OpenClaw - Partie 04 : Dépendances Kubernetes et Telegram
Introduction
Après avoir:
- introduit le principe d'agent et présenté Openclaw
- installé l'environnement nécessaire à la conteneurisation d'agent
- déployé une solution de sécurisation des secrets
Pour rappel, celui-ci, qu'on va nommer « itclaw », va avoir comme mission de me servir d'assistant de supervision et de suivi de mon cluster Kubernetes.
Le but est de pouvoir l'interroger afin que celui-ci puisse se connecter à mon cluster K8S pour me faire des retours sur l'état des pods, des nœuds et des autres composants, allant jusqu'à m'envoyer régulièrement des rapports sur ma plateforme.
Pour cela, il va d'abord falloir préparer deux choses.
- Un fichier de config kubectl adapté aux besoins de l'agent et associé à un rôle sur le cluster. Je ne vais pas rentrer dans le détail, n'hésitez pas au besoin à parcourir mon article sur la notion de RBAC autour de Kubernetes. Le but va être de donner accès à l'agent uniquement en lecture aux objets du cluster en lui interdisant l'accès aux secrets. Quand on débute avec les agents, comme c'est mon cas, il faut se montrer prudent et avancer par petit pas. La sécurité reste une priorité, et il n'est pas question pour moi de laisser l'agent faire ce qu'il veut sur le cluster dans un premier temps.
- Un bot Telegram rattaché à l'agent. Il faut une base pour discuter localement et à distance avec notre agent. Pour ce faire, openclaw offre plusieurs compatibilités avec des solutions de messagerie. Toutefois, Telegram, grâce à sa popularité et son écosystème, revient souvent sur le devant de la scène à cet effet. Alors je sais que la nébuleuse Telegram ne se prête sans doute pas à des usages en entreprise, pour ça openclaw peut aussi exploiter Signal. Toutefois, comme expliqué dans mon premier article, il faut davantage de prérequis pour ça, à commencer par un numéro de téléphone dédié. Je vais donc rester sur Telegram pour mon usage.
Dépendances Kubernetes
Démarrons par la partie Kubernetes.
Création du compte de service et du rôle
Pour isoler tous les objets éventuels nécessaires à l'accès au cluster par l'agent, on va dédié un namespace selon ma nomenclature habituelle : prd-openclaw-lan.
Ce namespace va déjà nous permettre d'y déclarer l'objet ServiceAccount qu'on va nommer svc-openclaw-it. Il va représenter l'identité de l'agent sur le cluster et toutes les interactions de l'agent avec Kubernetes se feront avec ce compte de service interne au cluster.
Comme l'accès au cluster doit être global, si on souhaite que l'agent puisse observer et interroger l'ensemble des objets du cluster (hors contenu des secrets), on va devoir se baser sur un ClusterRole, transverse au cluster. (encore une fois, n'hésitez pas à passer par là si vous n'êtes pas à l'aise à ce niveau)
Ce ClusterRole se verra attribuer les droits d'accès en lecture à tous les objets du cluster (hors secret).
Enfin, dans la pure logique K8S, il nous faut un dernier objet ClusterRoleBinding pour lier le compte de service au rôle.
Afin de simplifier, j'ai regroupé la création de tous ces objets dans un seul fichier all-object-openclaw.yml dont voici le contenu:
#Création du namespace
---
apiVersion: v1
kind: Namespace
metadata:
name: prd-openclaw-lan
#Création du service account pour l'agent it-claw
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: svc-openclaw-it
namespace: prd-openclaw-lan
annotations:
description: "Accès en lecture seule pour l'agent it-claw"
#Création du role spécifique pour l'agent it-claw avec accès en lecture seule à tous les objets sauf les secrets
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cr-openclaw-global-reader
rules:
#Groupe principal (Core) : on liste tout explicitement SAUF "secrets"
- apiGroups: [""]
resources:
- nodes
- namespaces
- pods
- pods/log
- configmaps
- endpoints
- events
- persistentvolumes
- persistentvolumeclaims
- serviceaccounts
- services
verbs: ["get", "list", "watch"]
#Autres groupes d'API (Deployments, Ingress, CronJobs, etc.) : accès total en lecture
- apiGroups:
- apps
- batch
- autoscaling
- networking.k8s.io
- storage.k8s.io
- policy
- rbac.authorization.k8s.io
- apiextensions.k8s.io
- admissionregistration.k8s.io
- scheduling.k8s.io
- certificates.k8s.io
- coordination.k8s.io
- discovery.k8s.io
resources: ["*"]
verbs: ["get", "list", "watch"]
#Association du role au compte de service
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: crb-openclaw-it-claw
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cr-openclaw-global-reader
subjects:
- kind: ServiceAccount
name: svc-openclaw-it
namespace: prd-openclaw-lan
Ensuite j'applique simplement la commande kubectl apply -f pour créer les objets sur mon cluster.
kubectl apply -f all-object-openclaw.yml
Cliquez sur l'image pour l'agrandir.
Maintenant que les objets sont créés, il va falloir générer un token d'authentification propre au compte de service, pour ensuite exploiter ce token pour construire un fichier kubeconfig.
Création du fichier kubeconfig
Sur suggestion de l'IA et avec son aide (faut pas avoir honte), on va essayer d'être malin et de générer le fichier en exploitant des variables.
Pour ça on se place sur un des nodes control plane du cluster.
On génère le token avec une durée de vie adaptée. Dans mon cas, je suis large et je vise 3 ans (26280h). Idéalement en entreprise, ne dépasser pas six mois. On place le token directement dans une variable SA_TOKEN.
SA_TOKEN=$(kubectl create token svc-openclaw-it -n prd-openclaw-lan --duration=26280h)Puis on récupère dans une variable SA_CA, le CA public du cluster K8S qu'on souhaite interroger via le contenu spécifique du configmap kube-root-ca.crt.
SA_CA=$(kubectl get cm kube-root-ca.crt -o jsonpath='{.data.ca\.crt}')(L'objet configmap kube-root-ca.crt est par défaut dans tout cluster K8S)
Comme cette empreinte du CA va être stockée dans notre fichier kubeconfig, il faut passer par une conversion en base64 dont le résultat va être stocké dans une variable SA_CA_B64.
SA_CA_B64=$(echo -n "$SA_CA" | base64 -w0)
Cliquez sur l'image pour l'agrandir.
Et avec tout ça, y'a plus qu'à générer notre fichier de config.
cat > /tmp/it-claw.kubeconfig <<EOF
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: ${SA_CA_B64}
server: ${API_SERVER}
name: kub.coolcorp.priv
contexts:
- context:
cluster: kub.coolcorp.priv
namespace: default
user: svc-openclaw-it
name: [email protected]
current-context: [email protected]
users:
- name: svc-openclaw-it
user:
token: ${SA_TOKEN}
EOF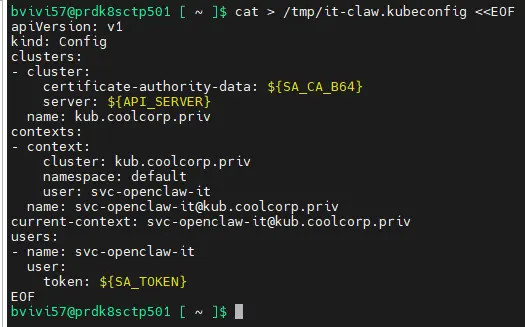
Cliquez sur l'image pour l'agrandir.
Pour l'instant on le stocke dans /tmp sur notre node k8s.
On peut directement tester son usage en forçant la commande kubectl à l'exploiter via la variable KUBECONFIG=/tmp/it-claw.kubeconfig.
Par exemple, en listant les nodes.
KUBECONFIG=/tmp/it-claw.kubeconfig kubectl get nodes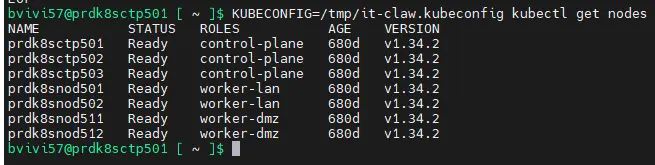
Cliquez sur l'image pour l'agrandir.
Par sécurité on teste l'accès aux secrets du cluster.
KUBECONFIG=/tmp/it-claw.kubeconfig kubectl get secrets -n prd-openclaw-lan 2>&1 | head -2Et là on obtient un message d'erreur nous indiquant que les secrets ne sont pas accessibles au compte de service.

Cliquez sur l'image pour l'agrandir.
Ainsi, même si notre agent venait à être détourné, il ne pourrait pas accéder au contenu des secrets sur le cluster.
Attention, notre fichier it-claw.kubeconfig est néanmoins sensible, le but va être de le sécuriser par la suite. Pour l'instant il faut ramener son contenu sur notre serveur dédié aux agents prdlinage501 (et ne pas laisser trainer le fichier sur le node K8S).
On poursuivra avec le fichier sur le serveur dédié aux agents par la suite.
Dépendance Telegram
Pour l'instant on va s'occuper de Telegram.
Le but va être de créer un bot Telegram qui va pouvoir être contrôlé par l'agent afin qu'on puisse communiquer avec lui.
Bon, forcément, il faut déjà disposer d'un compte Telegram et de l'application sur son téléphone.
Création du bot
Ensuite, il va falloir rechercher le contact « BotFather ». C'est un compte technique de la plateforme.
Attention, ne vous faites pas avoir, retenez bien celui qui dispose d'une petite icône bleue indiquant qu'il s'agit d'un compte officiel.
Vérifiez bien également l'orthographe.

Cliquez sur l'image pour l'agrandir.
Dans la conversation, taper /newbot.
Ceci va déclencher la procédure de création du bot.
Cliquez sur l'image pour l'agrandir.
Il faudra suivre la procédure, c'est-à-dire donner un nom à votre bot puis un username (attention, celui-ci doit respecter une certaine forme).
En retour, Telegram va vous retourner une clef API associée à votre bot nouvellement créé.
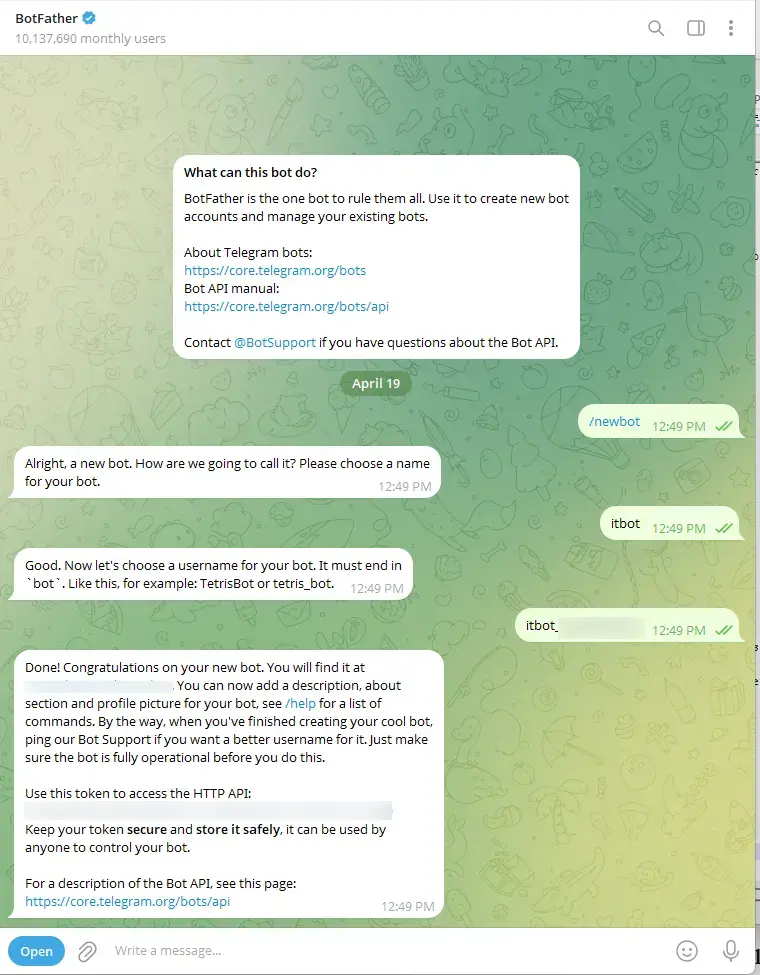
Cliquez sur l'image pour l'agrandir.
Attention, cette clef est critique ! Elle est confidentielle et doit être sécurisée, c'est d'ailleurs ce qu'on fera par la suite. En attendant, placez-la en lieu sûr et pensez toujours à purger votre conversation avec BotFather pour ne pas garder dans votre historique la valeur de la clef API.
Récupération de l'ID utilisateur
Cette clef n'est d'ailleurs pas suffisante, car Telegram inclut une protection supplémentaire pour échanger avec votre bot.
Par défaut celui-ci ne vous répondra qu'à vous.
Or, notre agent itclaw va devoir l'exploiter pour communiquer avec vous. Par conséquent, en plus de la clé API, vous devrez également lui fournir votre ID utilisateur. Ce dernier peut être obtenu via l'interface utilisateur du système.

Cliquez sur l'image pour l'agrandir.
Encore une fois, faites attention à l'orthographe du compte.
Une fois dans la conversation, tapez le mot clef /start.
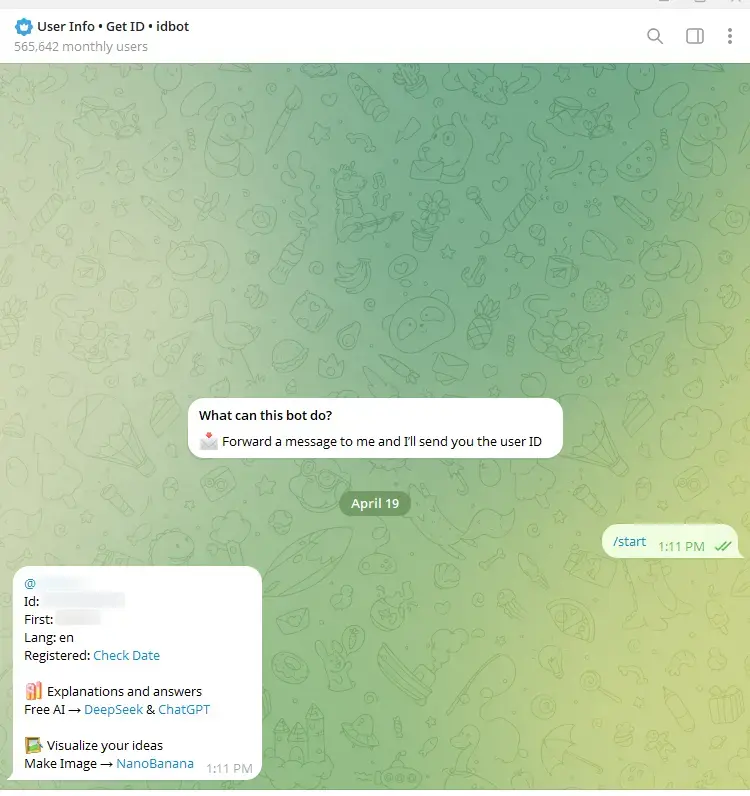
Cliquez sur l'image pour l'agrandir.
Cela aura comme conséquence de vous retourner votre ID d'utilisateur.
Ici aussi, faites attention à sa valeur, elle est moins confidentielle que la clef API mais gardez-la tout de même pour vous.
Nous voilà avec tous les éléments nécessaires.
Qu'il s'agisse de la clef API Telegram ou du fichier de config Kubernetes, tout cela s'apparente à des informations sensibles.
Usage de Vault
C'est donc maintenant que notre instance de Vault, installée dans l'article précédent, entrera en action. Toutes ces informations sensibles indispensables à notre agent seront stockées dans Vault.
Inscription des dépendances
Donc, sur notre serveur dédié au agent prdlinage501 avec notre compte utilisateur classique, comme la dernière fois, nous allons interagir avec Vault. Je ne répéterais pas la logique globale, n'hésitez pas à revoir ou voir l'article dédié au besoin.
On exporte dans une variable notre instance Vault, afin d'indiquer à notre CLI Vault où se connecter, soit à notre instance Vault locale.
export VAULT_ADDR="https://prdlinage501.coolcorp.priv:8200"Pour des raisons de sécurité, quand on interagit avec Vault, on désactive son historique de session.
set +o historyOn se connecte en root à l'instance.
vault login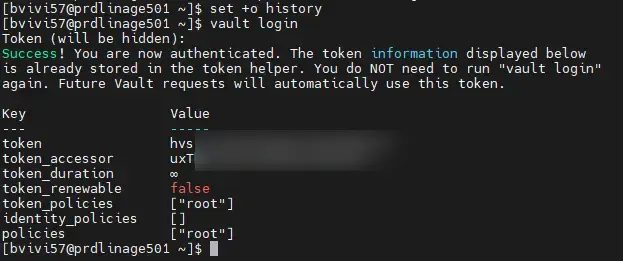
Cliquez sur l'image pour l'agrandir.
De là nous allons enregistrer dans la base clef/valeur sécurisée, au niveau de l'arborescence créée dans l'article précédent, nos différentes données sensibles.
On commence par la clef API (ou le token) de Telegram associé à notre bot.
vault kv put secret/openclaw/it-claw/telegram_token value="<TOKEN_TELEGRAM>"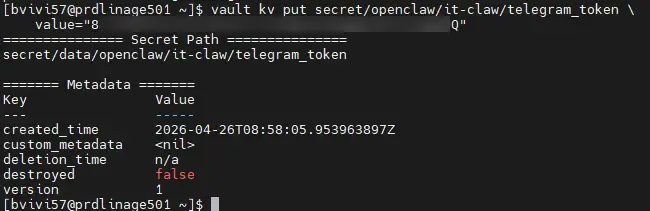
Cliquez sur l'image pour l'agrandir.
Puis notre config Kubernetes récupérée sur notre control plane (qu'on a temporairement mise dans /tmp sur notre serveur prdlinage501).
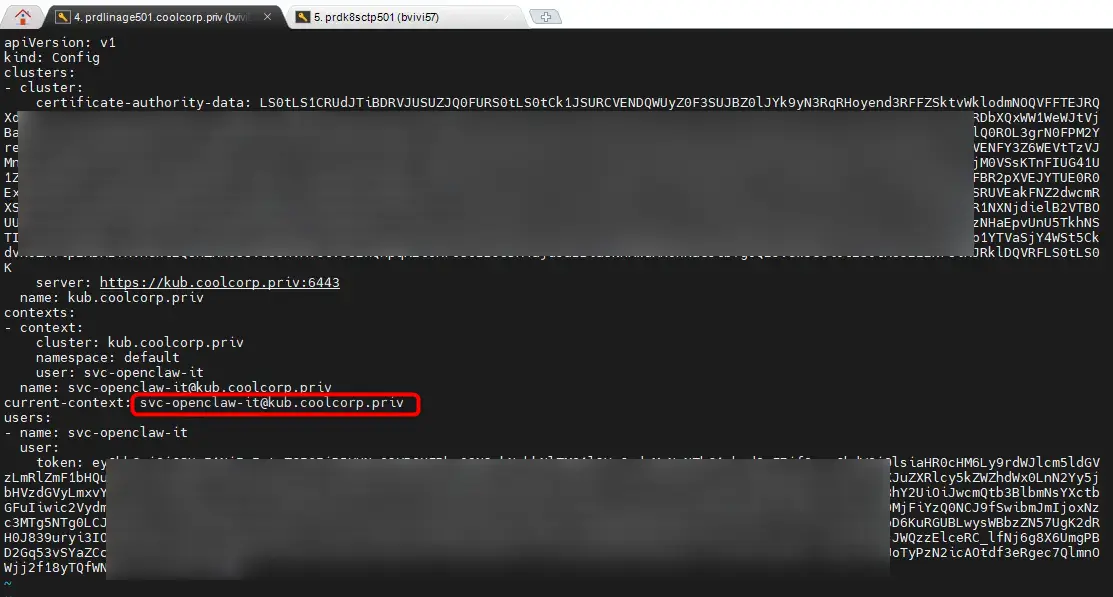
Cliquez sur l'image pour l'agrandir.
vault kv put secret/openclaw/it-claw/kubeconfig value=@/tmp/it-claw.kubeconfig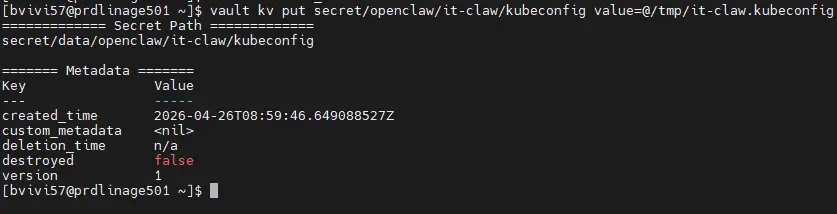
Cliquez sur l'image pour l'agrandir.
Enfin, si on ne met pas l'ID de l'utilisateur Telegram, car moins sensible, il faut exploiter un troisième secret, soit la clef privée de notre futur agent.
En effet, chaque agent OpenClaw possède sa propre gateway de communication et celle-ci est protégée par un jeton unique généré aléatoirement.
C'est ce token qu'on va créer (commande openssl) puis stocker dans le coffre-fort.
GATEWAY_TOKEN=$(openssl rand -hex 32)
vault kv put secret/openclaw/it-claw/gateway_token value="$GATEWAY_TOKEN"
unset GATEWAY_TOKEN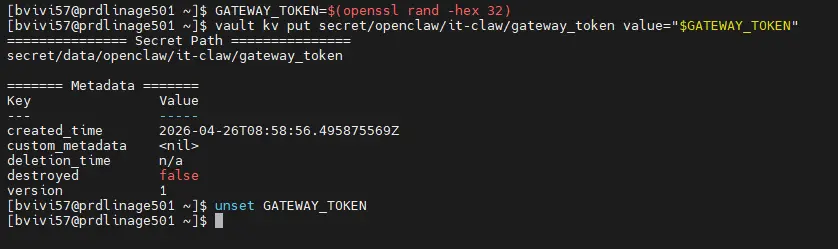
Cliquez sur l'image pour l'agrandir.
Une fois que tout est terminé, on peut s'assurer que toutes les données se trouvent bien dans Vault.
vault kv list secret/openclaw/it-claw/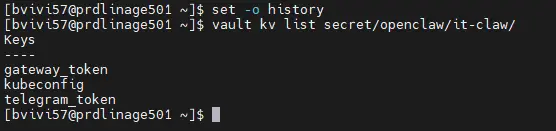
Cliquez sur l'image pour l'agrandir.
On n'oublie pas de supprimer toute trace éventuelle de fichier temporaire et on peut passer à la suite.

Cliquez sur l'image pour l'agrandir.
Récupération des identifiants
Toujours avec Vault et notre utilisateur actuel, on va maintenant devoir récupérer les identifiants nécessaires pour authentifier notre futur agent via la notion de AppRole présentée sur l'article dédié à Vault.
Pour ça, on va déjà demander à Vault de générer un nouveau mot de passe dynamique pour le rôle vault openclaw-it-claw.
Ce secret va être stocké dans la variable SECRET_ID (ce n'est que temporaire).
SECRET_ID=$(vault write -field=secret_id -f auth/approle/role/openclaw-it-claw/secret-id)Ensuite on récupère le role ID dans la variable ROLE_ID, normalement on l'a déjà fait précédemment et on l'a stocké dans l'arborescence de notre agent (/var/lib/openclaw/vault/it-claw-role-id).
Mais au besoin on peut le redemander (pour rappel cette info n'est pas confidentielle).
ROLE_ID=$(cat /var/lib/openclaw/vault/it-claw-role-id 2>/dev/null || \
vault read -field=role_id auth/approle/role/openclaw-it-claw/role-id)Après avoir enregistré les données dans Vault, on peut vérifier qu'elles sont effectivement accessibles grâce aux informations d'authentification récemment obtenues.
Pour ça, on génère un token TEST_TOKEN de connexion à Vault à partir du SECRET_ID et du ROLE_ID.
TEST_TOKEN=$(vault write -field=token auth/approle/login \
role_id="$ROLE_ID" \
secret_id="$SECRET_ID")On utilise ensuite ce jeton pour essayer d'obtenir un accès à une donnée de Vault liée à notre agent.
VAULT_TOKEN="$TEST_TOKEN" vault kv get secret/openclaw/it-claw/telegram_token > /dev/null && \
echo "AppRole OK" || echo "AppRole KO"
Cliquez sur l'image pour l'agrandir.
On est bon.
Il est temps de déposer ces éléments d'authentification au niveau de notre arborescence d'agent.
Le ROLE_ID est normalement déjà là, mais pas le SECRET_ID.
# role-id (non-sensible, équivalent d'un username)
echo "$ROLE_ID" | sudo tee /var/lib/openclaw/vault/it-claw-role-id > /dev/null
echo "$SECRET_ID" | sudo tee /var/lib/openclaw/vault/it-claw-secret-id > /dev/null
Cliquez sur l'image pour l'agrandir.
On touche à un point sensible déjà évoqué précédemment… Le fait qu'on stocke le secret_id dans l'arborescence du bot.
On va déja limiter les accès à ces données en les confinant à notre utilisateur openclaw créé spécifiquement pour nos besoins et présenté dans l'article spécifique au prérequis.
sudo chown -R openclaw:openclaw /var/lib/openclaw/vault/
sudo chmod 644 /var/lib/openclaw/vault/it-claw-role-id
sudo chmod 644 /var/lib/openclaw/vault/it-claw-secret-id
Cliquez sur l'image pour l'agrandir.
Sans oublier SELinux.
sudo restorecon -Rv /var/lib/openclaw/vault/
Cliquez sur l'image pour l'agrandir.
Nous pourrions aller plus loin en ajoutant des options telles que secret_id_bound_cidrs="127.0.0.1/32" à notre rôle Vault. Cela permettrait de s'assurer que le secret_id ne peut être exploitable que localement, ce qui le rendrait inutilisable pour une réutilisation depuis une autre machine que mon serveur prdlinage501. Cela minimiserait les risques de vol de ce secret.
Mais ce n'est pas le sujet ici.
Pour autant, on n'oublie pas de virer les variables.
unset SECRET_ID ROLE_ID TEST_TOKEN
Cliquez sur l'image pour l'agrandir.
Conclusion
À ce stade, l'article est déjà relativement long et on va s'arrêter ici pour l'instant. On a récupéré et sécurisé toutes les données confidentielles nécessaires à l'usage du futur agent itclaw.
Si on résume, celui-ci pourra interagir avec moi à travers un bot Telegram (itbot) puis accéder à mon cluster Kubernetes via l'usage d'un fichier de config qui lui permettra de se connecter sur le cluster en tant que le compte de service svc-openclaw-it. Ce compte n'ayant que des accès en lecture sur le cluster, l'agent ne pourra pas faire autre chose que de la remontée d'informations, et sans pouvoir toucher aux objets secrets du cluster.
L'agent pourra obtenir tous les renseignements confidentiels nécessaires auprès du conteneur Vault qui lui sera attribué. Ce dernier sera responsable de récupérer dans notre instance Vault les éléments requis.
Dans le prochain article on pourra enfin mettre en œuvre notre agent openclaw au sein d'un conteneur dans une arborescence dédiée ainsi que son conteneur vault.