KubeVirt - Partie 4: Stockage Distribué avec Longhorn
Introduction
La gestion du stockage sous Kubernetes a toujours été quelque peu complexe. Il ne faut pas oublier que K8S a été pensé au départ pour des architectures microservice conteneurisées, ou l’éphémère règne en maitre.
Dans une logique cloud, on sépare le compute du storage. La persistance de la donnée est traitée différemment des systèmes standards.
Fort heureusement, aujourd’hui, Kubernetes n’est pas réservé au microservice, mais peut héberger des applications traditionnelles.
On peut d’ailleurs considérer une VM comme une sorte de grosse application monolithique qui nécessite l’accès permanent à ses données, qui doit pouvoir les persister, tout en les retrouvant dans un état cohérent, démarrage après démarrage, même si le serveur hôte a changé.
Rappel sur les fondamentaux du stockage sous K8S
Sous K8S on retrouve trois objets principaux dédiés au stockage :
- Les StorageClass (sc): regroupe des ressources de stockage dans lesquels Kubernetes peut provisionner des volumes. On peut imaginer des storageclass regroupant des technologies de stockage répondant chacune à des exigences différentes en termes de performance, de redondance, de SLA…
- Les PersistentVolumeClaim (pvc): permets de déclarer un besoin de stockage de façon à ce qu’il puisse correspondre à un volume existant ou qu’il demande la création d’un nouveau volume… généralement dans une storageclass.
- Le PersistentVolume (pv): l’objet de base permettant d’associer un volume de donnée à une ressource sous Kubernetes. Peut-être créé dynamiquement dans une sc par un pvc.
Les trois peuvent s’utiliser de manière complémentaire, ou le PersistentVolume peut s’exploiter directement.
Tout ce petit monde fonctionne également grâce au CSI (Container Storage Interface), un standard permettant d’interconnecter des systèmes de stockage à Kubernetes de manière à ce qu’ils puissent être manipulés via les objets cités précédemment.
Je ne vais pas rentrer davantage dans le détail, si le sujet vous intéresse, n’hésitez pas à lire mon article dédié intégré à mon cookbook K8S. J’ai aussi un autre tutoriel sur le stockage qui reprennent ces principes pour exploiter des systèmes de fichiers partagés, comme NFS ou SMB.
Besoin pour KubeVirt
En ce qui concerne Kubevirt et la création de machines virtuelles, il est impératif de disposer d’un stockage en bloc. Cela permet à une VM d’exposer un volume persistant (PersistentVolume) comme s’il s’agissait d’un disque dur, que la VM peut ensuite formater selon ses besoins.
Plusieurs systèmes sont offerts sur le marché, compatibles avec CSI et pouvant traiter ce point.
Le plus connu est sans doute CEPH. C’est une solution complète, capable de traiter tous les types d’accès (objets, filer, bloc) très performante, mais réputée pour être complexe et nécessitant des compétences avancées dans le stockage.
Pour un usage plus « natif », il existe Longhorn Il est limité au mode bloc, mais ce n’est pas un problème pour nous.
Longhorn : origine et fonctionnement

Cliquez sur l'image pour l'agrandir.
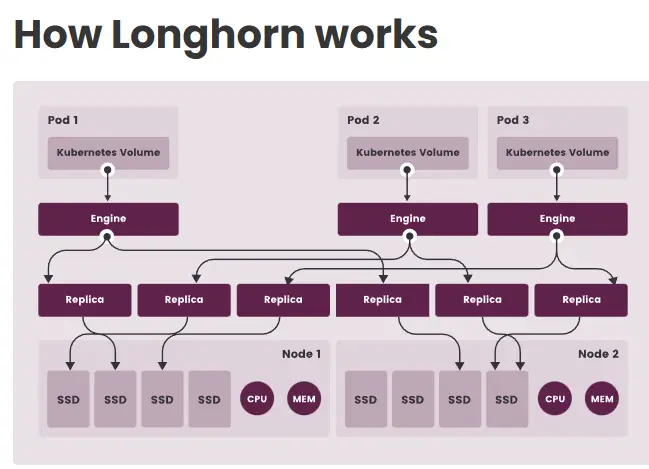
Longhorn est un moteur de stockage par bloc distribué conçu spécifiquement pour Kubernetes. Il est "Cloud-Native", ce qui signifie qu'il a été construit pour fonctionner comme un ensemble de microservices au sein du cluster, plutôt que comme une baie de stockage externe greffée dessus.
Il transforme le stockage local (disques SSD/NVMe) des nœuds Kubernetes en un pool de stockage répliqué et résilient pour les applications, ici pour nos VMs.
Il est simple d’implémentation, relativement performant (mais répondant déjà à bon nombre d’usage) avec peu de prérequis nécessaires.
Il a été créé par Rancher Labs vers 2017 (l'entreprise derrière la plateforme Rancher, aujourd'hui rachetée par SUSE) puis donné à la CNCF (Cloud Native Computing Foundation) en octobre 2019.
Ce projet est constamment amélioré et largement utilisé, en particulier dans KubeVirt, qui est intégré à l’offre d’hyperconvergence de SuSE (Harvester).
À noter que Longhorn dispose d’une compatibilité de backup à destination de stockage S3.
L’idée est d’avoir au sein de chaque nœud Kubernetes, des disques internes de mêmes capacités et de caractéristiques identiques pour les agréger virtuellement afin d’y déployer des PersistentVolume qui pourront être répliqués jusqu’au nombre maximum de nodes.
Même si la donnée n’est pas présente sur chaque node, un asset peut s’exécuter et échanger avec le stockage présent sur un autre node à travers le réseau… mais avec un risque de dégradation de performance si la VM exécutée sur un nœud X doit passer par le réseau pour chercher sa donnée sur le disque du nœud Y.
Cliquez sur l'image pour l'agrandir.
Prérequis et points d’attentions
On arrive directement à l’un des prérequis clefs pour un usage de LongHorn en production : disposer d’un réseau dédié idéalement de 10Gb… que je n’ai pas pour ce tutoriel…
Ce n’est pas gênant pour mon homelab mononoeud, mais il faudra forcément y passer si je souhaite monter en nombre de serveur.
Un avantage est que des cartes réseau 10 Go ainsi que des switches compatibles sont désormais disponibles à des prix abordables. Il sera donc nécessaire, en plus des réseaux créés dans la première partie de ce cookbook consacré à Kubevirt, de prévoir la création d’un réseau dédié au stockage.
Mais j’insiste sur ce point : l’utilisation de Longhorn en production, comme pour tout autre système de stockage basé sur des blocs distribués, doit bénéficier d’un réseau dédié (à minima un VLAN) et très performant (10 Go). De plus, bien que Longhorn permette des configurations hybrides entre les nœuds, offrant la possibilité de combiner différents types de disques, cette option n’est pas du tout recommandée.
Il faut bien imaginer que, par exemple, dans un système à 3 nodes, où la donnée est répliquée trois fois, c’est le node avec la performance la plus basse qui donne la cadence…
Autre limitation de ce type de technologie, la consommation d’espace. Si l’on veut s’assurer que chaque VM puisse tourner à un instant T sur chaque node avec sa donnée en local, cela implique de répliquer la donnée autant de fois qu’il y’a de node.
Longhorn n’intègre pas d’algorithme de compression ou de déduplication qui pourraient permettre de limiter l’impact de l’espace disque. Ça serait trop pénalisant en performance.
Par contre, pour KubeVirt, Longhorn va traiter les disques des VMs en mode thin. C’est-à-dire que, si vous déclarez un disque de 500Go, mais que la VM ne va pas occuper plus de 20Go d’espace, alors sur le disque physique des nodes, l’espace occupé ne sera que de 20Go. Si et seulement si la VM utilise la totalité de l’espace déclaré, alors l’espace occupé sur le disque physique sera de 500Go… par contre, attention, on ne peut pas revenir en arrière. Si, à un instant T la VM consomme 50Go, qu’on y réalise du ménage pour revenir à 20Go, l’espace physique restera à 50Go.
Enfin, notez qu’il est possible de créer des volumes chiffrés si le besoin de sécurité s’en fait sentir. Ainsi, si le disque est volé du nœud d’origine, le volume Longhorn ne pourra être lu.
Longhorn : Préparatifs
Cible
Finis la théorie, passons à la pratique. Sur mon serveur, j’ai trois disques SSD, deux au format sata, 1 au format NVME (et donc plus rapide).
L’idée va être de créer deux classes de storage, l’une nommée sc-longhorn-nvme rattachée à mon disque NVME pour mes besoins de stockage haute performance, et l’autre nommée sc-longhorn-sata rattachée à mes disques SATA pour des besoins de volumétrie avec moins d’exigence sur les performances.
Voici un petit schéma qui résume la stratégie :

Cliquez sur l'image pour l'agrandir.
Tout d’abord, il est crucial de vérifier que nous avons installé les packages système nécessaires pour longhorn, notamment iscsi-initiator-utils.
sudo dnf install -y iscsi-initiator-utils
sudo systemctl enable --now iscsid
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
À noter aussi le besoin du module kernel dm_crypt. Celui-ci a été mis en œuvre dans première partie du tutoriel, lors de l’installation des prérequis globaux du serveur via Ansible.
Configuration des disques
Ensuite, il faut préparer les disques qu’on va dédier à Longhorn. Pour ça on va les formater complètement pour s’assurer qu’ils soient vierges de toute donnée et prêts à être utilisés.
sudo mkfs.xfs -f /dev/sda
sudo mkfs.xfs -f /dev/sdb
sudo mkfs.xfs -f /dev/nvme1n1
Cliquez sur l'image pour l'agrandir.
Ici j’ai choisi le filesystem xfs, un standard qui présente un bon rapport simplicité/performance.
Ensuite on va créer des dossiers de montages, car il est nécessaire que ces disques soient montés par le système.
sudo mkdir -p /var/lib/longhorn/nvme
sudo mkdir -p /var/lib/longhorn/sata1
sudo mkdir -p /var/lib/longhorn/sata2
Cliquez sur l'image pour l'agrandir.
Il est conseillé de garder le chemin /var/lib/longhorn/. C’est l’usage classique.
Ensuite on monte les disques fraichement formatés dans le dossier qu’on vient de créer.
sudo mount /dev/nvme1n1 /var/lib/longhorn/nvme
sudo mount /dev/sda /var/lib/longhorn/sata1
sudo mount /dev/sdb /var/lib/longhorn/sata2
Cliquez sur l'image pour l'agrandir.
Il va falloir ensuite s’assurer qu’il soit monté automatiquement à chaque démarrage du serveur et donc être inscrit dans le fstab.
Je ne saurais que vous conseiller d’utiliser les uuid des partitions et non leur nom susceptible de changer suivant l’évolution matérielle de vos serveurs.
Pour cela, utiliser les commandes pour récupérer les bonnes informations :
df -h
sudo blkid

Cliquez sur l'image pour l'agrandir.
Editez le fstab pour le compléter avec les bonnes données :
sudo vi /etc/fstab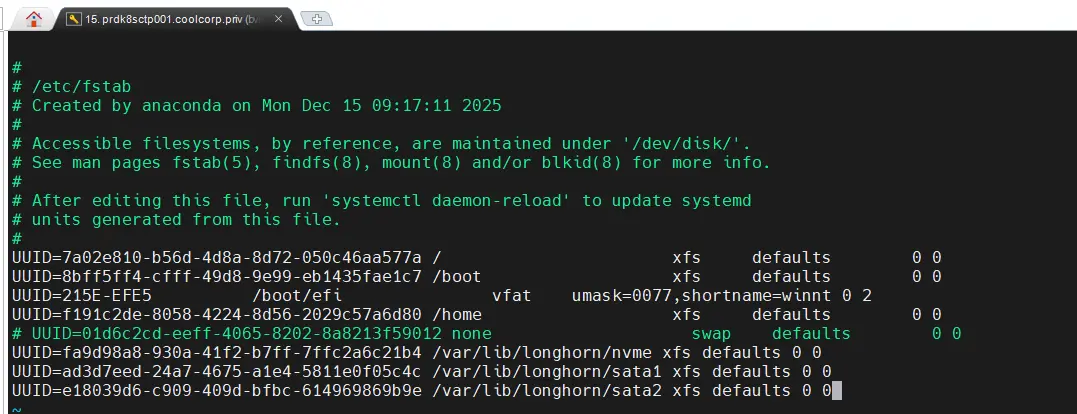
Cliquez sur l'image pour l'agrandir.
C’est toujours bon de faire un reboot à ce stade pour s’assurer que les disques soient bien remontés au démarrage du serveur et qu’il n’y ai pas d’erreur à ce niveau.
sudo reboot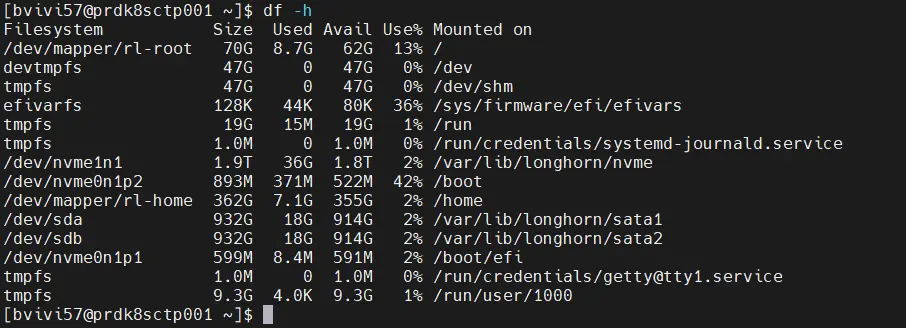
Cliquez sur l'image pour l'agrandir.
On peut maintenant installer Longhorn à proprement parler.
Longhorn : Déploiement
Installation
Pour cela, comme pour Traefik et Cert-Manager dans l’article précédent, on va utiliser Helm.
On ajoute le repo :
helm repo add longhorn https://charts.longhorn.io
helm repo update
Cliquez sur l'image pour l'agrandir.
Puis on lance le déploiement :
helm install longhorn longhorn/longhorn \
--namespace longhorn-system \
--create-namespace \
--set defaultSettings.createDefaultDiskLabeledNodes=true \
--set defaultSettings.defaultDataPath="/var/lib/longhorn/nvme"
Cliquez sur l'image pour l'agrandir.
Le nom du namespace cible est celui proposée par défaut par longhorn.
On passe peu d’arguments et, rapidement on devrait voir monter les pods dans le namespace qui vient d’être créé.
kubectl get pods -n longhorn-system
Cliquez sur l'image pour l'agrandir.
À partir de là, il est conseillé de passer par la GUI de longhorn.
4.2 Exposition de la GUI
Ça tombe bien, on a déployé tout le nécessaire pour cela via l’article précédent.
On va s’appuyer sur notre Gateway et notre instance Traefik, ainsi que de Cert-Manager pour rendre accessible l’interface de longhorn sur une URL https.
On commence par labéliser notre namespace pour qu’il rentre dans le périmètre de notre gateway. Si vous ne comprenez pas ce point, je vous invite à lire ou relire cette partie du tutorial.
kubectl label namespace longhorn-system network=lan

Cliquez sur l'image pour l'agrandir.
Histoire de sécuriser l’accès à la solution, on va utiliser un middleware Traefik pour forcer la demande d’un login et d’un mot de passe, comme pour le dashboard Traefik.
Pour ça, on crée un mot de passe avec l’outil htpasswd.
htpasswd -Bbn bvivi57 'pass'La sortie va être utilisée pour créer un secret sec-auth-longhon-ui qu’on va associer à middleware Traefik via le fichier 01-middelware-auth-longhon-ui.yml.
apiVersion: v1
kind: Secret
metadata:
name: sec-auth-longhon-ui
namespace: longhorn-system
type: Opaque
stringData:
users: bvivi57:xxxxxxxxxxxxxxxxxxxxxxxxx
---
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: middelware-auth-longhon-ui
namespace: longhorn-system
spec:
basicAuth:
secret: sec-auth-longhon-uiPuis on crée l’objet ReferenceGrant et l’objet HttpRoute pour que la Gateway puisse fournir l’accès à la GUI sur l’URL https://longhorn.coolcorp.priv. Pour exploiter HTTPS, on va autoriser, via l’objet ReferenceGrant, la Gateway à utiliser le certificat wildcard hébergé dans le namespace inf-cert-lan.
---
apiVersion: gateway.networking.k8s.io/v1beta1
kind: ReferenceGrant
metadata:
name: allow-traefik-read-coolcorp
namespace: inf-cert-lan
spec:
from:
- group: gateway.networking.k8s.io
kind: Gateway
namespace: inf-traefik-lan
to:
- group: ""
kind: Secret
name: sec-tls-wildcard-coolcorp-priv
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: httproute-longhorn-ui
namespace: longhorn-system
labels:
environment: prd
network: lan
application: longhorn-ui
spec:
parentRefs:
- name: traefik-gateway-lan
namespace: inf-traefik-lan
sectionName: websecure
hostnames:
- longhorn.coolcorp.priv
rules:
- matches:
- path:
type: PathPrefix
value: /
filters:
- type: ExtensionRef
extensionRef:
group: traefik.io
kind: Middleware
name: middelware-auth-longhon-ui
backendRefs:
- name: longhorn-frontend
port: 80
Encore une fois, si vous vous sentez perdu, tout est expliqué et détaillé dans l’article précédent.
On applique le tout :
kubectl apply -f 01-middelware-auth-longhon-ui.yml
kubectl apply -f 02-httproute-longhorn-ui.yml
Cliquez sur l'image pour l'agrandir.
Et la magie opérant, on peut maintenant se rendre dans l’interface de LongHorn pour finaliser notre configuration (en s’authentifiant au préalable avec notre login/password).
4.3 Configuration des volumes et des StorageClass
La GUI est simpliste et va à l’essentiel.
En l’état actuel, aucun volume n’est visible, et c’est normal, puisque rien n’a encore été fait.
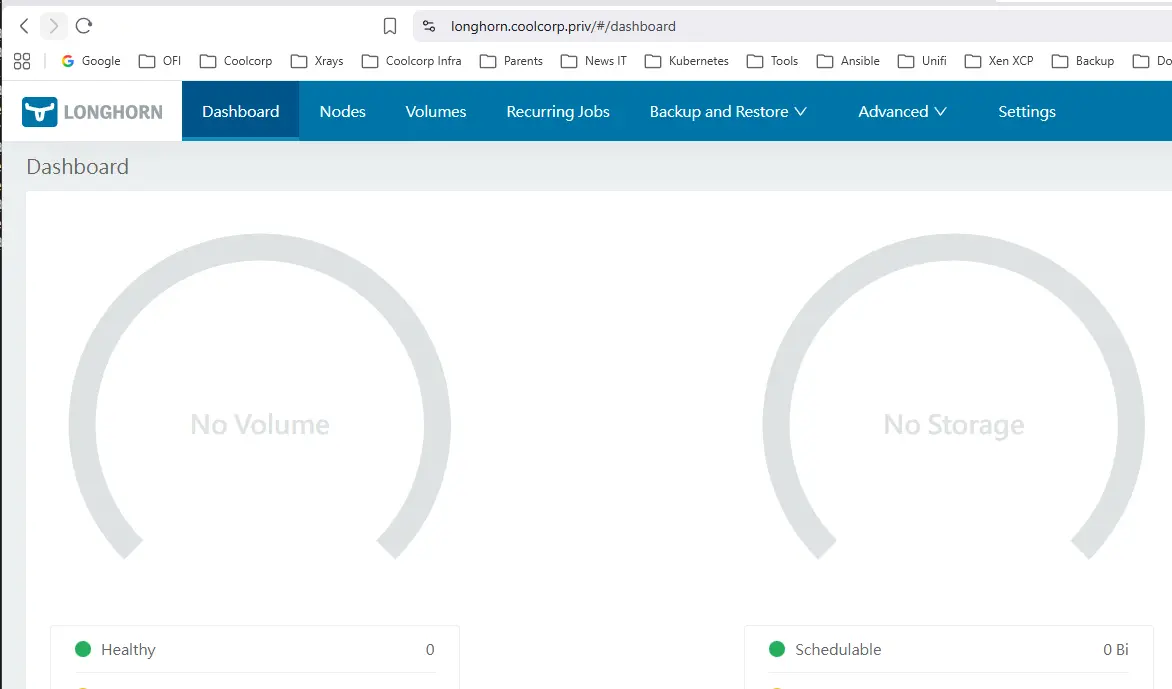
Cliquez sur l'image pour l'agrandir.
On va corriger cela en se rendant sur le menu node. Puis, via le menu « sandwich » on clique sur Edit node and Disks.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
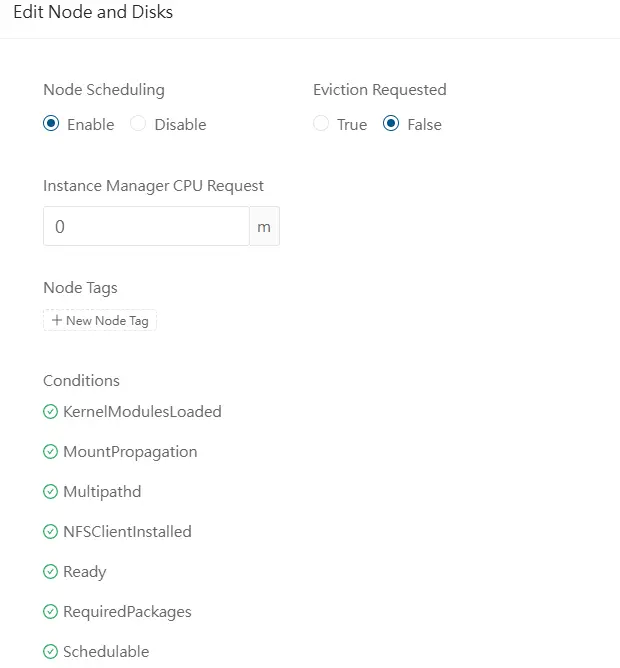
De là on peut déjà vérifier si tous nos prérequis sont au vert.
Cliquez sur l'image pour l'agrandir.
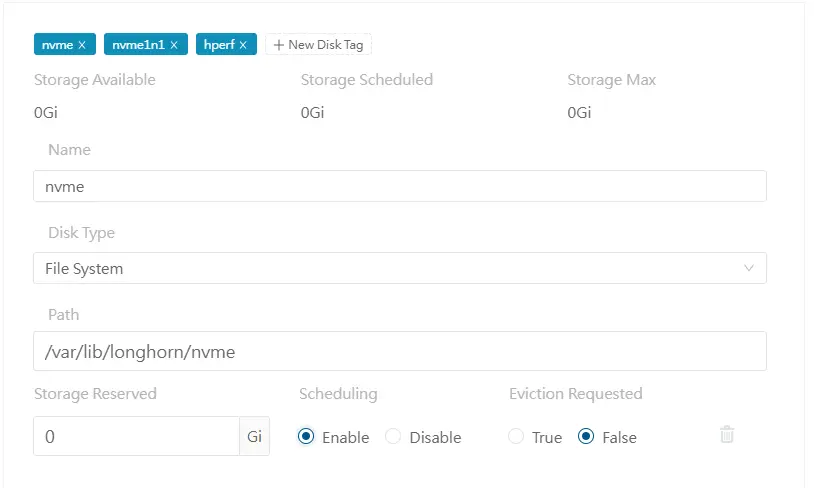
Si tout est bon, on peut déclarer de nouvelles ressources. Il suffit de lui donner un nom, de rester sur un mode File System, puis d’indiquer le point de montage où se situe la ressource.
Je vous invite également à mettre des tags, cela va nous être utile pour la suite.
Cliquez sur l'image pour l'agrandir.
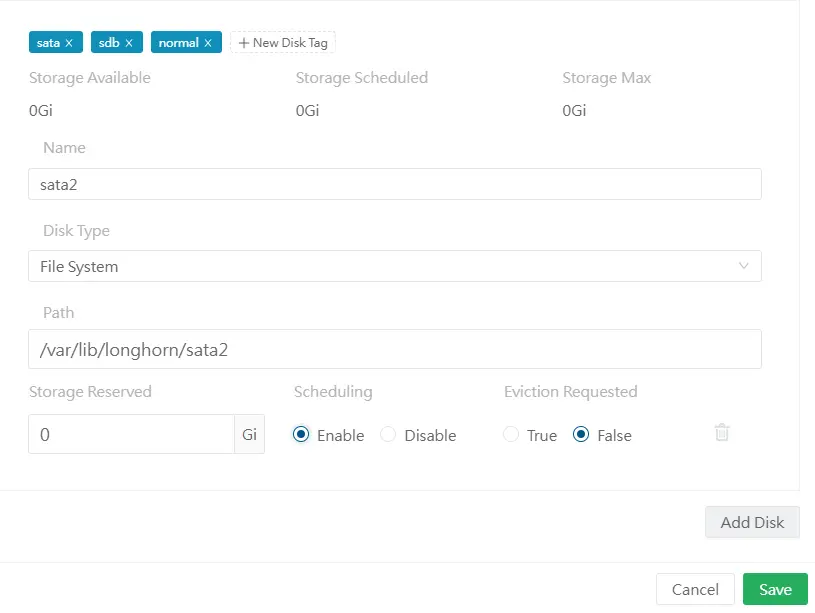
On reproduit la logique par nombre de points de montage, en prenant bien soin d’utiliser les mêmes tags pour les disques de même nature. En l’occurrence, pour mon exemple, les tags sata et normal qui vont s’appliquer à mes deux disques sata (pour mon disque NVME, j'utilise le tag nvme et hperf).

Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Si tout va bien, vous devriez obtenir en fin de configuration ce type d’affichage.

Cliquez sur l'image pour l'agrandir.
On peut y voir l’espace total disponible sur le node longhorn et son status. Si on rentre dans le détail du volume global, on retrouve nos disques.

Cliquez sur l'image pour l'agrandir.
Tout est prêt côté longhorn, il ne nous reste plus qu’à créer nos StorageClass.
Pour ça, on va utiliser un fichier 01-sc-all.yml, dans lequel on va retrouver nos deux StorageClass : sc-longhorn-nvme et sc-longhorn-sata.
Pour chacune d’entre elles, on va maintenir le paramètre de réplication à un, car je ne dispose que d’un nœud pour l’instant.
Par contre, pour l’option « diskSelector », on va s’appuyer sur les tags paramétrés au niveau de longhorn.
Pour sc-longhorn-nvme, on va utiliser le tag nvme, et pour sc-longhorn-sata, on va utiliser le tag sata.
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: sc-longhorn-nvme
provisioner: driver.longhorn.io
allowVolumeExpansion: true
parameters:
numberOfReplicas: "1"
# staleReplicaTimeout: "2880"
# fromBackup: ""
diskSelector: "nvme"
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: sc-longhorn-sata
provisioner: driver.longhorn.io
allowVolumeExpansion: true
parameters:
numberOfReplicas: "1"
# staleReplicaTimeout: "2880"
# fromBackup: ""
diskSelector: "sata"
C’est de cette manière que longhorn saura sur quel disque il doit provisionner le persistent volume.
kubectl apply -f 01-sc-all.yml

Cliquez sur l'image pour l'agrandir.
De notre côté, fonction de nos usages, il suffira de retenir l’une ou l’autre des storage class pour couvrir notre besoin de stockage persistent.
Conclusion intermédiaire
On arrive au bout de cette partie du Tutoriel autour de KubeVirt. Longhorn est une solution facile à déployer et rapide pour offrir un stockage de bloc persistant au sein d’un cluster K8S. Ce qui est parfait pour traiter les disques des VMs qu’on sera amené à créer avec KubeVirt. Néanmoins, attention au prérequis de performance, notamment réseau et disque. Si Longhorn se déploie facilement, il faut retenir des périphériques performants adressables à travers un réseau dédié à très haut débit. Ce n’est pas forcément le cas ici, car il s’agit d’un environnement de démonstration, mais j’ai déjà en commande de quoi basculer sur un cluster KubeVirt multinode. Quand viendra le moment, je mettrai à jour ce cookbook pour exploiter Longhorn via une nouvelle architecture matérielle. En attendant, on peut continuer notre découverte de KubeVirt, à travers le prochain article sur CDI (Containerized Data Importer)