XCP-ng: Evolution du Lab V2.0 - Mise en service du HA et test de résilience
Introduction
Cet article conclut le cookbook destiné à présenter et décrire l'évolution de mon homelab sous l'écosystème français Vates.
L'occasion pour moi de mettre en avant l'hyperviseur XCP-ng et son outil de gestion Xen Orchestra, ainsi que la solution de réplication de stockage XOSTOR intégrée à la plateforme.
Voici un rapide état de lieux des travaux menés jusque-là :
- Pour démarrer, on a introduit XCP-ng et acté de l'architecture cible à mettre en œuvre.
- Ensuite, on a installé XCP-ng sur les trois serveurs physiques retenus en y déployant une première VM sous Rocky Linux 10.
- Cette machine virtuelle nous aura permis d'y installer Xen Orchestra à partir des sources afin d'avoir une vue centralisée de nos hyperviseurs. L'occasion de créer un pool regroupant nos trois serveurs.
- Puis, nous avons fait le focus sur le réseau pour préparer les différents VLAN utiles à mon lab, ainsi que le réseau de stockage dédié à la réplication des données et au déplacement des VMs.
- Ce fut au tour du stockage d'être mis en œuvre avec la configuration de XOSTOR et l'établissement d'un Storage Repository mutualisé au sein du pool et tirant parti de l'espace disque restant sur chacun des serveurs. Nous avions terminé par le déplacement d'une VM témoin, à chaud, entre les différents nœuds du pool.
Tout est en place pour mettre en service les fonctionnalités HA du cluster et pour atteindre l'objectif d'obtenir une plateforme de virtualisation résiliente, qui pourrait être une alternative crédible à VMware.
Rappels importants
Avant de rentrer dans le vif du sujet, il est important de rappeler quelques éléments fondamentaux.
- Le master du pool : parmi les trois serveurs qui composent le pool, un seul est désigné comme master. C'est lui qui détient la configuration de référence quant au statut du pool et des VMs qui y sont rattachées. Toute commande passée, même depuis les autres nodes, lui est remontée pour y être inscrite dans sa base. Les autres serveurs ne font que répliquer l'information. C'est aussi le master qui communique avec Xen Orchestra. Si le master venait à tomber, les survivants du pool rentrent alors dans une phase d'élection pour élire un nouveau master. Celui-ci repart de la copie de la base de configuration dont il dispose pour reprendre le rôle du serveur ayant subi un incident. Si ce dernier revient à la vie, il ne redevient pas master, mais reprend une place au sein du pool en agissant cette fois-ci comme un serveur classique.
- Le contrôleur primaire XOSTOR : toujours parmi les trois serveurs, l'un d'entre eux agit comme contrôleur pour la gestion de la réplication des blocs entre les nœuds. C'est lui qui ordonnance et distribue les configurations. De la même façon que pour le master du pool, en cas de perte du contrôleur, les serveurs survivants s'accordent à l'élection d'un nouveau, reprenant ainsi la gestion globale de la réplication.
Le master du pool et le contrôleur XOSTOR sont deux rôles distincts et peuvent être attribués à différents serveurs du groupe. Il peut même arriver qu'un même serveur soit à la fois le serveur principal du pool et le contrôleur primaire XOSTOR. Dans tous les cas, il faut un minimum de trois serveurs pour établir une architecture résiliente et, dans ce cas, la perte maximum admissible d'un node est de un.
C'est donc ce que nous allons tester ici, mais avant terminons la configuration nécessaire pour que tout cela fonctionne correctement.
Création du SR pour le HA
La création d'un pool XCP-ng et la mise au sein de ce dernier des trois serveurs n'impliquent pas par défaut la prise en compte du HA. C'est une fonctionnalité avancée du pool qu'il va falloir activer.
Mais pour que cette configuration soit possible, il faut désigner un SR de référence, accessible à l'ensemble des serveurs du pool, qui pourra servir de stockage de heartbeat.
Chaque serveur va y inscrire et y lire des informations de disponibilité en plus de s'appuyer sur le réseau disponible entre eux. Cela permettra aux nœuds d'identifier leur situation relative les uns par rapport aux autres pour s'impliquer dans les processus d'HA.
On dispose déjà de SR partagés : le premier sur NFS destiné à l'hébergement des ISOs, et le second, le SR XOSTOR lui-même.
Le premier n'est pas utilisable, car il est déclaré comme dédié aux ISOs. Quant au second, bien qu'exploitable, il n'est pas conseillé de l'utiliser. En effet, étant associé à la mécanique XOSTOR, dans le cas où un seul et même serveur assurait à la fois le rôle de master du pool et de contrôleur primaire, la perte de ce dernier risquerait de perturber le HA… Puisque le SR destiné à servir de prise de décision pour le HA du pool serait lui-même perturbé par la perte du contrôleur primaire et impliqué dans la data des VMs susceptibles d'être impactées.
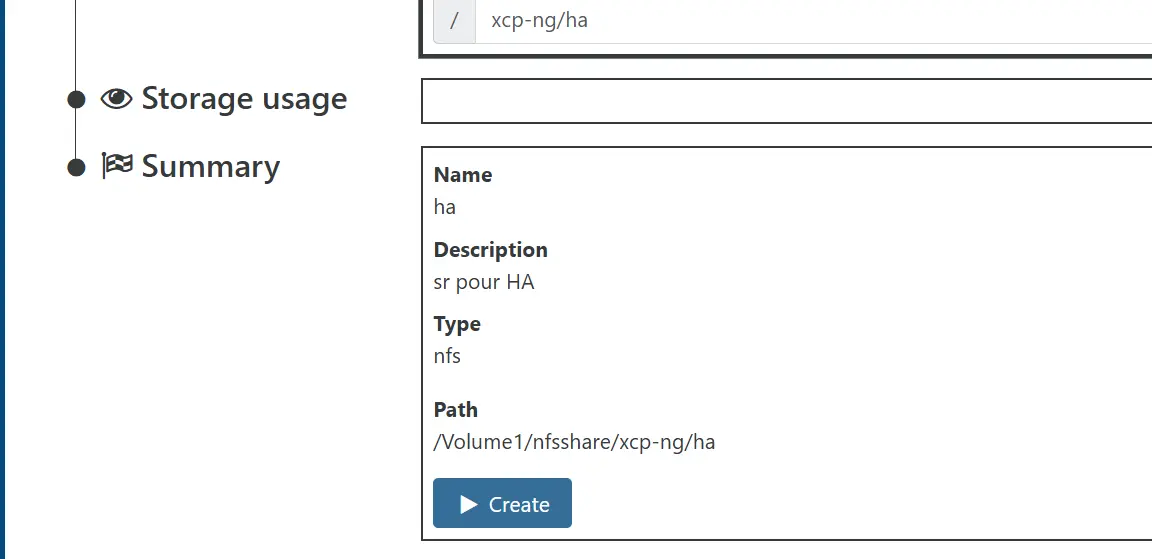
Il est donc conseillé de dédier un SR au sujet. Pas besoin de performance pour cet usage, un simple export NFS sur mon NAS va suffire.
Cliquez sur l'image pour l'agrandir.
Côté Xen Orchestra, il faut se rendre dans le menu adéquat, sélectionner le pool puis ajouter le SR de type NFS.
Cliquez sur l'image pour l'agrandir.
On pointe vers le chemin réseau du volume, on indique un sous-dossier si besoin, puis on valide.
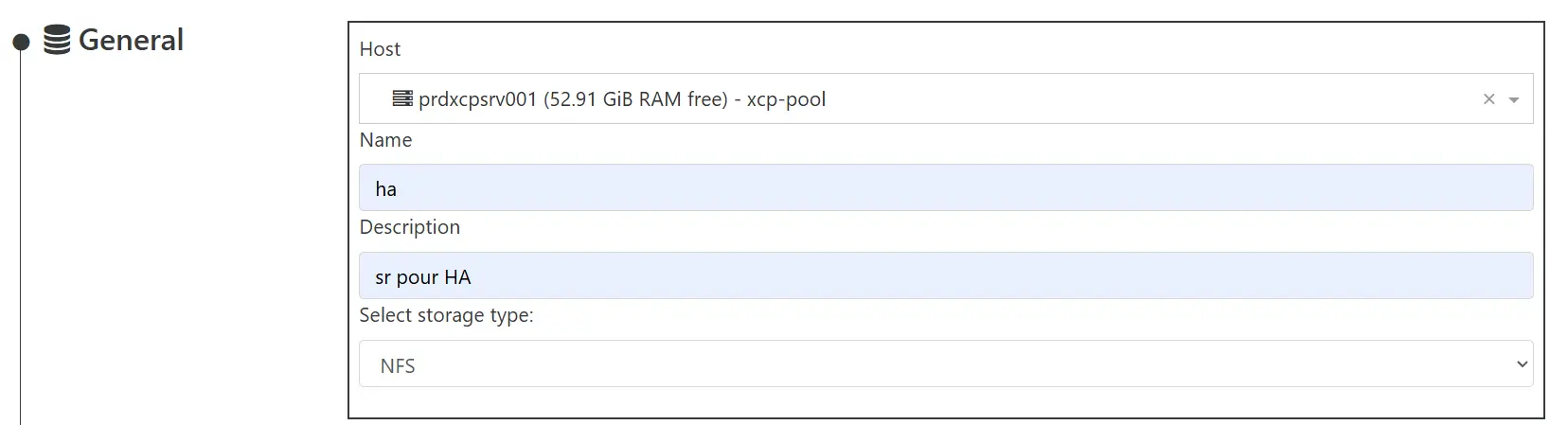
Cliquez sur l'image pour l'agrandir.
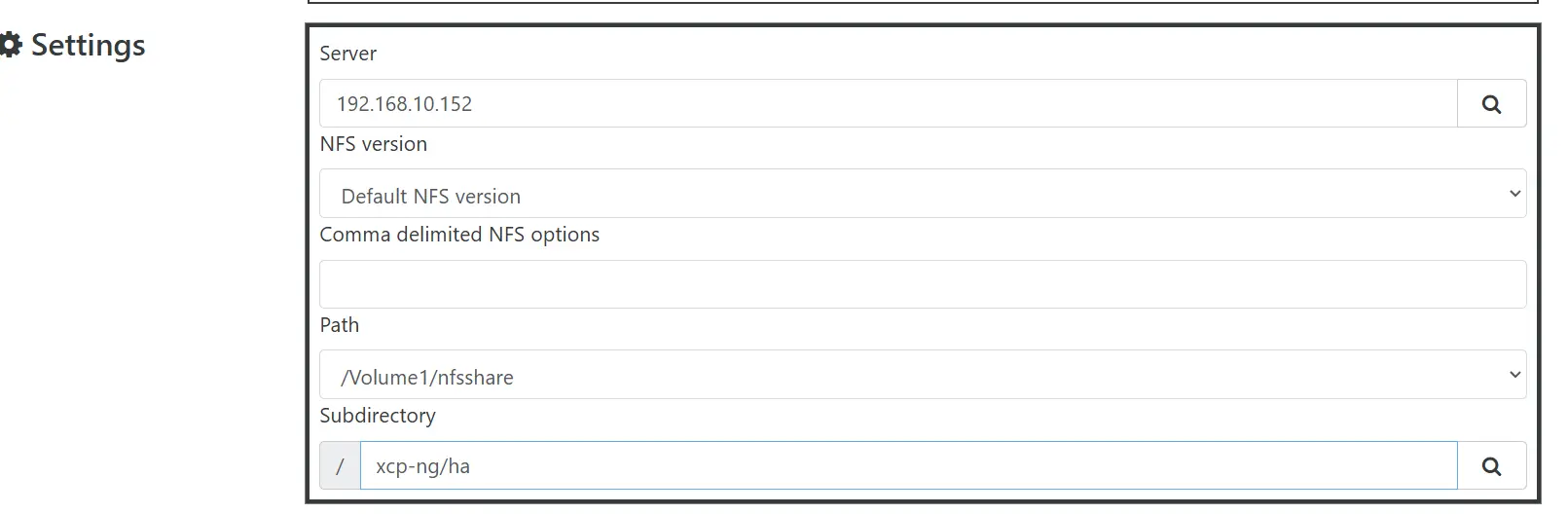
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
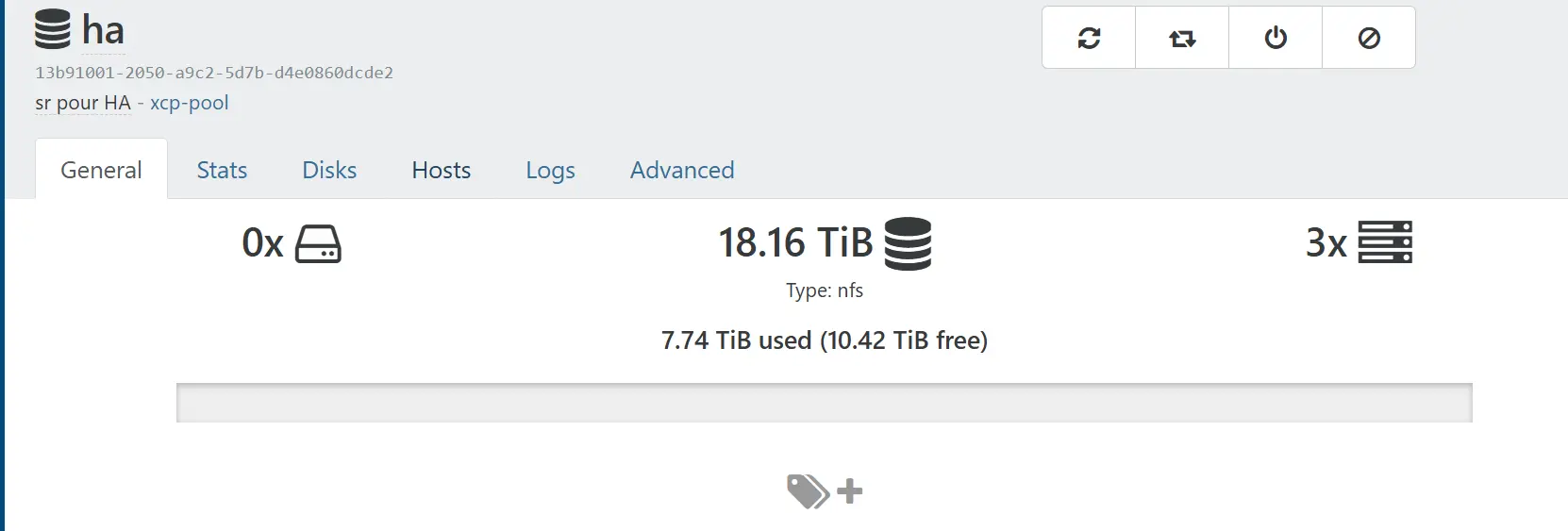
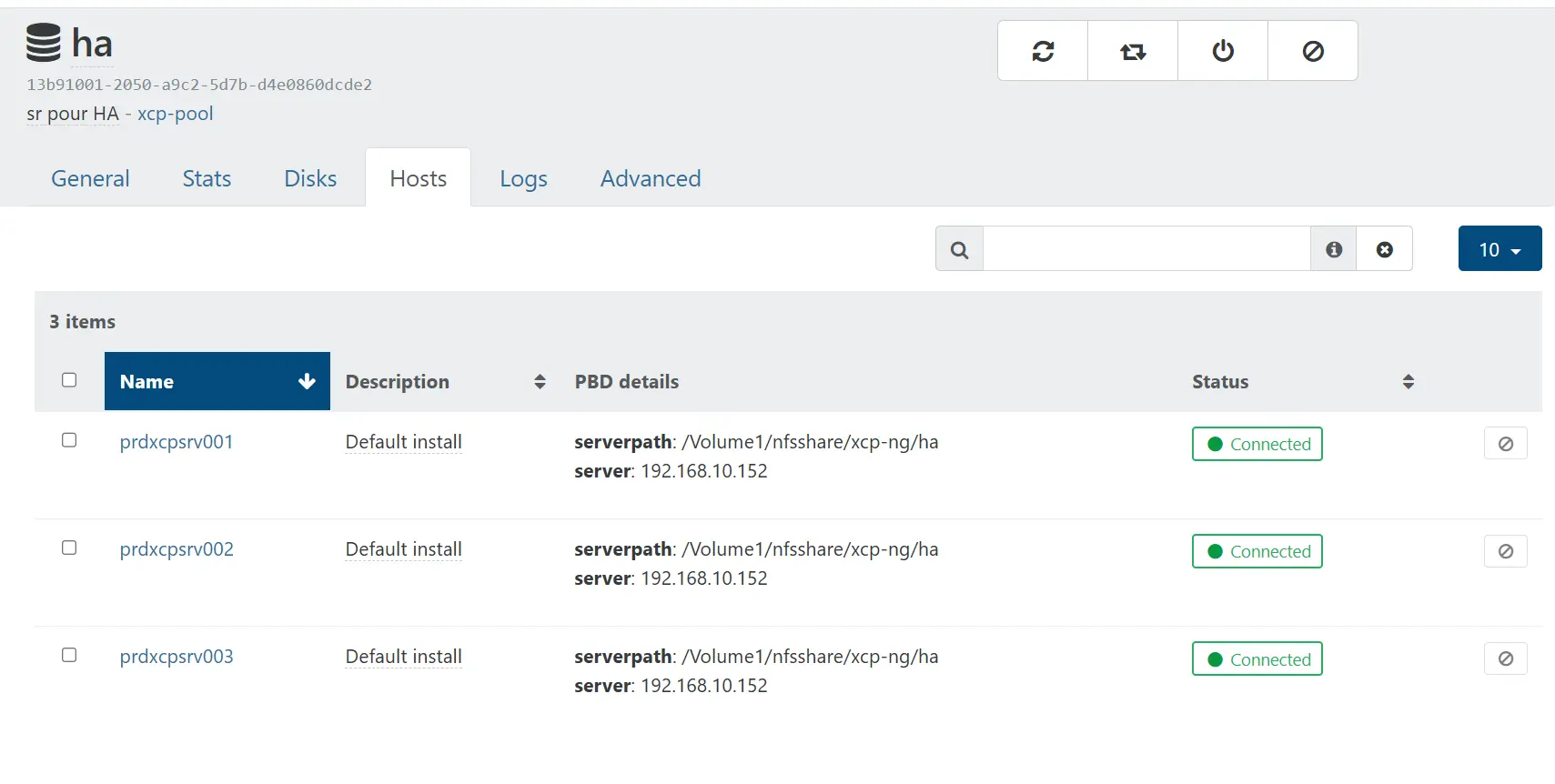
Bien qu'on ait sélectionné le premier serveur comme source de connexion, comme on est passé par le menu du pool, tous les nodes se retrouvent connectés à ce nouveau SR.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Je le rappelle, celui-ci n'est pas destiné à héberger des VMs.
Activation du HA au niveau pool
On peut maintenant se rendre dans les paramètres du pool, puis dans la section avancée, activer l'auto boot, puis la fonctionnalité HA.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
Celle-ci va nous demander de retenir au moins un SR de référence, soit celui qu'on vient de créer (il est possible d'en mettre plusieurs).
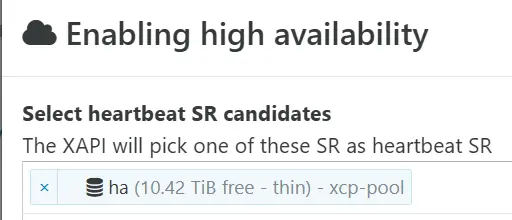
Cliquez sur l'image pour l'agrandir.
Le panel ne passe pas tout de suite au vert, car l'activation du HA va exécuter plusieurs tâches de configuration que l'on va pouvoir suivre dans le menu de suivi des activités du pool.
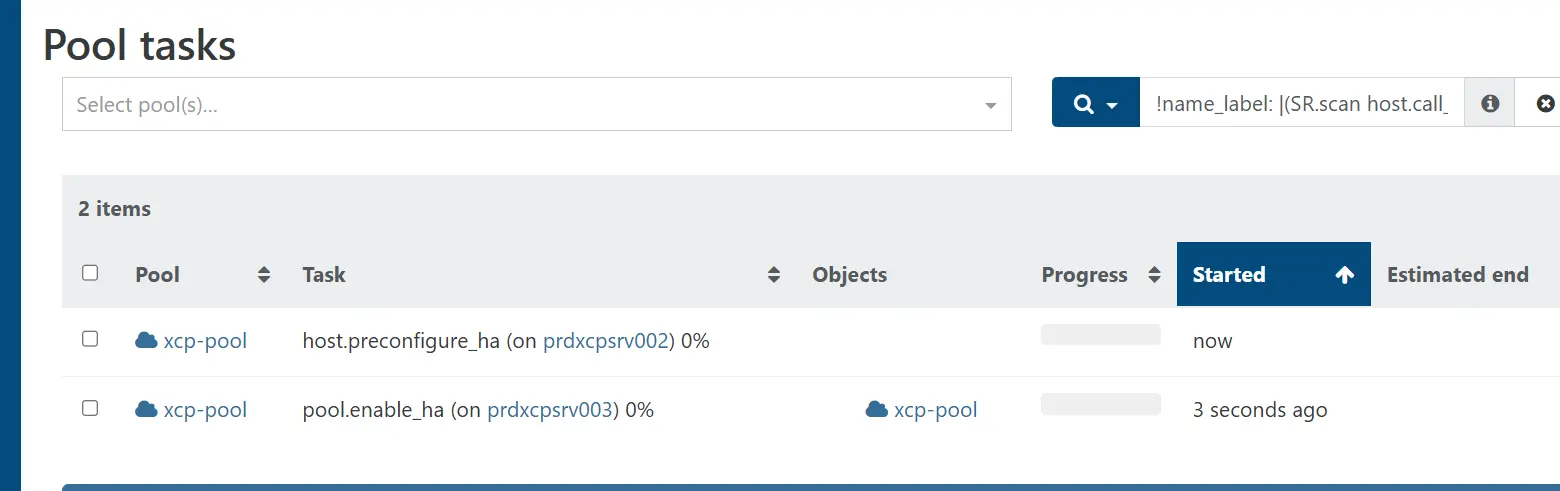
Cliquez sur l'image pour l'agrandir.
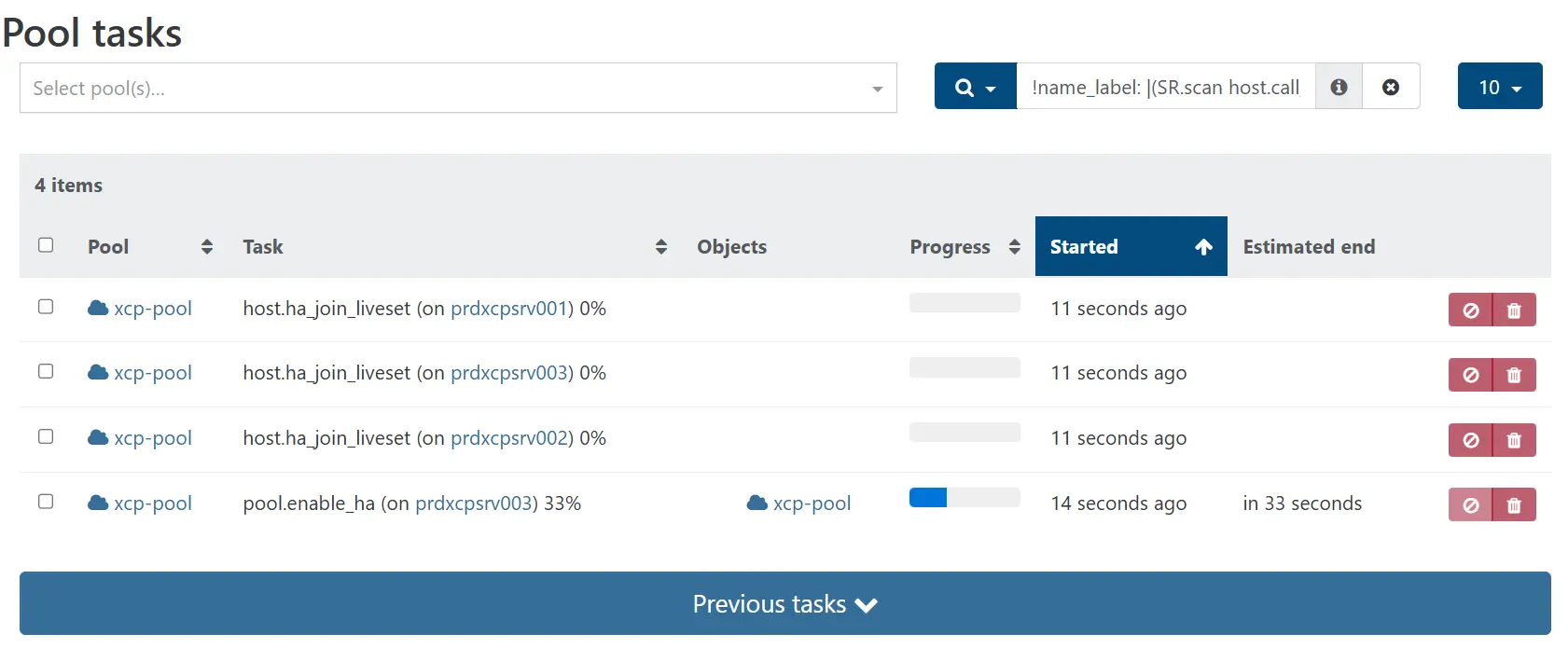
Cliquez sur l'image pour l'agrandir.
Chaque node doit être paramétré pour supporter le HA.
Quelques secondes plus tard, si on revient dans le menu du pool, au niveau HA, on voit que celui-ci est désormais actif.
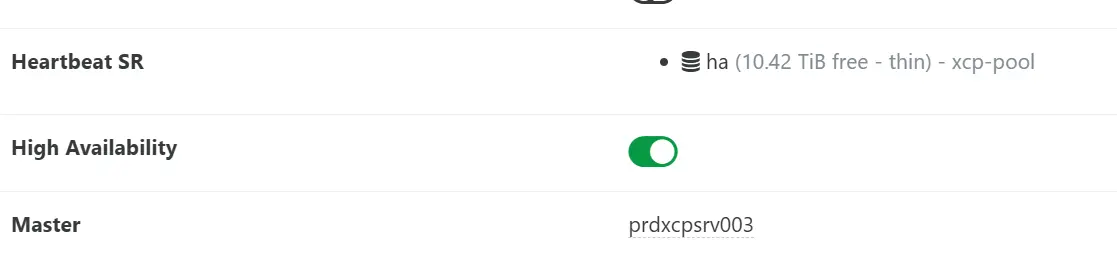
Cliquez sur l'image pour l'agrandir.
De même, on remarque la création d'éléments dans le dossier NFS rattaché à notre SR.
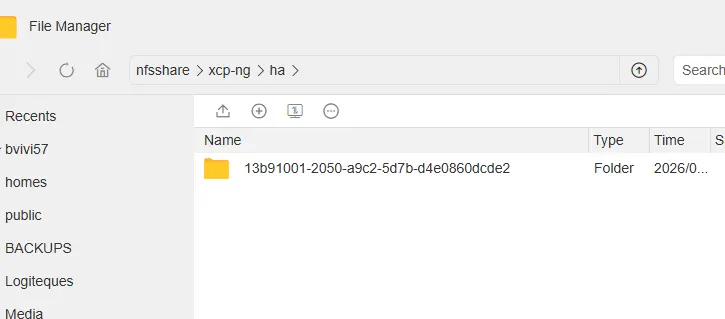
Cliquez sur l'image pour l'agrandir.
Activation du HA au niveau VM
Maintenant, nous allons devoir indiquer quelles VMs doivent être sous protection HA. Cela se fait au niveau des paramètres avancés de chaque VM, pour activer l'option (on en profite également pour activer l'auto boot).
Cliquez sur l'image pour l'agrandir.
Cliquez sur l'image pour l'agrandir.

Cliquez sur l'image pour l'agrandir.
On peut sélectionner le niveau d'exigence à appliquer pour redémarrer la VM en cas d'incident : soit en mode best effort, le pool allant essayer de faire le mieux possible pour démarrer la VM sans sacrifier de performances sur les nœuds restants, ou restart si on souhaite à tout prix que la VM redémarre, même en cas de contention de ressources.

Cliquez sur l'image pour l'agrandir.
Côté XO, dans la GUI en V6.0, on retrouve ces infos au niveau de chaque VM. Si l'on veut s'assurer qu'une VM survivra à la perte du nœud qui l'exécute, il faut activer le HA pour cette dernière et, idéalement, l'auto-démarrage.
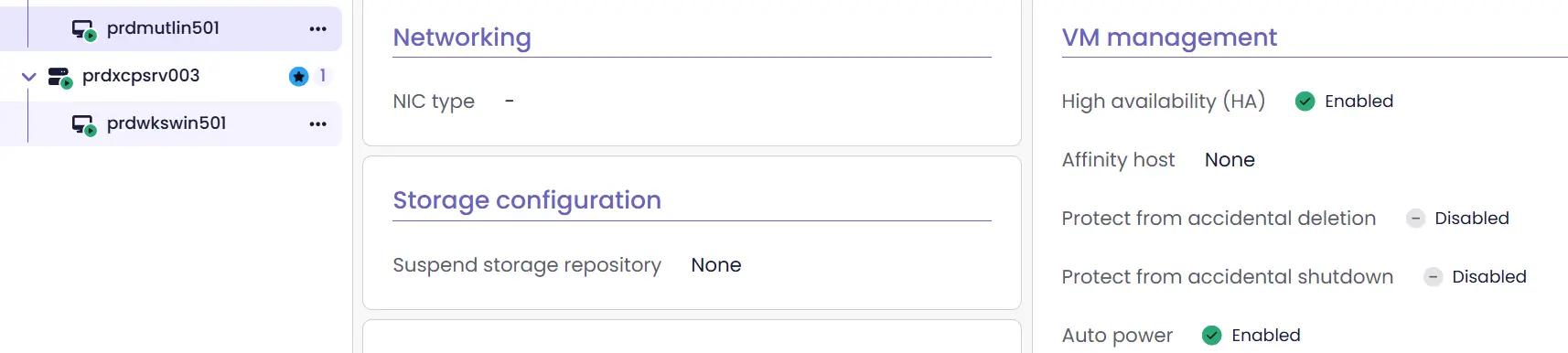
Cliquez sur l'image pour l'agrandir.
Tout est prêt, il ne reste plus qu'à tester.
Test HA
Situation de départ
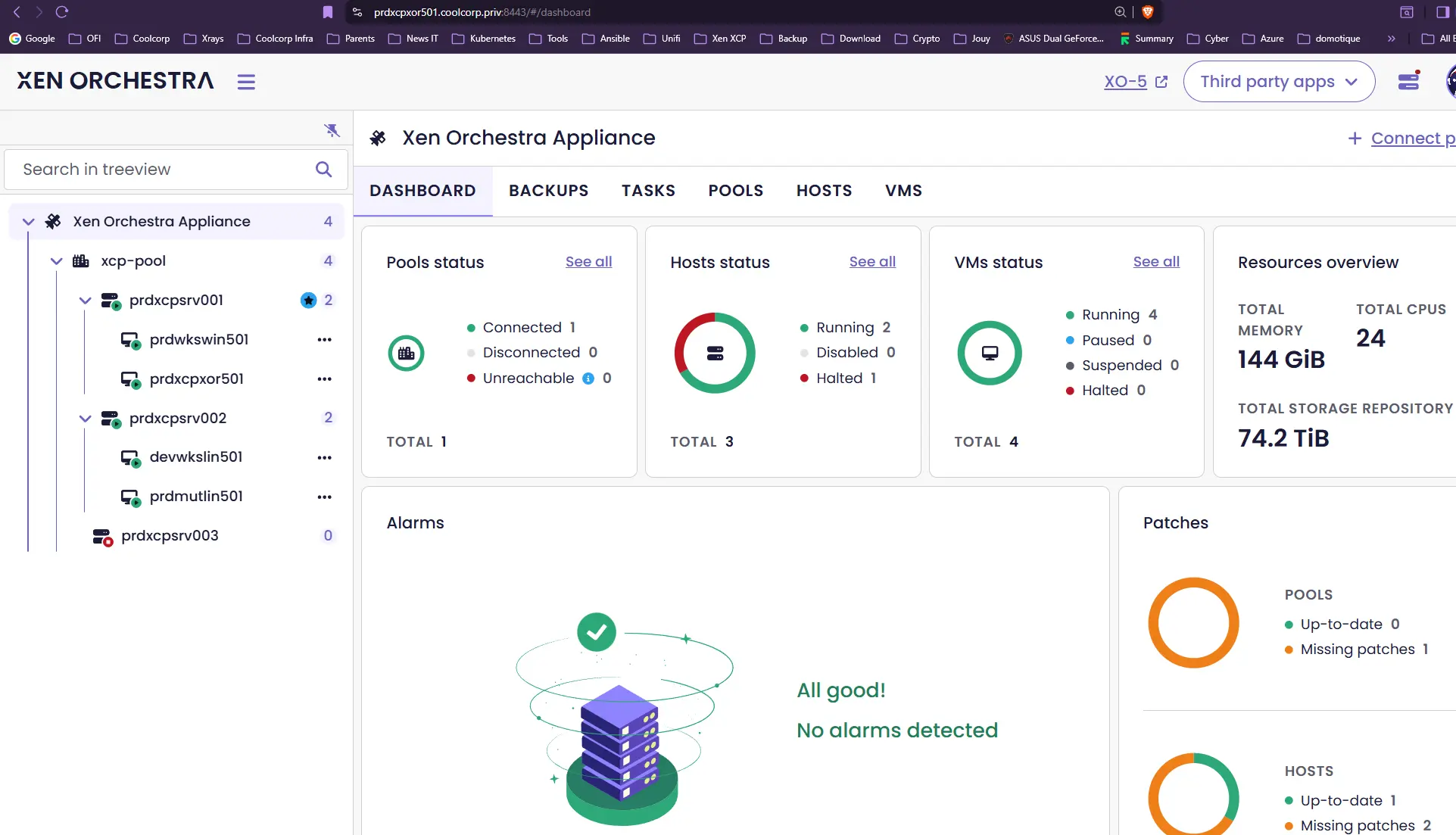
Avant de lancer le test, on va s'assurer de l'état du pool et identifier les nœuds critiques.
Pour le master du pool, c'est simple. On peut l'obtenir visuellement dans la console XO.
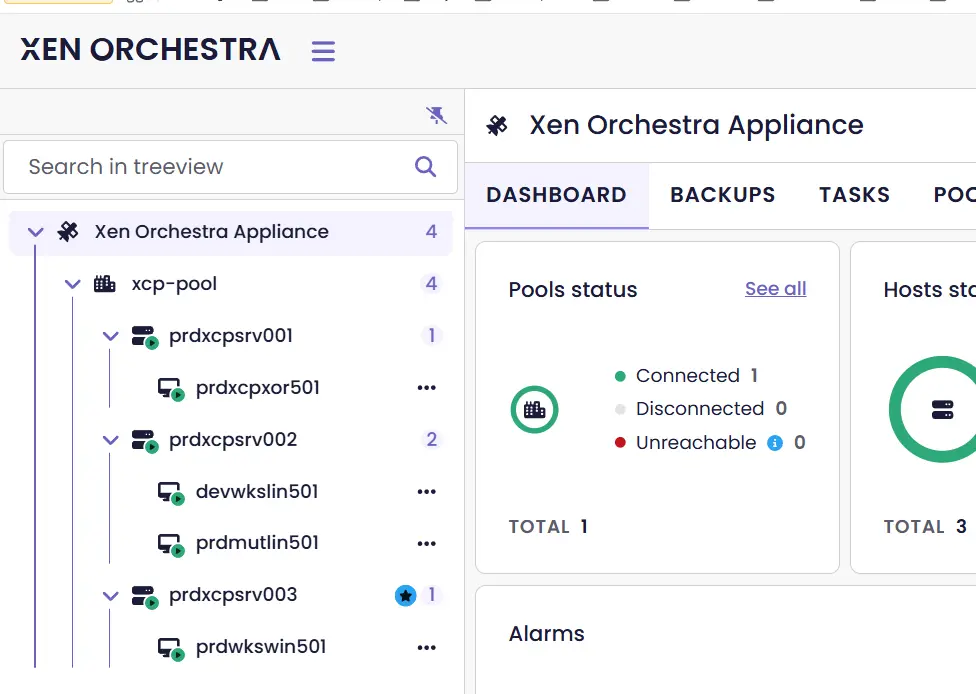
Cliquez sur l'image pour l'agrandir.
Ici c'est le serveur prdxcpsrv003. Côté CLI, en se connectant sur n'importe quel serveur en SSH, on peut avoir le même genre d'information via ces commandes :
MASTER_UUID=$(xe pool-list params=master --minimal)
xe host-list uuid="$MASTER_UUID" params=name-label,address
Cliquez sur l'image pour l'agrandir.
Maintenant, voyons côté XOSTOR. Comme on n'a pas de GUI dans notre version d'installation de XO, il va falloir passer par la CLI. Depuis n'importe quelle machine du pool, on tape la commande suivante :
linstor controller which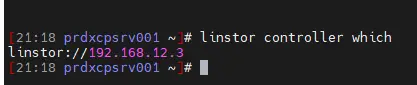
Cliquez sur l'image pour l'agrandir.
C'est l'IP du serveur prdxcpsrv003 sur le VLAN de storage qui répond. Dans cette situation on a donc le rôle de master du pool et le contrôleur primaire XOSTOR sur prdxcpsrv003.
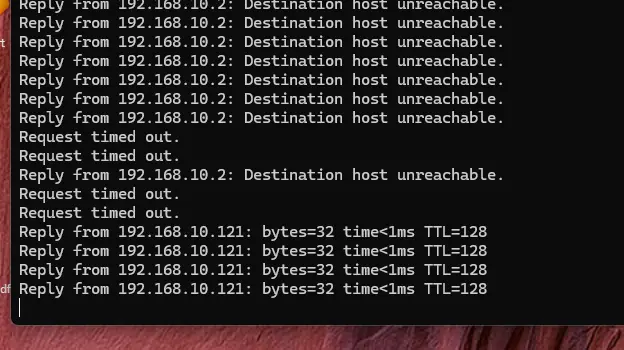
On va donc couper prdxcpsrv003. C'est le scénario le plus critique puisque les deux roles les plus importants seront perdus. Pour contrôler le fonctionnement du processus d'HA durant l'incident, on va pinger en continu une VM actuellement sur prdxcpsrv003 et une autre sur prdxcpsrv002.
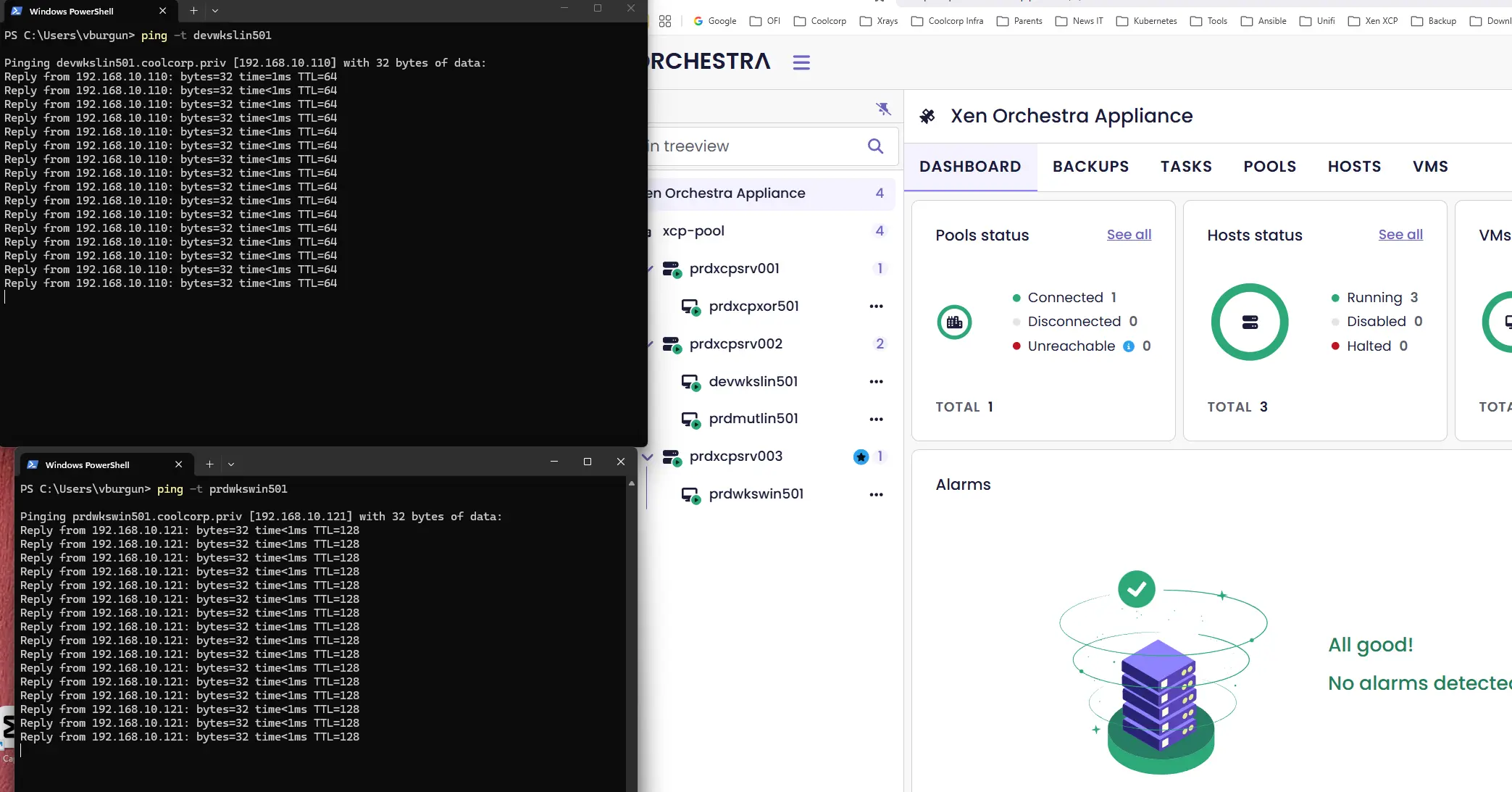
Cliquez sur l'image pour l'agrandir.
Perte du serveur maître et du contrôleur primaire
Faisons un poweroff violent sur prdxcpsrv003.
Instantanément on perd le ping sur la VM qui était exécutée sur ce dernier.
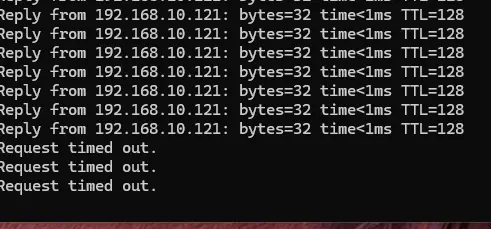
Cliquez sur l'image pour l'agrandir.
XO perd également contact avec le pool, ce qui est normal, puisque c'était via le master qu'il communiquait.
Cliquez sur l'image pour l'agrandir.
Il faut maintenant attendre quelques minutes, le temps que le processus de redémarrage prenne le relais. Dans mon cas, la VM a redonné signe de vie au bout de 2 min 30.
Cliquez sur l'image pour l'agrandir.
Par contre j'ai dû forcer un peu le destin pour XO en redémarrant le service pour le forcer à contacter le nouveau master. En effet, XO peut se mettre à attendre pendant plusieurs minutes s'il n'arrive pas à se connecter au serveur principal avant de réessayer… mais XO n'est en rien nécessaire au HA : une fois configuré, il n'entre plus dans l'équation.
Cliquez sur l'image pour l'agrandir.
Attention, bien que XO n'intervienne pas dans le processus HA, son redemarrage peut néanmoins avoir un impact en production, notamment si des tâches d'automatisation sont en cours d'exécution (déploiement, backup, migration...). Il est donc conseillé de ne pas faire cela en période de production, ou de s'assurer que les tâches en cours ne seront pas impactées par une indisponibilité temporaire de XO.
Une méthode plus douce est possible via l'interface XO 5.0 en allant dans Setting Server, et en cliquant sur le bouton disconnect puis reconnect. Cela va forcer XO à se reconnecter au pool, et à se synchroniser avec le nouveau master. (merci à AtaxyaNetwork du forum XCP-ng pour m'avoir signalé ce point)
XO ayant redémarré, il retrouve un master, en l'occurrence prdxcpsrv001. On a bien une vue du pool où la VM impactée est démarrée sur prdxcpsrv001, et prdxcpsrv003 est en erreur.

Cliquez sur l'image pour l'agrandir.
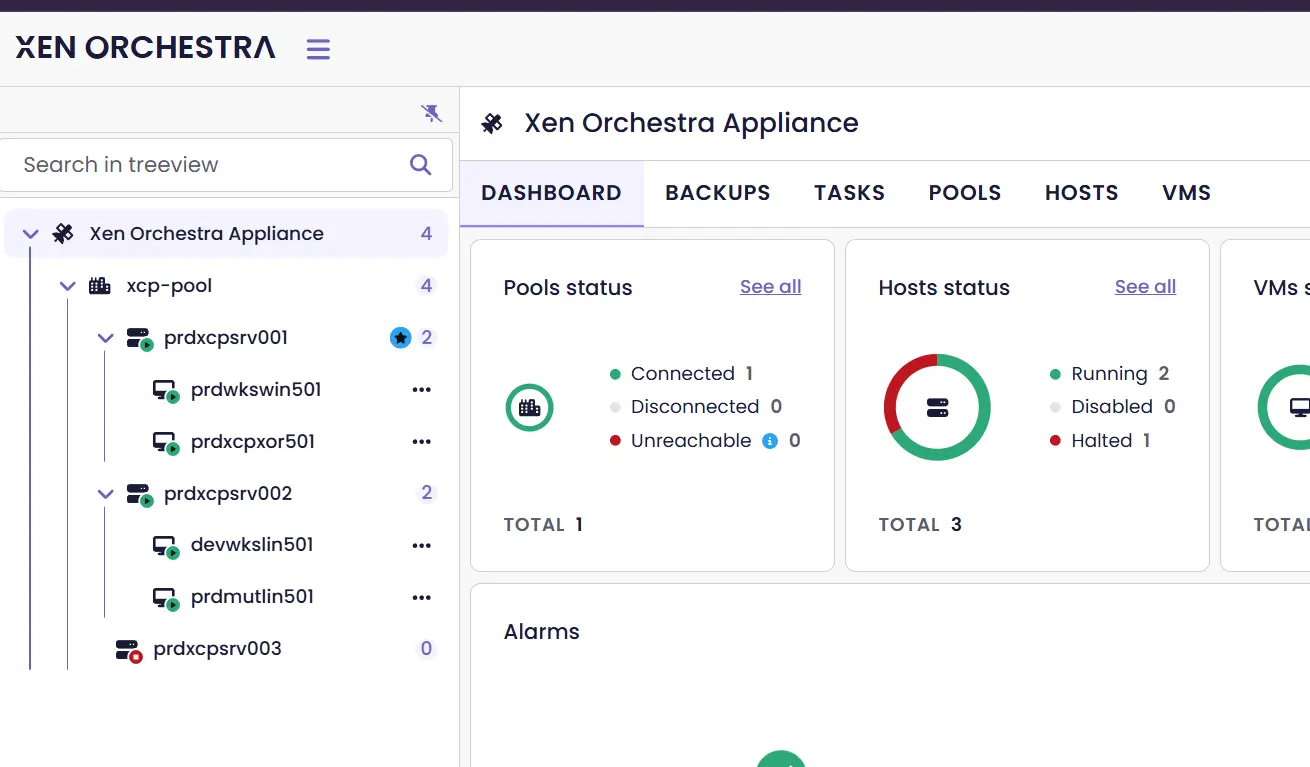
Cliquez sur l'image pour l'agrandir.
En ce qui concerne le stockage, on voit bien que le serveur en défaut est exclu de la configuration.

Cliquez sur l'image pour l'agrandir.
C'est également prdxcpsrv001 qui a obtenu le role de controleur primaire.

Cliquez sur l'image pour l'agrandir.
En l'état, la VM impactée par la perte du serveur a été redémarrée et les autres n'ont pas été impactées.
Par contre on n'est plus en mesure de supporter une panne supplémentaire. Si l'on avait besoin d'un niveau de résilience supérieur avec, par exemple, la perte acceptable de deux serveurs, il faudrait augmenter le nombre d'hyperviseurs dans le pool.
Cliquez sur l'image pour l'agrandir.
Retour à la normale
Ramenons maintenant le serveur prdxcpsrv003 à la vie.
Quelques minutes après le boot de ce dernier, il apparaît de nouveau comme opérationnel au niveau de la vue XO.
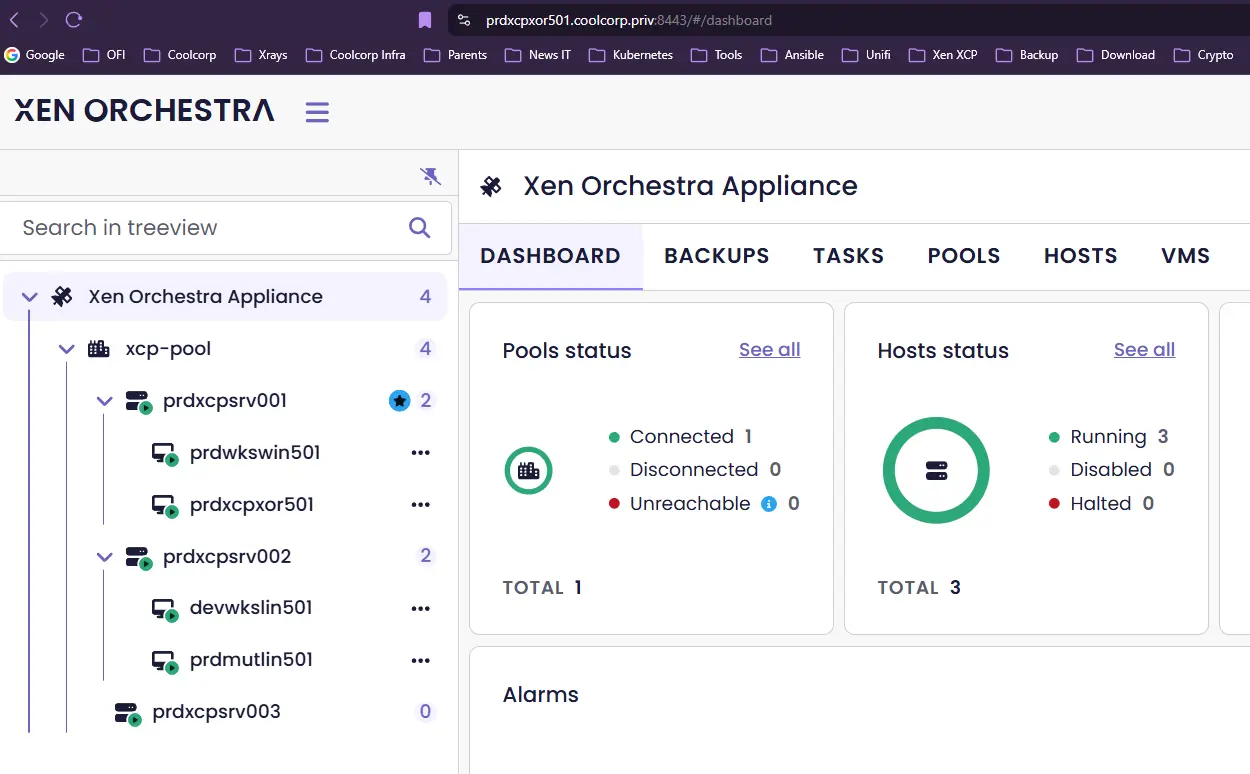
Cliquez sur l'image pour l'agrandir.
Du côté stockage, si l'on rappelle nos commandes de vérification, on a également constaté qu'il est en ligne :
linstor node list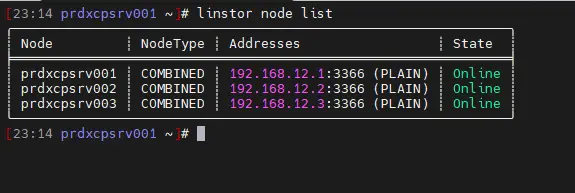
Cliquez sur l'image pour l'agrandir.
Notez que, malgré cela, il pourrait encore être nécessaire d'attendre quelques minutes supplémentaires pour que le service prdxcpsrv003 soit complètement rétabli. Des tâches de réplication peuvent avoir lieu, notamment au niveau de XOSTOR.
Il est possible de controler l'état des réplications avec la commande:
linstor resource list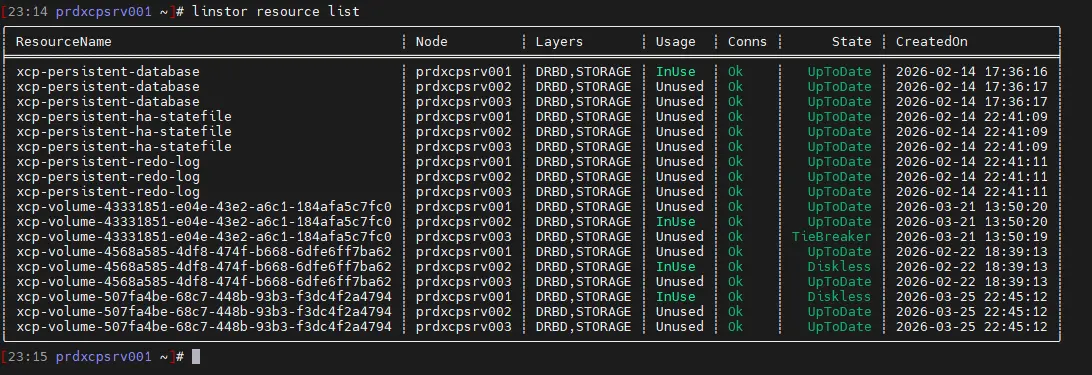
Cliquez sur l'image pour l'agrandir.
Conclusion
Nous voilà arrivés au bout de la mise en œuvre de mon homelab dans sa version 2 autour de XCP-ng.
L'écosystème Vates est probablement moins célèbre et moins utilisé que ProxMox comme alternative à VMware, corrompue par Satan, mais il mérite certainement qu'on s'y intéresse de près.
XCP-ng, XO et XOSTOR sont parfaitement aptes à proposer une infrastructure résiliente et performante en environnement professionnel, et ce, même pour de grosses structures.
Certes l'ergonomie et l'intégration méritent encore d'être travaillées, mais même des fonctionnalités comme VMware DRS (Distributed Resource Scheduler) sont disponibles sous forme de plugin de loadbalancing.
XOSTOR ne peut sans doute pas rivaliser avec VSAN en termes de fonctionnalités avancées, comme la déduplication, mais sa base open source est très robuste.
Personnellement je retrouve dans l'écosystème Vates un peu de mes premières expériences avec VMware. On y retrouve certains principes communs, et la présence de XenOrchestra appelle à la comparaison avec vCenter.
J'avais quelque peu abandonné mon métier d'ingénieur d'infrastructure, car les évolutions technologiques et mes propres envies d'évolution m'ont poussé à d'autres tâches professionnelles, préférant déléguer à des personnes plus compétentes que moi la mission d'entretenir et de maintenir les hyperviseurs de mon entreprise. Mais les enjeux réglementaires et les critères de souveraineté prenant de plus en plus d'ampleur, je reste toujours attentif aux alternatives. Un retour aux sources ne fait parfois pas de mal, et mon homelab est une bonne manière de rester connecté sur ce type de besoin.
J'ai donc hâte de continuer à voir évoluer XCP-ng et tout ce qui s'y rattache. La version 6.0 de XenOrchestra est très prometteuse, et ce n'est pas anodin si des géants du marché comme Veeam, après avoir priorisé leur intégration avec Proxmox, ont également annoncé leur compatibilité avec XCP.
Xen, à la base de XCP, n'a plus l'aura qu'il avait autrefois et c'est sans doute à cause de l'omniprésence de KVM. Toutefois, c'est un hyperviseur toujours en développement, fiable et performant.
Personnellement, je ne compte pas changer mon fusil d'épaule, et si KubeVirt reste dans mon viseur, j'ai clairement mis derrière moi mon ESXi, XCP-ng devenant ma nouvelle référence pour mon homelab.
Pour les personnes intéressées par la partie performance, notamment en comparaison de VMware, je vous invite à parcourir cette partie de mon ancien article sur la premiere version de mon lab sous XCP-ng qui reste d'actualité.