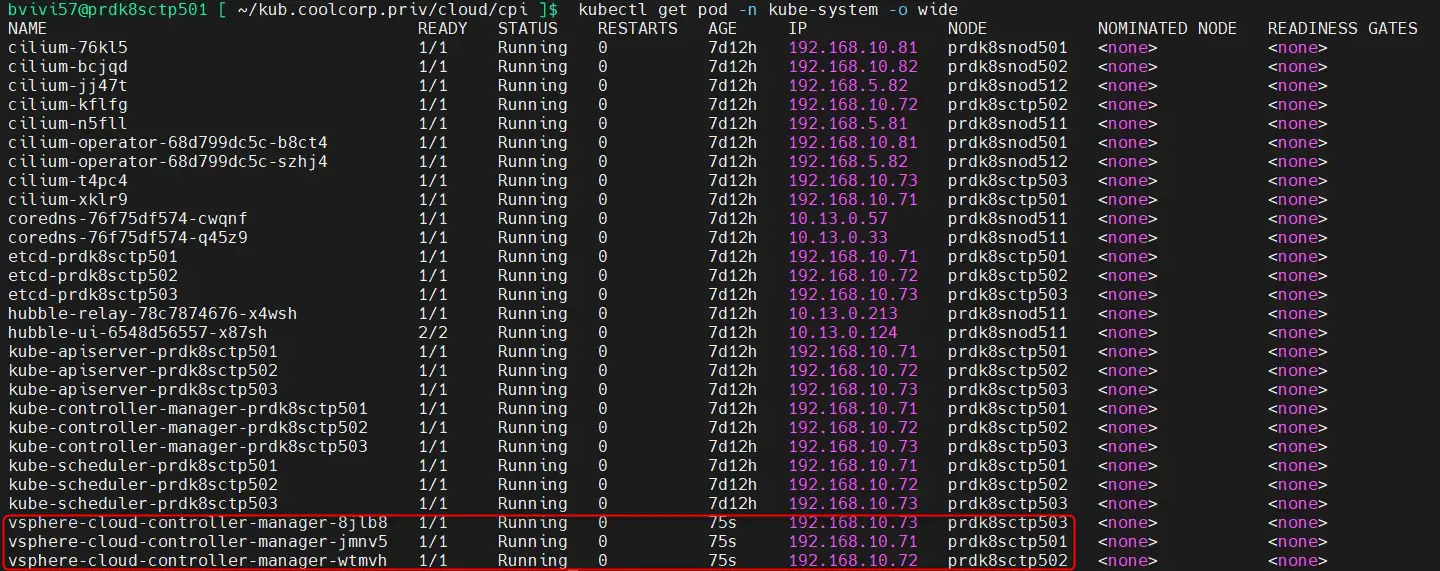
Cliquez sur l'image pour l'agrandir.
CSI
On peut maintenant basculer sur l’installation du CSI.
De la même manière que pour le CPI, la préparation des fichiers a été réalisée par Ansible et tout le nécessaire de trouve dans ~/kub.coolcorp.priv/cloud/csi sur le premier control plane.

Cliquez sur l'image pour l'agrandir.
Contrairement au CPI qui se déploie dans le namespace kube-system, le CSI nécessite un namespace dédié.
On va donc commencer par la création de ce dernier avec la commande:
kubectl apply -f namespace.yaml

Cliquez sur l'image pour l'agrandir.
Le contenu du yaml appelé est très basique et permet de décrire le namespace vmware-system-csi.
apiVersion: v1
kind: Namespace
metadata:
name: vmware-system-csi
Une fois cette partie faite, comme pour le CPI, le CSI nécessite des accès au vCenter.
On utilise le même compte de service (voir article ici), mais cette fois-ci on va d’abord générer un objet secret pour y stocker nos identifiants ainsi que les informations propres au cluster VMware que l'on souhaite utiliser.
Le secret doit s’appeler vsphere-config-secret et prend les valeurs positionnées dans le fichier csi-vsphere.conf dont le contenu est le suivant:
[Global]
cluster-id = "kub"
[VirtualCenter "prdvmwvce501.coolcorp.priv"]
insecure-flag = "true"
user = "[email protected]"
password = "monpassword"
port = "443"
datacenters = "Paris"
Il suffit d’utiliser la commande suivante pour créer le dossier:
kubectl create secret generic vsphere-config-secret --from-file=csi-vsphere.conf --namespace=vmware-system-csi

Cliquez sur l'image pour l'agrandir.
On appelle ensuite le yaml vsphere-csi-driver.yaml récupéré chez VMware (voir l'article) via la commande:
kubectl apply -f vsphere-csi-driver.yaml
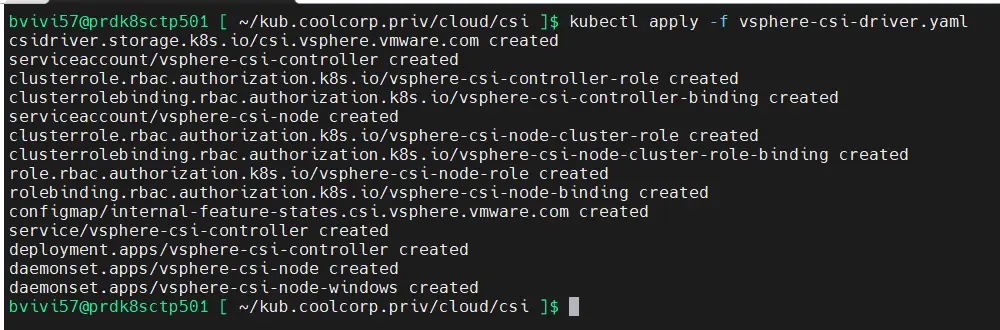
Cliquez sur l'image pour l'agrandir.
On peut vérifier le bon déploiement via la commande:
kubectl get pod -n vmware-system-csi -o wide
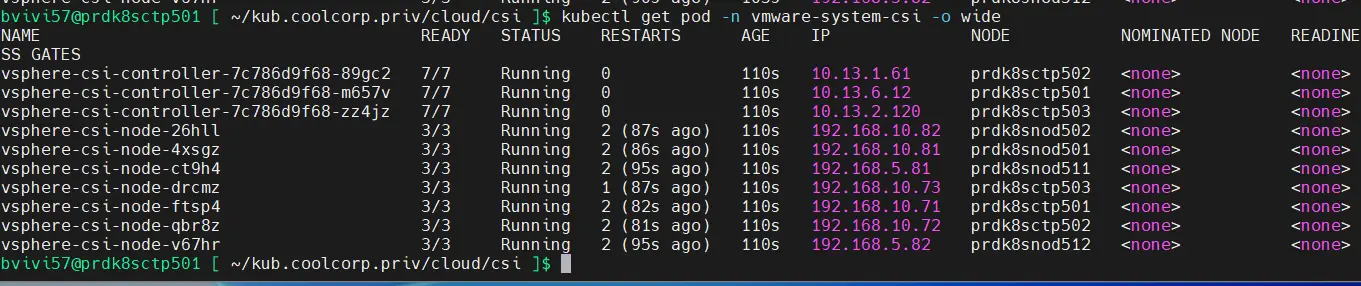
Cliquez sur l'image pour l'agrandir.
Si tous les voyants sont au vert, alors on peut considérer le déploiement du CSI comme terminé.
Tests
Pour vérifier le bon fonctionnement de l’ensemble, on va réaliser quelques tests.
La première chose va être la création d’un namespace dédié pour déployer une application d’essai utilisant un volume persistant.
Le namespace peut se créer directement sans passer par un yaml (comme tout objet k8s).
kubectl create ns dev-demopvdatastore-lan
J’ai pris ensuite l’habitude de toujours créer un dossier de travail du nom du namespace.

Cliquez sur l'image pour l'agrandir.
Une fois à l’intérieur de ce dernier je crée mes fichiers yaml.
Comme expliqué en introduction, j’utilise une StorageClass.
Pour cela, on repère d’abord sur le vCenter l’identifiant du datastore qui va servir à héberger le volumes.
De mon côté, j’ai un datastore dédié nommé prddtsnfs001. J’ai besoin de récupérer sa location, puisque c’est cette valeur que je vais déclarer dans la sc.
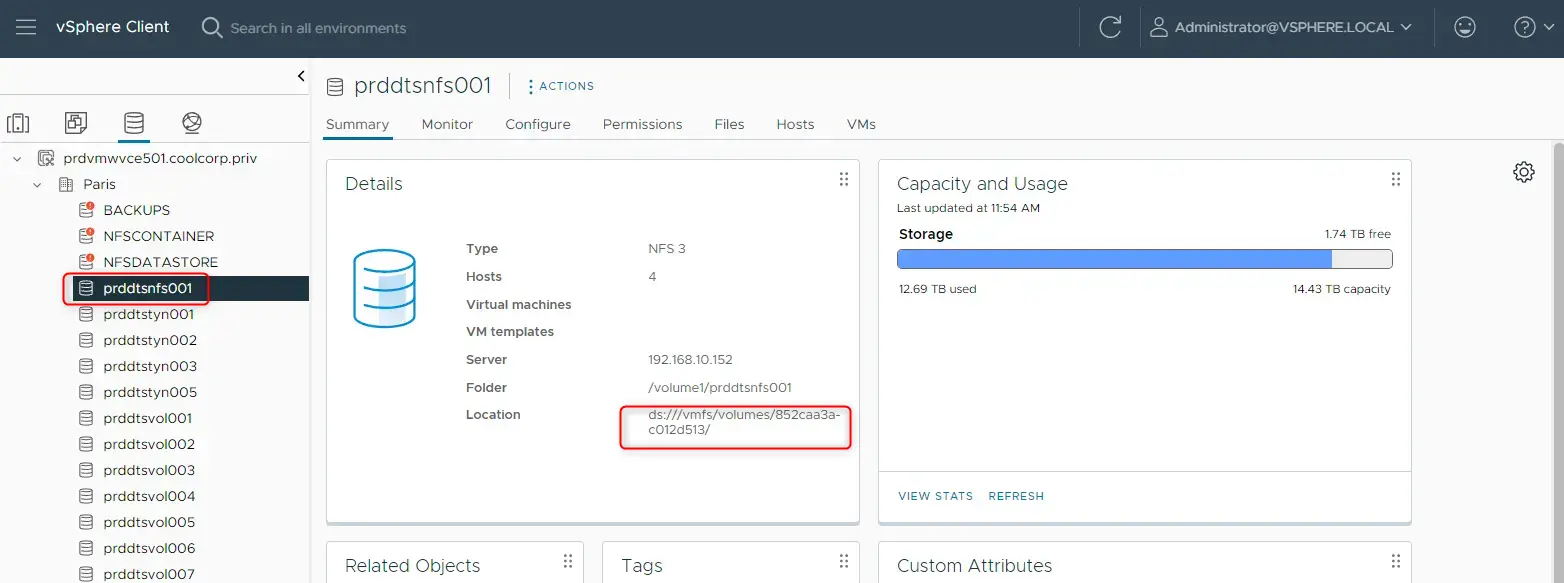
Cliquez sur l'image pour l'agrandir.
Ma sc de test est décrit dans le fichier 01-sc-datastore.yaml:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: sc-prddtsnfs001
parameters:
datastoreurl: ds:///vmfs/volumes/852caa3a-c012d513/
allowVolumeExpansion: true
provisioner: csi.vsphere.vmware.com
reclaimPolicy: Retain
volumeBindingMode: Immediate
Le fichier n’est pas compliqué à comprendre. On y’ retrouve les classiques champs apiVersion, Kind, metadata commun à chaque objet K8S.
On n’appelle l’objet StorageClass de la branche api storage.k8s.io/v1 qu’on va nommer sc-prddtsnfs001.
En termes de paramètres, on fixe la location VMware du datastore récupéré précédemment.
En option supplémentaire, on autorise les extensions de volume si nécessaire via allowVolumeExpansion: true.
Très important on indique qu’on utilise le CSI vsphere pour provisionner des volumes issus de cette storage class via l’option provisionner: csi.vsphere.vmware.com.
Enfin, un élément intéressant est l’option reclaimPolicy: Retain. Celle-ci va définir la manière dont devra être traité un volume dès lors que son pvc et l’application qui y fait appel sont supprimés.
Dans cet exemple, Retain, indique que le volume sera conservé. L’alternative serait de choisir Delete. Dans ce cas, la donnée est effacée en même temps que l’application via la suppression du pv.
C’est un choix propre à chacun et à son besoin. L’avantage de choisir Retain et de pouvoir réaccéder à la donnée si nécessaire en remappant le volume.
L’inconvénient est que si vous n’avez pas une politique de nettoyage régulière, vous risquez d’empiler les PersistentVolume au fil du temps et de consommer de l’espace pour rien.
Bien entendu, même avec l’option Retain, vous pourrez par la suite supprimer un PersistentVolume manuellement.
À noter également que vous pouvez choisir une StorageClass par défaut, dans ce cas, si rien n’est précisé au niveau d’un PersistentVolumeClaim, c’est cette dernière qui sera retenue par le cluster.
kubectl apply -f 01-sc-datastore.yaml

Cliquez sur l'image pour l'agrandir.
On peut passer maintenance au pvc. Il est décrit dans le fichier 02-pvc-demopvdatastore.yaml dont le contenu est le suivant:
kind: "PersistentVolumeClaim"
apiVersion: "v1"
metadata:
name: pvc-demopvdatastore
namespace: dev-demopvdatastore-lan
labels:
environment: dev
network: lan
application: demopvdatastore
spec:
accessModes:
- "ReadWriteOnce"
resources:
requests:
storage: "5Gi"
storageClassName: sc-prddtsnfs001
On y trouve un champ Spec: dans lequel on va pouvoir indiquer pour cet objet de type PersistentVolumeClaim, l’espace souhaité 5Go et le type d’accès associé, ReadWriteOnce. On demande donc un volume accessible aussi bien en lecture qu’en écriture depuis un seul pod à la fois.
Le plus important étant la référence à la sc créée précédemment pour indiquer au pvc de provisionner dynamiquement le volume dans cette dernière.
kubectl apply -f 02-pvc-demopvdatastore.yaml
Cliquez sur l'image pour l'agrandir.
C’est maintenant au tour de l’application elle-même via le fichier 03-deploy-demopvdatastore.yaml d’être déployée.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-demopvdatastore
namespace: dev-demopvdatastore-lan
labels:
environment: dev
network: lan
application: demopvdatastore
spec:
strategy:
type: Recreate
selector:
matchLabels:
environment: dev
network: lan
application: demopvdatastore
template:
metadata:
labels:
environment: dev
network: lan
application: demopvdatastore
spec:
nodeSelector:
network: lan
containers:
- name: demo-nginx-with-datastore
image: nginx:1.27
resources:
requests:
memory: "8Mi"
cpu: "250m"
limits:
memory: "256Mi"
cpu: 1
livenessProbe:
initialDelaySeconds: 5
periodSeconds: 5
exec:
command:
- ls /usr/share/nginx/html
ports:
- containerPort: 80
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: nginx-data
volumes:
- name: nginx-data
persistentVolumeClaim:
claimName: pvc-demopvdatastore
Je ne vais pas rentrer dans le détail du principe de l’objet Deployment qui lui-même gère le ou les pods , mais l’idée de ce fichier est de provoquer l’exécution d’un conteneur basé sur l’image nginx 1.27 et d’y mapper un volume dans le point de montage interne au conteneur /usr/share/nginx/html.
En fin de fichier, on note l’appel au pvc pvc-demopvdatastore qui va permettre de générer le volume nginx-data qui lui-même sera monté dans /usr/share/nginx/html.
Le déploiement se fait via la commande:
kubectl apply -f 03-deploy-demopvdatastore.yaml
On pourra noter que pendant le lancement du pvc et de l’application, de l’activité est vue côté vCenter. Ce qui est normal, puisque le cluster K8S est capable de dialoguer avec l’infrastructure VMware pour demander la création de volume dans le datastore rattaché à la storageclass utilisée (grâce à la combinaison CPI/CSI).

Cliquez sur l'image pour l'agrandir.
Vérifions que l’application est exécutée:
kubectl get pod -n dev-demopvdatastore-lan -o wide

Cliquez sur l'image pour l'agrandir.
Descendons plus dans le détail pour voir l’état du pvc via la commande:
kubectl get pvc -n dev-demopvdatastore-lan

Cliquez sur l'image pour l'agrandir.
Celui-ci est bien indiqué comme bound soit mappé à un volume.
On peut d’ailleurs lister les volumes via la commande:
kubectl get pv

Cliquez sur l'image pour l'agrandir.
Les plus attentifs observeront que je n’ai pas précisé le namespace pour cette commande. En effet les PersistentVolume sont des objets transverses au cluster, qui n’appartiennent pas à un namespace spécifique contrairement au PersistentVolumeClaim (pvc).
Essayons de réellement voir si le volume est utilisé par l’application.
Pour cela on va rentrer dans le contexte du conteneur via la commande:
kubectl exec -it deploy-demopvdatastore-5cb5fd6db7-mt54m bash -n dev-demopvdatastore-lan
deploy-demopvdatastore-5cb5fd6db7-mt54m est le nom du pod dans lequel s’exécute le conteneur, son nom est généré dynamiquement et va donc changer à chaque redémarrage du pod.
Une fois dans le contexte du conteneur, on peut taper la commande df -h.
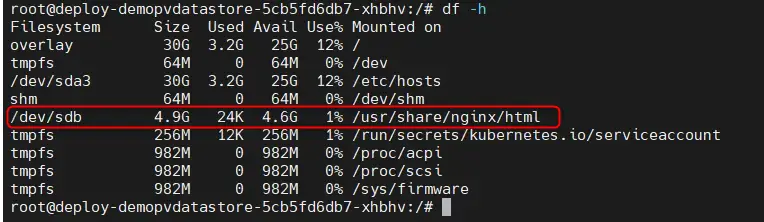
Cliquez sur l'image pour l'agrandir.
Celle-ci nous montre bien qu’on dispose d’un périphérique /dev/sdb de 5G utilisé pour /usr/share/nginx/html.
C’est ni plus ni moins que notre persistent volume K8S qui est vu au sein du conteneur comme un disque monté dans l’OS.
Ce volume est en faite un VMDK (disque au format vmware) mappé dynamiquement au worker qui exécute actuellement le pod soit prdk8snod501. On retrouve ce VMDK au niveau de la VM.
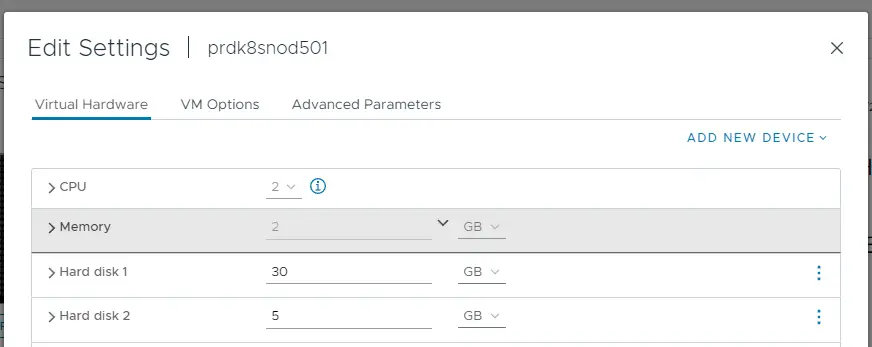
Cliquez sur l'image pour l'agrandir.
Tout ce mappage automatique est d’ailleurs visible au niveau des activités du vCenter.
Cliquez sur l'image pour l'agrandir.
Revenu dans le contexte du conteneur, on peut se déplacer dans le chemin /usr/share/nginx/html et créer un fichier testpv avec la commande touch testpv.

Cliquez sur l'image pour l'agrandir.
On sort ensuite du contexte du conteneur via CTRL+Z.
Pour poursuivre l’expérience, on va maintenant mettre en maintenance le node qui exécute le conteneur. Je ne rentre pas dans le détail, mais la commande suivante va permettre au cluster de déplacer tous les pods du nœud prdk8snod501 vers les autres nodes. C’est généralement ce que l’on fait quand on souhaite mettre à jour le serveur ou intervenir sur ce dernier.
kubectl drain --ignore-daemonsets --ignore-daemonsets --delete-emptydir-data prdk8snod501

Cliquez sur l'image pour l'agrandir.
Comme attendu, le pod va automatiquement être lancé sur un autre node éligible, en l’occurrence ici prdk8snod502.

Cliquez sur l'image pour l'agrandir.
Etant donné que le pod a redemarré son nom a changé, mais on peut toujours rentrer dans son contexte en mettant à jour notre commande précédente.
kubectl exec -it deploy-demopvdatastore-5cb5fd6db7-5kjms bash -n dev-demopvdatastore-lan
Si on cherche à accéder à /usr/share/nginx/html, on retrouve bien notre fichier créer précédemment.

Cliquez sur l'image pour l'agrandir.
Cette fois-ci le vmdk est rattaché au worker qui a pris le relais. Il a été détaché de prdk8snod501 puis remonté sur prdk8snod502, directement piloté par le cluster kubernetes. C’est grâce a la configuration du CPI/CSI et des accès au vCenter que l’opération peut être réalisée.
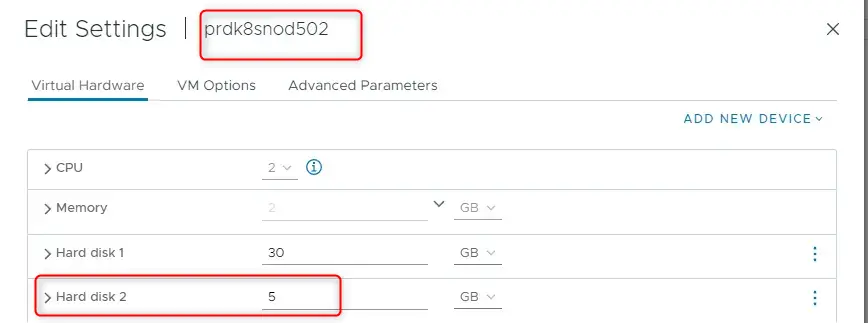
Cliquez sur l'image pour l'agrandir.
Pour terminer, on peut supprimer le déploiement donc le pod, donc l’application, ainsi que le pvc.
kubectl delete -f 03-deploy-demopvdatastore.yaml
kubectl delete -f 02-pvc-demopvdatastore.yaml

Cliquez sur l'image pour l'agrandir.
Néanmoins si on liste les volumes, via la commande kubectl get pv, le volume est toujours là, mais cette fois-ci dans un statut Released.
Ce qui est normal, puisque la sc dont il est issu est configurée pour obtenir des volumes avec une police de suppression fixée à Retain.
Si vraiment on veut libérer l’espace et détruire le volume, il faudra passer une commande explicite: kubectl delete pv nom_volume

Cliquez sur l'image pour l'agrandir.
Petite opération à terminer: ne pas oublier de sortir le premier node prdk8snod501 du mode maintenance avec la commande kubectl uncordon prdk8snod501

Cliquez sur l'image pour l'agrandir.
Là encore, je ne rentrerais pas dans le détail, un article dédié sera proposé pour la gestion des nodes d'un cluster K8S et leur maintenance.
Par contre, la remise online du premier node, n'implique pas le retour de l'application test sur ce dernier. Celle-ci ayant basculée sur le second node, il n'y aucune raison qu'elle soit redemarrée sur le premier node.
Conclusion
Nous voila arrivé au terme de cette partie dédiée au storage.
Je ne suis pas rentré dans le détail du déploiement des applications, cela viendra plus tard. L’objectif était ici de présenter la gestion du stockage persistent au sein d’un cluster Kubernetes.
J’ai choisi le cas le plus complet possible, incluant un driver CSI et une StorageClass (sc) pour un provisionnement dynamique des PersistentVolume (pv) via des PersistentVolumeClaim (pvc).
Il est possible de faire plus simple, notamment pour mapper des espaces de stockage basés sur du partage de fichier comme NFS ou CIFS.
On peut également mapper des dossiers et points de montage locaux à un node. Dans ce cas, les données qui y sont stockées ne seront pas retrouvées en cas de redémarrage de l’application sur un autre worker.
L’avantage de la logique présentée ici est qu’elle est proche de ce que l’on peut trouver en production.
Ici, le CSI est lié à vSphere et je sais que VMware n’est désormais plus forcément une solution sur laquelle miser.
Mais l’exemple vu ici pourrait très bien s’appliquer à d’autres écosystèmes.
L’usage d’un driver CSI, de sc, de pvc et de pv n’est absolument pas exclusif à VMware. C’est d’ailleurs la chose la plus importante à comprendre ici.
Changer de solutions de storage, hormis le déploiement d’un nouveau CSI et la mise à jour de vos StorageClass (sc), n’aura aucun impact sur la logique de déploiement de vos applications.
Même un passage d’une infra Onprem à une infra Cloud conservera cette logique de fonctionnement, hormis peut-être qu’en cloud, vous n’aurez pas forcement le même choix de fournisseurs CSI.
Si vous voulez vous détacher de tout fabricant/fournisseur spécifique, vous pouvez très bien partir sur une solution d’infrastructure de storage comme CEPH.
Ce genre d’écosystème se marrie très bien à K8S et permet d’avoir aussi bien du partage de fichier que du stockage bloc, mais ça nécessite quelques connaissances et une charge d’administration complémentaire.
Si à l’inverse vous souhaitez capitaliser sur des baies de stockage traditionnelles, comme celle du constructeur NetAPP, alors vous pouvez également exploiter leur implémentation de CSI autorisant le cluster à provisionner des volumes directement sur leurs équipements.
Quoiqu’il arrive, vous devriez toujours arrivez à retenir une cible pour proposer du storage persistent au sein de vos clusters Kubernetes. L’important est d’être au plus proche de ce que vous connaissez et/ou maitrisez…ou bien de repartir d’un nouveau besoin si vous en avez l’intérêt.
Pour la suite du cookbook c'est par la.