Kubevirt - Partie 2: Initialisation du cluster et installation de KubeVirt
Introduction
Après avoir examiné les prérequis et les configurations réseau dans l’article précédent, il est temps de passer à l’initialisation du cluster Kubernetes et à l’installation de KubeVirt.
Comme je l’ai toujours fait pour mon usage de K8S, je déploie ce dernier via une installation dite Vanilla. C’est-à-dire que je n’utilise pas de distribution Kubernetes particulière, mais je m’appuie sur l’outil officiel d’installation: kubeadm.
Cela me permet de rester au plus proche des versions Kubernetes telles que mises à disposition par les développeurs et d’avoir le moins de dépendance possible à une distribution spécifique.
L’inconvénient est d’avoir une solution moins intégrée nécessitant parfois plus de paramétrage et d’attention, bien que je trouve les installations de K8S Vanilla de plus en plus simples au fil des versions.
Il reste le cas des updates, mais là aussi, cela se fait finalement relativement simplement dès lors qu’on adopte une démarche posée, en traitant composant par composant et en prenant bien soin de vérifier les matrices de compatibilité à chaque nouvelle version.
Initialisation du cluster
Le cluster est composé d’un seul nœud pour les besoins de ce tutoriel. Mais qu’on utilise un ou plusieurs serveurs, l’initialisation reste la même.
On se connecte au serveur qui assurera le rôle de premier node et de premier controle plan, (ici mon serveur physique précédemment déployé, prdk8sctp001).
On s’appuie sur le fichier de configuration kubeadm.conf qui,
pour rappel, dispose du contenu suivant :
---
# PARTIE 1 : Configuration du noeud initial (Master)
apiVersion: kubeadm.k8s.io/v1beta4
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: "192.168.10.160"
bindPort: 6443
nodeRegistration:
criSocket: "unix:///var/run/containerd/containerd.sock"
kubeletExtraArgs:
- name: "node-ip"
value: "192.168.10.160"
---
# PARTIE 2 : Configuration du Cluster
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
kubernetesVersion: "1.34.2"
clusterName: "rubikub"
controlPlaneEndpoint: "rubikub.coolcorp.priv:6443"
networking:
dnsDomain: cluster.local
podSubnet: "10.11.0.0/16"
serviceSubnet: "10.12.0.0/16"
apiServer:
certSANs:
- "192.168.10.160"
- "rubikub.coolcorp.priv"
- "127.0.0.1"
- "localhost"
scheduler: {}
controllerManager: {}
---
# PARTIE 3 : Configuration du Kubelet
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
failSwapOn: true
authentication:
anonymous:
enabled: false
Pour lancer la commande kubeadm (installé via les packages
déployés dans l’article précédent), on se connecte au profil root et on exécute la commande
kubeadm init --config kubeadm.conf --skip-phases=addon/kube-proxy

Cliquez sur l'image pour l'agrandir.
Le fichier de conf est passé en argument et on précise qu’on ne souhaite pas déployer le composant « kube-proxy », celui-ci sera remplacé par le driver CNI Cilium par la suite.
L’opération prend plusieurs minutes, mais doit se terminer avec les instructions de fin permettant d’ajouter des control planes ou des workers.
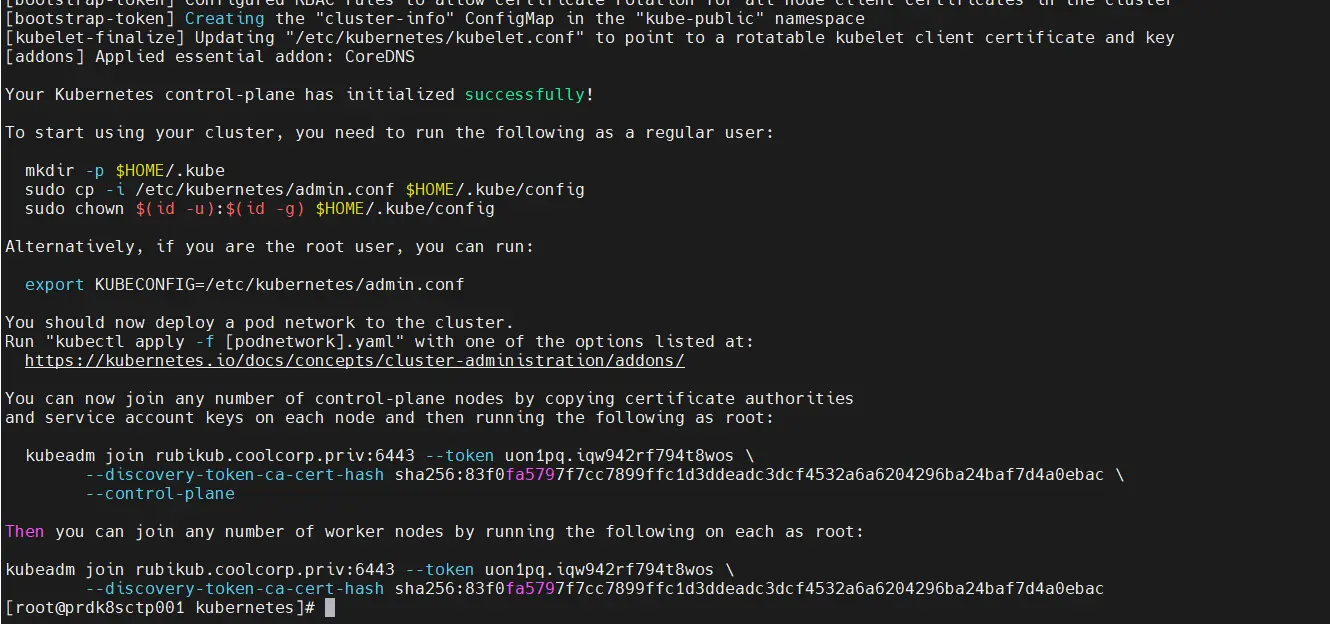
Cliquez sur l'image pour l'agrandir.
Ici, je me contente simplement de récupérer le fichier de configuration généré par l’initialisation du cluster. Celui-ci contient les éléments d’authentification pour accéder à l’API K8S en tant qu’administrateur.
Je copie ce fichier au niveau de mon profil utilisateur, afin qu’il puisse être appelé automatiquement par la CLI kubectl.
cp -i /etc/kubernetes/admin.conf /home/bvivi57/.kube/config
chown -R bvivi57:bvivi57 /home/bvivi57/.kube/configN’hésitez pas à parcourir mon cookbook K8S pour plus d’informations sur l’initialisation d’un cluster. Vous y trouverez d’autres exemples avec l’ajout de nœuds supplémentaires.
Une fois toutes les commandes passées, on peut revenir à un profil de
session classique et tester l’état du node avec la commande kubectl get node
L’API devrait répondre positivement, mais le node n’est pour l’instant pas dans le statut ready. Ce qui est normal à ce stade.
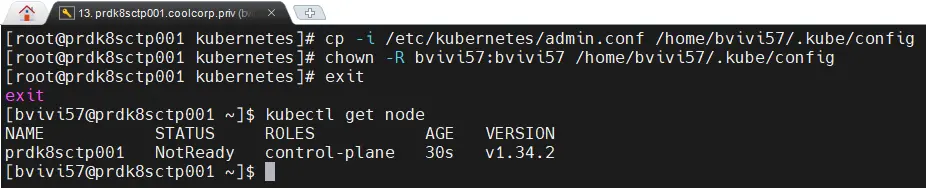
Cliquez sur l'image pour l'agrandir.
Déploiement de Cilium
Pour rendre le node opérationnel, il est nécessaire de déployer un driver CNI (Container Network Interface). En l’occurrence, j’ai retenu Cilium.
Je ne détaillerais pas ce qu’est un CNI, mais vous pouvez retrouver des informations associées dans mon article dédié dans mon cookbook K8S.
Cilium est actuellement le driver privilégié pour la gestion du réseau sous Kubernetes. C’est lui qui va assurer toute la connectivité interne au cluster.
Avant de le déployer, il est nécessaire de lever une restriction par défaut présent sur notre node, via la levée d’un « taint ».
Il s’agit de retirer l’interdiction d’exécuter des assets non spécifiques sur un control plane. Pour cela, on tape la commande :
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
Cliquez sur l'image pour l'agrandir.
Cette opération est uniquement nécessaire en raison de l’installation d’un node unique sur le cluster jouant à la fois le rôle de control plane et de worker.
Il ne faut jamais lever cette restriction sur un cluster multinode en production. Les control planes ne sont normalement pas utilisés pour exécuter n’importe quel assets et doivent être réservés au pilotage du cluster.
Dans mon tutoriel, c’est un prérequis à réaliser si je ne veux pas être coincé sur l’exécution de certains conteneurs qui pourraient refuser de se lancer sur un control plane.
Je pourrais toujours rétablir cette contrainte plus tard lorsque j’ajouterais des nodes en séparant bien les serveurs control planes et les workers.
Pour rappel, la configuration de cilium préparé précédemment est associée à ce fichier cilium-values.yaml
kubeProxyReplacement: true
k8sServiceHost: 192.168.10.160
k8sServicePort: 6443
cni:
# Empêche Cilium de prendre le contrôle total du dossier /etc/cni/net.d
# Cela permet à Multus de rester le "maître" et d'appeler Cilium comme plugin délégué
exclusive: false
ipam:
mode: "cluster-pool"
operator:
clusterPoolIPv4PodCIDRList:
- "10.13.0.0/16"
# Configuration Hubble (Visualisation)
hubble:
relay:
enabled: true
ui:
enabled: true
frontend:
server:
ipv6:
enabled: false
tls:
auto:
enabled: true
method: helm
certValidityDuration: 1095
cgroup:
autoMount:
enabled: false
Le point important concerne l’option :
exclusive: falseCela est nécessaire pour autoriser l'usage de l’autre driver CNI multus dont on aura besoin ensuite.
Pour déployer Cilium, je vais utiliser Helm, partant du principe que le binaire associé a été copié sur le serveur lors de la précédente étape.
Pareil, si cela ne vous parle pas n’hésitez pas à consulter mon coockbook K8S.
En l’état, helm est un gestionnaire de package pour Kubernetes simplifiant le déploiement des applicatifs qui ont été mis à disposition sur des repos spécifiques.
On commence d’ailleurs par ajouter le repo propre au package de cilium, en s’assurant d’en avoir une version à jour sur le node :
helm repo add cilium https://helm.cilium.io/
helm repo update
Cliquez sur l'image pour l'agrandir.
Puis on lance le déploiement de Cilium avec Helm et l’attribut install auquel on passe comme argument notre fichier de configuration :
helm install --version 1.18.4 --namespace=kube-system cilium cilium/cilium --values=./cilium-values.yaml --set hubble.relay.tolerations[0].key="node-role.kubernetes.io/control-plane" --set hubble.relay.tolerations[0].operator="Exists" --set hubble.relay.tolerations[0].effect="NoSchedule" --set hubble.relay.tolerations[1].key="node-role.kubernetes.io/master" --set hubble.relay.tolerations[1].operator="Exists" --set hubble.relay.tolerations[1].effect="NoSchedule" --set hubble.ui.tolerations[0].key="node-role.kubernetes.io/control-plane" --set hubble.ui.tolerations[0].operator="Exists" --set hubble.ui.tolerations[0].effect="NoSchedule" --set hubble.ui.tolerations[1].key="node-role.kubernetes.io/master" --set hubble.ui.tolerations[1].operator="Exists" --set hubble.ui.tolerations[1].effect="NoSchedule"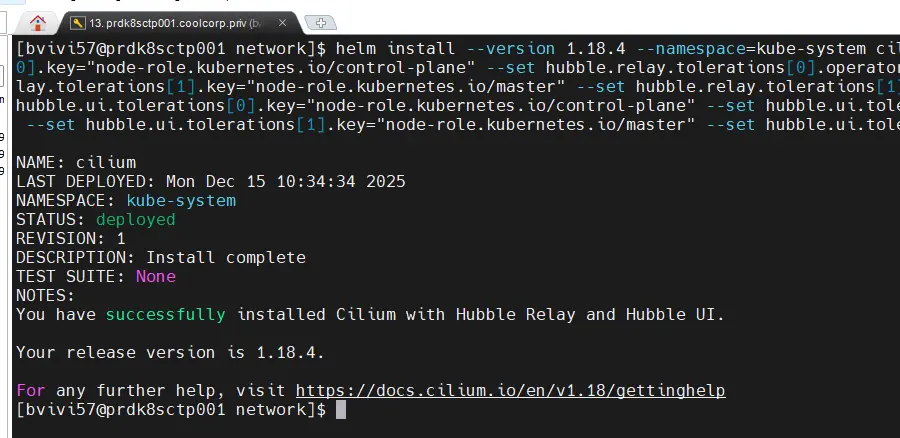
Cliquez sur l'image pour l'agrandir.
Notez qu’on ajoute beaucoup d’attributs supplémentaires normalement inutiles, mais, dans mon cas, comme pour la levée du « taint », il s’agit de s’assurer que tous les conteneurs liés à Cilium puissent s’exécuter sur mon seul et unique node.
D’ailleurs toujours pour cette même raison, si on veut éviter qu’un pod reste en erreur, il faut passer ensuite cette commande :
kubectl scale deployment cilium-operator -n kube-system --replicas=1
Cliquez sur l'image pour l'agrandir.
Cela fait descendre le nombre de répliques du composant cilium-operator à 1, puisque, par défaut, l’installation tente d’en déployer au moins 2 sur des nœuds différents pour des questions de résilience.
Là aussi il faudra penser à rétablir le chiffre de 2 une fois plusieurs nodes en place.
Si tout va bien, alors on devrait avoir les pods de cilium opérationnels dans le namespace kube-system:
kubectl get pod -n kube-system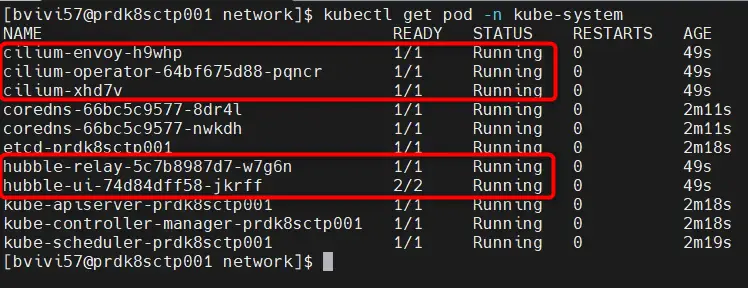
Cliquez sur l'image pour l'agrandir.
Et le node doit maintenant être en statut ready :
kubectl get node
Cliquez sur l'image pour l'agrandir.
Déploiement de Multus
Par défaut, il n’est possible d’attribuer qu’une seule interface réseau à un objet K8S.
Pour lever cette restriction, il faut, en plus de Cilium, ajouter le CNI Multus. Multus se base sur Cilium pour fournir la connectivité, mais autorise plusieurs interfaces à être montées au sein d’une ressource Kubernetes.
C’est Multus qui nous permettra donc d’avoir 2 cartes réseau sur la VM OPNsense cible.
Il existe plusieurs façons d’implémenter Multus, mais nous allons nous concentrer sur la version en tant que daemon, ou mode « thick », car c’est la méthode recommandée actuellement.
Pour cela, on exécute directement le yaml disponible en ligne :
kubectl apply -f https://raw.githubusercontent.com/k8snetworkplumbingwg/multus-cni/master/deployments/multus-daemonset-thick.yml
Cliquez sur l'image pour l'agrandir.
Par contre de base, les ressources attribuées aux pods Multus sont faibles. Il y a un risque pour qu’une fois sollicités à la création de nos VMs, ils finissent par être redémarrés automatiquement par K8S en raison des limites mémoires atteintes.
On va donc booster un peu les pods en autorisant des limites de consommation CPU et mémoires plus élevées :
kubectl set resources daemonset kube-multus-ds -n kube-system --containers=kube-multus --limits=memory=512Mi,cpu=500m --requests=memory=128Mi,cpu=100mÀ ce stade, les ressources multus devraient être up dans le namespace kube-system:
kubectl get pod -n kube-system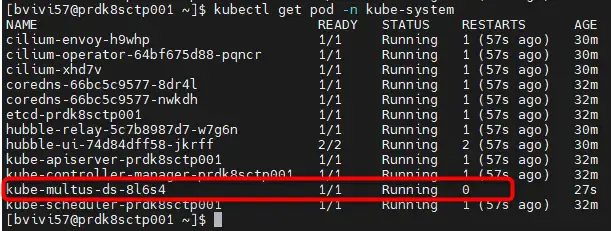
Cliquez sur l'image pour l'agrandir.
Déploiement de KubeVirt
Maintenant que la base Kubernetes est opérationnelle, on peut déployer KubeVirt.
On commence par exporter en variable, la version de la dernière release stable :
export RELEASE=$(curl -L https://storage.googleapis.com/kubevirt-prow/release/kubevirt/kubevirt/stable.txt)En l’occurrence, au moment de cet article, c’est la 1.7.0
Puis, en s’appuyant sur cette variable, on récupère tous les composants en ligne via ces deux commandes :
kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${RELEASE}/kubevirt-operator.yaml
kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${RELEASE}/kubevirt-cr.yaml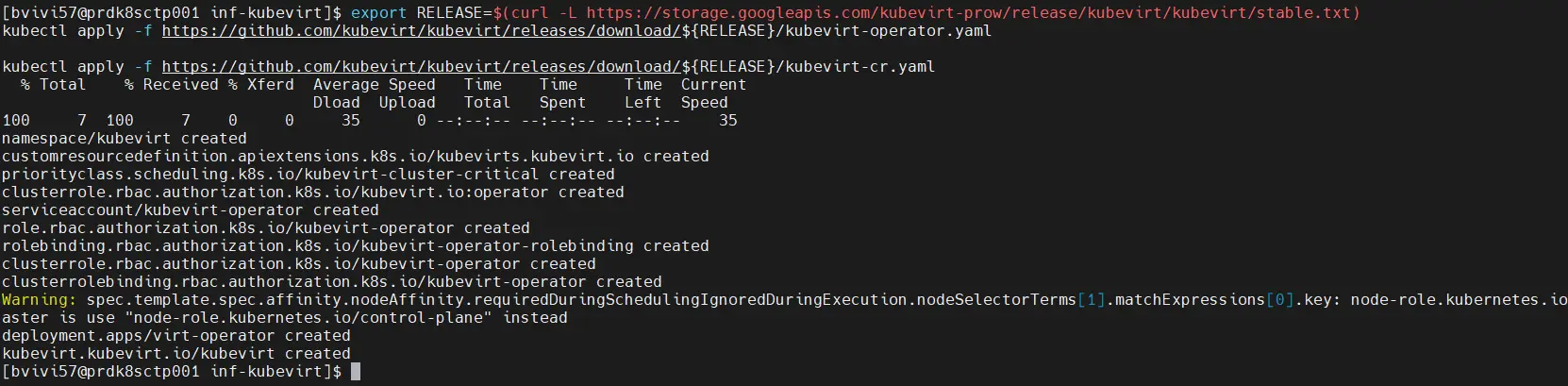
Cliquez sur l'image pour l'agrandir.
Il va falloir patienter plusieurs minutes, car il y a beaucoup de choses à déployer.
À la fin du processus, il est impératif de vérifier que tous les pods actifs se trouvent dans le namespace kubevirt. Il est fortement recommandé d’éviter d’utiliser un autre namespace, car celui-ci est créé automatiquement lors de l’installation de kubevirt.
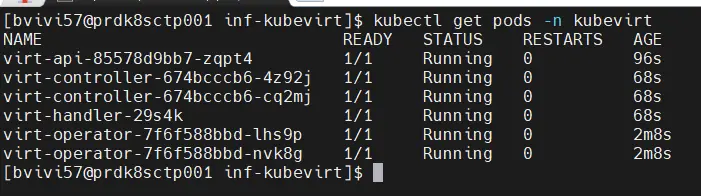
Cliquez sur l'image pour l'agrandir.
Ne reste plus qu’à récupérer le binaire virtcl qui, a l’image de kubectl pour K8S, permet d’interagir avec les composants propres à kubevirt, à commencer par les VMs.
Pour cela on récupère la version identique à celle de kubevirt qu’on vient de déployer :
wget https://github.com/kubevirt/kubevirt/releases/download/${RELEASE}/virtctl-${RELEASE}-linux-amd64
sudo install virtctl-${RELEASE}-linux-amd64 /usr/local/bin/virtctl
Cliquez sur l'image pour l'agrandir.
On vérifie l’appel à la commande :
virtctl version
Cliquez sur l'image pour l'agrandir.
Déploiement des NetworkAttachmentDefinition
Il reste à déployer les NetworkAttachmentDefinition
Il s’agit d’objet K8S qui vont permettre de rattacher les interfaces réseau bridge crée dans la première partie à un espace réseau exploitable par multus pour rattacher des interfaces virtuelles montées par Cilium.
En simplifiant, on pourrait dire qu’il s’agit des réseaux virtuels déclarés au sein de KubeVirt qu’on va pouvoir utiliser pour mapper le réseau à nos VMs.
Comme on l’a vu dans le schéma d’architecture initial, on va exploiter trois réseaux différents :
- Le LAN : réseau par défaut
- Le VLAN_WEB : réseau d’hébergement des VMs exposées à l’extérieur
- Le LAN DMZ : réseau directement rattaché à mon routeur externe.
Il va donc falloir créer trois NetworkAttachmentDefinition, un par zone réseau.
On va les retrouver au sein de ce fichier yaml :
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: nad-lan-default
namespace: inf-kubevirt
spec:
config: '{
"cniVersion": "0.3.1",
"name": "nad-lan-default",
"type": "bridge",
"bridge": "br-lan",
"ipam": {}
}'
---
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: nad-vlan-web
namespace: inf-kubevirt
spec:
config: '{
"cniVersion": "0.3.1",
"name": "nad-vlan-web",
"type": "bridge",
"bridge": "br-web",
"ipam": {}
}'
---
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: nad-dmz-first
namespace: inf-kubevirt
spec:
config: '{
"cniVersion": "0.3.1",
"name": "nad-dmz-first",
"type": "bridge",
"bridge": "br-dmz",
"ipam": {}
}'
À chaque section correspond un réseau. On y référence l’interface de bridge sur laquelle se rattacher.
Il est évident que, dans le cas d’un cluster multinode, il faut que les noms des interfaces de bridge telles que créées précédemment existent avec la même nomenclature sur tout les nodes.
Avant d’exécuter le fichier, on crée un namespace dédié, inf-kubevirt. Il va servir à stocker toutes les configurations communes propres à kubevirt sans impacter le namespace kubevirt par défaut.
kubectl create namespace inf-kubevirt
Cliquez sur l'image pour l'agrandir.
Puis on applique le fichier des NetworkAttachmentDefinition :
kubectl apply -f 01-nad-all.yml
Cliquez sur l'image pour l'agrandir.
On s’assure qu’ils existent bien :
kubectl get network-attachment-definitions -n inf-kubevirt
Cliquez sur l'image pour l'agrandir.
C’est la fin de cette seconde partie. Avant d’attaquer la création de VM, on va poursuivre dans la suite du tutoriel au déploiement de quelques composants tiers optionnels… mais bien pratiques.